
التعلم الفعال: المستقبل القريب للذكاء الاصطناعي
نشرت: 2017-11-09تقنيات التعلم الفعالة هذه ليست تقنيات جديدة للتعلم العميق / تعلم الآلة ، ولكنها تعزز التقنيات الحالية مثل المأجورون
بالتأكيد ليس هناك شك في أن المستقبل النهائي للذكاء الاصطناعي هو الوصول إلى الذكاء البشري وتجاوزه. لكن هذا إنجاز بعيد المنال يجب تحقيقه. حتى أكثر الأشخاص تفاؤلاً بيننا يراهنون على أن الذكاء الاصطناعي على المستوى البشري (AGI أو ASI) سيصل إلى ما بين 10 إلى 15 سنة من الآن مع وجود متشككين على استعداد للمراهنة على أن الأمر سيستغرق قرونًا ، إن أمكن ذلك. حسنًا ، هذا ليس موضوع المنشور.
هنا سوف نتحدث عن مستقبل أكثر واقعية وأقرب ونناقش خوارزميات وتقنيات الذكاء الاصطناعي الناشئة والفعالة والتي ، في رأينا ، ستشكل المستقبل القريب للذكاء الاصطناعي.
بدأ الذكاء الاصطناعي في تحسين البشر في عدد قليل من المهام المحددة والمحددة. على سبيل المثال ، ضرب الأطباء في تشخيص سرطان الجلد وهزيمة لاعبي Go في بطولة العالم. لكن نفس الأنظمة والنماذج ستفشل في أداء مهام مختلفة عن تلك التي تم تدريبهم على حلها. لهذا السبب ، على المدى الطويل ، يُطلق على النظام الذكي بشكل عام الذي يؤدي مجموعة من المهام بكفاءة دون الحاجة إلى إعادة التقييم اسم مستقبل الذكاء الاصطناعي.
ولكن ، في المستقبل القريب للذكاء الاصطناعي ، وقبل ظهور الذكاء الاصطناعي العام ، كيف يمكن للعلماء أن يجعلوا خوارزمية مدعومة بالذكاء الاصطناعي تتغلب على المشاكل التي يواجهونها اليوم لتخرج من المختبرات وتصبح أدوات للاستخدام اليومي؟
عندما تنظر حولك ، تفوز منظمة العفو الدولية بقلعة واحدة في كل مرة (اقرأ منشوراتنا حول كيفية تفوق الذكاء الاصطناعي على البشر ، الجزء الأول والجزء الثاني). ما الخطأ الذي يمكن أن يحدث في مثل هذه اللعبة المربحة للجانبين؟ ينتج البشر المزيد والمزيد من البيانات (وهي العلف الذي يستهلكه الذكاء الاصطناعي) مع مرور الوقت ، كما تتحسن قدرات أجهزتنا أيضًا. بعد كل شيء ، البيانات والحسابات الأفضل هي الأسباب التي أدت إلى بدء ثورة التعلم العميق في عام 2012 ، أليس كذلك؟ الحقيقة هي أن نمو التوقعات البشرية أسرع من نمو البيانات والحسابات. سيتعين على علماء البيانات التفكير في حلول تتجاوز ما هو موجود الآن لحل مشاكل العالم الحقيقي. على سبيل المثال ، تصنيف الصور كما يعتقد معظم الناس هو مشكلة تم حلها علميًا (إذا قاومنا الرغبة في قول دقة 100٪ أو GTFO).
يمكننا تصنيف الصور (دعنا نقول إلى صور قطط أو صور كلاب) مطابقة للقدرة البشرية باستخدام الذكاء الاصطناعي. ولكن هل يمكن استخدام هذا بالفعل في حالات الاستخدام الواقعية؟ هل يمكن للذكاء الاصطناعي تقديم حل للمشكلات العملية التي يواجهها البشر؟ في بعض الحالات ، نعم ، لكن في كثير من الحالات ، لم نصل إلى هناك بعد.
سنوجهك عبر التحديات التي تمثل العوائق الرئيسية لتطوير حل في العالم الحقيقي باستخدام الذكاء الاصطناعي. لنفترض أنك تريد تصنيف صور القطط والكلاب. سنستخدم هذا المثال في جميع أنحاء المنشور.

خوارزمية المثال لدينا: تصنيف صور القطط والكلاب
يلخص الرسم أدناه التحديات:

التحديات التي ينطوي عليها تطوير الذكاء الاصطناعي في العالم الحقيقي
دعونا نناقش هذه التحديات بالتفصيل:
التعلم ببيانات أقل
- تتطلب بيانات التدريب الأكثر نجاحًا التي تستهلكها خوارزميات التعلم العميق أن يتم تصنيفها وفقًا للمحتوى / الميزة التي تحتوي عليها. هذه العملية تسمى التعليق التوضيحي.
- لا يمكن للخوارزميات استخدام البيانات الموجودة بشكل طبيعي من حولك. يعد التعليق التوضيحي لبضع مئات (أو بضعة آلاف من نقاط البيانات) أمرًا سهلاً ، لكن خوارزمية تصنيف الصور على المستوى البشري أخذت مليون صورة توضيحية لتتعلم جيدًا.
- لذا فإن السؤال هو ، هل من الممكن إضافة تعليقات توضيحية إلى مليون صورة؟ إذا لم يكن الأمر كذلك ، فكيف يمكن للذكاء الاصطناعي التوسع بكمية أقل من البيانات المشروحة؟
حل مشاكل العالم الحقيقي المتنوعة
- بينما يتم إصلاح مجموعات البيانات ، يكون الاستخدام الفعلي أكثر تنوعًا (على سبيل المثال ، قد تفشل الخوارزمية المدربة على الصور الملونة بشكل سيئ في الصور ذات التدرج الرمادي على عكس البشر).
- بينما قمنا بتحسين خوارزميات رؤية الكمبيوتر لاكتشاف الأشياء لتتناسب مع البشر. ولكن كما ذكرنا سابقًا ، تحل هذه الخوارزميات مشكلة محددة جدًا مقارنة بالذكاء البشري الذي يعتبر أكثر عمومية بكثير في العديد من المعاني.
- لن تتمكن خوارزمية الذكاء الاصطناعي في مثالنا ، والتي تصنف القطط والكلاب ، من تحديد أنواع الكلاب النادرة إذا لم تتغذى بصور من هذا النوع.
ضبط البيانات الإضافية
- التحدي الرئيسي الآخر هو البيانات الإضافية. في مثالنا ، إذا كنا نحاول التعرف على القطط والكلاب ، فقد نقوم بتدريب الذكاء الاصطناعي الخاص بنا على عدد من صور القطط والكلاب لأنواع مختلفة أثناء نشرنا لأول مرة. ولكن عند اكتشاف نوع جديد تمامًا ، نحتاج إلى تدريب الخوارزمية للتعرف على "Kotpies" جنبًا إلى جنب مع الأنواع السابقة.
- في حين أن الأنواع الجديدة قد تكون أكثر تشابهًا مع الأنواع الأخرى مما نعتقد ويمكن تدريبها بسهولة لتكييف الخوارزمية ، إلا أن هناك نقاط يكون فيها هذا الأمر أكثر صعوبة ويتطلب إعادة تدريب وإعادة تقييم كاملة.
- السؤال هو هل يمكننا جعل الذكاء الاصطناعي قابلاً للتكيف على الأقل مع هذه التغييرات الصغيرة؟
لجعل الذكاء الاصطناعي قابلاً للاستخدام على الفور ، تكمن الفكرة في حل التحديات المذكورة أعلاه من خلال مجموعة من الأساليب تسمى التعلم الفعال (يرجى ملاحظة أنه ليس مصطلحًا رسميًا ، فأنا فقط أقوم بإعداده لتجنب كتابة Meta-Learning ، نقل التعلم ، قليل التعلم بالرصاص والتعلم العدائي والتعلم متعدد المهام في كل مرة). نحن ، في ParallelDots ، نستخدم الآن هذه الأساليب لحل المشكلات الضيقة مع الذكاء الاصطناعي ، والفوز بمعارك صغيرة بينما نستعد لذكاء اصطناعي أكثر شمولاً لقهر حروب أكبر. دعنا نقدم لك هذه التقنيات واحدة تلو الأخرى.
من الملاحظ أن معظم تقنيات التعلم الفعال هذه ليست شيئًا جديدًا. إنهم فقط يشهدون عودة الظهور الآن. يستخدم باحثو SVM (آلات المتجهات الداعمة) هذه التقنيات لفترة طويلة. التعلم العدواني ، من ناحية أخرى ، هو شيء خرج من عمل Goodfellow الأخير في GANs و Neural Reasoning عبارة عن مجموعة جديدة من التقنيات التي أصبحت مجموعات البيانات متاحة لها مؤخرًا. دعونا نتعمق في الكيفية التي ستساعد بها هذه التقنيات في تشكيل مستقبل الذكاء الاصطناعي.
نقل التعلم
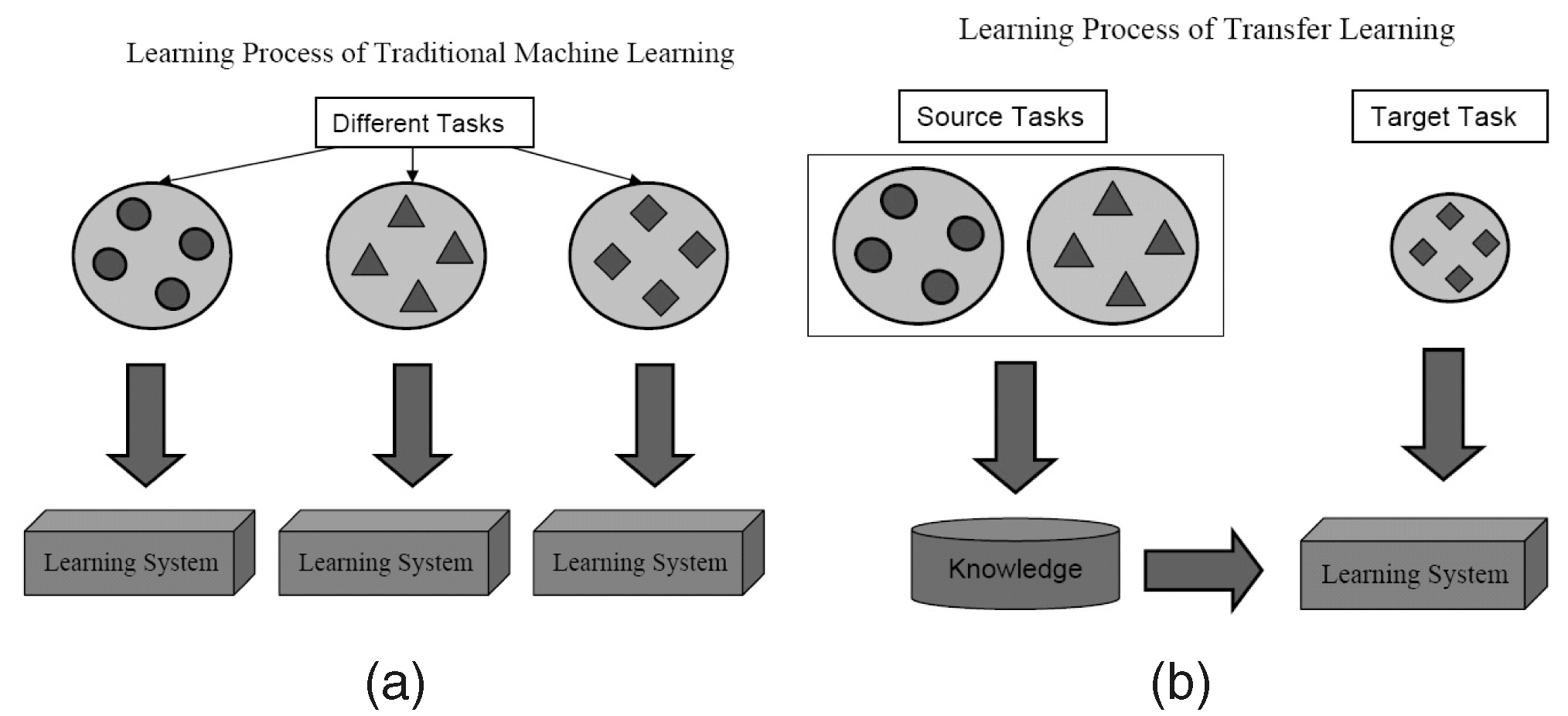
ما هذا؟
كما يوحي الاسم ، يتم نقل التعلم من مهمة إلى أخرى ضمن نفس الخوارزمية في Transfer Learning. يمكن نقل الخوارزميات المدربة على مهمة واحدة (مهمة المصدر) مع مجموعة بيانات أكبر مع أو بدون تعديل كجزء من خوارزمية تحاول تعلم مهمة مختلفة (مهمة مستهدفة) على مجموعة بيانات أصغر (نسبيًا).
بعض الأمثلة
يعد استخدام معلمات خوارزمية تصنيف الصور كمستخرج ميزة في مهام مختلفة مثل اكتشاف الكائنات تطبيقًا بسيطًا لـ Transfer Learning. في المقابل ، يمكن استخدامه أيضًا لأداء المهام المعقدة. تم تطوير الخوارزمية التي طورتها Google لتصنيف اعتلال الشبكية السكري بشكل أفضل من الأطباء في وقت ما باستخدام Transfer Learning. من المثير للدهشة أن كاشف اعتلال الشبكية السكري كان في الواقع مصنفًا حقيقيًا للصور (مصنف صور كلب / قطة) نقل التعلم لتصنيف عمليات مسح العين.
اخبرني المزيد!
ستجد علماء البيانات يتصلون بهذه الأجزاء المنقولة من الشبكات العصبية من المصدر إلى المهمة المستهدفة مثل الشبكات المدربة مسبقًا في أدبيات التعلم العميق. الضبط الدقيق هو عندما يتم إعادة نشر أخطاء المهمة المستهدفة بشكل معتدل في الشبكة سابقة التدريب بدلاً من استخدام الشبكة سابقة التدريب غير المعدلة. يمكن الاطلاع على مقدمة فنية جيدة لـ Transfer Learning in Computer Vision هنا. يعتبر هذا المفهوم البسيط للتعلم الانتقالي مهمًا جدًا في مجموعتنا من منهجيات التعلم الفعال.
موصى به لك:

كيف ستحول Metaverse صناعة السيارات الهندية

ماذا يعني توفير مكافحة الربح بالنسبة للشركات الهندية الناشئة؟

كيف تساعد الشركات الناشئة في تكنولوجيا التعليم في تطوير مهارات القوى العاملة في الهند وتصبح جاهزة للمستقبل ...

الأسهم التقنية في العصر الجديد هذا الأسبوع: مشاكل Zomato مستمرة ، EaseMyTrip تنشر Stro ...

تتخذ الشركات الهندية الناشئة اختصارات في مطاردة للتمويل

منصة التسويق الرقمي Logicserve Bags INR 80 Cr Funding، Rbrands as LS Dig ...
التعلم متعدد المهام
ما هذا؟
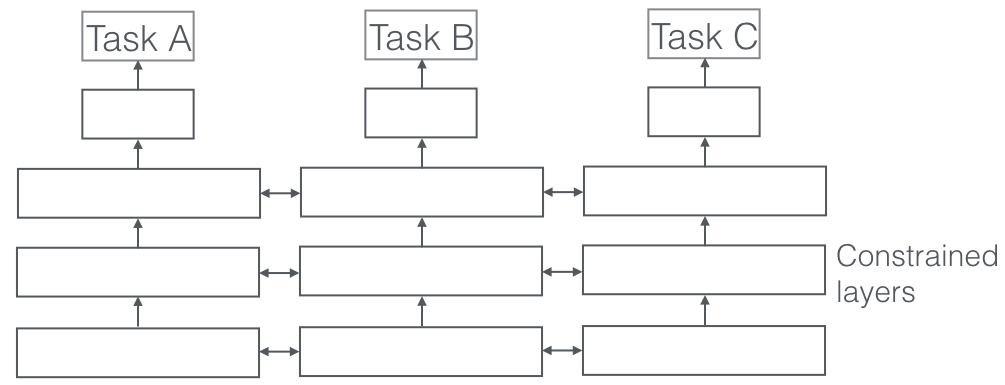

في التعلم متعدد المهام ، يتم حل مهام التعلم المتعددة في نفس الوقت ، مع استغلال القواسم المشتركة والاختلافات عبر المهام. إنه أمر مثير للدهشة ، ولكن في بعض الأحيان يمكن أن يؤدي تعلم مهمتين أو أكثر معًا (تسمى أيضًا المهمة الرئيسية والمهام المساعدة) إلى تحسين النتائج للمهام. يرجى ملاحظة أنه لا يمكن اعتبار كل زوج أو ثلاثي أو رباعي من المهام بمثابة مساعدة. ولكن عندما تعمل ، فهي زيادة مجانية في الدقة.
بعض الأمثلة
على سبيل المثال ، في ParallelDots ، تم تدريب مصنفات المشاعر والنية واكتشاف المشاعر لدينا على أنها تعلم متعدد المهام مما زاد من دقتها مقارنة بما إذا كنا قد قمنا بتدريبهم بشكل منفصل. إن أفضل نظام لوسم الأدوار الدلالية وعلامات نقاط البيع في البرمجة اللغوية العصبية الذي نعرفه هو نظام التعلم متعدد المهام ، لذلك فهو أحد أفضل الأنظمة للتجزئة الدلالية والمثيلات في رؤية الكمبيوتر. ابتكرت Google متعلمين متعددي المهام متعدد الوسائط (نموذج واحد لحكمهم جميعًا) يمكنهم التعلم من مجموعات البيانات البصرية والنصية في نفس اللقطة.
اخبرني المزيد!
أحد الجوانب المهمة جدًا في التعلم متعدد المهام الذي يظهر في تطبيقات العالم الحقيقي هو المكان الذي يتم فيه تدريب أي مهمة لتصبح مقاومة للرصاص ، فنحن بحاجة إلى احترام العديد من بيانات المجالات التي تأتي من (وتسمى أيضًا تكيف المجال). سيكون أحد الأمثلة في حالات استخدام القطط والكلاب لدينا عبارة عن خوارزمية يمكنها التعرف على صور من مصادر مختلفة (مثل كاميرات VGA وكاميرات HD أو حتى كاميرات الأشعة تحت الحمراء). في مثل هذه الحالات ، يمكن إضافة خسارة إضافية لتصنيف المجال (من أين أتت الصور) إلى أي مهمة ثم يتعلم الجهاز أن الخوارزمية تستمر في التحسن في المهمة الرئيسية (تصنيف الصور إلى صور قط أو كلب) ، ولكن تعمد أن تزداد سوءًا في المهمة الإضافية (يتم ذلك عن طريق إعادة نشر تدرج الخطأ العكسي من مهمة تصنيف المجال). الفكرة هي أن الخوارزمية تتعلم السمات التمييزية للمهمة الرئيسية ، لكنها تنسى الميزات التي تميز المجالات وهذا سيجعلها أفضل. يعد التعلم متعدد المهام وأبناء عمومته للتكيف مع المجال أحد أكثر تقنيات التعلم الفعال نجاحًا التي نعرفها ولدينا دور كبير نلعبه في تشكيل مستقبل الذكاء الاصطناعي.
التعلم العدائي
ما هذا؟
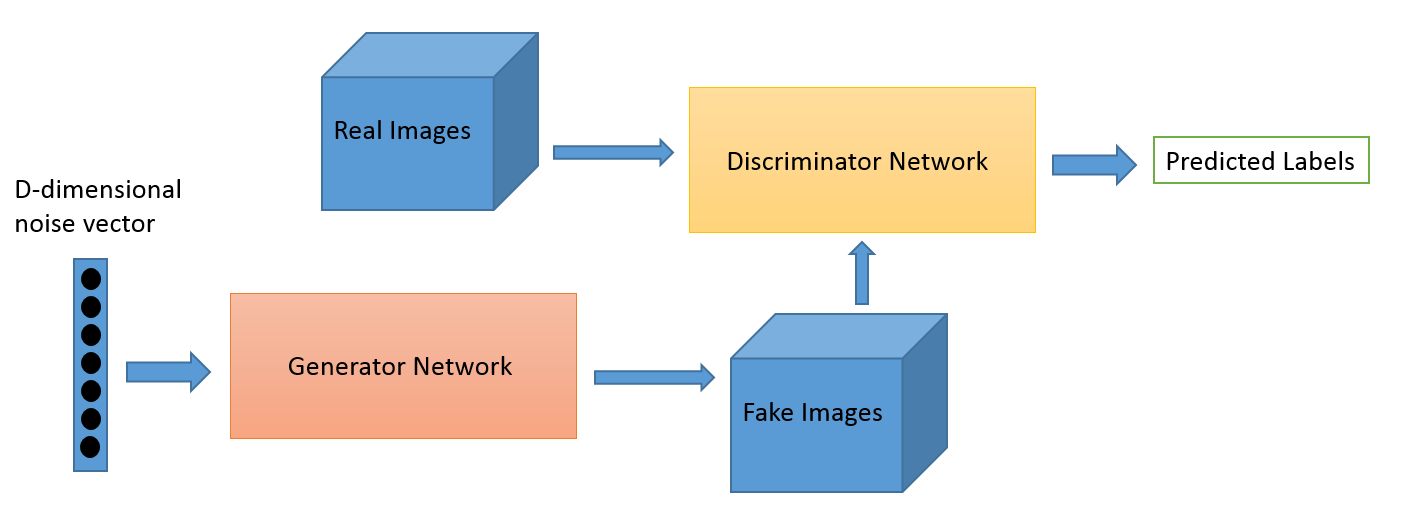
التعلم العدائي كمجال تطور من العمل البحثي لإيان جودفيلو. في حين أن التطبيقات الأكثر شيوعًا للتعلم العدائي هي بلا شك شبكات الخصومة التوليدية (GANs) التي يمكن استخدامها لإنشاء صور مذهلة ، إلا أن هناك عدة طرق أخرى لهذه المجموعة من التقنيات. عادةً ما يكون لهذه التقنية المستوحاة من نظرية اللعبة خوارزميتان: مولد ومميز ، هدفهما خداع بعضهما البعض أثناء التدريب. يمكن استخدام المولد لإنشاء صور جديدة كما ناقشنا ، ولكن يمكنه أيضًا إنشاء تمثيلات لأي بيانات أخرى لإخفاء التفاصيل من أداة التمييز. هذا الأخير هو سبب أهمية هذا المفهوم لنا.
بعض الأمثلة
هذا مجال جديد وقدرة توليد الصور هي على الأرجح ما يركز عليه معظم الأشخاص المهتمين مثل علماء الفلك. لكننا نعتقد أن هذا سيطور حالات استخدام أحدث أيضًا كما قلنا لاحقًا.
اخبرني المزيد!
يمكن تحسين لعبة تكييف المجال باستخدام خسارة GAN. الخسارة الإضافية هنا هي نظام GAN بدلاً من تصنيف المجال الخالص ، حيث يحاول المميّز تصنيف المجال الذي جاءت منه البيانات ويحاول مكون المولد خداعه من خلال تقديم ضوضاء عشوائية كبيانات. في تجربتنا ، يعمل هذا بشكل أفضل من التكيف مع المجال العادي (وهو أيضًا أكثر انحرافًا في الكود).
قليل من التعلم بالرصاص
ما هذا؟
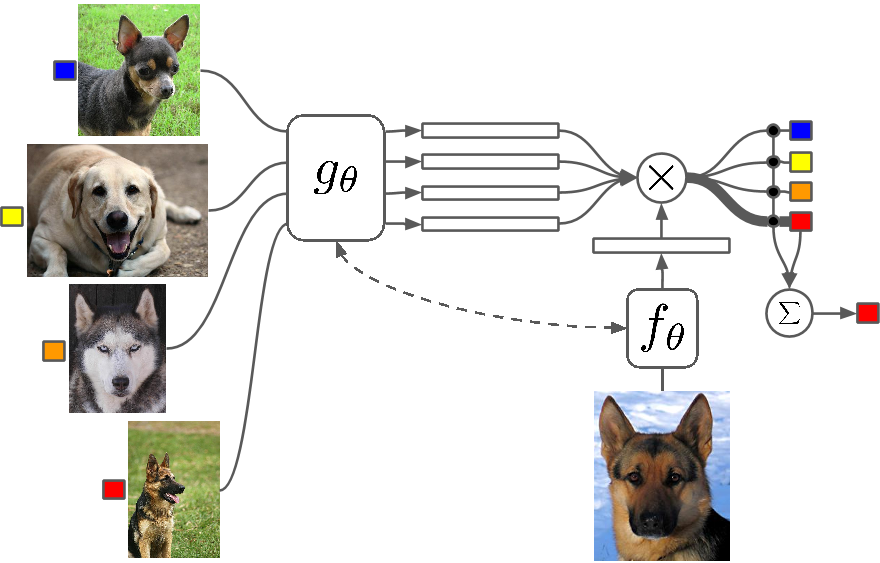
قليل من التعلم بالرصاص هو دراسة للتقنيات التي تجعل خوارزميات التعلم العميق (أو أي خوارزمية للتعلم الآلي) تتعلم بعدد أقل من الأمثلة مقارنة بما ستفعله الخوارزمية التقليدية. يتعلم One Shot Learning بشكل أساسي باستخدام مثال واحد لفئة ، ويعني التعلم الاستقرائي k-shot التعلم باستخدام أمثلة k لكل فئة.
بعض الأمثلة
يشهد عدد قليل من Shot Learning كمجال تدفق الأوراق في جميع مؤتمرات التعلم العميق الرئيسية وهناك الآن مجموعات بيانات محددة لقياس النتائج على أساسها ، تمامًا مثل MNIST و CIFAR للتعلم الآلي العادي. يرى التعلم بلقطة واحدة عددًا من التطبيقات في مهام معينة لتصنيف الصور مثل اكتشاف الميزات والتمثيل.
اخبرني المزيد!
هناك العديد من الطرق التي يتم استخدامها للتعلم باستخدام طلقة قليلة ، بما في ذلك نقل التعلم والتعلم متعدد المهام بالإضافة إلى التعلم التلوي باعتباره كل أو جزء من الخوارزمية. هناك طرق أخرى مثل وظيفة الخسارة الذكية ، أو استخدام البنى الديناميكية أو استخدام قرصنة التحسين. تعلم Zero Shot ، وهو فئة من الخوارزميات التي تدعي التنبؤ بإجابات الفئات التي لم ترها الخوارزمية حتى ، هي في الأساس خوارزميات يمكن توسيع نطاقها باستخدام نوع جديد من البيانات.
ميتا التعلم
ما هذا؟

التعلم الفوقي هو بالضبط ما يبدو عليه ، خوارزمية تتدرب بحيث ، عند رؤية مجموعة بيانات ، ينتج عنها متنبئ جديد لتعلم الآلة لمجموعة البيانات المحددة هذه. التعريف مستقبلي للغاية إذا أعطيته نظرة أولى. تشعر "قف! هذا ما يفعله عالم البيانات "وهو يعمل على أتمتة" أكثر الوظائف جاذبية في القرن الحادي والعشرين "، وفي بعض النواحي ، بدأ المتعلمون الفائقون في القيام بذلك.
بعض الأمثلة
أصبح Meta-Learning موضوعًا ساخنًا في Deep Learning مؤخرًا ، مع صدور الكثير من الأوراق البحثية ، والأكثر شيوعًا باستخدام تقنية المعلمة الفائقة وتحسين الشبكة العصبية ، وإيجاد بنى شبكات جيدة ، والتعرف على الصور قليلة اللقطات ، والتعلم السريع التعزيز.
اخبرني المزيد!
يشير بعض الأشخاص إلى هذه الأتمتة الكاملة لتحديد كل من المعلمات والمعلمات الفائقة مثل بنية الشبكة مثل autoML وقد تجد أشخاصًا يشيرون إلى Meta Learning و AutoML كحقول مختلفة. على الرغم من كل الضجيج حولهم ، فإن الحقيقة هي أن Meta Learners لا يزالون خوارزميات ومسارات لتوسيع نطاق التعلم الآلي مع تزايد تعقيد البيانات وتنوعها.
معظم أوراق التعلم الفوقية عبارة عن اختراقات ذكية ، والتي وفقًا لويكيبيديا لها الخصائص التالية:
- يجب أن يشتمل النظام على نظام تعليمي فرعي يتكيف مع الخبرة.
- تُكتسب الخبرة من خلال استغلال المعرفة الوصفية المستخرجة إما في حلقة تعليمية سابقة على مجموعة بيانات واحدة أو من مجالات أو مشاكل مختلفة.
- يجب اختيار تحيز التعلم ديناميكيًا.
النظام الفرعي هو في الأساس إعداد يتكيف عندما يتم تقديم البيانات الوصفية لمجال (أو مجال جديد تمامًا) إليه. يمكن لهذه البيانات الوصفية أن تخبرنا عن العدد المتزايد للفئات ، والتعقيد ، والتغيير في الألوان والقوام والكائنات (في الصور) ، والأنماط ، وأنماط اللغة (اللغة الطبيعية) وغيرها من الميزات المماثلة. تحقق من بعض الأوراق الرائعة هنا: التسلسلات الهرمية المشتركة للتعليم التلوي والتعلم التلوي باستخدام التلافيف المؤقتة. يمكنك أيضًا إنشاء خوارزميات Few Shot أو Zero Shot باستخدام معماريات Meta-Learning. تعد Meta-Learning واحدة من أكثر التقنيات الواعدة التي ستساعد في تشكيل مستقبل الذكاء الاصطناعي.
التفكير العصبي
ما هذا؟

التفكير العصبي هو الشيء الكبير التالي في مشاكل تصنيف الصور. الاستدلال العصبي هو خطوة أعلى من التعرف على الأنماط حيث تتحرك الخوارزميات إلى ما وراء فكرة مجرد تحديد وتصنيف النص أو الصور. يحل الاستدلال العصبي أسئلة أكثر عمومية في تحليلات النص أو التحليلات المرئية. على سبيل المثال ، تمثل الصورة أدناه مجموعة من الأسئلة التي يمكن أن يجيب عليها الاستدلال العصبي من صورة.
اخبرني المزيد!
ستظهر هذه المجموعة الجديدة من التقنيات بعد إصدار مجموعة بيانات bAbi على Facebook أو مجموعة بيانات CLEVR الأخيرة. تمتلك التقنيات التي يتم التوصل إليها لفك رموز العلاقات وليس الأنماط فقط إمكانات هائلة لحل ليس فقط الاستدلال العصبي ولكن أيضًا العديد من المشكلات الصعبة الأخرى بما في ذلك مشاكل تعلم قليلة.
العودة
الآن بعد أن عرفنا ما هي التقنيات ، دعنا نعود ونرى كيف حلوا المشاكل الأساسية التي بدأنا بها. يعطي الجدول أدناه لمحة عن قدرات تقنيات التعلم الفعال لمواجهة التحديات:
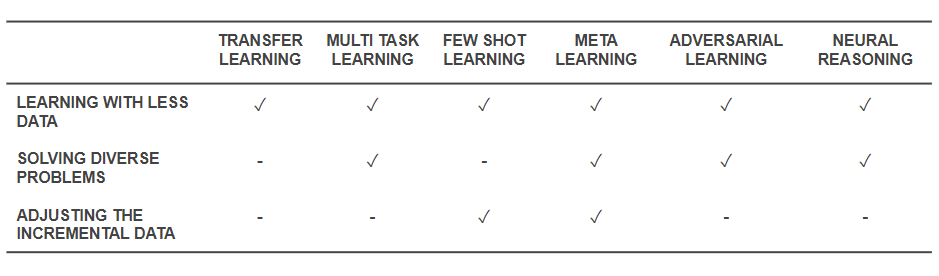
قدرات تقنيات التعلم الفعال
- تساعد جميع التقنيات المذكورة أعلاه في حل التدريب بكمية أقل من البيانات بطريقة أو بأخرى. في حين أن Meta-Learning سيعطي بنيات من شأنها أن تتشكل فقط مع البيانات ، فإن Transfer Learning يجعل المعرفة من بعض المجالات الأخرى مفيدة للتعويض عن بيانات أقل. قليل من Shot Learning مكرس لهذه المشكلة كنظام علمي. يمكن أن يساعد التعلم الخصوم في تحسين مجموعات البيانات.
- يساعد تكييف المجال (نوع من التعلم متعدد المهام) ، والتعلم الخصامي و (أحيانًا) بنى التعلم التلوي في حل المشكلات الناشئة عن تنوع البيانات.
- يساعد التعلم التلوي وقليل من التعلم بالرصاص في حل مشاكل البيانات المتزايدة.
- تتمتع خوارزميات الاستدلال العصبي بإمكانيات هائلة لحل مشكلات العالم الواقعي عند دمجها كمتعلمين متعددين أو متعلمين قليلين.
يرجى ملاحظة أن تقنيات التعلم الفعال هذه ليست تقنيات جديدة للتعلم العميق / التعلم الآلي ، ولكنها تزيد من التقنيات الحالية مثل الاختراقات مما يجعلها أكثر فائدة. وبالتالي ، ستظل ترى أدواتنا المعتادة مثل الشبكات العصبية التلافيفية و LSTMs قيد التشغيل ، ولكن مع التوابل المضافة. يمكن أن تساعد تقنيات التعلم الفعال هذه التي تعمل مع بيانات أقل وتؤدي العديد من المهام أثناء التنقل في تسهيل إنتاج وتسويق المنتجات والخدمات التي تعمل بالذكاء الاصطناعي. في ParallelDots ، ندرك قوة التعلم الفعال ودمجها كأحد السمات الرئيسية لفلسفتنا البحثية.
ظهر هذا المنشور من قبل Parth Shrivastava لأول مرة على مدونة ParallelDots وتم إعادة إنتاجه بإذن.