
فهم خوارزميات البرمجة اللغوية العصبية من Google لتحسين المحتوى وتحسين محركات البحث
نشرت: 2022-06-04
تعد معالجة اللغات الطبيعية ، أو NLP ، أحد أكثر التطورات تعقيدًا وابتكارًا في مجال الذكاء الاصطناعي (AI) وخوارزميات محرك البحث. وليس من المستغرب أن تصبح Google رائدة في مجال البرمجة اللغوية العصبية. مع إضافة 2021 لخوارزمية SMITH وخوارزمية اللغة الطبيعية السابقة ، BERT ، طورت Google ذكاءً اصطناعيًا يفهم اللغة البشرية بكفاءة. ولهذه التقنية القدرة على استخدامها في إنشاء المحتوى الذي يتم إنشاؤه بواسطة الذكاء الاصطناعي.
بدقة استثنائية ، غيرت خوارزميات البرمجة اللغوية العصبية من Google لعبة الذكاء الاصطناعي. إذن ، ماذا يعني هذا بالنسبة إلى مُحسّنات محرّكات البحث؟ ستتعمق هذه المقالة في جميع تفاصيل تقنيات البرمجة اللغوية العصبية من Google وكيف يمكنك استخدامها للحصول على ترتيب أفضل في نتائج محرك البحث.
ما هي معالجة اللغة الطبيعية؟

معالجة اللغة الطبيعية (NLP) هي أحد مجالات علوم الكمبيوتر والذكاء الاصطناعي التي تتضمن دراسة كيفية جعل أجهزة الكمبيوتر تفهم لغة الإنسان. على عكس الأشكال السابقة للذكاء الاصطناعي ، يستخدم البرمجة اللغوية العصبية (NLP) التعلم العميق.
يعتبر البرمجة اللغوية العصبية (NLP) مكونًا مهمًا للذكاء الاصطناعي لأنه يمكّن أجهزة الكمبيوتر من التفاعل مع البشر بطريقة تبدو طبيعية.
على الرغم من أن البرمجة اللغوية العصبية قد يبدو أن الغرض منه هو تحسين نتائج بحث Google وإخراج الكتاب من العمل ، إلا أن هذه التقنية تُستخدم في مجموعة متنوعة من الطرق بخلاف مُحسّنات محرّكات البحث.
فيما يلي الأكثر شيوعًا:
1. تحليل المشاعر: البرمجة اللغوية العصبية التي تقيس المستويات العاطفية للأشخاص لتحديد أشياء مثل رضا العملاء.
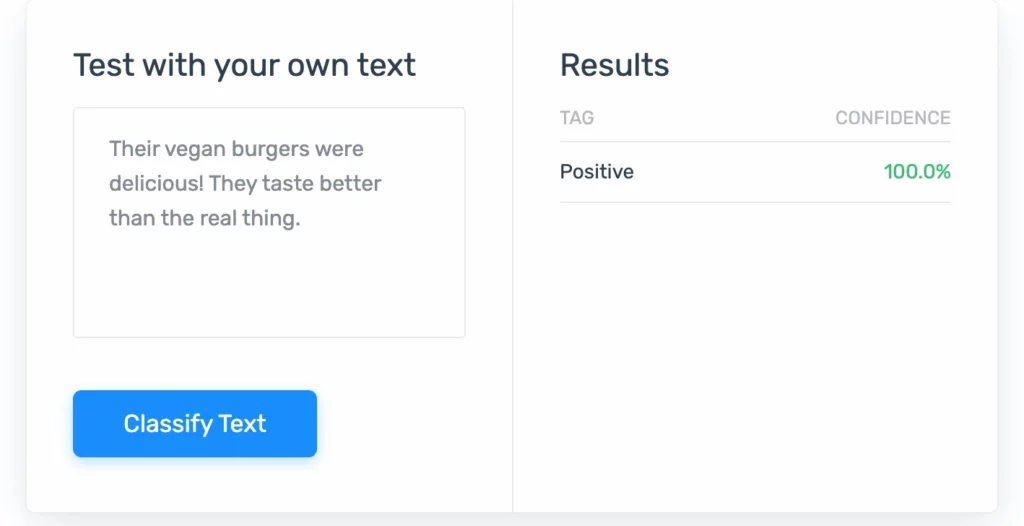
2. روبوتات المحادثة: هذه هي شاشات الدردشة التي تظهر على صفحات المساعدة أو مواقع الويب العامة. لديهم موهبة لتقليل عبء العمل على مراكز دعم العملاء.

4. التعرف على الكلام: هذا البرمجة اللغوية العصبية يأخذ الصوت ويترجمه إلى أوامر وأكثر من ذلك.

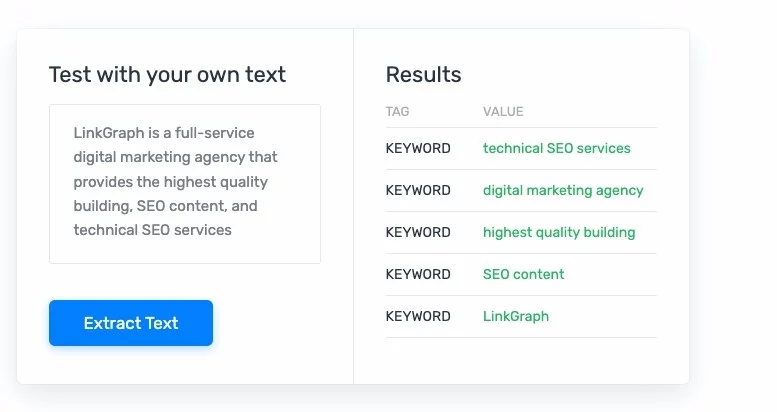
تصنيف النص واستخراجه وتلخيصه: يمكن لهذه الأشكال من البرمجة اللغوية العصبية أن تحلل النص ثم تعيد تنسيقه ليكون أسهل على البشر في استخدامه وتحليله وفهمه. يمكن أن يكون استخراج النص مفيدًا جدًا عندما يتعلق الأمر بمهام مثل الترميز الطبي واكتشاف الأخطاء في الفواتير.
ما هو التعلم العميق؟

التعلم العميق هو فئة من فئات التعلم الآلي التي تم تصميمها على غرار الشبكات العصبية في الدماغ البشري. غالبًا ما يُعتبر هذا الشكل من أشكال التعلم الآلي أكثر تعقيدًا من نماذج التعلم النموذجية للذكاء الاصطناعي.
لأنهم يعكسون الدماغ البشري ، يمكنهم أيضًا عكس السلوك البشري - ويتعلمون الكثير! غالبًا ما تستخدم خوارزميات التعلم العميق نظامًا من جزأين. يقوم أحد النظامين بعمل تنبؤات بينما يقوم الآخر بتحسين النتائج.
تم استخدام التعلم العميق في الأجهزة المنزلية والبيئات العامة ومكان العمل لبعض الوقت. تشمل التطبيقات الأكثر شيوعًا ما يلي:
- سيارات ذاتية القيادة
- أجهزة التحكم عن بعد الصوتية
- كشف الاحتيال في بطاقة الائتمان
- أجهزة طبية
- الدفاع الوطني القائم على الأقمار الصناعية
كيف تؤثر البرمجة اللغوية العصبية على تحسين محركات البحث؟

أدت بعض التحديثات التي تم إجراؤها على نظام ترتيب الصفحات من Google إلى تعطيل معايير تحسين محركات البحث مثل روبوتات معالجة اللغة الطبيعية. مع طرح SMITH من Google ، رأينا متخصصين في تحسين محركات البحث يتدافعون لفهم كيفية عمل الخوارزمية وكذلك كيفية إنتاج محتوى يتوافق مع معايير الخوارزمية. ومع ذلك ، مثل معظم تحديثات الخوارزميات ، غالبًا ما يكشف الوقت عن كيفية تلبية معايير المحتوى وتجاوزها لضمان حصول المحتوى الخاص بك على أفضل فرصة للوصول إلى SERPs.
بشكل أساسي ، تساعد البرمجة اللغوية العصبية (NLP) Google على تزويد الباحثين بنتائج بحث أفضل بناءً على نواياهم وفهم أوضح لمحتوى الموقع. هذا يعني أن المواقع التي تقدم أفضل محتوى فقط احتفظت بمكانتها في SERPs. علاوة على ذلك ، سيتم دفن المحتوى المتنوع الذي لا يوفر نية الباحث في SERP أعمق أو لا يظهر على الإطلاق.
ما هو Google BERT؟

تم طرح خوارزمية BERT (تمثيلات التشفير ثنائية الاتجاه من المحولات) في عام 2019 ، وقد أحدثت الموجات باعتبارها أكبر تغيير منذ PageRank. هذه الخوارزمية عبارة عن معالجة لغوية طبيعية (NLP) تعمل على فهم النص من أجل تقديم نتائج بحث فائقة.
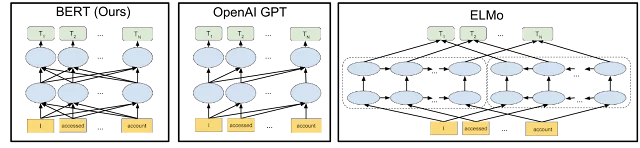
بشكل أكثر تحديدًا ، BERT عبارة عن شبكة عصبية مصممة لفهم سياق الكلمات بشكل أفضل في الجملة. الخوارزمية قادرة على تعلم العلاقات بين الكلمات في الجملة باستخدام تقنية تسمى التدريب المسبق.
الهدف من خوارزمية BERT هو تحسين دقة مهام معالجة اللغة الطبيعية ، مثل الترجمة الآلية والإجابة على الأسئلة.
كيف تعمل خوارزمية Google BERT؟
خوارزمية BERT قادرة على تحقيق هدفها باستخدام تقنية تسمى نقل التعلم. التعلم عن طريق النقل هو تقنية تُستخدم لتحسين دقة الشبكة العصبية باستخدام شبكة مُدرَّبة مسبقًا تم تدريبها بالفعل على مجموعة بيانات كبيرة.
على عكس العديد من تحديثات Google ، فإن أعمال BERT الداخلية مفتوحة المصدر. تستند خوارزمية BERT إلى ورقة نشرتها Google في 2018. يتضمن هذا الشرح مفتوح المصدر أن BERT يستخدم نموذجًا سياقيًا ثنائي الاتجاه لفهم معنى الكلمات أو العبارات الفردية بشكل أفضل. والنتيجة هي تصنيف محتوى مضبوط بدقة.
فمثلا:
إذا كنت تبحث عن شريط لساعة سعيدة مقابل شريط لمعدات ضغط مقاعد البدلاء الخاصة بك ، فستظهر لك Google النوع الصحيح من الشريط بناءً على كيفية استخدام الكلمة في السياق داخل الصفحة.
ما الذي يجعل BERT مختلفًا أيضًا؟
استخدمت BERT وحدات معالجة الموتر السحابية (TPUs) التي سرعت من قدرة البرمجة اللغوية العصبية على التعلم من العينات الموجودة للنص كنظام التدريب المسبق. التدريب المسبق هو تقنية تُستخدم لتدريب شبكة عصبية على مجموعة بيانات كبيرة قبل استخدامها لمعالجة البيانات. ثم يتم استخدام الشبكة سابقة التدريب لمعالجة البيانات التي تشبه البيانات التي تم استخدامها لتدريب الشبكة. باستخدام سحابة TPUs ، كان BERT قادرًا على معالجة البيانات بسرعة فائقة. وتم أيضًا اختبار Google Cloud.
بعد ملايين الجلسات التدريبية ، أصبحت خوارزمية BERT قادرة على تحقيق دقة أعلى من خوارزميات معالجة اللغة الطبيعية السابقة لأنها قادرة على فهم سياق الكلمات بشكل أفضل في الجملة.
كم عدد العينات النصية التي احتاجها BERT؟ استخدم BERT الملايين ، بل المليارات من العينات لفهم اللغة الطبيعية بشكل كامل (وليس اللغة الإنجليزية فقط).
كيف أثر تحديث Google Bert على مواقع الويب؟
كان تأثير تحديث BERT على مواقع الويب ذا شقين. أولاً ، أدى التحديث إلى تحسين دقة نتائج بحث Google. وهذا يعني أن مواقع الويب التي احتلت مرتبة أعلى في نتائج بحث Google شهدت نسبة نقر إلى ظهور أعلى (CTR).

ثانيًا ، أدى تحديث BERT إلى زيادة أهمية محتوى موقع الويب. هذا يعني أن مواقع الويب التي تحتوي على محتوى ذي صلة وعالي الجودة من المرجح أن تحتل مرتبة أعلى في نتائج بحث Google.
ما هي قيود Google Bert؟

BERT هي أداة قوية ، ولكن هناك بعض القيود على قدراتها. في حين أنه من السهل الانشغال بمدى دقة نموذج البرمجة اللغوية العصبية هذا ، من المهم أن تضع في اعتبارك أن نموذج BERT غير قادر على جميع العمليات الإدراكية البشرية. ويمكن أن تكون هذه قيودًا في قدرات فهم المحتوى.
BERT هي خوارزمية نصية فقط
أولاً ، يكون BERT فعالاً فقط لمهام معالجة اللغة الطبيعية التي تتضمن نصًا. لا يمكن استخدامه للمهام التي تتضمن صورًا أو أشكالًا أخرى من البيانات. ومع ذلك ، ضع في اعتبارك أن BERT يمكنه قراءة النص البديل الخاص بك والذي يمكن أن يساعدك في الظهور في عمليات البحث عن الصور من Google.
لا يفهم بيرت "الصورة الكاملة"
ثانيًا ، BERT غير فعال للمهام التي تتطلب درجة عالية جدًا من الفهم. بشكل أساسي ، يعد BERT محترفًا في الكلمات داخل الجمل ، ولكنه غير قادر على فهم المقالات بأكملها.
على سبيل المثال ، يمكن أن يفهم BERT أن "الخفاش" في الجملة التالية يشير إلى الثدييات بدلاً من مضرب بيسبول خشبي: يلتهم الخفاش البعوضة. لكنها ليست فعالة للمهام التي تتطلب فهم جمل أو فقرات معقدة.
ما هي خوارزمية Google SMITH؟

تعد خوارزمية Google SMITH (أو خوارزمية Siamese Multi-Deep Transformer Hierarchical) عبارة عن خوارزمية تصنيف تم تصميمها بواسطة مهندسي Google. تبحث الخوارزمية في اللغة الطبيعية ، وتتعلم أنماط المعنى فيما يتعلق بالعبارات فيما يتعلق ببعدها عن بعضها البعض ، وتخلق تسلسلاً هرميًا للمعلومات يسمح بفهرسة الصفحات بشكل أكثر دقة.
هذا يسمح لـ SMITH بأداء تصنيف المحتوى بشكل أكثر كفاءة.
ميزة أخرى مثيرة للاهتمام في SMITH هي أنه يمكن أن يعمل كمتنبئ للنص. هناك شركات أخرى حققت موجات كبيرة باستخدام البرمجة اللغوية العصبية (فكر في إصدار GPT-3 التجريبي الشهير من Open AI العام الماضي). يمكن لبعض هذه التقنيات أن تساعد الآخرين في بناء محركات البحث الخاصة بهم .
كيف أثر تحديث Google SMITH في مواقع الويب؟
كان لتحديث Google SMITH تأثير كبير على مواقع الويب. تم تصميم التحديث لتحسين دقة نتائج البحث ، وقد تم ذلك من خلال معاقبة المواقع التي كانت تستخدم تقنيات تلاعب للتأثير على ترتيبها. صُممت SMITH لاستهداف مجموعة واسعة من تقنيات التلاعب ، بما في ذلك الروابط غير المرغوب فيها ، وكبار المسئولين الاقتصاديين للقبعة السوداء ، والذكاء الاصطناعي ، وقد رفعت SMITH مستوى جودة المحتوى وبناء الروابط العضوية.
تضمنت بعض تقنيات التلاعب الأكثر شيوعًا التي استهدفتها SMITH
- حشو الكلمات الرئيسية
- شراء الارتباط
- الاستخدام المفرط لنص الرابط.
تمت معاقبة مواقع الويب التي تم اكتشاف أنها تستخدم هذه الأساليب من قِبل Google ، مما أدى إلى انخفاض ترتيب البحث.
ما الفرق بين تحديث Google SMITH و Google BERT؟

يوفر كل من نموذج BERT ونموذج SMITH لزوافي الويب من Google فهمًا أفضل للغة وفهرسة الصفحات. نحن نعلم أن Google تحب بالفعل المحتوى الطويل ، ولكن عندما يكون SMITH مباشرًا ، تفهم Google المحتوى الأطول بشكل أكثر فعالية. ستعمل SMITH على تحسين مجالات توصيات الأخبار وتوصيات المقالات ذات الصلة وتجميع المستندات.
كيفية ضبط إستراتيجية تحسين محركات البحث (SEO) لخوارزميات معالجة اللغات الطبيعية من Google
بينما تدعي Google أنه لا يمكنك التحسين لـ BERT أو SMITH ، فإن فهم كيفية تحسين البرمجة اللغوية العصبية يمكن أن يكون له تأثير على أداء موقعك في SERPs. ومع ذلك ، فإن معرفة أن BERT تركز على توفير نية المستخدم يعني أنه يجب عليك فهم الغرض من أي استعلام بحث تريد تحسينه.
غالبًا ما تكون Google حذرة بعض الشيء عند طرح الخوارزميات الخاصة بهم ، ولا يزالون يتكتمون بشأن متى سيتم طرح SMITH بالكامل. لكن من الأفضل دائمًا افتراض أنهم بدأوا في التحسين من أجل التغيير.
من المحتمل أن تكون SMITH مجرد واحدة من العديد من التكرارات في هدف Google طويل المدى المتمثل في الحفاظ على هيمنتها في البرمجة اللغوية العصبية وتقنية التعلم الآلي. نظرًا لأن Google تعمل على تحسين فهمها للمستندات الكاملة ، فستكون بنية المعلومات الجيدة أكثر أهمية .
كيف يمكنك تحسين المحتوى الخاص بك لخوارزميات البرمجة اللغوية العصبية من Google؟

- تأكد من تنسيق المحتوى الخاص بك بشكل جيد وسهل القراءة. حافظ على أفضل ممارسات العنوان وأفضل ممارسات القراءة الأخرى. وتشمل هذه:
- حافظ على جملك أقل من 20 كلمة
- استخدم قوائم نقطية للعناصر المدرجة الأكبر من 2
- استخدم التسلسل الهرمي الصحيح للعناوين
- تجنب تقديم كتلة نصية غير قابلة للاختراق للقراء
- استخدم لغة واضحة وموجزة يسهل فهمها. لا تُفرط في تعقيد تراكيب الجمل. من خلال الحد من طول الجملة ، من المحتمل أيضًا أن تبسط أفكارك.
- تجنب استخدام الكلمات المعقدة أو الصعبة التي قد تربك خوارزميات Google. تخلص من قاموس المرادفات وحافظ على جملك مباشرة. ضع في اعتبارك أن أقصر الطرق لتحقيق شيء ما هي الأفضل غالبًا.
- استخدم الكلمات الرئيسية ومصطلحات التركيز ذات الصلة بموضوعك . يمكن أن تساعد مصطلحات التركيز ذات الصلة من الناحية الدلالية معالجات اللغة الطبيعية في Google على فهم الصفحة بأكملها بشكل أفضل.
- تأكد من أن المحتوى الخاص بك حديث وحديث. تذكر أن الدافع وراء خوارزميات البرمجة اللغوية العصبية هذه هو تحسين نتائج البحث مع التخلص من المحتوى غير المرغوب فيه والقديم.
- اكتب محتوى شيقًا وجذابًا سيرغب الناس في قراءته. لا يمكنك أبدًا أن تخطئ في تزويد الباحثين بأفضل محتوى يلبي احتياجاتهم . ضع في اعتبارك هدف البحث وعمق الموضوع.
- ملاحظات العملاء مهمة. من المحتمل أن تقوم معالجة البرمجة اللغوية العصبية من Google بإجراء تحليل لمشاعر الكيانات ، لذلك لا تتجاهل المراجعات السيئة. إذا تلقيت مراجعات سلبية (سواء كانت باللغة الإنجليزية أو المريخية) ، فيمكنك المراهنة على أن تحليل مشاعر الكيان من Google سوف يدفعك إلى أسفل SERPs.
- قدم إجابات واضحة لأسئلة الباحثين. إذا كنت تريد أن ينتهي بك الأمر في مقتطف مميز ، فإن البرمجة اللغوية العصبية من Google ستوصلك إلى هناك فقط إذا قمت باستخراج النص باستخدام تحليل الكيان. هذا يعني أن Google لديها القدرة على التركيز على معلومات محددة لعرضها على الباحثين.
مستقبل البرمجة اللغوية العصبية من Google
تتوفر الآن واجهة برمجة تطبيقات اللغة الطبيعية من Google و TPU السحابية ليستخدمها الجميع . لذلك ، إذا كان بإمكانك استخدام نظام أساسي للتعلم الآلي للتعلم العميق لأداء مهام البرمجة اللغوية العصبية (NLP) ، فيمكنك استخدام واجهات برمجة تطبيقات اللغة الطبيعية من Google. يمكنك حتى المشاركة في تدريب Google Cloud NLPs إذا كنت تريد!
تحسين واجهة برمجة تطبيقات اللغة الطبيعية من Google والحصول على النتائج
هناك شيء واحد واضح: واجهات برمجة التطبيقات للغة الطبيعية موجودة لتبقى. كما يمكننا أن نرى من التقدم بين نموذج BERT ونموذج SMITH ، ستستمر خوارزميات بحث Google فقط في فهم المحتوى الخاص بك بشكل أفضل وأفضل.
دع شعارك تظل كما هي: ركز على المحتوى ، ركز على الجودة. بينما ستستمر مُحسّنات محرّكات البحث في التعلم والتجريب لمعرفة ما هو الأفضل لخوارزميات البرمجة اللغوية العصبية من Google ، التزم دائمًا بأفضل الممارسات لتحسين محركات البحث. ضع في اعتبارك أن ما تكتبه سيؤثر على ترتيبك ، ولكن ما يكتبه عملاؤك وزوارك سيكون كذلك بفضل تحليل المشاعر. تعرف على المزيد حول خوارزمية BERT.
تم بناء أداة إنشاء محتوى AI من SearchAtlas على واجهة برمجة تطبيقات اللغة الطبيعية من Google ، بحيث يمكنك إنتاج محتوى عالي الجودة بأقل جهد.