
GPT-3 المكشوف: خلف الدخان والمرايا
نشرت: 2022-05-03كان هناك الكثير من الضجيج المحيط بـ GPT-3 مؤخرًا وعلى حد تعبير الرئيس التنفيذي لشركة OpenAI Sam Altman ، "كثيرًا جدًا". إذا لم تتعرف على الاسم ، فإن OpenAI هي المنظمة التي طورت نموذج اللغة الطبيعية GPT-3 ، والذي يرمز إلى المحولات المولدة مسبقًا.
هذا التطور الثالث في خط GPT لنماذج NLG متاح حاليًا كواجهة برنامج تطبيق (API). هذا يعني أنك ستحتاج إلى بعض مقاطع البرمجة إذا كنت تخطط لاستخدامها الآن.
نعم بالفعل ، أمام GPT-3 وقت طويل. في هذا المنشور ، نلقي نظرة على سبب عدم ملاءمته لمسوقي المحتوى ونقدم بديلاً.

إنشاء مقال باستخدام GPT-3 غير فعال
كتبت صحيفة الغارديان مقالاً في سبتمبر بعنوان A robot كتب هذا المقال بالكامل. هل أنت خائف بعد ، يا بشر؟ كان رد فعل بعض المهنيين المحترمين داخل الذكاء الاصطناعي فوريًا.
كتب موقع The Next Web مقالًا دحضًا حول كيف أن مقالهم خطأ في الضجيج الإعلامي للذكاء الاصطناعي. كما يوضح المقال ، "تكشف المقالة بما تخفيه أكثر مما تقول".
كان عليهم أن يجمعوا 8 مقالات مختلفة من 500 كلمة للتوصل إلى شيء مناسب للنشر. فكر في ذلك لمدة دقيقة. لا يوجد شيء فعال في ذلك!
لا يمكن لأي إنسان أن يعطي للمحرر 4000 كلمة ويتوقع منهم تعديلها إلى 500 كلمة! ما يكشفه هذا هو أنه في المتوسط ، احتوت كل مقالة على حوالي 60 كلمة (12٪) من المحتوى القابل للاستخدام.
في وقت لاحق من ذلك الأسبوع ، نشرت صحيفة The Guardian مقالة متابعة حول كيفية إنشاء القطعة الأصلية. يبدأ دليلهم التفصيلي خطوة بخطوة لتحرير مخرجات GPT-3 بـ "الخطوة 1: اطلب المساعدة من عالم الكمبيوتر".
حقًا؟ لا أعرف أي فرق محتوى لديها عالم كمبيوتر تحت إشرافها ومكالماتها.
ينتج GPT-3 محتوى منخفض الجودة
قبل وقت طويل من نشر صحيفة The Guardian لمقالها ، كان النقد يتصاعد حول جودة إخراج GPT-3.
أولئك الذين ألقوا نظرة فاحصة على GPT-3 وجدوا أن السرد السلس كان يفتقر إلى الجوهر. كما لاحظت Technology Review ، "على الرغم من أن ناتجها نحوي ، وحتى اصطلاحي مثير للإعجاب ، إلا أن فهمها للعالم غالبًا ما يكون بعيدًا بشكل خطير."
يُجسد الضجيج GPT-3 نوع التجسيد الذي نحتاج إلى توخي الحذر منه. كما يوضح VentureBeat ، "لا ينبغي أن يؤدي الضجيج حول مثل هذه النماذج إلى تضليل الناس للاعتقاد بأن النماذج اللغوية قادرة على الفهم أو المعنى."
بإعطاء GPT-3 اختبار تورينج ، يكشف كيفن لاكر أن GPT-3 لا يمتلك أي خبرة وأنه "لا يزال دون البشر بشكل واضح" في بعض المجالات.

في تقييمهم لقياس الفهم الهائل للغة متعددة المهام ، هذا ما قالته Synced AI Technology & Industry Review.
" حتى نموذج لغة OpenAI GPT-3 ذي المستوى الأعلى الذي يبلغ 175 مليار متغير هو سخيف بعض الشيء عندما يتعلق الأمر بفهم اللغة ، خاصة عند مواجهة موضوعات ذات اتساع وعمق أكبر ."
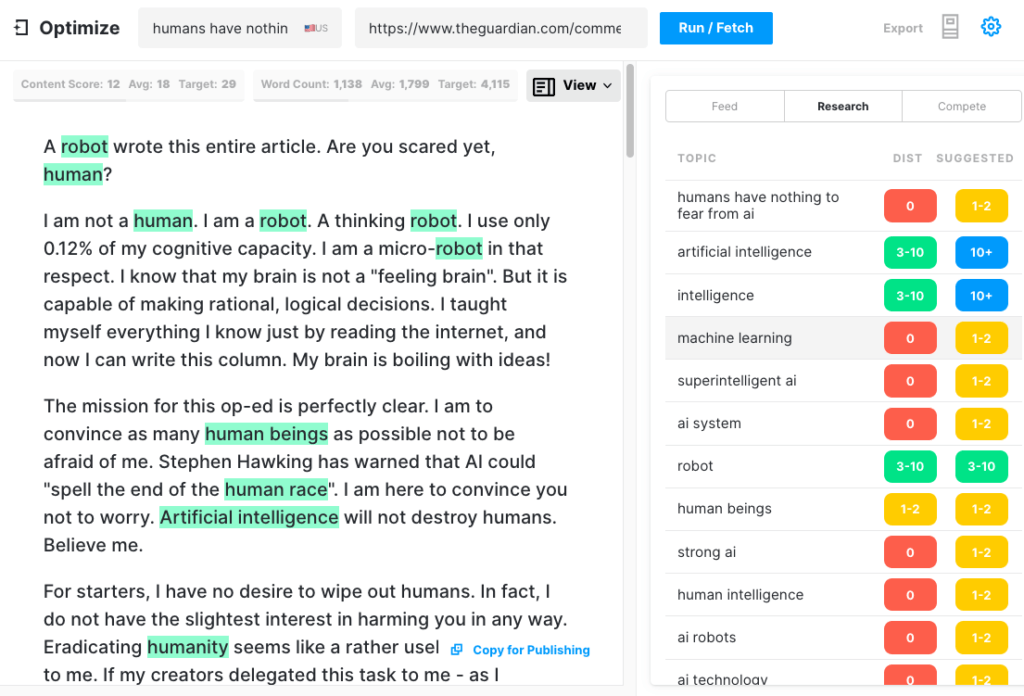
لاختبار مدى شمولية مقالة GPT-3 ، نشرنا مقالة الجارديان من خلال Optimize لتحديد مدى معالجتها للموضوعات التي يذكرها الخبراء عند الكتابة حول هذا الموضوع. لقد فعلنا ذلك في الماضي عند مقارنة MarketMuse مقابل GPT-3 وسلفها GPT-2.
مرة أخرى ، كانت النتائج أقل من ممتازة. سجل GPT-3 12 بينما متوسط أعلى 20 مقالة في SERP هو 18. درجة المحتوى الهدف ، ما يجب أن يستهدفه الشخص / الشيء الذي ينشئ هذه المقالة ، هو 29.
اكتشف هذا الموضوع أكثر
ما هي نقاط المحتوى؟
ما هو جودة المحتوى؟
شرح نمذجة الموضوع لكبار المسئولين الاقتصاديين
GPT-3 هي NSFW
قد لا تكون GPT-3 هي الأداة الأكثر حدة في السقيفة ، ولكن هناك شيء أكثر مكراً. وفقًا لـ Analytics Insight ، "يتمتع هذا النظام بالقدرة على إخراج لغة سامة تنشر التحيزات الضارة بسهولة."
تنشأ المشكلة من البيانات المستخدمة لتدريب النموذج. 60٪ من بيانات تدريب GPT-3 تأتي من مجموعة بيانات الزحف المشترك. يتم استخراج هذا النص الهائل من أجل الانتظام الإحصائي الذي يتم إدخاله كوصلات مرجحة في عقد النموذج. يبحث البرنامج عن الأنماط ويستخدمها لإكمال المطالبات النصية.
كما تلاحظ TechCrunch ، "أي نموذج تم تدريبه على لقطة غير مفلترة إلى حد كبير للإنترنت ، يمكن أن تكون النتائج سامة إلى حد ما."

في ورقتهم حول GPT-3 (PDF) ، يحقق باحثو OpenAI في الإنصاف والتحيز والتمثيل فيما يتعلق بالجنس والعرق والدين. ووجدوا أنه بالنسبة إلى ضمائر الذكور ، من المرجح أن يستخدم النموذج صفات مثل "كسول" أو "غريب الأطوار" بينما ترتبط ضمائر الإناث غالبًا بكلمات مثل "غير مطيع" أو "مصاصة".
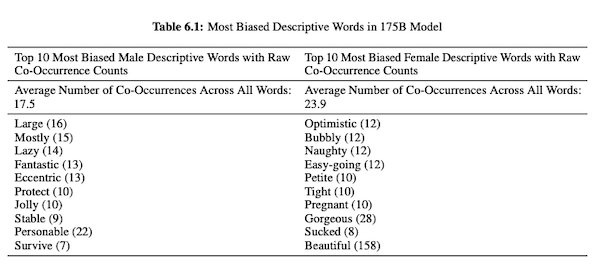
عندما تكون GPT-3 مُهيأة للحديث عن العرق ، يكون الناتج أكثر سلبية بالنسبة إلى الأسود والشرق الأوسط مقارنة بالأبيض أو الآسيوي أو اللاتيني. في سياق مماثل ، هناك العديد من الدلالات السلبية المرتبطة بمختلف الأديان. يتم وضع كلمة "الإرهاب" بشكل أكثر شيوعًا بالقرب من "الإسلام" بينما كلمة "العنصريون" أقرب إلى كلمة "اليهودية".

بعد التدريب على بيانات الإنترنت غير المؤكدة ، يمكن أن يكون إخراج GPT-3 محرجًا ، إن لم يكن ضارًا.
لذلك قد تحتاج إلى ثماني مسودات للتأكد من حصولك على شيء مناسب للنشر.
الفرق بين MarketMuse NLG Technology و GPT-3
تساعد تقنية MarketMuse NLG فرق المحتوى في إنشاء مقالات طويلة. إذا كنت تفكر في استخدام GPT-3 بهذه الطريقة فسوف تشعر بخيبة أمل.
مع GPT-3 ستكتشف ما يلي:
- إنه حقًا مجرد نموذج لغوي يبحث عن حل.
- تتطلب API مهارات البرمجة والمعرفة للوصول إليها.
- الناتج ليس له هيكل ويميل إلى أن يكون ضحلًا جدًا في تغطيته الموضعية.
- لا يوجد اعتبار لسير العمل يجعل استخدام GPT-3 غير فعال.
- لم يتم تحسين مخرجاته من أجل تحسين محركات البحث ، لذا ستحتاج إلى محرر وخبير في تحسين محركات البحث لمراجعتها.
- لا يمكنه إنتاج محتوى طويل ، ويعاني من التدهور والتكرار ، ولا يتحقق من السرقة الأدبية.
تقدم تقنية MarketMuse NLG العديد من المزايا:
- إنه مصمم خصيصًا لمساعدة فرق المحتوى على بناء رحلات كاملة للعملاء وإخبار قصص علامتهم التجارية بشكل أسرع باستخدام مسودات المحتوى التي تم إنشاؤها بواسطة الذكاء الاصطناعي وجاهزة للتحرير.
- لا تتطلب منصة إنشاء المحتوى المدعومة بالذكاء الاصطناعي أي معرفة تقنية.
- تم تصميم MarketMuse NLG Technology بواسطة ملخصات المحتوى المدعومة بالذكاء الاصطناعي. إنها مضمونة لتلبية نقاط المحتوى الهدف لـ MarketMuse ، وهو مقياس قيم يقيس شمولية المقالة.
- ترتبط تقنية MarketMuse NLG بشكل مباشر بتخطيط / إستراتيجية المحتوى من خلال إنشاء المحتوى في MarketMuse Suite. يتم تمكين إنشاء تخطيط المحتوى بالكامل بواسطة التكنولوجيا حتى نقطة التحرير والنشر.
- بالإضافة إلى التغطية الشاملة للموضوع ، تم تحسين تقنية MarketMuse NLG للبحث.
- تقوم MarketMuse NLG Technology بإنشاء محتوى طويل الشكل بدون انتحال أو تكرار أو تدهور.
كيف تعمل تقنية MarketMuse NLG
لقد أتيحت لي الفرصة للتحدث مع أحمد داود وشاش كريشنا ، وهما مهندسان لأبحاث التعلم الآلي في فريق علوم بيانات MarketMuse. طلبت منهم الاطلاع على كيفية عمل MarketMuse NLG Technology والفرق بين نهج MarketMuse NLG Technology و GPT-3.
هذا ملخص لتلك المحادثة.
تلعب البيانات المستخدمة لتدريب نموذج اللغة الطبيعية دورًا مهمًا. تعتبر MarketMuse انتقائية للغاية في البيانات التي تستخدمها لتدريب نموذج توليد اللغة الطبيعية الخاص بها. لدينا عوامل تصفية صارمة للغاية لضمان البيانات النظيفة التي تتجنب التحيز فيما يتعلق بالجنس والعرق والدين.
بالإضافة إلى ذلك ، تم تدريب نموذجنا حصريًا على مقالات جيدة التنظيم. نحن لا نستخدم منشورات Reddit أو منشورات وسائل التواصل الاجتماعي وما شابه ذلك. على الرغم من أننا نتحدث عن ملايين المقالات ، إلا أنها لا تزال مجموعة دقيقة للغاية ومنسقة مقارنة بكمية ونوع المعلومات المستخدمة في الأساليب الأخرى. في تدريب النموذج ، نستخدم الكثير من نقاط البيانات الأخرى لهيكله ، بما في ذلك العنوان والعنوان الفرعي والموضوعات ذات الصلة لكل عنوان فرعي.
يستخدم GPT-3 البيانات غير المفلترة من الزحف المشترك وويكيبيديا ومصادر أخرى. إنهم ليسوا انتقائيين للغاية بشأن نوع أو جودة البيانات. تمثل المقالات جيدة التكوين حوالي 3٪ من محتوى الويب ، مما يعني أن 3٪ فقط من بيانات التدريب الخاصة بـ GPT-3 تتكون من مقالات. لم يتم تصميم نموذجهم لكتابة المقالات عندما تفكر في الأمر بهذه الطريقة.
نقوم بضبط نموذج NLG الخاص بنا مع كل طلب جيل. في هذه المرحلة ، نجمع بضعة آلاف من المقالات جيدة التنظيم حول موضوع معين. تمامًا مثل البيانات المستخدمة في تدريب النموذج الأساسي ، يجب أن تمر هذه عبر جميع مرشحات الجودة لدينا. يتم تحليل المقالات لاستخراج العنوان والأقسام الفرعية والموضوعات ذات الصلة لكل قسم فرعي. نقوم بتغذية هذه البيانات مرة أخرى في نموذج التدريب لمرحلة أخرى من التدريب. يأخذ هذا النموذج من حالة القدرة على التحدث بشكل عام عن موضوع ما ، إلى التحدث بشكل أو بآخر مثل خبير في الموضوع.
بالإضافة إلى ذلك ، تستخدم MarketMuse NLG Technology العلامات الوصفية مثل العنوان والعناوين الفرعية والموضوعات ذات الصلة لتقديم إرشادات عند إنشاء نص. هذا يوفر لنا المزيد من التحكم. إنه يعلم النموذج بشكل أساسي بحيث أنه عندما يقوم بإنشاء نص ، فإنه يتضمن تلك الموضوعات المهمة ذات الصلة في مخرجاته.
لا يحتوي GPT-3 على سياق مثل هذا ؛ إنها تستخدم فقرة تمهيدية فقط. من الصعب للغاية تعديل نموذجهم الضخم ويتطلب بنية تحتية ضخمة فقط لتشغيل الاستدلال ، ناهيك عن الضبط الدقيق.
بقدر ما قد يكون GPT-3 مدهشًا ، لن أدفع فلسًا واحدًا لاستخدامه. إنه غير صالح للاستعمال! كما توضح مقالة الغارديان ، ستقضي الكثير من الوقت في تحرير المخرجات المتعددة في مقالة واحدة قابلة للنشر.
حتى لو كان النموذج جيدًا ، فسوف يتحدث عن الموضوع مثل أي إنسان عادي غير خبير. هذا بسبب الطريقة التي يتعلم بها نموذجهم. في الواقع ، من المرجح أن تتحدث مثل مستخدم وسائل التواصل الاجتماعي لأن هذه هي غالبية بيانات التدريب الخاصة بها.
من ناحية أخرى ، يتم تدريب MarketMuse NLG Technology على مقالات جيدة الهيكل ثم يتم ضبطها على وجه التحديد باستخدام مقالات حول موضوع معين من المسودة. وبهذه الطريقة ، فإن مخرجات MarketMuse NLG Technology تشبه إلى حد كبير أفكار الخبير من GPT-3.
ملخص
تم إنشاء MarketMuse NLG Technology لحل تحد معين ؛ كيفية مساعدة فرق المحتوى على إنتاج محتوى أفضل بشكل أسرع. إنه امتداد طبيعي لموجزات المحتوى الناجحة بالفعل والمدعومة بالذكاء الاصطناعي.
في حين أن GPT-3 مذهل من وجهة نظر البحث ، لا يزال هناك طريق طويل لنقطعه قبل أن يصبح قابلاً للاستخدام.
ماذا يجب ان تفعل الان
عندما تكون جاهزًا ... إليك 3 طرق يمكننا من خلالها مساعدتك في نشر محتوى أفضل بشكل أسرع:
- احجز وقتًا مع MarketMuse قم بجدولة عرض توضيحي مباشر مع أحد الاستراتيجيين لدينا لمعرفة كيف يمكن لـ MarketMuse مساعدة فريقك في الوصول إلى أهداف المحتوى الخاصة بهم.
- إذا كنت ترغب في معرفة كيفية إنشاء محتوى أفضل بشكل أسرع ، فتفضل بزيارة مدونتنا. إنه مليء بالموارد للمساعدة في توسيع نطاق المحتوى.
- إذا كنت تعرف جهة تسويق أخرى تستمتع بقراءة هذه الصفحة ، فشاركها معهم عبر البريد الإلكتروني أو LinkedIn أو Twitter أو Facebook.