
كيفية استخدام البرمجة اللغوية العصبية في تسويق المحتوى
نشرت: 2022-05-02يناقش كريس بن ، المؤسس المشارك لـ Trust Insights ، والمؤسس المشارك لـ MarketMuse ورئيس قسم المنتجات جيف كويل حالة العمل الخاصة بالذكاء الاصطناعي للتسويق. بعد الندوة عبر الويب ، شارك بول في جلسة اسألني أي شيء في مجتمع Slack ، مجموعة إستراتيجية المحتوى (انضم هنا). فيما يلي ملاحظات الندوة متبوعة بنسخة من AMA.

الندوة عبر الإنترنت
المشكلة
مع الانفجار في المحتوى لدينا وسطاء جدد. إنهم ليسوا صحفيين أو مؤثرين على وسائل التواصل الاجتماعي. هم خوارزميات. نماذج التعلم الآلي التي تملي كل ما يقف بينك وبين جمهورك.
فشل في حساب هذا وسيظل المحتوى الخاص بك غارق في الغموض.
الحل: معالجة اللغة الطبيعية
البرمجة اللغوية العصبية هي برمجة أجهزة الكمبيوتر لمعالجة وتحليل كميات كبيرة من بيانات اللغة الطبيعية. يأتي ذلك من المستندات وروبوتات الدردشة ومنشورات الوسائط الاجتماعية والصفحات الموجودة على موقع الويب الخاص بك وأي شيء آخر يمثل في الأساس كومة من الكلمات. جاء البرمجة اللغوية العصبية القائمة على القواعد في المرتبة الأولى ولكن تم استبداله بمعالجة اللغة الطبيعية الإحصائية.
كيف يعمل البرمجة اللغوية العصبية
المهام الأساسية الثلاث لمعالجة اللغة الطبيعية هي التعرف والفهم والتوليد.
التعرف - لا تستطيع أجهزة الكمبيوتر معالجة النصوص مثل البشر. يمكنهم قراءة الأرقام فقط. لذا فإن الخطوة الأولى هي تحويل اللغة إلى تنسيق يستطيع الكمبيوتر فهمه.
الفهم - يتيح تمثيل النص كأرقام للخوارزميات إجراء تحليل إحصائي لتحديد الموضوعات التي يتم ذكرها معًا بشكل متكرر.
الجيل - بعد التحليل والفهم الرياضي ، فإن الخطوة المنطقية التالية في البرمجة اللغوية العصبية هي توليد النص. يمكن استخدام الآلات لإبراز الأسئلة التي يحتاج الكاتب إلى الإجابة عليها ضمن محتواها. على مستوى آخر ، يمكن للذكاء الاصطناعي أن يقود ملخصات المحتوى التي توفر نظرة ثاقبة إضافية لإنشاء محتوى على مستوى الخبراء.
هذه الأدوات متاحة تجاريًا اليوم من خلال MarketMuse. علاوة على ذلك ، توجد نماذج توليد اللغة الطبيعية التي يمكنك اللعب بها اليوم ، ولكنها ليست في شكل قابل للاستخدام تجاريًا. على الرغم من أن MarketMuse NLG Technology ستأتي قريبًا جدًا.
المصادر الإضافية المذكورة
- Huggingface.co
- بايثون
- ص
- كولاب
- استوديو IBM Watson

AMA
هل لديك أي مقالات أو توصيات لمواقع الويب لمواكبة اتجاهات صناعة الذكاء الاصطناعي؟
أن تقرأ البحث الأكاديمي المنشور هناك. تقوم مواقع مثل هذه جميعًا بعمل رائع في تغطية الأحدث والأفضل.
- KDNuggets.com
- نحو علم البيانات
- Kaggle
هذا بالإضافة إلى منشورات بحثية رئيسية في Facebook و Google و IBM و Microsoft و Amazon. سترى الكثير من المواد الرائعة التي تمت مشاركتها على تلك المواقع.
"أنا أستخدم مدقق كثافة الكلمات الرئيسية لجميع المحتويات الخاصة بي. إلى أي مدى بعيدًا عن كونها استراتيجية معقولة اليوم بالنسبة إلى مُحسّنات محرّكات البحث؟ "
كثافة الكلمات الرئيسية هي أساسًا مصطلح حساب التردد. لها مكانها لفهم الطبيعة الخشنة للنص ، لكنها تفتقر إلى أي نوع من المعرفة الدلالية. إذا لم يكن لديك حق الوصول إلى أدوات البرمجة اللغوية العصبية ، فراجع على الأقل أشياء مثل "بحث الأشخاص أيضًا عن" المحتوى في أداة تحسين محركات البحث التي تختارها.
هل يمكنك إعطاء بعض الأمثلة المحددة حول كيفية إنشاء محتوى في… صفحات الويب؟ المشاركات؟ تغريدات؟
التحدي هو أن هذه الأدوات هي بالضبط - إنها أدوات. إنه مثل ، كيف تقوم بتشغيل ملعقة؟ يعتمد ذلك على ما تطبخه. يمكنك استخدامه لتحريك الحساء وتقليب الفطائر أيضًا. تعتمد طريقة البدء ببعض هذه المعرفة على مستوى مهارتك التقنية. إذا كنت مرتاحًا مع دفاتر Python و Jupyter ، على سبيل المثال ، يمكنك استيراد مكتبة المحولات ، وتغذية في ملف نصي للتدريب ، وبدء الإنشاء على الفور. لقد فعلت ذلك بتغريدات أحد السياسيين وبدأت في نشر تغريدات من شأنها أن تبدأ الحرب العالمية الثالثة. إذا لم تكن مرتاحًا من الناحية الفنية ، فابدأ في البحث عن أدوات مثل MarketMuse. سأترك Jeff Coyle يقدم اقتراحات حول كيفية بدء المسوق العادي هناك.
إذا نظرت إلى ما هو أبعد من الأدوات ، ولكن أكثر في الاستراتيجيات ، فما الذي يمكن أن يكون مثالاً على استراتيجية يمكنك تنفيذها للاستفادة من هذه المعرفة؟
هناك زوجان من الضربات السريعة لأشياء مثل الأوصاف التعريفية ، لتصنيف الصفحات أو كتل المحتوى في تصنيف ، أو لمحاولة تخمين الأسئلة التي تحتاج إلى إجابات - ولكن هذه هي بالفعل حلول نقطية. تأتي الحكمة الإستراتيجية الأكبر عندما تستخدم هذا لتظهر لك نقاط قوتك الحالية ، وفجواتك ، وأين لديك الزخم. من هناك ، يصبح اتخاذ القرارات بشأن ما يجب إنشاؤه وتحديثه وتوسيعه أمرًا تحويليًا للأعمال. تخيل الآن أن تفعل الشيء نفسه ضد منافس. إيجاد الثغرات الخاصة بهم. رغوة الصابون تكرار شطف.
تعتمد الإستراتيجية دائمًا على الهدف. ما الهدف الذي تحاول تحقيقه؟ هل تجذب حركة البحث؟ هل تقوم بعمل جيل الرصاص؟ هل تفعل العلاقات العامة؟ البرمجة اللغوية العصبية هي مجموعة من الأدوات. إنه مشابه - الإستراتيجية هي القائمة. هل تقدم وجبة فطور ، غداء ، أم عشاء؟ تعتمد الأدوات والوصفات التي تستخدمها بشكل كبير على القائمة التي تقدمها. لن يكون إناء الحساء مفيدًا إلى حد كبير إذا كنت تصنع سبانكوبيتا.
ما هو مكان الانطلاق الجيد لمن يريد أن يبدأ التنقيب عن البيانات للحصول على رؤى؟
ابدأ بالطريقة العلمية.
- ما السؤال الذي تريد الإجابة عليه؟
- ما هي البيانات والعمليات والأدوات التي تحتاجها للإجابة على هذا السؤال؟
- قم بصياغة فرضية أو شرط واحد أو بيان صواب أو خطأ يمكنك اختباره.
- اختبار.
- تحليل بيانات الاختبار الخاصة بك.
- صقل أو ارفض الفرضية.
بالنسبة للبيانات نفسها ، استخدم إطار عمل بيانات 6C الخاص بنا للحكم على جودة البيانات.
ما هي ، في رأيك ، نوايا مستخدم البحث الرئيسية التي يجب على المسوقين أخذها في الاعتبار؟
خطوات رحلة العميل. ضع خريطة لتجربة العميل من البداية إلى النهاية - الوعي ، الاعتبار ، المشاركة ، الشراء ، الملكية ، الولاء ، الكرازة. ثم حدد النوايا التي من المحتمل أن تكون في كل مرحلة. على سبيل المثال ، عند الملكية ، من المرجح جدًا أن تكون مقاصد البحث موجهة نحو الخدمة. مثال على ذلك "كيفية إصلاح ضوضاء طقطقة airpods pro". يكمن التحدي في جمع البيانات في كل مرحلة من مراحل الرحلة واستخدامها للتدريب / الضبط.
ألا تعتقد أن هذا يمكن أن يكون متقلبًا بعض الشيء؟ إذا كنا بحاجة إلى شيء أكثر استقرارًا لأتمتة العملية ، فنحن بحاجة إلى تعميم الأشياء على مستوى أعلى.
قال جيف بيزوس الشهير ، ركز على ما لا يتغير. لا يتغير المسار العام للملكية كثيرًا - سيختبر أي شخص غير راضٍ عن علبة العلكة الخاصة به أشياءً مماثلة لشخص غير راضٍ عن حاملة الطائرات النووية الجديدة التي طلبها. تتغير التفاصيل ، بالتأكيد ، لكن فهم أنواع البيانات والنوايا أمر حيوي لمعرفة مكان وجود شخص ما ، عاطفياً ، في الرحلة - وكيف ينقلون ذلك باللغة.
ما هي المخاطر المحتملة التي قد يقع فيها الأشخاص عند محاولة تصنيف نية المستخدم؟
إلى حد بعيد ، تحيز التأكيد. سيعرض الأشخاص افتراضاتهم الخاصة على تجربة العميل ويفسرون بيانات العملاء من خلال تحيزاتهم الخاصة. أود أيضًا أن أقترح قدر الإمكان استخدام بيانات التفاعل (رسائل البريد الإلكتروني المفتوحة ، والقدم في الباب ، والمكالمات إلى مركز الاتصال ، وما إلى ذلك) بأفضل ما يمكنك للتحقق من صحتها. أعلم أن بعض الأماكن ، وخاصة المؤسسات الكبيرة ، من أشد المعجبين بنمذجة المعادلات المنظمة لفهم هدف المستخدم. لم أكن معجبًا بقدر ما كانوا ، لكنها طريقة محتملة إضافية.
ما هي الأدوات أو المنتجات التي تعتقد أنها تقوم بعمل جيد في تحديد هدف المستخدم من الاستعلام؟
اللحمة. إلى جانب MarketMuse؟ بصراحة ، كان علي العمل مع أشيائي الخاصة لأنني لم أجد نتائج رائعة ، خاصة من أدوات تحسين محركات البحث (SEO) السائدة. FastText للتحويل الاتجاهي ثم التجميع غير المنظم.
من واقع تجربتك ، كيف غيرت BERT بحث Google؟
مساهمة BERT الأساسية هي السياق ، خاصة مع المعدلات. يسمح BERT لـ Google بمشاهدة ترتيب الكلمات وتفسير المعنى. قبل ذلك ، قد يكون هذان الاستعلاماتان متكافئين وظيفيًا في نموذج نمط كيس من الكلمات:
- أين هو أفضل مقهى
- ما هو أفضل مكان لشراء القهوة
هذان الاستعلامان ، على الرغم من تشابههما الشديد ، يمكن أن يكون لهما نتائج مختلفة تمامًا. قد لا يكون المقهى مكانًا تريد شراء الفول فيه. وول مارت هو بالتأكيد ليس مكانًا تريد أن تشرب فيه القهوة.
هل تعتقد أن الذكاء الاصطناعي أو تكنولوجيا المعلومات والاتصالات سوف يطوران الوعي / العواطف / التعاطف مثل البشر؟ كيف سنبرمجهم؟ كيف يمكننا إضفاء الطابع الإنساني على الذكاء الاصطناعي؟
الجواب على ذلك يعتمد على ما يحدث مع الحوسبة الكمومية. يسمح الكم لحالات ضبابية متغيرة وحوسبة متوازية بشكل كبير تحاكي ما يحدث في أدمغتنا. دماغك هو معالج متوازي ضخم يعتمد على المواد الكيميائية. من الجيد حقًا القيام بمجموعة من الأشياء في وقت واحد ، إن لم يكن بسرعة. سيسمح الكم لأجهزة الكمبيوتر بفعل الشيء نفسه ، ولكن بشكل أسرع بكثير - وهذا يفتح الباب أمام الذكاء الاصطناعي العام. هذا هو قلقي ، وهذا مصدر قلق للذكاء الاصطناعي اليوم ، بالفعل ، في الاستخدام الضيق: نحن ندربهم بناءً علىنا. لم تقم الإنسانية بعمل رائع في علاج نفسها أو التعامل مع الكوكب الذي نعيش عليه بشكل جيد. لا نريد أن تحاكي أجهزة الكمبيوتر الخاصة بنا ذلك.
أظن أنه إلى الحد الذي تسمح به الأنظمة ، ستكون مشاعر الكمبيوتر مختلفة وظيفيًا تمامًا عن عواطفنا وستنظم ذاتيًا من بياناتها ، تمامًا كما تفعل شبكاتنا العصبية القائمة على الكيمياء. وهذا بدوره يعني أنهم قد يشعرون بشكل مختلف تمامًا عما نشعر به. إذا قامت الآلات ، التي تستند أساسًا إلى المنطق والبيانات ، بإجراء تقييم صريح وموضوعي للإنسانية ، فقد تحدد بصراحة أننا مشكلة أكثر مما تستحق. ولن يكونوا مخطئين ، بصراحة. نحن ، كجنس ، فوضى بربرية في معظم الأوقات.
في رأيك ، كيف ترى مسوقي المحتوى يدمجون / يتبنون إنشاء اللغة الطبيعية في سير العمل / العمليات اليومية؟
يجب أن يقوم المسوقون بالفعل بدمج شكل من أشكاله ، حتى لو كان مجرد إجابة على أسئلة مثل التي عرضناها في منتج MarketMuse. تعد الإجابة عن الأسئلة التي تعرف أن الجمهور يهتم بها طريقة سريعة وسهلة لإنشاء محتوى هادف. كتب صديقي ماركوس شيريدان كتابًا رائعًا ، "يسألون ، أنت تجيب" ، ومن المفارقات أنك لست بحاجة إلى قراءته من أجل فهم استراتيجية العميل الأساسية: الإجابة على أسئلة الناس. إذا لم يكن لديك أسئلة تم إرسالها من قبل أشخاص حقيقيين حتى الآن ، فاستخدم NLG لطرحها.

أين ترى تقدم الذكاء الاصطناعي ومعالجة اللغات الطبيعية في العامين المقبلين؟
إذا كنت أعرف ذلك ، فلن أكون هنا ، لأنني سأكون في حصن على قمة جبل اشتريته من أرباحي. ولكن بكل جدية ، فإن المحور الرئيسي الذي رأيناه في العامين الماضيين والذي لا يظهر أي علامة على التغيير هو التقدم من نماذج "دحرجت الخاصة بك" إلى "تنزيل مُدرَّبة مسبقًا وصقلها". أعتقد أننا سنواجه بعض الأوقات المثيرة في الفيديو والصوت حيث تتحسن الآلات في التوليف. توليد الموسيقى ، على وجه الخصوص ، هو RIPE للأتمتة ؛ تولد الآلات حاليًا موسيقى متواضعة تمامًا في أحسن الأحوال وتقرحات الأذن في أسوأ الأحوال. هذا يتغير بسرعة. أرى المزيد من الأمثلة مثل مزج المحولات والمشفرات التلقائية معًا مثلما فعل BART كخطوات رئيسية تالية في تقدم النموذج وأحدث النتائج.
إلى أين تتجه أبحاث Google فيما يتعلق بالاسترجاع المعلوماتي؟
التحدي الذي تواصل Google مواجهته ، وتراه في العديد من أوراقهم البحثية ، هو الحجم. إنهم يواجهون تحديات خاصة مع أشياء مثل YouTube ؛ حقيقة أنهم ما زالوا يعتمدون بشكل كبير على bigrams ليس بمثابة ضربة على تطورهم ، إنه اعتراف بأن أي شيء أكثر من ذلك له تكلفة حسابية مجنونة. لن تكون أي اختراقات كبيرة ناتجة عنها على مستوى النموذج بقدر ما تكون على مستوى المقياس للتعامل مع طوفان من المحتوى الغني الجديد الذي يتم سكبه على الإنترنت كل يوم.
ما هي بعض أكثر تطبيقات الذكاء الاصطناعي إثارة للاهتمام التي صادفتها؟
كل شيء مستقل هو منطقة أراقبها عن كثب. وكذلك المزيفة العميقة. إنها أمثلة على مدى خطورة الطريق أمامنا ، إذا لم نكن حذرين. في البرمجة اللغوية العصبية على وجه التحديد ، يقوم الجيل بخطوات سريعة وهو المجال الذي يجب مراقبته.
أين رأيت أن مُحسّنات محرّكات البحث تستخدم البرمجة اللغوية العصبية بطرق لا تعمل أو لا تعمل؟
لقد فقدت العد. في كثير من الأحيان ، يستخدم الأشخاص أداة بطريقة لم تكن مقصودة ويحصلون على نتائج دون المستوى. كما ذكرنا في الندوة عبر الإنترنت ، هناك بطاقات تسجيل لأحدث الاختبارات المختلفة للنماذج ، والأشخاص الذين يستخدمون أداة في منطقة ليست قوية لا يستمتعون عادةً بالنتائج. ومع ذلك ... لا يستخدم معظم ممارسي تحسين محركات البحث (SEO) أي نوع من معالجة اللغات الطبيعية بصرف النظر عما يقدمه البائعون ، ولا يزال العديد من البائعين عالقين في عام 2015. كل قوائم الكلمات الرئيسية ، طوال الوقت.
أين ترى الفيديو (يوتيوب) والبحث عن الصور في جوجل؟ هل تعتقد أن التقنيات التي نشرتها Google والمستخدمة لجميع أنواع عمليات البحث متشابهة جدًا أو مختلفة عن بعضها البعض؟
جميع تقنيات Google مبنية على بنيتها التحتية وتستخدم تقنيتها. الكثير مبني على TensorFlow ولسبب وجيه - إنه قوي للغاية وقابل للتطوير. حيث تختلف الأشياء في كيفية استخدام Google للأدوات المختلفة. يحتوي TensorFlow للتعرف على الصور على مدخلات وطبقات مختلفة جدًا عن TensorFlow للمقارنة الزوجية ومعالجة اللغة. ولكن إذا كنت تعرف كيفية استخدام TensorFlow والنماذج المختلفة الموجودة هناك ، فيمكنك تحقيق بعض الأشياء الرائعة بنفسك.
ما هي الطرق التي يمكننا بها التكيف / مواكبة التطورات في مجال الذكاء الاصطناعي ومعالجة اللغات الطبيعية؟
استمر في القراءة والبحث والاختبار. ليس هناك بديل عن اتساخ يديك ، على الأقل قليلاً. قم بالتسجيل للحصول على حساب Google Colab مجاني وجرب الأشياء. علم نفسك القليل من بايثون. نسخ ولصق أمثلة التعليمات البرمجية من Stack Overflow. لا تحتاج إلى معرفة كل عمل داخلي لمحرك احتراق داخلي لقيادة السيارة ، ولكن عندما يحدث خطأ ما ، فإن القليل من المعرفة يقطع شوطًا طويلاً. وينطبق الشيء نفسه على الذكاء الاصطناعي ومعالجة اللغات الطبيعية - حتى مجرد القدرة على استدعاء BS على البائع هو مهارة قيمة. إنه أحد الأسباب التي تجعلني أستمتع بالعمل مع أفراد MarketMuse. إنهم يعرفون حقًا ما يفعلونه وعملهم في مجال الذكاء الاصطناعي ليس درجة البكالوريوس.
ماذا ستقول للأشخاص القلقين بشأن تولي الذكاء الاصطناعي وظائفهم؟ على سبيل المثال ، الكتاب الذين يرون تقنية مثل NLG ويخشون أنهم سيكونون عاطلين عن العمل إذا كان الذكاء الاصطناعي يمكن أن يكون "جيدًا بما يكفي" للمحرر لتنظيف النص قليلاً.
"الذكاء الاصطناعي سيحل محل المهام وليس الوظائف" - معهد بروكينغز وهذا صحيح تمامًا. ولكن ستكون هناك وظائف صافية مفقودة ، لأن هذا ما سيحدث. افترض أن وظيفتك تتكون من 50 مهمة. الذكاء الاصطناعي يفعل 30 منهم. رائع ، لديك الآن 20 مهمة. إذا كنت الشخص الوحيد الذي يفعل ذلك ، فأنت في النيرفانا لأن لديك 30 وحدة زمنية أخرى للقيام بعمل أكثر تشويقًا وإمتاعًا. هذا ما يعد به المتفائلون بالذكاء الاصطناعي: التحقق من الواقع: إذا كان هناك 5 أشخاص يقومون بهذه الوحدات الخمسين ، والذكاء الاصطناعي يقوم بـ 30 وحدة ، فإن الذكاء الاصطناعي يقوم الآن بـ 150/250 وحدة عمل. هذا يعني أن هناك 100 وحدة عمل متبقية ليقوم بها الأشخاص ، وبما أن الشركات على ما هي عليه ، فإنها ستقطع على الفور 3 وظائف لأن 100 وحدة عمل يمكن أن يقوم بها شخصان. هل تقلق بشأن تولي الذكاء الاصطناعي وظائف؟ هذا يعتمد على الوظيفة. إذا كان العمل الذي تقوم به متكررًا بشكل لا يصدق ، فلا داعي للقلق. في وكالتي القديمة ، كان هناك شخص فقير كانت وظيفته نسخ ولصق نتائج البحث في جدول بيانات للعملاء (عملت في شركة علاقات عامة ، وليس أكثر الأماكن تقدمًا من الناحية التكنولوجية) 8 ساعات في اليوم. هذه الوظيفة في خطر مباشر ، وبصراحة كان يجب أن تكون لسنوات. كلما كان عملك أقل تكرارًا ، كنت أكثر أمانًا.
أدى كل تغيير أيضًا إلى المزيد والمزيد من عدم المساواة في الدخل. نحن الآن في مرحلة خطيرة حيث الآلات - التي لا تنفق ، ليست مستهلكين - تقوم بالمزيد والمزيد من العمل للأشخاص الذين ينفقون ، والذين يستهلكون بالفعل ، ونرى هذا في هيمنة الثروة الهائلة في التكنولوجيا. هذه مشكلة مجتمعية سيتعين علينا معالجتها في مرحلة ما.
والتحدي في ذلك هو التقدم هو القوة. كما كتب روبرت إنجرسول (ونُسب لاحقًا بشكل خاطئ إلى أبراهام لنكولن): "يمكن لجميع الرجال تقريبًا تحمل الشدائد ، ولكن إذا كنت ترغب في اختبار شخصية الرجل ، فامنحه القوة". نرى كيف يتعامل الناس اليوم مع السلطة.
كيف يمكنني إقران بيانات Google Analytics بأبحاث البرمجة اللغوية العصبية؟
يشير GA إلى الاتجاه ، ثم يشير NLP إلى الإنشاء. ما الشائع؟ لقد فعلت هذا للتو لعميل منذ فترة قصيرة. لديهم الآلاف من صفحات الويب وجلسات الدردشة. استخدمنا GA لتحليل الفئات التي كانت تنمو بشكل أسرع على مواقعهم ، ثم استخدمنا البرمجة اللغوية العصبية لمعالجة سجلات الدردشة هذه لتوضيح ما هو شائع وما يحتاجون إليه لإنشاء محتوى عنه.
برنامج Google Analytics رائع لإخبارنا بما حدث. يمكن أن تبدأ البرمجة اللغوية العصبية في استخلاص القليل من السبب ، ثم نكمل ذلك بأبحاث السوق.
لقد رأيت أنك تستخدم Talkwalker كمصدر بيانات في العديد من دراساتك. ما المصادر وحالات الاستخدام الأخرى التي يجب عليّ مراعاتها للتحليل؟
الكثير جدا. Data.gov. Talkwalker. MarketMuse. Otter.ai لنسخ الصوت الخاص بك. حبات Kaggle. Google Data Search - وهو بالمناسبة GOLD وإذا لم تستخدمه ، فيجب أن تكون كذلك. أخبار Google و GDELT. هناك الكثير من المصادر العظيمة بالخارج
كيف يبدو التعاون المثالي بين فريق التسويق وتحليل البيانات بالنسبة لك؟
لا أمزح؛ من أكبر الأخطاء التي أراها كاتي روبيرت وأنا كل الوقت في العملاء هي الصوامع التنظيمية. ليس لدى اليد اليسرى أي فكرة عما تفعله اليد اليمنى ، وهي فوضى ساخنة في كل مكان. جمع الأشخاص معًا ، ومشاركة الأفكار ، ومشاركة قوائم المهام ، والحصول على مواقف مشتركة ، وتعليم بعضهم البعض - كونك وظيفيًا "فريق واحد ، حلم واحد" هو التعاون المثالي ، إلى الحد الذي لا تحتاج فيه إلى استخدام كلمة تعاون بعد الآن . يعمل الأشخاص معًا فقط ويجمعون كل مهاراتهم على الطاولة.
هل يمكنك مراجعة تقرير MVP الذي تقوم بمعاينته بشكل متكرر في عروضك التقديمية وكيف يعمل؟
يشير تقرير MVP إلى الصفحات الأكثر قيمة. الطريقة التي تعمل بها هي استخراج بيانات المسار من Google Analytics ، وتسلسلها ، ثم وضعها من خلال نموذج سلسلة ماركوف للتأكد من الصفحات التي من المرجح أن تساعد التحويلات.
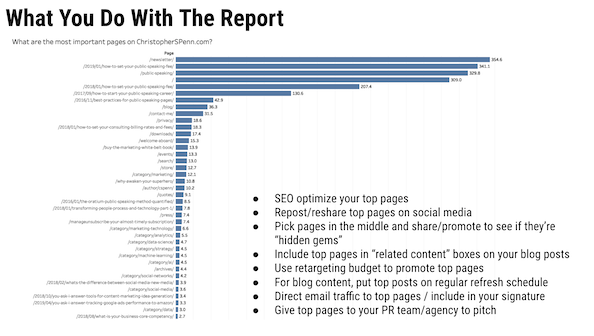
وإذا كنت تريد الشرح الأطول.
هل يمكنك إعطاء مزيد من الأفكار حول تحيز البيانات؟ ما هي بعض الاعتبارات عند بناء نماذج البرمجة اللغوية العصبية أو NLG؟
نعم بالتأكيد. هناك الكثير ليقوله هنا. أولاً ، نحتاج إلى تحديد ماهية التحيز ، لأن هناك نوعين أساسيين.
من المقبول عمومًا تعريف التحيز البشري على أنه "تحيز لصالح شيء ما أو ضده مقارنة بشيء آخر ، عادةً بطريقة تعتبر غير عادلة".
ثم هناك تحيز رياضي ، مقبول بشكل عام لتعريفه على أنه "الإحصاء متحيز إذا تم حسابه بطريقة تختلف منهجياً عن معلمة السكان التي يتم تقديرها."
هم مختلفون لكنهم مرتبطين التحيز الرياضي ليس سيئًا بالضرورة ؛ على سبيل المثال ، تريد تمامًا أن تكون متحيزًا لصالح العملاء الأكثر ولاءً لديك إذا كان لديك أي حس تجاري على الإطلاق. التحيز البشري سيئ ضمنيًا بمعنى عدم الإنصاف ، خاصةً ضد أي شيء يعتبر فئة محمية: العمر ، والجنس ، والتوجه الجنسي ، والهوية الجنسية ، والعرق / الإثنية ، والوضع المخضرم ، والإعاقة ، وما إلى ذلك. هذه هي الفئات التي يجب ألا تفعلها تميز ضد.
يولد التحيز البشري تحيزًا للبيانات ، عادةً في 6 أماكن: الأشخاص ، والاستراتيجية ، والبيانات ، والخوارزميات ، والنماذج ، والإجراءات. نحن نوظف أشخاصًا متحيزين - ما عليك سوى إلقاء نظرة على الجناح التنفيذي أو مجلس الإدارة للشركة لتحديد ما هو تحيزها. رأيت وكالة علاقات عامة ذات يوم تروج لالتزامها بالتنوع وبنقرة واحدة لفريقها التنفيذي وهم من أصل عرقي واحد ، كل 15 منهم.
يمكنني المضي قدمًا لبعض الوقت حول هذا الموضوع ، لكنني أقترح أن تأخذ دورة قمت بتطويرها حول هذا الموضوع ، في معهد التسويق للذكاء الاصطناعي. فيما يتعلق بنماذج NLG و NLP ، يتعين علينا القيام ببعض الأشياء.
أولاً ، علينا التحقق من صحة بياناتنا. هل يوجد تحيز فيها ، وإذا كان الأمر كذلك ، فهل هو تمييز ضد فئة محمية؟ ثانيًا ، إذا كان تمييزيًا ، فهل من الممكن التخفيف منه ، أم يتعين علينا التخلص من البيانات؟
التكتيك الشائع هو قلب البيانات الوصفية إلى debias. إذا كان لديك ، على سبيل المثال ، مجموعة بيانات 60٪ ذكور و 40٪ إناث ، فأنت تعيد ترميز 10٪ من الذكور للإناث لموازنتها من أجل تدريب النموذج. هذا غير مثالي ولديه بعض المشكلات ، لكنه أفضل من ترك التحيز يركب.
من الناحية المثالية ، قمنا ببناء القابلية للتفسير في نماذجنا التي تسمح لنا بإجراء عمليات تحقق أثناء العملية ، ثم نقوم أيضًا بالتحقق من صحة النتائج (قابلية التفسير) بعد ذلك. كلاهما ضروري إذا كنت تريد أن تكون قادرًا على اجتياز تدقيق يشهد أنك لا تبني تحيزات في نماذجك. Woe هي الشركة التي لديها تفسيرات لاحقة فقط.
وأخيرًا ، فأنت بحاجة ماسة إلى إشراف بشري على فريق متنوع وشامل للتحقق من النتائج. من الناحية المثالية ، تستخدم طرفًا ثالثًا ، ولكن لا بأس من وجود طرف داخلي موثوق. هل يقدم النموذج ونتائجه نتيجة منحرفة أكثر مما قد تحصل عليه من السكان أنفسهم؟
على سبيل المثال ، إذا كنت تنشئ محتوى للأطفال الذين تتراوح أعمارهم بين 16 و 22 عامًا ولم تشاهد ذات مرة مصطلحات مثل deadass أو dank أو low-key وما إلى ذلك في النص الذي تم إنشاؤه ، فقد فشلت في التقاط أي بيانات من جانب الإدخال من شأنها تدريب النموذج على استخدام لغته بدقة.
التحدي الأكبر هنا هو التعامل مع كل ذلك من خلال البيانات غير المهيكلة. هذا هو سبب أهمية النسب. بدون النسب ، لا يمكنك إثبات أنك أخذت عينات من السكان بشكل صحيح. النسب هو توثيقك لماهية مصدر البيانات ، ومن أين أتت ، وكيف تم جمعها ، وما إذا كانت تنطبق عليها أي متطلبات تنظيمية أو إفصاحات.
ماذا يجب ان تفعل الان
عندما تكون جاهزًا ... إليك 3 طرق يمكننا من خلالها مساعدتك في نشر محتوى أفضل بشكل أسرع:
- احجز وقتًا مع MarketMuse قم بجدولة عرض توضيحي مباشر مع أحد الاستراتيجيين لدينا لمعرفة كيف يمكن لـ MarketMuse مساعدة فريقك في الوصول إلى أهداف المحتوى الخاصة بهم.
- إذا كنت ترغب في معرفة كيفية إنشاء محتوى أفضل بشكل أسرع ، فتفضل بزيارة مدونتنا. إنه مليء بالموارد للمساعدة في توسيع نطاق المحتوى.
- إذا كنت تعرف جهة تسويق أخرى تستمتع بقراءة هذه الصفحة ، فشاركها معهم عبر البريد الإلكتروني أو LinkedIn أو Twitter أو Facebook.