
Erzielen von Resilienz mit Warteschlangen: Aufbau eines Systems, das niemals einen Schlag in einer Milliarde überspringt
Veröffentlicht: 2018-12-21Braze verarbeitet täglich Milliarden und Abermilliarden von Ereignissen im Auftrag seiner Kunden, was zu Milliarden von hyperfokussierten, personalisierten Nachrichten führt, die an seine Endbenutzer gesendet werden. Das Versäumnis, eine dieser Nachrichten zu senden, hat Konsequenzen, sei es eine verpasste Quittung oder – noch schlimmer – eine verpasste Benachrichtigung, die einen Benutzer darüber informiert, dass sein Essen fertig ist. Um sicherzustellen, dass diese Schlüsselbotschaften immer korrekt und pünktlich sind, verfolgt Braze einen strategischen Ansatz, wie wir Jobwarteschlangen nutzen.
Was ist eine Jobwarteschlange?
Eine typische Jobwarteschlange ist ein Architekturmuster, bei dem Prozesse Berechnungsjobs an eine Warteschlange senden und andere Prozesse die Jobs tatsächlich ausführen. Dies ist normalerweise eine gute Sache – wenn es richtig verwendet wird, bietet es Ihnen ein Maß an Gleichzeitigkeit, Skalierbarkeit und Redundanz, das Sie mit einem traditionellen Request-Response-Paradigma nicht erreichen können. Viele Mitarbeiter können gleichzeitig verschiedene Jobs in mehreren Prozessen, auf mehreren Maschinen oder sogar in mehreren Rechenzentren für höchste Gleichzeitigkeit ausführen. Sie können bestimmten Worker-Knoten die Arbeit an bestimmten Warteschlangen zuweisen und bestimmte Jobs an bestimmte Warteschlangen senden, sodass Sie Ressourcen nach Bedarf skalieren können. Wenn ein Worker-Prozess abstürzt oder ein Rechenzentrum offline geht, können andere Worker die verbleibenden Jobs ausführen.
Während Sie diese Prinzipien sicherlich anwenden und ein Job-Warteschlangensystem problemlos in einem kleinen Maßstab betreiben können, beginnen sich die Nähte zu zeigen (und platzen sogar), wenn Sie Milliarden und Abermilliarden von Jobs verarbeiten. Werfen wir einen Blick auf einige Probleme, mit denen Braze konfrontiert war, als wir von der Verarbeitung von Tausenden auf Millionen und jetzt Milliarden von Jobs pro Tag gewachsen sind.
Mangelnde Konsistenz ist eine Schwäche
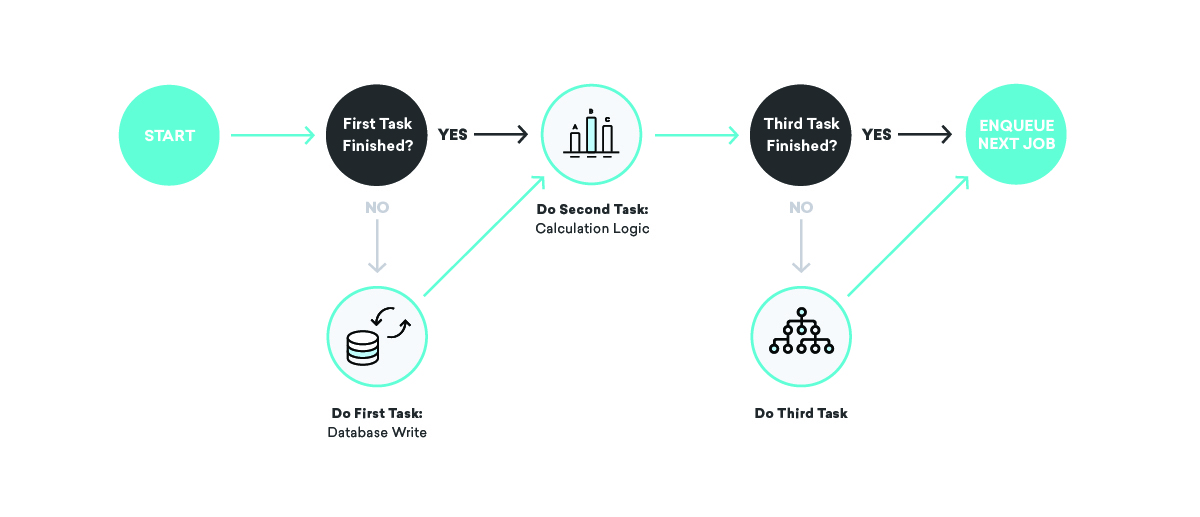
Was passiert, wenn wir eine Nachricht senden, aber wir stürzen ab, bevor wir die Tatsache aufzeichnen, dass wir diese Nachricht gerade gesendet haben?
Hier sind ein paar verschiedene schlechte Ergebnisse möglich. Erstens könnten Sie den fehlgeschlagenen Job neu planen und die Nachricht erneut senden. Das ist … nicht ideal: Niemand möchte dasselbe zweimal erhalten. Ziehen Sie stattdessen in Betracht, es überhaupt nicht zu verschieben. In diesem Fall ist unsere interne Buchhaltung falsch, sodass Zuordnungen, Conversions und alle möglichen anderen Dinge in Zukunft nicht mehr richtig sind.
Wie beheben wir das? Beim Schreiben unserer Jobdefinitionen denken wir sehr intensiv über Idempotenz und Wiederholungsverhalten nach.
Wenn Sie über Warteschlangen sprechen, bedeutet Idempotenz, dass ein einzelner Job an einem beliebigen Punkt beendet werden kann, der erneut in die Warteschlange gestellte Job vollständig neu ausgeführt wird und das Endergebnis dasselbe ist, als hätten wir den Job genau einmal erfolgreich ausgeführt Zeit. Dies ist eng mit unserem gewählten Wiederholungsverhalten verbunden – mindestens einmal Zustellung. Indem wir bedenken, dass alle unsere Jobs mindestens einmal und möglicherweise mehrmals ausgeführt werden, können wir idempotente Jobdefinitionen schreiben, die selbst bei zufälligen Fehlern Konsistenz gewährleisten.
Um auf unser Beispiel zum Senden von Nachrichten zurückzukommen, wie können wir diese Konzepte verwenden, um Konsistenz zu gewährleisten? In diesem Fall könnten wir den Job in zwei Teile aufteilen, wobei der erste die Nachricht sendet und den zweiten in die Warteschlange einreiht und der zweite in die Datenbank schreibt. In diesem Szenario können wir jeden Job so oft wiederholen, wie wir wollen – wenn der Nachrichten sendende Anbieter ausgefallen ist oder die interne Buchhaltungsdatenbank ausgefallen ist, werden wir es entsprechend wiederholen, bis wir erfolgreich sind!
Gute Zäune machen gute Nachbarn
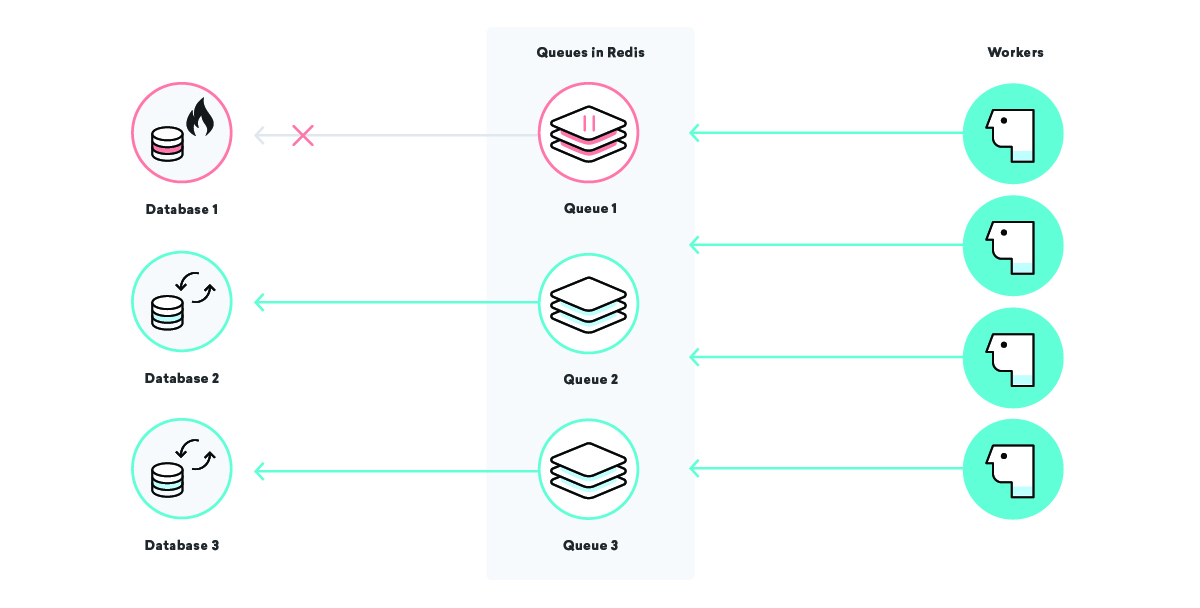
Was passiert mit der Datenverarbeitung unseres Beispielunternehmens Consolidated Widgets, wenn die Datenbank für Global Gizmos ausfällt?
In diesem Szenario würden wir erwarten, dass alle Datenverarbeitungsjobs für Global Gizmos immer wieder neu versucht werden, bis sie erfolgreich sind, wenn unsere Mindestens-einmal-Zustellungsstrategie im Spiel ist. Das ist großartig – wir verlieren keine Daten, selbst wenn ihre Datenbank ausgefallen ist. Für Consolidated Widgets ist es jedoch möglicherweise nicht so toll: Wenn die Worker ständig neue Versuche unternehmen und fehlschlagen, sind sie möglicherweise zu beschäftigt, um die Arbeit von Consolidated Widgets rechtzeitig zu verarbeiten.
Wir können dies beheben, indem wir gut gewählte Warteschlangennamen verwenden und bestimmte Warteschlangen nach Bedarf pausieren. Damit können wir Teile der Infrastruktur chirurgisch entlasten. In unserem obigen Szenario können wir, sobald wir wissen, dass die Datenbank von Global Gizmos ausgefallen ist, ihre Datenverarbeitungswarteschlange anhalten, bis wir wissen, dass sie wieder verfügbar ist, um sicherzustellen, dass ein bestimmter Ausfall keine anderen Kunden beeinträchtigt!

Warten ist schmerzhaft
Was wäre, wenn Consolidated Widgets und Global Gizmos E-Mail-Kampagnen im Abstand von 5 Minuten an jeweils 50 Millionen Benutzer senden würden? Wer geht zuerst?
Einfache Jobwarteschlangensysteme haben eine einfache "Arbeitswarteschlange", aus der Arbeiter Jobs ziehen. Sobald Sie eine schöne Auswahl an verschiedenen Jobs und Jobtypen haben, gehen Sie wahrscheinlich dazu über, mehrere Arten von Warteschlangen zu haben, die jeweils unterschiedliche Prioritäten oder Arten von Mitarbeitern haben, die aus diesen Warteschlangen ziehen. In diesem Sinne haben wir eine Vielzahl einfacher Warteschlangen für Datenverarbeitung, Nachrichtenübermittlung und verschiedene Wartungsaufgaben.
Spulen Sie vor, wenn Sie Milliarden von personalisierten Nachrichten pro Tag senden, eine „Messaging“-Warteschlange reicht nicht aus – was passiert, wenn diese Warteschlange extrem groß wird, wie in unserem obigen Beispiel? Priorisieren wir die Aufträge, die zuerst eingetroffen sind?
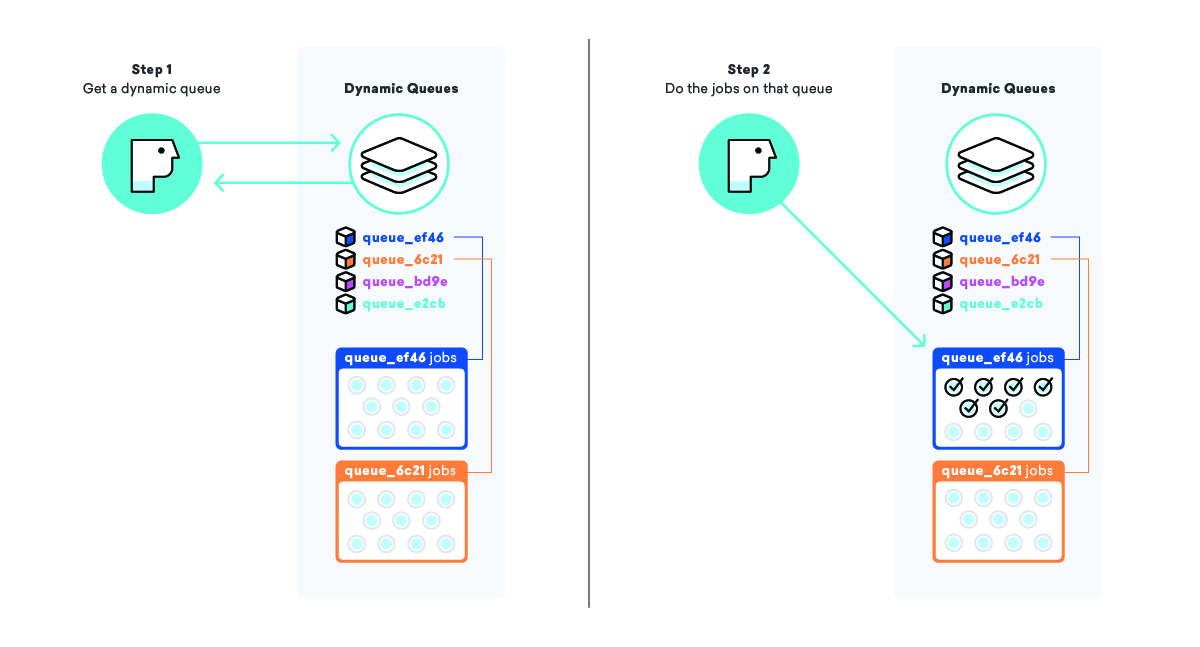
Unser dynamisches Warteschlangensystem versucht, ein Phänomen namens Job-Hunger anzugehen, bei dem ein Job, der zur Ausführung bereit ist, lange Zeit auf seine Ausführung wartet, normalerweise aufgrund einer Art von Priorität. In einer einfachen "Messaging"-Warteschlange ist die Priorität einfach der Zeitpunkt, zu dem der Job in die Warteschlange aufgenommen wurde, was bedeutet, dass Jobs, die am Ende einer großen Warteschlange hinzugefügt werden, sehr lange warten können.
Wenn wir eine Kampagne und alle ihre Nachrichten in die Warteschlange stellen, erstellen wir eine völlig neue Warteschlange nur für diese Kampagne, anstatt die Jobs zu einer großen „Nachrichten“-Warteschlange hinzuzufügen, komplett mit einem speziellen Namen, damit wir wissen, was es ist und wie man es findet. Nachdem wir die Jobs zur Warteschlange hinzugefügt haben, greifen wir unsere Liste „Dynamische Warteschlangen“ und fügen diesen neuen Warteschlangennamen am Ende hinzu.
Durch die Anwendung dieser Strategie können wir Mitarbeiter anweisen, den Namen einer dynamischen Warteschlange aus der Liste „Dynamische Warteschlangen“ zu entnehmen und dann alle Jobs in dieser bestimmten Warteschlange zu verarbeiten. Dadurch können wir sicherstellen, dass Nachrichten so schnell wie möglich gesendet werden UND dass alle unsere Kunden mit der gleichen Priorität behandelt werden.
Folglich hat dies andere Vorteile, wie höhere Cache-Trefferraten und weniger Datenbankverbindungen aufgrund der Zunahme der Arbeitslokalität für bestimmte Arbeiter. Alle gewinnen!
Haben Sie immer einen Backup-Plan
Was passiert, wenn eine Datenbank ausfällt, einige Warteschlangen angehalten werden und sich die Auftragswarteschlangen zu füllen beginnen?
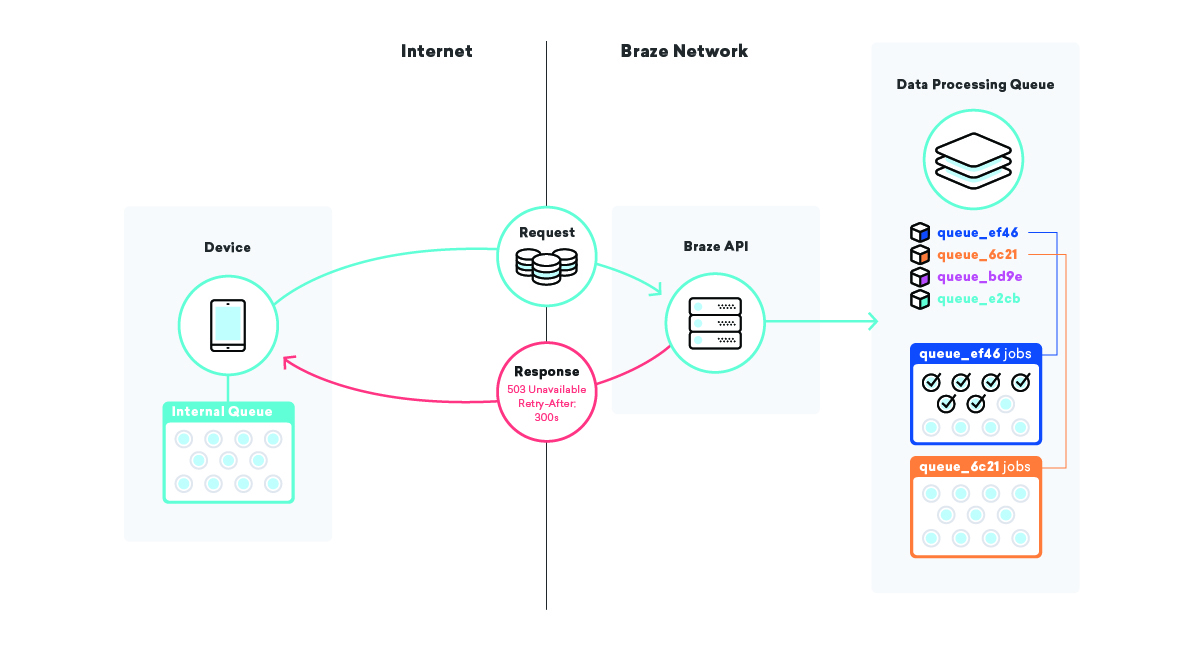
Manchmal sterben wichtige Teile der Infrastruktur einfach an Ihnen. Wir haben Secondaries und Backups eingerichtet, aber die Zeit, die für die Förderung der Backup-Infrastruktur benötigt wird, ist fast nie gleich null. Mehrere Ebenen von Warteschlangen in der gesamten Anwendungsinfrastruktur zu haben, kann sehr hilfreich sein, um die Auswirkungen dieser Art von Ereignissen zu mindern.
Eine solche Strategie, die wir anwenden, ist die Warteschlange auf den Geräten selbst. Millionen und Abermillionen von Geräten haben verschiedene Anwendungen, die ein Braze SDK verwenden, und in diesen Anwendungen verwenden wir eine Warteschlange zum Senden von Daten an unsere APIs.
Wenn unser SDK diese Daten übermittelt und aus irgendeinem Grund fehlschlägt, stellt das SDK einen Wiederholungsversuch mit einem exponentiellen Backoff-Algorithmus in die Warteschlange, bis es erfolgreich ist. Diese Strategie minimiert die Auswirkungen von Infrastruktur- oder Codefehlern, da Geräte einfach ihre eigenen Daten in eine Warteschlange stellen und sie an Braze senden, wenn alles wieder online ist.
Sich schnell bewegen und nichts kaputt machen
Letztendlich ist es unser Ziel, hyperfokussierte, personalisierte Nachrichten besser als jeder andere zu versenden, und dazu gehört, schnell zu handeln, belastbar zu sein und alles richtig zu machen. Jobwarteschlangen sind das Herzstück der Infrastruktur von Braze, daher beobachten wir unsere Leistung ständig, wenden Best Practices an und experimentieren mit neuen Strategien und fortschrittlichen Techniken, um die Besten im Spiel zu sein.
Wenn Sie diese Art von hochleistungsfähigem Systems Engineering mit geringer Latenz im Bereich der Marketingautomatisierung begeistert, dann sollten Sie unbedingt unsere Stellenbörse besuchen!