
Was ist Crawl-Budget und wie wird es optimiert?
Veröffentlicht: 2022-11-25
Ein Crawl-Budget mag wie ein Fremdwort erscheinen, wenn Sie zum ersten Mal lernen, wie Suchmaschinen-Bots funktionieren. Obwohl es nicht das einfachste SEO-Konzept ist, sind sie weniger kompliziert, als es scheint. Sobald Sie anfangen zu verstehen, was ein Crawl-Budget ist und wie Suchmaschinen-Crawling funktioniert, können Sie damit beginnen, Ihre Website zu optimieren, um die Crawlbarkeit zu optimieren. Dieser Prozess trägt dazu bei, dass Ihre Website das höchste Potenzial für eine Platzierung in den Suchergebnissen von Google erreicht.
Was ist ein Crawl-Budget?
Ein Crawl-Budget ist die Anzahl der URLs einer Website, die Suchmaschinen-Bots innerhalb einer Indexierungssitzung indizieren können. Das „Budget“ einer Crawling-Sitzung unterscheidet sich von Website zu Website, basierend auf der Größe jeder einzelnen Website, den Traffic-Metriken und der Seitenladegeschwindigkeit.
Wenn Sie so weit gekommen sind und Ihnen die SEO-Begriffe nicht vertraut sind, verwenden Sie unser SEO-Glossar, um sich mit den Definitionen vertraut zu machen .
Welche Faktoren beeinflussen das Crawling-Budget einer Website?
 Google widmet nicht jeder Website im Internet die gleiche Zeit oder Anzahl von Crawls. Webcrawler bestimmen auch anhand mehrerer Faktoren, welche Seiten sie wie oft crawlen. Sie bestimmen, wie oft und wie lange jede Website gecrawlt werden soll, basierend auf:
Google widmet nicht jeder Website im Internet die gleiche Zeit oder Anzahl von Crawls. Webcrawler bestimmen auch anhand mehrerer Faktoren, welche Seiten sie wie oft crawlen. Sie bestimmen, wie oft und wie lange jede Website gecrawlt werden soll, basierend auf:
- Popularität: Je häufiger eine Website oder Seite besucht wird, desto häufiger sollte sie auf Aktualisierungen analysiert werden. Darüber hinaus erhalten populärere Seiten schneller mehr eingehende Links.
- Größe: Große Websites und Seiten mit datenintensiveren Elementen brauchen länger zum Crawlen.
- Gesundheit/Probleme: Wenn ein Webcrawler durch interne Links in eine Sackgasse gerät, braucht er Zeit, um einen neuen Ausgangspunkt zu finden – oder er bricht den Crawl ab. 404-Fehler, Weiterleitungen und langsame Ladezeiten verlangsamen und blockieren Webcrawler.
Wie wirkt sich Ihr Crawl-Budget auf SEO aus?

Der Indexierungsprozess des Webcrawlers ermöglicht die Suche. Wenn Ihre Inhalte nicht gefunden und dann von den Webcrawlern von Google indexiert werden können, sind Ihre Webseiten und Ihre Website für Suchende nicht auffindbar. Dies würde dazu führen, dass Ihrer Website viel Suchverkehr entgeht.
Warum crawlt Google Websites?
Googlebots gehen systematisch die Seiten einer Website durch, um festzustellen, worum es auf der Seite und der gesamten Website geht. Die Webcrawler verarbeiten, kategorisieren und organisieren Daten von dieser Website Seite für Seite, um einen Cache von URLs zusammen mit ihrem Inhalt zu erstellen, sodass Google bestimmen kann, welche Suchergebnisse als Antwort auf eine Suchanfrage erscheinen sollen.
Außerdem verwendet Google diese Informationen, um zu bestimmen, welche Suchergebnisse am besten zu der Suchanfrage passen, um zu bestimmen, wo jedes Suchergebnis in der hierarchischen Suchergebnisliste erscheinen soll.
Was passiert während eines Crawls?
Google weist einem Googlebot eine bestimmte Zeit zu, um eine Website zu verarbeiten. Aufgrund dieser Einschränkung durchsucht der Bot während einer Durchforstungssitzung wahrscheinlich nicht die gesamte Website. Stattdessen arbeitet es sich basierend auf der robots.txt-Datei und anderen Faktoren (z. B. der Popularität einer Seite) durch alle Seiten der Website.
Während der Crawling-Sitzung verwendet ein Googlebot einen systematischen Ansatz, um den Inhalt jeder verarbeiteten Seite zu verstehen.
Dazu gehört die Indizierung bestimmter Attribute, wie z. B.:
- Meta-Tags und Verwendung von NLP zur Bestimmung ihrer Bedeutung
- Links und Ankertext
- Rich-Media-Dateien für die Bildsuche und Videosuche
- Schema-Markup
- HTML-Markup
Der Webcrawler führt auch eine Überprüfung durch, um festzustellen, ob der Inhalt auf der Seite ein Duplikat einer kanonischen ist. Wenn dies der Fall ist, verschiebt Google die URL nach unten auf eine Crawl-Stufe mit niedriger Priorität, damit die Seite nicht so oft gecrawlt wird.
Was sind Crawling-Rate und Crawling-Nachfrage?
Die Web-Crawler von Google weisen jedem Crawl, den sie durchführen, eine bestimmte Zeit zu. Als Website-Eigentümer haben Sie keine Kontrolle über diese Zeitspanne. Sie können jedoch ändern, wie schnell sie einzelne Seiten Ihrer Website crawlen, während sie sich auf Ihrer Website befinden. Diese Zahl wird als Ihre Crawling-Rate bezeichnet .
Die Crawling-Nachfrage gibt an, wie oft Google Ihre Website crawlt. Diese Häufigkeit basiert auf der Nachfrage Ihrer Website durch Internetnutzer und darauf, wie oft der Inhalt Ihrer Website bei der Suche aktualisiert werden muss. Wie oft Google Ihre Seite crawlt, erfahren Sie anhand einer Logfile-Analyse (siehe Punkt 2 unten).
Wie kann ich das Crawling-Budget meiner Website bestimmen?

Da Google die Häufigkeit und Dauer des Crawlens Ihrer Website begrenzt, möchten Sie wissen, wie hoch Ihr Crawling-Budget ist. Google stellt Website-Eigentümern diese Daten jedoch nicht zur Verfügung – insbesondere dann nicht, wenn Ihr Budget so knapp ist, dass neue Inhalte nicht zeitnah in die SERPs gelangen. Dies kann für wichtige Inhalte und neue Seiten wie Produktseiten katastrophal sein, die Ihnen Geld einbringen könnten.
Um zu verstehen, ob Ihre Website mit Einschränkungen des Crawl-Budgets konfrontiert ist (oder um zu bestätigen, dass Ihre Website OK ist), sollten Sie Folgendes tun: Erhalten Sie eine Bestandsaufnahme, wie viele URLs sich auf Ihrer Website befinden. Wenn Sie Yoast verwenden, wird Ihre Gesamtzahl oben in Ihrer Sitemap-URL aufgeführt .
Wie können Sie Ihr Crawl-Budget optimieren?
Wenn die Zeit kommt, in der Ihre Website zu groß für ihr Crawl-Budget geworden ist, müssen Sie sich mit der Optimierung des Crawl-Budgets befassen. Da Sie Google nicht anweisen können, Ihre Website häufiger oder länger zu crawlen, müssen Sie sich auf das konzentrieren, was Sie kontrollieren können.
Die Optimierung des Crawl-Budgets erfordert einen facettenreichen Ansatz und ein Verständnis der Best Practices von Google . Wo sollten Sie anfangen, wenn es darum geht, das Beste aus Ihrer Crawling-Rate herauszuholen? Diese umfassende Liste ist in hierarchischer Reihenfolge geschrieben, beginnen Sie also oben.
1. Erwägen Sie, das Limit für die Crawling-Rate Ihrer Website zu erhöhen
Google sendet Anforderungen gleichzeitig an mehrere Seiten Ihrer Website. Google versucht jedoch, höflich zu sein und Ihren Server nicht zu verlangsamen, was zu einer langsameren Ladezeit für Ihre Website-Besucher führt. Wenn Sie bemerken, dass Ihre Website aus dem Nichts zurückbleibt, könnte dies das Problem sein.
Um die Erfahrung Ihrer Nutzer zu beeinträchtigen, ermöglicht Ihnen Google, Ihre Crawling-Rate zu reduzieren. Dadurch wird begrenzt, wie viele Seiten Google gleichzeitig indizieren kann.
Interessanterweise erlaubt Google Ihnen jedoch auch, Ihr Crawling-Ratenlimit zu erhöhen – der Effekt ist, dass sie mehr Seiten auf einmal abrufen können, was dazu führt, dass mehr URLs gleichzeitig gecrawlt werden. Alle Berichte deuten jedoch darauf hin, dass Google nur langsam auf eine Erhöhung des Crawling-Ratenlimits reagiert, und es garantiert nicht, dass Google mehr Websites gleichzeitig crawlt.
So erhöhen Sie Ihr Limit für die Crawling-Rate:
- Gehen Sie in der Search Console zu „Einstellungen“.
- Von dort aus können Sie sehen, ob Ihre Crawling-Rate optimal ist oder nicht.
- Dann können Sie das Limit für 90 Tage auf eine schnellere Crawling-Rate erhöhen.
2. Führen Sie eine Protokolldateianalyse durch

Eine Protokolldateianalyse ist ein Bericht des Servers, der jede an den Server gesendete Anfrage widerspiegelt. Dieser Bericht zeigt Ihnen genau, was Googlebots auf Ihrer Website tun. Während dieser Prozess oft von technischen SEOs durchgeführt wird, können Sie mit Ihrem Serveradministrator sprechen, um einen zu erhalten.
Anhand Ihrer Logdatei-Analyse oder Server-Logdatei erfahren Sie:
- Wie oft Google Ihre Website crawlt
- Welche Seiten werden am meisten gecrawlt
- Welche Seiten haben einen nicht reagierenden oder fehlenden Servercode
Sobald Sie diese Informationen haben, können Sie sie verwenden, um Nr. 3 bis Nr. 7 auszuführen.
3. Halten Sie Ihre XML-Sitemap und Robots.txt auf dem neuesten Stand
Wenn Ihre Protokolldatei zeigt, dass Google zu viel Zeit mit dem Crawlen von Seiten verbringt, die nicht in den SERPs erscheinen sollen, können Sie verlangen, dass die Crawler von Google diese Seiten überspringen. Dadurch wird ein Teil Ihres Crawl-Budgets für wichtigere Seiten frei.
Ihre Sitemap (die Sie von Google Search Console oder SearchAtlas erhalten können ) gibt Googlebots eine Liste aller Seiten Ihrer Website, die Google indizieren soll, damit sie in den Suchergebnissen erscheinen können. Wenn Sie Ihre Sitemap mit allen Webseiten, die Suchmaschinen finden sollen, auf dem neuesten Stand halten und diejenigen weglassen, die sie nicht finden sollen, können Webcrawler ihre Zeit auf Ihrer Website maximieren.

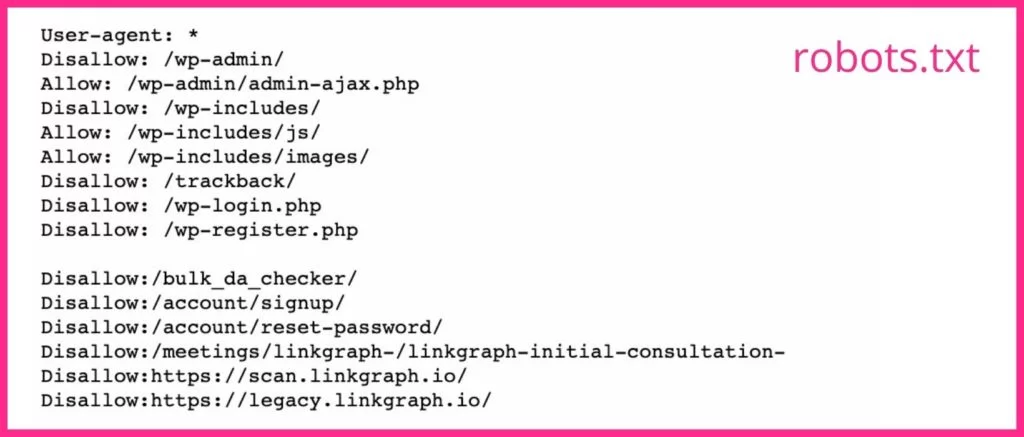
Ihre robots.txt-Datei teilt Suchmaschinen-Crawlern mit, welche Seiten gecrawlt werden sollen und welche nicht . Wenn Sie Seiten haben, die keine guten Zielseiten abgeben, oder Seiten, die mit einem Gate versehen sind, sollten Sie das noindex-Tag für ihre URLs in Ihrer robots.txt-Datei verwenden. Googlebots werden wahrscheinlich jede Webseite mit dem noindex-Tag überspringen.
4. Reduzieren Sie Weiterleitungen und Weiterleitungsketten
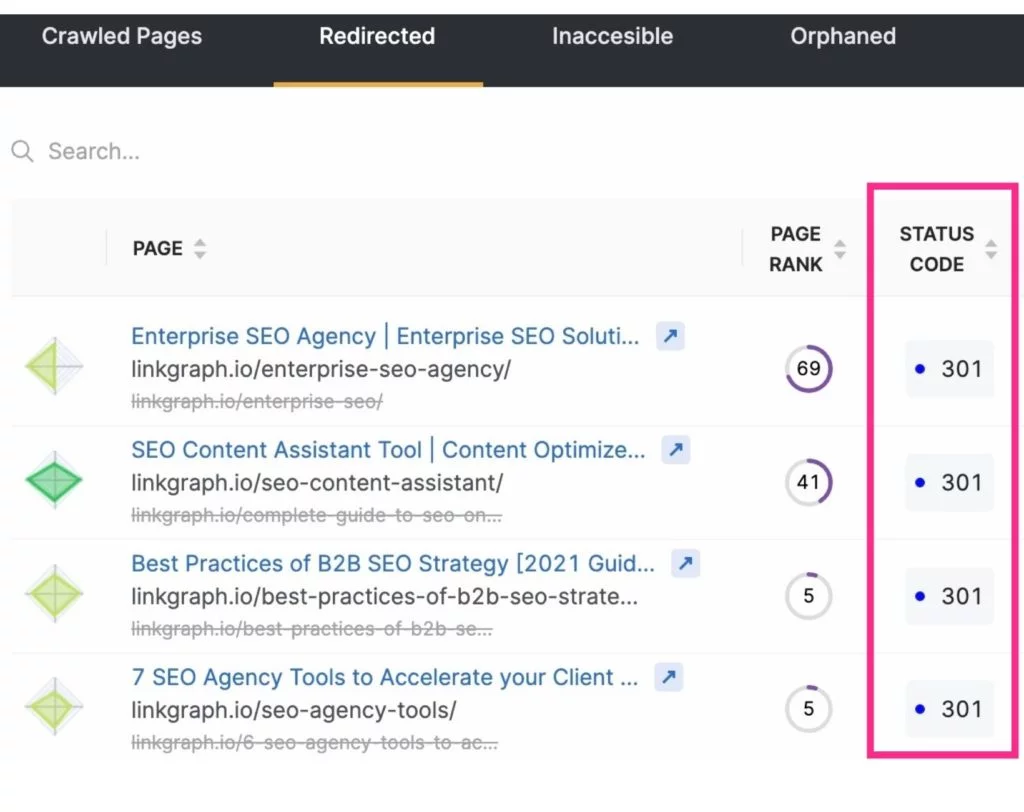
Sie können nicht nur das Crawl-Budget freigeben, indem Sie unnötige Seiten von Suchmaschinen-Crawls ausschließen, sondern auch Crawls maximieren, indem Sie Weiterleitungen reduzieren oder eliminieren. Dies sind alle URLs, die zu einem 3xx-Statuscode führen.
Umgeleitete URLs brauchen länger, um von einem Googlebot abgerufen zu werden, da der Server mit der Umleitung antworten und dann die neue Seite abrufen muss. Während eine Weiterleitung nur wenige Millisekunden dauert, können sie sich summieren. Und das kann dazu führen, dass das Crawlen Ihrer Website insgesamt länger dauert. Diese Zeitspanne wird multipliziert, wenn ein Googlebot auf eine Kette von URL-Weiterleitungen trifft.
Um Weiterleitungen und Weiterleitungsketten zu reduzieren, achten Sie auf Ihre Strategie zur Erstellung von Inhalten und wählen Sie den Text für Ihre Slugs sorgfältig aus.
5. Korrigieren Sie defekte Links
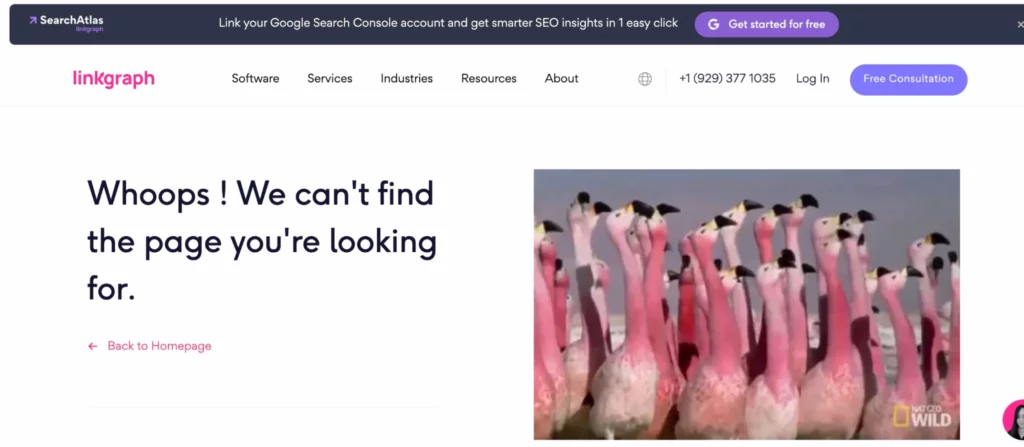
Die Art und Weise, wie Google eine Website häufig erkundet, besteht darin, über Ihre interne Linkstruktur zu navigieren. Während es sich durch Ihre Seiten arbeitet, wird es feststellen, ob ein Link zu einer nicht existierenden Seite führt (dies wird oft als weicher 404-Fehler bezeichnet). Es wird dann weitergehen und keine Zeit mit der Indizierung dieser Seite verschwenden wollen.
Die Links zu diesen Seiten müssen aktualisiert werden, um den Benutzer oder Googlebot auf eine echte Seite zu leiten. ODER (auch wenn es schwer zu glauben ist) der Googlebot hat eine Seite möglicherweise fälschlicherweise als 4xx- oder 404-Fehler identifiziert, obwohl die Seite tatsächlich existiert. Überprüfen Sie in diesem Fall, ob die URL keine Tippfehler enthält, und senden Sie dann eine Crawl-Anfrage für diese URL über Ihr Google Search Console-Konto.
Um bei diesen Crawling-Fehlern auf dem Laufenden zu bleiben, können Sie den Index > Abdeckungsbericht Ihres Google Search Console-Kontos verwenden. Oder verwenden Sie das Site-Audit-Tool von SearchAtlas , um Ihren Site-Fehlerbericht zu finden und an Ihren Webentwickler weiterzuleiten.
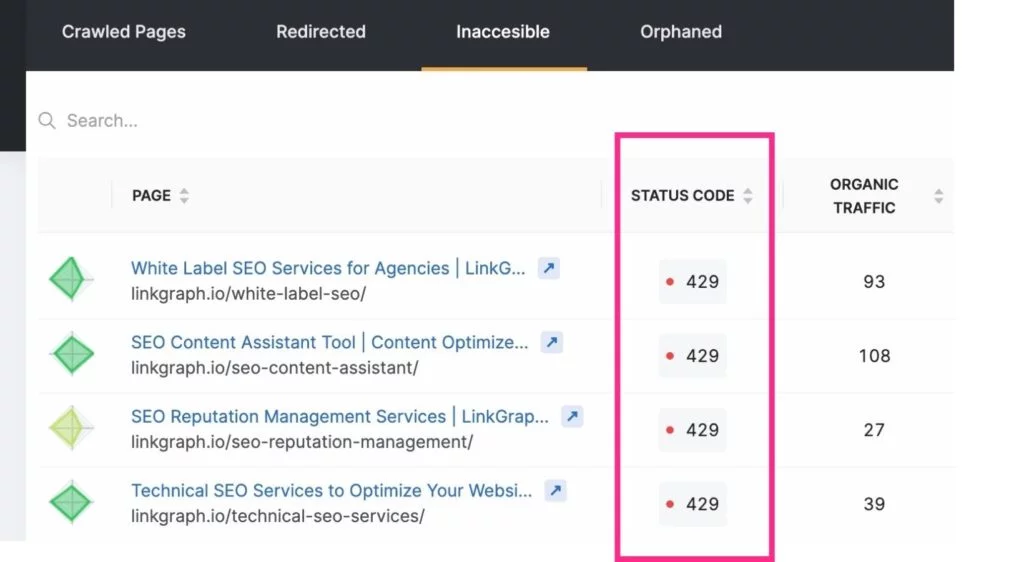
Hinweis: Neue URLs werden möglicherweise nicht sofort in Ihrer Protokolldateianalyse angezeigt. Geben Sie Google etwas Zeit, um sie zu finden, bevor Sie einen Crawl anfordern.
6. Arbeiten Sie an der Verbesserung der Seitenladegeschwindigkeiten
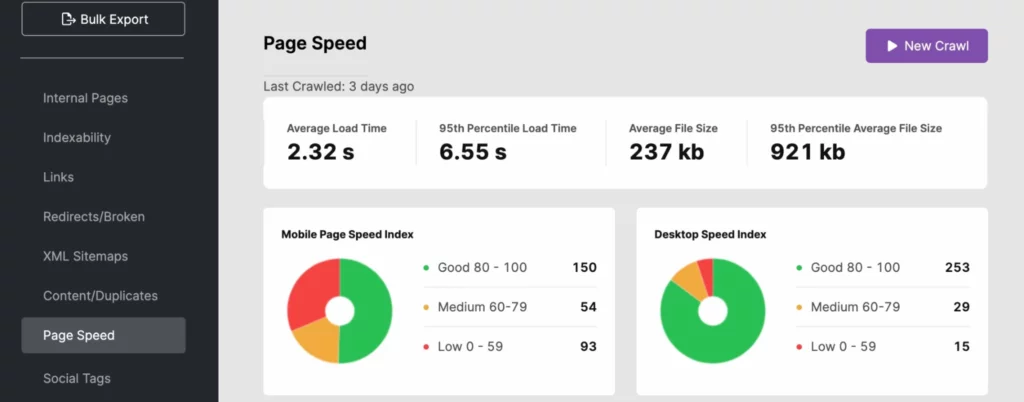
Suchmaschinen-Bots können sich schnell durch eine Website bewegen. Wenn die Geschwindigkeit Ihrer Website jedoch nicht den Anforderungen entspricht, kann dies Ihr Crawl-Budget stark belasten. Verwenden Sie Ihre Logdatei-Analyse, SearchAtlas oder PageSpeedInsights, um festzustellen, ob die Ladezeit Ihrer Website Ihre Sichtbarkeit in den Suchergebnissen negativ beeinflusst.
Um die Antwortzeit Ihrer Website zu verbessern, verwenden Sie dynamische URLs und befolgen Sie die Best Practices von Google Core Web Vitals . Dies kann eine Bildoptimierung für Medien „above the fold“ beinhalten.
Wenn das Problem mit der Site-Geschwindigkeit auf der Serverseite liegt, möchten Sie vielleicht in andere Serverressourcen investieren, wie zum Beispiel:
- Ein dedizierter Server (insbesondere für große Websites)
- Upgrade auf neuere Serverhardware
- Arbeitsspeicher erhöhen
Diese Verbesserungen werden auch Ihre Benutzererfahrung verbessern, was dazu beitragen kann, dass Ihre Website in der Google-Suche besser abschneidet, da die Geschwindigkeit der Website ein Signal für den PageRank ist.
7. Vergessen Sie nicht, kanonische Tags zu verwenden
Duplicate Content wird von Google verpönt – zumindest wenn Sie nicht anerkennen, dass der Duplicate Content eine Quellseite hat. Wieso den? Der Googlebot crawlt jede Seite, es sei denn, dies ist unvermeidlich, sofern er nicht anders angewiesen wird. Wenn es jedoch auf eine doppelte Seite oder eine Kopie von etwas stößt, mit der es vertraut ist (auf Ihrer Seite oder außerhalb der Website), wird das Crawlen dieser Seite beendet. Und während dies Zeit spart, sollten Sie dem Crawler noch mehr Zeit sparen, indem Sie ein kanonisches Tag verwenden, das die kanonische URL identifiziert.

Canonicals weisen den Googlebot an, sich nicht die Mühe zu machen, Ihren Crawl-Zeitraum zu verwenden, um diesen Inhalt zu indexieren. Dies gibt dem Suchmaschinen-Bot mehr Zeit, Ihre anderen Seiten zu untersuchen.
8. Konzentrieren Sie sich auf Ihre interne Linkstruktur
Eine gut strukturierte Verlinkungspraxis auf Ihrer Website kann die Effizienz eines Google-Crawls steigern. Interne Links teilen Google mit, welche Seiten Ihrer Website die wichtigsten sind, und diese Links helfen den Crawlern, Seiten leichter zu finden.
Die besten Verknüpfungsstrukturen verbinden Nutzer und Googlebots mit Inhalten auf Ihrer gesamten Website. Verwenden Sie immer relevanten Ankertext und platzieren Sie Ihre Links auf natürliche Weise in Ihren Inhalten.
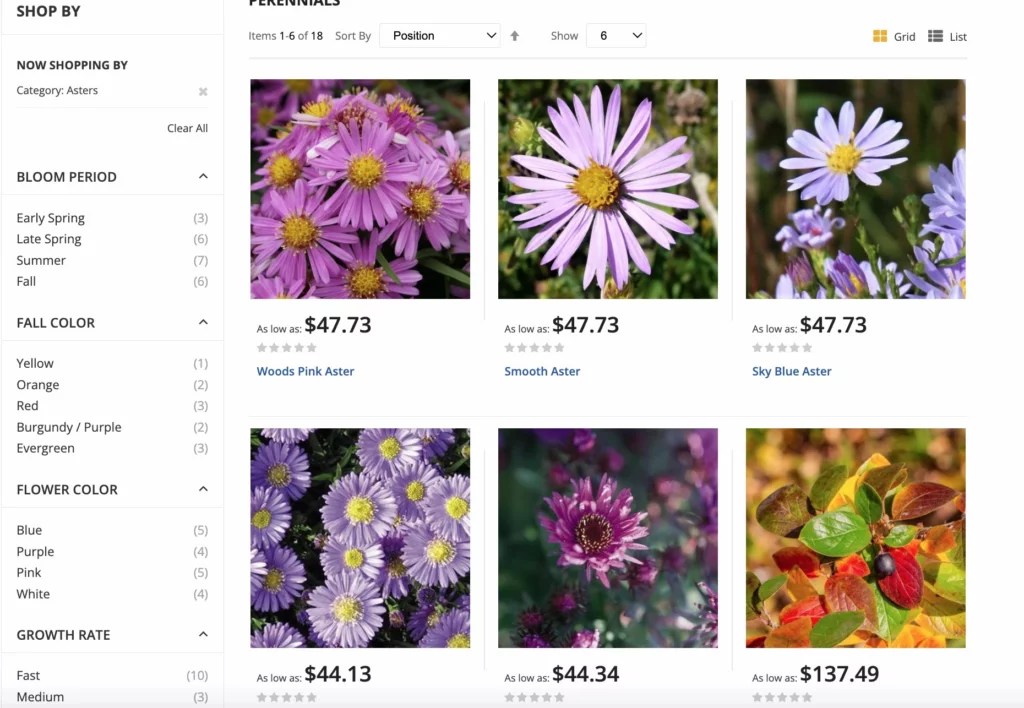
Für E-Commerce-Websites hat Google Best Practices für facettierte Navigationsoptionen zur Maximierung der Crawls. Die Facettennavigation ermöglicht es den Benutzern der Website, Produkte nach Attributen zu filtern, wodurch das Einkaufen zu einem besseren Erlebnis wird. Dieses Update trägt dazu bei, kanonische Verwirrung und doppelte Probleme zusätzlich zu übermäßigen URL-Crawls zu vermeiden.
9. Beseitigen Sie unnötige Inhalte

Googlebots können sich nur so schnell bewegen und jedes Mal, wenn sie eine Website crawlen, so viele Seiten indizieren. Wenn Sie eine große Anzahl von Seiten haben, die keinen Traffic erhalten oder veraltete oder qualitativ minderwertige Inhalte haben, schneiden Sie sie ab! Mit dem Beschneidungsprozess können Sie das überschüssige Gepäck Ihrer Website entfernen, das sie belasten kann.
Wenn Sie zu viele Seiten auf Ihrer Website haben, können Googlebots auf unwichtige Seiten umgeleitet werden, während Seiten ignoriert werden.
Denken Sie nur daran, alle Links auf diese Seiten umzuleiten, damit Sie nicht mit Crawling-Fehlern enden.
10. Sammeln Sie mehr Backlinks
So wie Googlebots auf Ihrer Website ankommen und beginnen, Seiten basierend auf internen Links zu indizieren, verwenden sie auch externe Links im Indexierungsprozess. Wenn andere Websites auf Ihre Website verlinken, wechselt der Googlebot zu Ihrer Website und indiziert Seiten, um die verlinkten Inhalte besser zu verstehen.
Darüber hinaus verleihen Backlinks Ihrer Website etwas mehr Popularität und Aktualität, die Google verwendet, um zu bestimmen, wie oft Ihre Website indiziert werden muss.
11. Beseitigen Sie verwaiste Seiten
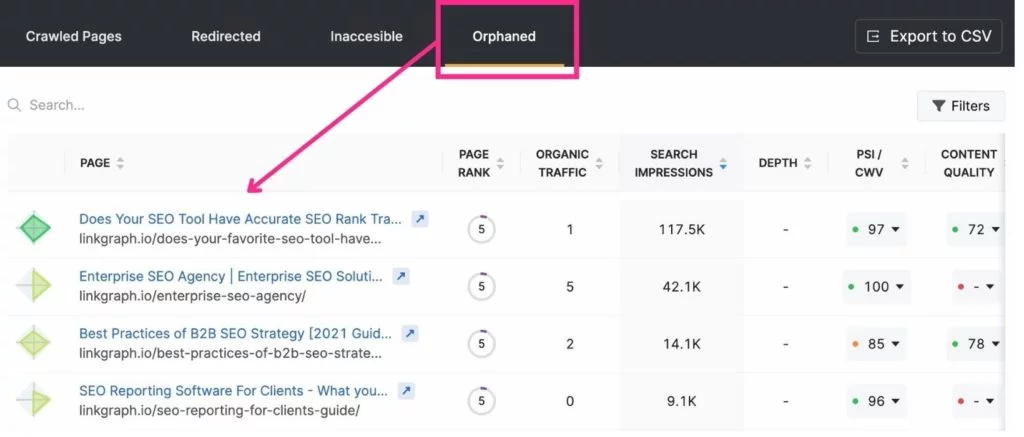
Da der Crawler von Google über interne Links von Seite zu Seite springt, kann er mühelos verlinkte Seiten finden. Allerdings bleiben Seiten, die nicht irgendwo auf Ihrer Website verlinkt sind, von Google oft unbemerkt. Diese werden als „verwaiste Seiten“ bezeichnet.
Wann ist eine verwaiste Seite angebracht? Wenn es sich um eine Zielseite handelt, die einen ganz bestimmten Zweck oder eine bestimmte Zielgruppe hat. Wenn Sie zum Beispiel eine E-Mail mit einer Zielseite, die nur für sie gilt, an Golfer senden, die in Miami leben, möchten Sie möglicherweise nicht von einer anderen Seite auf die Seite verlinken.
Die besten Tools zur Optimierung des Crawl-Budgets
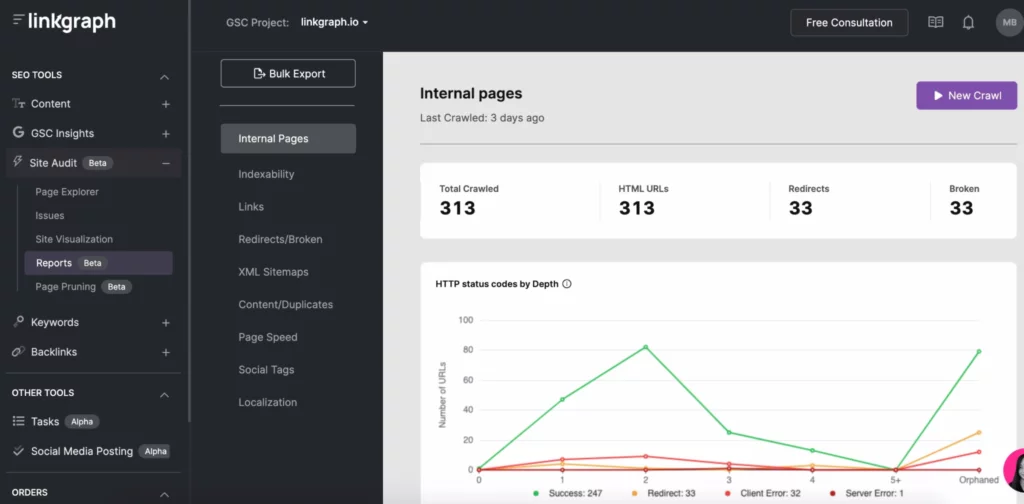
Search Console und Google Analytics können sehr nützlich sein, wenn es darum geht, Ihr Crawl-Budget zu optimieren. Mit der Search Console können Sie einen Crawler anfordern, Seiten zu indizieren und Ihre Crawling-Statistiken zu verfolgen. Google Analytics hilft Ihnen, Ihre interne Verlinkungsreise zu verfolgen.
Andere SEO-Tools wie SearchAtlas ermöglichen es Ihnen, Crawling-Probleme einfach über Site-Audit-Tools zu finden. Mit einem Bericht können Sie Folgendes für Ihre Website anzeigen:
- Indexierbarkeits-Crawling-Bericht
- Indextiefe
- Seitengeschwindigkeit
- Doppelter Inhalt
- XML-Sitemap
- Verknüpfungen
Optimieren Sie Ihr Crawl-Budget und werden Sie zum Suchmaschinen-Top-Performer
Obwohl Sie nicht kontrollieren können, wie oft Suchmaschinen Ihre Website indizieren oder wie lange, können Sie Ihre Website optimieren, um das Beste aus jedem Ihrer Suchmaschinen-Crawls herauszuholen. Beginnen Sie mit Ihren Serverprotokollen und sehen Sie sich Ihren Crawling-Bericht in der Search Console genauer an. Tauchen Sie dann in die Behebung von Crawling-Fehlern, Ihrer Linkstruktur und Problemen mit der Seitengeschwindigkeit ein.
Konzentrieren Sie sich beim Durcharbeiten Ihrer GSC-Crawling-Aktivität auf den Rest Ihrer SEO-Strategie, einschließlich Linkaufbau und Hinzufügen hochwertiger Inhalte . Im Laufe der Zeit werden Sie feststellen, dass Ihre Zielseiten die Ergebnisseiten der Suchmaschinen erklimmen.