
Effektives Lernen: Die nahe Zukunft der KI
Veröffentlicht: 2017-11-09Diese effektiven Lerntechniken sind keine neuen Deep-Learning-/Machine-Learning-Techniken, sondern ergänzen die bestehenden Techniken als Hacks
Es besteht kein Zweifel, dass die ultimative Zukunft der KI darin besteht, die menschliche Intelligenz zu erreichen und zu übertreffen. Aber dies zu erreichen ist eine weit hergeholte Leistung. Selbst die Optimisten unter uns wetten, dass die KI auf menschlicher Ebene (AGI oder ASI) in 10 bis 15 Jahren so weit sein wird, wobei Skeptiker sogar bereit sind zu wetten, dass es Jahrhunderte dauern wird, wenn dies überhaupt möglich ist. Nun, darum geht es in dem Beitrag nicht.
Hier werden wir über eine greifbarere, nähere Zukunft sprechen und die aufkommenden und leistungsfähigen KI-Algorithmen und -Techniken diskutieren, die unserer Meinung nach die nahe Zukunft der KI prägen werden.
KI hat begonnen, Menschen in einigen ausgewählten und spezifischen Aufgaben zu verbessern. Zum Beispiel Ärzte bei der Diagnose von Hautkrebs schlagen und Go-Spieler bei der Weltmeisterschaft besiegen. Aber die gleichen Systeme und Modelle werden bei der Erfüllung der Aufgaben scheitern, die sich von denen unterscheiden, für deren Lösung sie trainiert wurden. Langfristig wird daher ein allgemein intelligentes System, das eine Reihe von Aufgaben effizient und ohne Neubewertung erledigt, als Zukunft der KI bezeichnet.
Aber wie werden Wissenschaftler in der nahen Zukunft der KI, lange bevor der AGI auftaucht, möglicherweise KI-gestützte Algorithmen dazu bringen, die Probleme zu überwinden, mit denen sie heute konfrontiert sind, um aus den Labors herauszukommen und zu alltäglichen Gebrauchsgegenständen zu werden?
Wenn Sie sich umschauen, gewinnt die KI ein Schloss nach dem anderen (lesen Sie unsere Beiträge darüber, wie die KI den Menschen überholt, Teil eins und Teil zwei). Was könnte bei einem solchen Win-Win-Spiel schief gehen? Die Menschen produzieren mit der Zeit immer mehr Daten (die das Futter sind, das die KI verbraucht), und auch unsere Hardwarefähigkeiten werden besser. Schließlich sind Daten und bessere Berechnungen die Gründe, warum die Deep-Learning-Revolution 2012 begann, richtig? Die Wahrheit ist, dass die menschlichen Erwartungen schneller wachsen als Daten und Berechnungen. Datenwissenschaftler müssten sich Lösungen überlegen, die über das hinausgehen, was derzeit existiert, um reale Probleme zu lösen. Zum Beispiel ist die Bildklassifizierung, wie die meisten Leute denken würden, wissenschaftlich ein gelöstes Problem (wenn wir dem Drang widerstehen, 100% Genauigkeit oder GTFO zu sagen).
Wir können Bilder (sagen wir in Katzenbilder oder Hundebilder) klassifizieren, die der menschlichen Kapazität entsprechen, indem wir KI verwenden. Aber kann dies bereits für reale Anwendungsfälle verwendet werden? Kann KI eine Lösung für praktischere Probleme liefern, mit denen Menschen konfrontiert sind? In einigen Fällen ja, aber in vielen Fällen sind wir noch nicht so weit.
Wir führen Sie durch die Herausforderungen, die die Haupthindernisse für die Entwicklung einer realen Lösung mit KI darstellen. Angenommen, Sie möchten Bilder von Katzen und Hunden klassifizieren. Wir werden dieses Beispiel im gesamten Beitrag verwenden.

Unser Beispielalgorithmus: Klassifizieren der Bilder von Katzen und Hunden
Die folgende Grafik fasst die Herausforderungen zusammen:

Herausforderungen bei der Entwicklung einer realen KI
Lassen Sie uns diese Herausforderungen im Detail besprechen:
Lernen mit weniger Daten
- Die Trainingsdaten, die die erfolgreichsten Deep-Learning-Algorithmen verbrauchen, erfordern eine Kennzeichnung gemäß den darin enthaltenen Inhalten/Funktionen. Dieser Vorgang wird Annotation genannt.
- Die Algorithmen können die natürlich gefundenen Daten um Sie herum nicht verwenden. Die Annotation von einigen hundert (oder einigen tausend Datenpunkten) ist einfach, aber unser Bildklassifizierungsalgorithmus auf menschlicher Ebene benötigte eine Million kommentierter Bilder, um gut zu lernen.
- Die Frage ist also, ob es möglich ist, eine Million Bilder zu kommentieren? Wenn nicht, wie kann KI dann mit einer geringeren Menge an kommentierter Daten skalieren?
Diverse reale Probleme lösen
- Während Datensätze festgelegt sind, ist die Verwendung in der realen Welt vielfältiger (z. B. könnte ein auf Farbbildern trainierter Algorithmus bei Graustufenbildern im Gegensatz zu Menschen schlecht versagen).
- Während wir die Computer Vision-Algorithmen verbessert haben, um Objekte zu erkennen, die Menschen entsprechen. Aber wie bereits erwähnt, lösen diese Algorithmen ein sehr spezifisches Problem im Vergleich zur menschlichen Intelligenz, die in vielerlei Hinsicht weitaus allgemeiner ist.
- Unser KI-Beispielalgorithmus, der Katzen und Hunde klassifiziert, kann eine seltene Hundeart nicht identifizieren, wenn er nicht mit Bildern dieser Art gefüttert wird.
Anpassen der inkrementellen Daten
- Eine weitere große Herausforderung sind inkrementelle Daten. Wenn wir in unserem Beispiel versuchen, Katzen und Hunde zu erkennen, könnten wir unsere KI für eine Reihe von Katzen- und Hundebildern verschiedener Arten trainieren, während wir sie zum ersten Mal einsetzen. Aber bei der Entdeckung einer insgesamt neuen Art müssen wir den Algorithmus trainieren, um „Kotpies“ zusammen mit der vorherigen Art zu erkennen.
- Während die neue Spezies anderen ähnlicher sein könnte, als wir denken, und leicht trainiert werden kann, den Algorithmus anzupassen, gibt es Punkte, an denen dies schwieriger ist und ein vollständiges Neutraining und eine Neubewertung erfordert.
- Die Frage ist, können wir die KI zumindest anpassungsfähig an diese kleinen Änderungen machen?
Um KI sofort nutzbar zu machen, besteht die Idee darin, die oben genannten Herausforderungen durch eine Reihe von Ansätzen namens Effektives Lernen zu lösen (bitte beachten Sie, dass es sich nicht um einen offiziellen Begriff handelt, ich erfinde ihn nur, um zu vermeiden, Meta-Learning, Transfer Learning, Few Shot Learning, Adversarial Learning und Multi-Task Learning jedes Mal). Wir bei ParallelDots verwenden diese Ansätze jetzt, um enge Probleme mit KI zu lösen, kleine Schlachten zu gewinnen und uns gleichzeitig auf eine umfassendere KI vorzubereiten, um größere Kriege zu erobern. Lassen Sie uns Ihnen diese Techniken eine nach der anderen vorstellen.
Bemerkenswerterweise sind die meisten dieser Techniken des effektiven Lernens nichts Neues. Sie erleben gerade ein Wiederaufleben. SVM-Forscher (Support Vector Machines) verwenden diese Techniken seit langem. Adversarial Learning hingegen ist etwas, das aus Goodfellows jüngster Arbeit zu GANs hervorgegangen ist, und Neural Reasoning ist eine neue Reihe von Techniken, für die erst seit kurzem Datensätze verfügbar sind. Lassen Sie uns eingehend untersuchen, wie diese Techniken dazu beitragen werden, die Zukunft der KI zu gestalten.
Lernen übertragen
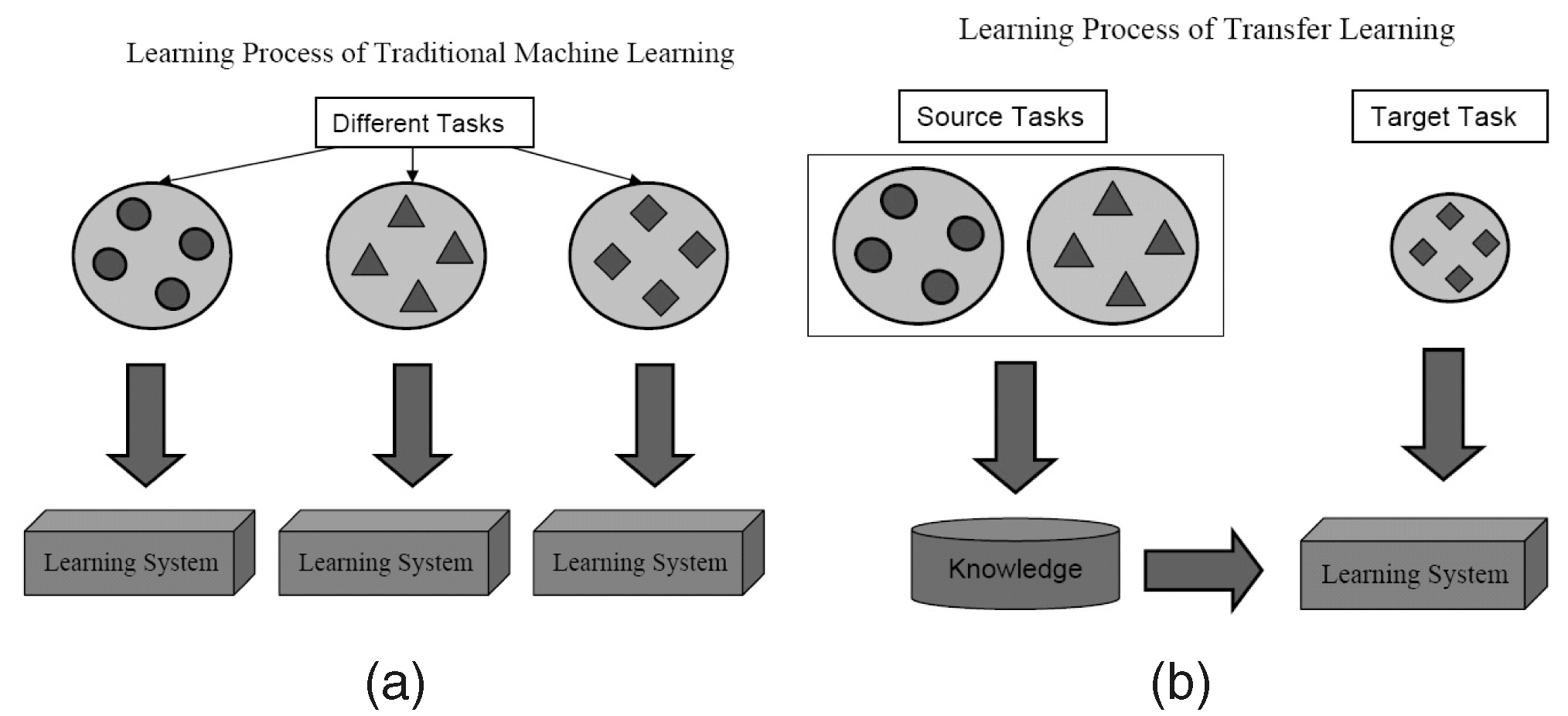
Was ist es?
Wie der Name schon sagt, wird beim Transfer Learning das Gelernte innerhalb desselben Algorithmus von einer Aufgabe auf die andere übertragen. Algorithmen, die an einer Aufgabe (Quellaufgabe) mit einem größeren Datensatz trainiert wurden, können mit oder ohne Modifikation als Teil des Algorithmus übertragen werden, der versucht, eine andere Aufgabe (Zielaufgabe) an einem (relativ) kleineren Datensatz zu lernen.
Einige Beispiele
Die Verwendung von Parametern eines Bildklassifizierungsalgorithmus als Merkmalsextraktion in verschiedenen Aufgaben wie der Objekterkennung ist eine einfache Anwendung von Transfer Learning. Im Gegensatz dazu können damit auch komplexe Aufgaben erledigt werden. Der Algorithmus, den Google entwickelt hat, um diabetische Retinopathie vor einiger Zeit besser zu klassifizieren als Ärzte, wurde mithilfe von Transfer Learning erstellt. Überraschenderweise war der Detektor für diabetische Retinopathie tatsächlich ein realer Bildklassifizierer (Hund/Katze-Bildklassifizierer) Transfer Learning zur Klassifizierung von Augenscans.
Erzähl mir mehr!
Sie finden Data Scientists, die solche übertragenen Teile neuronaler Netze von der Quelle zur Zielaufgabe als vortrainierte Netze in der Deep-Learning-Literatur bezeichnen. Bei der Feinabstimmung werden Fehler der Zielaufgabe leicht in das vortrainierte Netz zurückpropagiert, anstatt das vortrainierte Netz unverändert zu verwenden. Eine gute technische Einführung in Transfer Learning in Computer Vision finden Sie hier. Dieses einfache Konzept des Transfer-Lernens ist sehr wichtig in unserem Satz effektiver Lernmethoden.
Für dich empfohlen:

Wie Metaverse die indische Automobilindustrie verändern wird

Was bedeutet die Anti-Profiteering-Bestimmung für indische Startups?

Wie Edtech-Startups Indiens Arbeitskräften helfen, sich weiterzubilden und zukunftsfähig zu werden ...

New-Age-Tech-Aktien in dieser Woche: Zomatos Probleme gehen weiter, EaseMyTrip-Posts steigen...

Indische Startups nehmen Abkürzungen bei der Jagd nach Finanzierung

Digitale Marketingplattform Logicserve Bags INR 80 Cr-Finanzierung, Umbenennung in LS Dig...
Multitasking-Lernen
Was ist es?
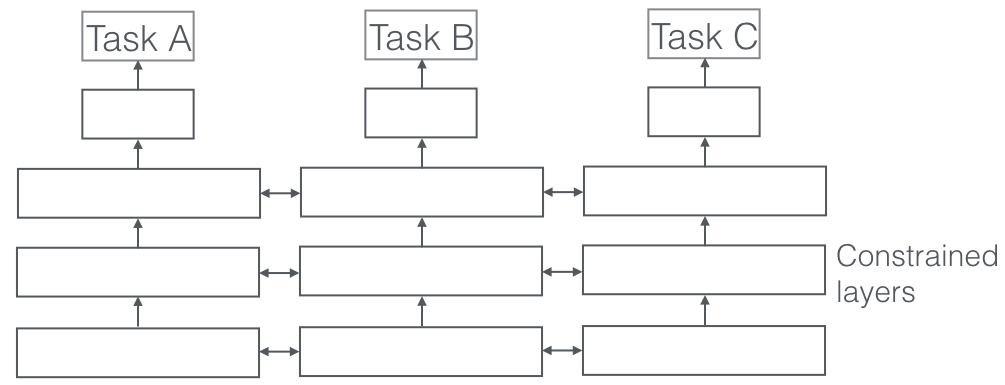

Beim Multi-Task-Lernen werden mehrere Lernaufgaben gleichzeitig gelöst, wobei Gemeinsamkeiten und Unterschiede zwischen den Aufgaben ausgenutzt werden. Es ist überraschend, aber manchmal kann das gemeinsame Lernen von zwei oder mehr Aufgaben (auch als Hauptaufgabe und Nebenaufgaben bezeichnet) die Ergebnisse für die Aufgaben verbessern. Bitte beachten Sie, dass nicht jedes Aufgabenpaar oder -triplett oder -quartett als Hilfsaufgabe betrachtet werden kann. Aber wenn es funktioniert, ist es eine kostenlose Erhöhung der Genauigkeit.
Einige Beispiele
Zum Beispiel wurden bei ParallelDots unsere Sentiment-, Absichts- und Emotionserkennungs-Klassifikatoren als Multi-Task-Lernen trainiert, was ihre Genauigkeit im Vergleich zu einem separaten Training erhöhte. Das beste semantische Rollenkennzeichnungs- und POS-Tagging-System in NLP, das wir kennen, ist ein Multi-Task-Lernsystem, also eines der besten Systeme für semantische und Instanzsegmentierung in Computer Vision. Google entwickelte multimodale Multi-Task-Lerner (ein Modell, um sie alle zu beherrschen), die in derselben Aufnahme sowohl aus Bild- als auch aus Textdatensätzen lernen können.
Erzähl mir mehr!
Ein sehr wichtiger Aspekt des Multi-Task-Lernens, der in realen Anwendungen zu sehen ist, besteht darin, dass wir beim Trainieren einer Aufgabe, um kugelsicher zu werden, viele Domänen berücksichtigen müssen, aus denen Daten stammen (auch Domänenanpassung genannt). Ein Beispiel in unseren Anwendungsfällen für Katzen und Hunde wird ein Algorithmus sein, der Bilder verschiedener Quellen erkennen kann (z. B. VGA-Kameras und HD-Kameras oder sogar Infrarotkameras). In solchen Fällen kann jeder Aufgabe ein zusätzlicher Verlust der Domänenklassifizierung (woher die Bilder stammen) hinzugefügt werden, und dann lernt die Maschine so, dass der Algorithmus bei der Hauptaufgabe (Klassifizieren von Bildern in Katzen- oder Hundebilder) immer besser wird, aber absichtlich schlechter werden bei der Hilfsaufgabe (dies geschieht durch Backpropagation des umgekehrten Fehlergradienten von der Domänenklassifizierungsaufgabe). Die Idee ist, dass der Algorithmus Unterscheidungsmerkmale für die Hauptaufgabe lernt, aber Merkmale vergisst, die Domänen unterscheiden, und dies würde ihn verbessern. Multi-Task-Lernen und seine Cousins Domain Adaption sind eine der erfolgreichsten effektiven Lerntechniken, die wir kennen, und spielen eine große Rolle bei der Gestaltung der Zukunft der KI.
Gegenseitiges Lernen
Was ist es?
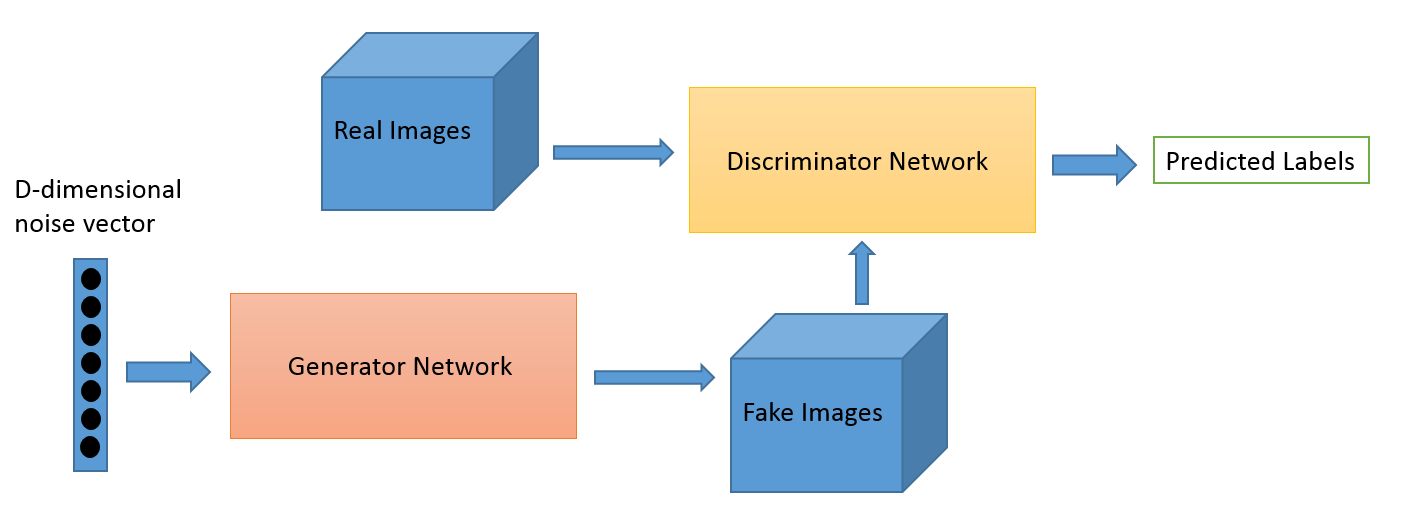
Adversarial Learning als Feld entwickelte sich aus der Forschungsarbeit von Ian Goodfellow. Während die beliebtesten Anwendungen von Adversarial Learning zweifellos Generative Adversarial Networks (GANs) sind, die verwendet werden können, um atemberaubende Bilder zu erzeugen, gibt es mehrere andere Möglichkeiten für diese Reihe von Techniken. Typischerweise hat diese von der Spieltheorie inspirierte Technik zwei Algorithmen, einen Generator und einen Diskriminator, deren Ziel es ist, sich gegenseitig zu täuschen, während sie trainieren. Der Generator kann verwendet werden, um neue neuartige Bilder zu generieren, wie wir besprochen haben, kann aber auch Darstellungen anderer Daten generieren, um Details vor dem Diskriminator zu verbergen. Letzteres ist der Grund, warum dieses Konzept für uns so interessant ist.
Einige Beispiele
Dies ist ein neues Gebiet, und die Bilderzeugungskapazität ist wahrscheinlich das, worauf sich die meisten Interessierten wie Astronomen konzentrieren. Aber wir glauben, dass dies auch neuere Anwendungsfälle hervorbringen wird, wie wir später erzählen werden.
Erzähl mir mehr!
Das Domänenanpassungsspiel kann unter Verwendung des GAN-Verlusts verbessert werden. Der zusätzliche Verlust ist hier ein GAN-System anstelle einer reinen Domänenklassifizierung, bei der ein Diskriminator versucht zu klassifizieren, aus welcher Domäne die Daten stammen, und eine Generatorkomponente versucht, sie zu täuschen, indem sie zufälliges Rauschen als Daten präsentiert. Unserer Erfahrung nach funktioniert dies besser als eine einfache Domänenanpassung (die auch unberechenbarer für den Code ist).
Lernen mit wenigen Schüssen
Was ist es?
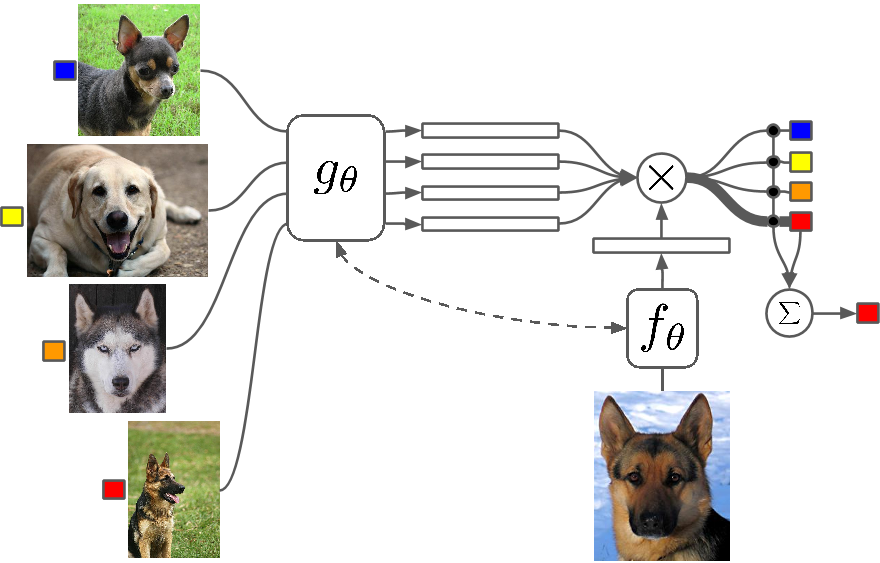
Few Shot Learning ist eine Untersuchung von Techniken, die Algorithmen für Deep Learning (oder jeden Algorithmus für maschinelles Lernen) dazu bringen, mit weniger Beispielen zu lernen, als dies bei einem herkömmlichen Algorithmus der Fall wäre. One-Shot-Lernen ist im Grunde Lernen mit einem Beispiel einer Kategorie, induktives K-Shot-Lernen bedeutet Lernen mit k Beispielen jeder Kategorie.
Einige Beispiele
Few Shot Learning als Feld verzeichnet einen Zustrom von Beiträgen auf allen großen Deep-Learning-Konferenzen, und es gibt jetzt spezifische Datensätze, an denen Ergebnisse gemessen werden können, genau wie MNIST und CIFAR für normales maschinelles Lernen. One-Shot-Learning sieht eine Reihe von Anwendungen in bestimmten Bildklassifizierungsaufgaben wie der Merkmalserkennung und -darstellung vor.
Erzähl mir mehr!
Es gibt mehrere Methoden, die für das Few-Shot-Lernen verwendet werden, einschließlich Transfer-Lernen, Multi-Task-Lernen sowie Meta-Lernen als Gesamtheit oder Teil des Algorithmus. Es gibt andere Möglichkeiten wie eine clevere Verlustfunktion, die Verwendung dynamischer Architekturen oder die Verwendung von Optimierungs-Hacks. Zero Shot Learning, eine Klasse von Algorithmen, die behaupten, Antworten für Kategorien vorherzusagen, die der Algorithmus noch nicht einmal gesehen hat, sind im Grunde Algorithmen, die mit einer neuen Art von Daten skalieren können.
Meta-Lernen
Was ist es?

Meta-Learning ist genau das, wonach es sich anhört, ein Algorithmus, der so trainiert, dass er beim Betrachten eines Datensatzes einen neuen Prädiktor für maschinelles Lernen für diesen bestimmten Datensatz liefert. Die Definition ist auf den ersten Blick sehr futuristisch. Du fühlst „Wow! das ist, was ein Datenwissenschaftler tut“ und es automatisiert den „heißesten Job des 21. Jahrhunderts“, und in gewissem Sinne haben Meta-Lernende damit begonnen.
Einige Beispiele
Meta-Learning ist in letzter Zeit zu einem heißen Thema im Deep Learning geworden, mit vielen Forschungsarbeiten, die am häufigsten die Technik zur Optimierung von Hyperparametern und neuronalen Netzwerken verwenden, gute Netzwerkarchitekturen finden, Few-Shot-Bilderkennung und schnelles bestärkendes Lernen.
Erzähl mir mehr!
Einige Leute bezeichnen diese vollständige Automatisierung der Entscheidung sowohl für Parameter als auch für Hyperparameter wie die Netzwerkarchitektur als autoML, und Sie werden vielleicht Leute finden, die Meta Learning und AutoML als unterschiedliche Bereiche bezeichnen. Trotz all des Hypes um sie herum sind Meta-Lerner in Wahrheit immer noch Algorithmen und Wege, um maschinelles Lernen mit zunehmender Komplexität und Vielfalt der Daten zu skalieren.
Die meisten Meta-Learning-Papiere sind clevere Hacks, die laut Wikipedia folgende Eigenschaften haben:
- Das System muss ein lernendes Subsystem enthalten, das sich mit der Erfahrung anpasst.
- Erfahrung wird gewonnen, indem Metawissen genutzt wird, das entweder in einer früheren Lernepisode zu einem einzelnen Datensatz oder aus verschiedenen Bereichen oder Problemen extrahiert wurde.
- Learning Bias muss dynamisch gewählt werden.
Das Subsystem ist im Grunde eine Einrichtung, die sich anpasst, wenn Metadaten einer Domäne (oder einer völlig neuen Domäne) eingeführt werden. Diese Metadaten können Aufschluss über die zunehmende Anzahl von Klassen, Komplexität, Veränderung von Farben und Texturen und Objekten (in Bildern), Stile, Sprachmuster (natürliche Sprache) und andere ähnliche Merkmale geben. Sehen Sie sich hier einige super coole Artikel an: Meta-Learning Shared Hierarchies und Meta-Learning Using Temporal Convolutions. Sie können auch Few-Shot- oder Zero-Shot-Algorithmen mithilfe von Meta-Learning-Architekturen erstellen. Meta-Learning ist eine der vielversprechendsten Techniken, die dabei helfen wird, die Zukunft der KI zu gestalten.
Neurales Denken
Was ist es?

Neural Reasoning ist das nächste große Ding bei Bildklassifizierungsproblemen. Neural Reasoning ist eine Stufe über der Mustererkennung, bei der Algorithmen über die Idee hinausgehen, Text oder Bilder einfach zu identifizieren und zu klassifizieren. Neural Reasoning löst allgemeinere Fragen in der Textanalyse oder visuellen Analyse. Das folgende Bild stellt beispielsweise eine Reihe von Fragen dar, die Neural Reasoning anhand eines Bildes beantworten kann.
Erzähl mir mehr!
Diese neuen Techniken kommen nach der Veröffentlichung des bAbi-Datensatzes von Facebook oder des jüngsten CLEVR-Datensatzes auf den Markt. Die Techniken zur Entschlüsselung von Beziehungen und nicht nur von Mustern haben ein immenses Potenzial, nicht nur das neurale Denken zu lösen, sondern auch mehrere andere schwierige Probleme, einschließlich Lernprobleme mit wenigen Schüssen.
Zurück gehen
Nun, da wir wissen, was die Techniken sind, lassen Sie uns zurückgehen und sehen, wie sie die grundlegenden Probleme lösen, mit denen wir begonnen haben. Die folgende Tabelle gibt eine Momentaufnahme der Möglichkeiten effektiver Lerntechniken zur Bewältigung der Herausforderungen wieder:
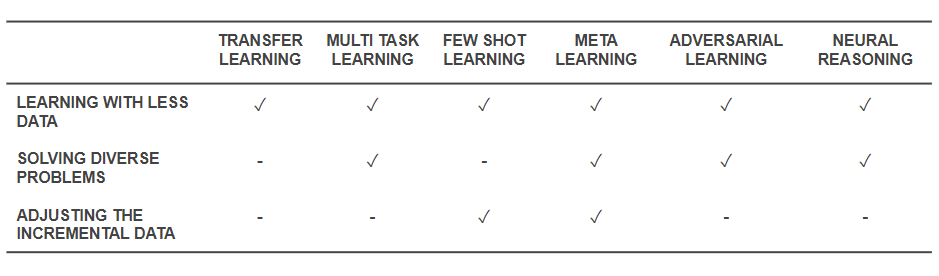
Fähigkeiten effektiver Lerntechniken
- Alle oben genannten Techniken helfen, das Training mit einer geringeren Datenmenge auf die eine oder andere Weise zu lösen. Während Meta-Learning Architekturen ergeben würde, die sich einfach mit Daten formen würden, macht Transfer Learning Wissen aus einem anderen Bereich nützlich, um weniger Daten zu kompensieren. Few Shot Learning widmet sich dem Problem als wissenschaftliche Disziplin. Adversarial Learning kann helfen, die Datensätze zu verbessern.
- Domain Adaptation (eine Art Multi-Task-Lernen), Adversarial Learning und (manchmal) Meta-Learning-Architekturen helfen bei der Lösung von Problemen, die sich aus der Datenvielfalt ergeben.
- Meta-Learning und Few-Shot-Learning helfen, Probleme mit inkrementellen Daten zu lösen.
- Neural Reasoning-Algorithmen haben ein immenses Potenzial, reale Probleme zu lösen, wenn sie als Meta-Learner oder Few-Shot-Learner integriert werden.
Bitte beachten Sie, dass diese Techniken des effektiven Lernens keine neuen Techniken des Deep Learning/Maschinellen Lernens sind, sondern die bestehenden Techniken als Hacks erweitern , wodurch sie mehr Geld kosten. Daher werden Sie unsere regulären Tools wie Convolutional Neural Networks und LSTMs immer noch in Aktion sehen, aber mit der zusätzlichen Würze. Diese effektiven Lerntechniken, die mit weniger Daten arbeiten und viele Aufgaben auf einmal erledigen, können zu einer einfacheren Produktion und Kommerzialisierung von KI-gestützten Produkten und Dienstleistungen beitragen. Bei ParallelDots erkennen wir die Kraft des effizienten Lernens und integrieren es als eines der Hauptmerkmale unserer Forschungsphilosophie.
Dieser Beitrag von Parth Shrivastava erschien zuerst im ParallelDots-Blog und wurde mit Genehmigung reproduziert.