
Fünf kognitive Technologien zur Gestaltung der Zukunft
Veröffentlicht: 2019-12-04Cognitive Technology ist ein KI-basiertes, fortschrittliches Fahrerassistenzsystem. Eine von der Hackett Group vorgeschlagene Studie hat ergeben, dass 85 Prozent der Beschaffungsleiter sich mit dem Studium kognitiver Technologien befassen, die das operative Programm in den nächsten drei bis fünf Jahren weiterentwickeln werden. Nur 32 Prozent von allen haben die Strategie, die Technologien umzusetzen, und 25 Prozent von ihnen haben genug Kapital und Verstand, um die Technologien umzusetzen. Ich schlage Ihnen die potenziellsten kognitiven Technologien vor, die Ihre Zukunft gestalten können.
Da KI zur Grundlage für die Weiterentwicklung unseres täglichen Lebens wird. IT-Organisationen müssen diese neu entstandene Technologie übernehmen, um ihre Position auf dem Markt zu behaupten. Im Service Management ist es wichtig, kognitive Technologien zu integrieren, um das ganzheitliche System zu erweitern. Dieser Ansatz bietet enorme potenzielle Vorteile bei der Gestaltung der Zukunft sowohl für Benutzer als auch für das Service-Management. Durch die Integration kognitiver Technologien können Sie Ihren Benutzern personalisierte, fortschrittliche und dialogorientierte Erfahrungen bieten, die zu besseren und schnelleren Ergebnissen führen. Genauso wie Smartphone-Benutzer ihren Assistenten bei der Unterstützung verschiedener alltäglicher Aufgaben befehlen, werden Sie die genaue Erfahrung mit dem Service Desk machen, der Chatbots bittet, bei verschiedenen Aktivitäten ohne menschliches Eingreifen zu helfen. So erzielen Sie eine hohe Kundenzufriedenheit.
Big-Data-Analyse

Big Data Analytics ist der Prozess der Verwaltung der riesigen Datenmenge, um mithilfe fortschrittlicher Technologien und Rechenfunktionen Muster, Trends und umsetzbare Erkenntnisse zu zeichnen. Es ist eine Form der fortgeschrittenen Analytik, die komplizierte Anwendungen mit Vorhersagemodellen und statistischen Algorithmen beinhaltet, diese Aufgaben werden von Hochleistungsanalysesystemen erledigt. Diese spezialisierten Analysesysteme und -software bieten zahlreiche Vorteile, darunter bessere Einnahmemöglichkeiten, eine bemerkenswerte Marketingbasis, erweiterten Kundenservice, betriebliche Effizienz und einen besseren Wettbewerbsvorteil. Anwendungen, die auf Big-Data-Analyseanwendungen basieren, geben Datenanalysten, Vorhersagemodellierern, Statistikern und anderen Fachleuten in diesen Bereichen Raum, um die wachsenden Mengen strukturierter Transaktionsdaten und anderer Datenformen zu analysieren, die von herkömmlichen BI- und Analyseprogrammen nicht praktiziert werden. Es umgibt eine Verschmelzung von strukturierten und unstrukturierten Daten. Durch Sensoranbindung werden diese Daten gesammelt und mit IoT (Internet of Things) verbunden. Dabei kommen eine Vielzahl von Tools und Technologien zum Einsatz:
- NoSQL-Datenbanken
- Hadoop
- GARN
- Karte verkleinern
- Funke
- Hbase
- Bienenstock
- Schwein
Big-Data-Analytics-Apps umfassen Daten aus internen Systemen und externen Quellen wie Wetterdaten über Verbraucher, die von Drittanbietern von Informationsdiensten zusammengestellt wurden. Streaming-Analytics-Anwendungen sind in Big-Data-Umgebungen üblich geworden, um Echtzeitanalysen von Daten durchzuführen, die über Stream-Processing-Engines wie Spark, Flink und Storm in Hadoop-Systeme eingespeist wurden. Komplexe Analysesysteme sind in diese Technologie integriert, um große Datenmengen zu verwalten und zu analysieren. Big Data ist in der Supply-Chain-Analyse von großem Nutzen geworden. Bis 2011 hat Big Data Analytics begonnen, eine feste Position in Organisationen und der Öffentlichkeit einzunehmen. Mit Big Data begannen sich Hadoop und andere verwandte Big-Data-Technologien zu entwickeln. In erster Linie nahm das Hadoop-Ökosystem Gestalt an und wurde mit der Zeit ausgereift. Big Data waren in erster Linie die Plattform großer Internetsystem- und E-Commerce-Unternehmen. Gegenwärtig wird es von Einzelhändlern, Finanzdienstleistungsunternehmen, Versicherern, Gesundheitsorganisationen, Herstellern und anderen potenziellen Unternehmen angenommen. In einigen Fällen werden Hadoop-Cluster und NoSQL-Systeme auf der vorläufigen Ebene als Landing Pads und Staging-Bereiche für Daten verwendet. Die gesamte Aktion wird durchgeführt, bevor sie in eine analytische Datenbank geladen wird, um sie allgemein in zusammengesetzter Form zu analysieren. Wenn die Daten fertig sind, können sie mit Software analysiert werden, die für erweiterte Analyseprozesse verwendet wird. Data Mining, Predictive Analytics, maschinelles Lernen und Deep Learning sind die typischen Werkzeuge, um die gesamte Aktion abzuschließen. In diesem Spektrum ist es sehr wichtig zu erwähnen, dass Text-Mining- und statistische Analysesoftware eine zentrale Rolle im Big-Data-Analyseprozess spielt. Sowohl für ETL- als auch für Analyseanwendungen werden Abfragen in MapReduce mit verschiedenen Programmiersprachen wie R, Python, Scala und SQL geschrieben.
Maschinelles Lernen:

Maschinelles Lernen ist ein kontinuierlicher Fortschrittsprozess, bei dem Maschinen so entwickelt werden, dass sie ihre Aufgabe als Mensch erfüllen können. Diese Maschinen werden mithilfe von Hightech-Daten entwickelt, um ihre Aufgabe ohne menschliches Eingreifen zu erfüllen. Maschinelles Lernen ist eine Anwendung der KI, die einer Maschine die Fähigkeit verleiht, Programme ohne direkte und explizite Aktion zu lernen und zu verbessern. Es konzentriert sich im Wesentlichen auf die Entwicklung eines Computerprogramms, das auf Daten zugreifen und diese nutzen kann, um selbst zu lernen. Ihr oberstes Ziel ist es, Maschinen ohne menschliches Zutun automatisch lernen zu lassen. Maschinelles Lernen ist eng verwandt mit der Computerstatistik, mit der das Studium der mathematischen Optimierung die Aufgabe des maschinellen Lernens erfüllt. Die Aufgabe des maschinellen Lernens kann in mehrere große Kategorien eingeteilt werden.
- Überwachtes Lernen.
- Halbüberwachtes Lernen.
- Unüberwachtes maschinelles Lernen.
- Verstärkung des maschinellen Lernens.
Alle diese klassifizierten Kategorien des maschinellen Lernens bieten unterschiedliche Aufgabenstellungen bei der Analyse von Daten und Informationen und treffen wesentliche Entscheidungen:
- Der Lernalgorithmus erstellt eine vermutete Funktion zum Treffen von Vorhersagen über den Ausgabewert. Die Lernalgorithmen können ihre Ausgabe mit der berechneten Ausgabe vergleichen und Fehler finden, um das Modell gemäß den Anforderungen zu modifizieren.
- Unüberwachte Algorithmen für maschinelles Lernen können die richtige Ausgabe nicht korrigieren, sondern können Daten untersuchen und Rückschlüsse aus dem Datensatz ziehen, um verborgene Strukturen aus unbeschrifteten Daten zu beschreiben.
- Der halbüberwachte maschinelle Lernalgorithmus wird sowohl für gekennzeichnete als auch für nicht gekennzeichnete Daten verwendet.
- Reinforcement Machine Learning-Algorithmen interagieren mit der Umgebung, um Aktionen zu erzeugen und Belohnungen und Fehler zu entdecken. Der Trial-and-Error-Prozess ist zufällig das wichtigste Merkmal dieses Lernens. Um diesen Prozess zu ermöglichen, ist ein einfaches Belohnungs-Feedback unerlässlich, um zu lernen, welche Aktion am besten ist, was allgemein als Verstärkungssignal bezeichnet wird.
Wie Big Data Analytics ermöglicht auch maschinelles Lernen die Analyse der riesigen Datenmenge. Es liefert in der Regel schnelle und genaueste Ergebnisse, um vorteilhafte Möglichkeiten zu identifizieren oder das Risikomanagementsystem zu verwalten. Es kann jedoch auch zusätzliche Zeit und Ressourcen erfordern, um das gesamte Programm ordnungsgemäß auszuführen. Es ist ein sehr effektiver Prozess, um eine große Menge an Daten und Informationen zu verwalten und zu überwachen.

Verarbeitung natürlicher Sprache (NLP)
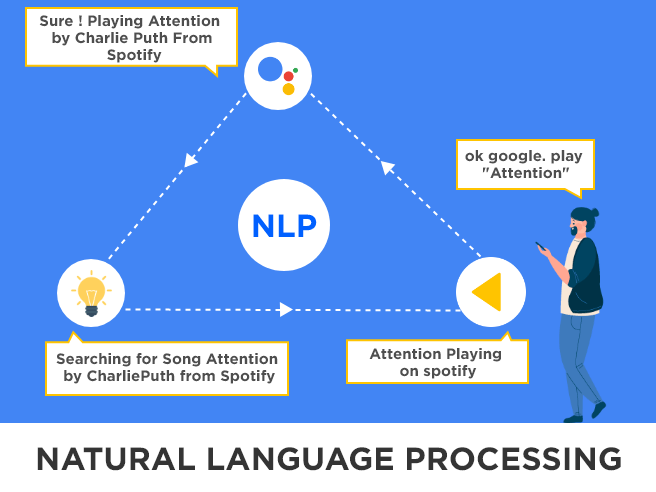
Die Verarbeitung natürlicher Sprache soll Maschinen mit menschlicher Intelligenz trainieren, um Änderungen in ihrer Sprache und Antworten zu erzeugen, um sie menschenähnlicher zu machen. Es bezieht sich eigentlich darauf, wie wir miteinander kommunizieren. NLP ist definiert als die automatische Manipulation natürlicher Sprache durch die Verwendung der Software. Das Studium der Natursprachverarbeitung wurde vor mehr als 50 Jahren begonnen. Es unterscheidet sich von anderen Arten von Daten. Trotzdem ist die Herausforderung des Prozesses natürlicher Sprache nach so vielen Jahren Arbeit nicht in einer mathematisch-linguistischen Zeitschrift gelöst, die von einem begeisterten Wissenschaftler veröffentlicht wurde: „Es ist hart vom Standpunkt des Kindes, das viele Jahre damit verbringen muss, eine Sprache zu lernen … es ist schwierig für den erwachsenen Sprachenlerner, es ist schwierig für den Wissenschaftler, der versucht, die relevanten Phänomene zu modellieren, und es ist schwierig für den Ingenieur, der versucht, Systeme zu bauen, die mit Eingabe und Ausgabe natürlicher Sprache umgehen. Diese Aufgaben sind so schwierig, dass Turing eine fließende Konversation in natürlicher Sprache zu Recht zum Kernstück seines Intelligenztests machen könnte.
Da Wissenschaftler und Forscher des maschinellen Lernens daran interessiert sind, mit Daten zu arbeiten, kann die Linguistik im NLP-Prozess arbeiten. Moderne Entwickler schlugen vor: „Das Ziel der Sprachwissenschaft ist es, die Vielzahl sprachlicher Beobachtungen, die uns in Gesprächen, Schriften und anderen Medien umgeben, zu charakterisieren und zu erklären. Ein Teil davon hat mit der kognitiven Größe zu tun, wie Menschen Sprache erwerben, produzieren und verstehen, ein Teil davon hat mit dem Verständnis der Beziehung zwischen sprachlicher Äußerung und der Welt zu tun, und ein Teil davon hat mit dem Verständnis der sprachlichen Strukturen zu tun welche Sprache kommuniziert“
Künstliche Intelligenz

KI treibt die Automatisierung primärer Aufgaben mit Computern voran, die als fortschrittliche digitale Assistenten dienen. Die menschliche Intelligenz ist darauf ausgerichtet, die Umwelt wahrzunehmen, von der Umwelt zu lernen und Informationen aus der Umwelt zu verarbeiten. Das bedeutet, dass KI Folgendes beinhaltet:
- Täuschung des menschlichen Sinnes, wie Fühlen, Schmecken, Sehen, Riechen und Hören.
- Täuschung menschlicher Reaktionen: Robotik.
- Täuschung des Lernens und der Verarbeitung: Maschinelles Lernen und Deep Learning.
Cognitive Computing konzentriert sich im Allgemeinen darauf, menschliches Verhalten nachzuahmen und daran zu arbeiten, Probleme zu lösen, die möglicherweise sogar besser als die menschliche Intelligenz gelöst werden können. Cognitive Computing ergänzt einfach die Informationen, um Entscheidungen einfacher denn je zu treffen. Während die künstliche Intelligenz dafür verantwortlich ist, die Entscheidung selbst zu treffen und die Rolle des Menschen zu minimieren. Die Technologien, die hinter Cognitive Computing arbeiten, ähneln den Technologien hinter KI, zu denen Deep Learning, maschinelles Lernen, neuronale Netze, NLP usw. gehören. Obwohl Cognitive Computing eng mit künstlicher Intelligenz verbunden ist, sind sie, wenn ihr praktischer Nutzen ans Licht kommt sind komplett anders. KI ist definiert als „die Simulation menschlicher Intelligenzprozesse durch Maschinen, insbesondere Computersysteme. Zu diesen Prozessen gehören Lernen (Erwerb von Informationen und Regeln für die Verwendung der Informationen), Argumentieren (Anwenden der Regeln, um zu ungefähren oder endgültigen Schlussfolgerungen zu gelangen) und Selbstkorrektur“. KI ist ein Überbegriff, unter dem eine Vielzahl von Technologien, Algorithmen, Theorien und Methoden es dem Computer oder jedem intelligenten Gerät ermöglichen, mit Hightech-Technologien mit menschlicher Intelligenz zu arbeiten. Maschinelles Lernen und Robotik sind alle Bereiche der künstlichen Intelligenz, die es Maschinen ermöglicht, erweiterte Intelligenz anzubieten und die menschliche Einsicht und Genauigkeit zu übertreffen. Das KI-Tool bietet eine Reihe neuer Funktionalitäten in Ihrem Unternehmen. Die Deep-Learning-Algorithmen, die in die fortschrittlichsten KI-Tools integriert sind. Forscher und Vermarkter glauben, dass die Einführung von Augmented Intelligence eine neutralere Konnotation hat, die es uns ermöglicht zu verstehen, dass KI zur Verbesserung von Produkten und Dienstleistungen eingesetzt wird. KI kann in vier Kategorien eingeteilt werden:
Reaktive Maschinen: Der Schachcomputer Deep Blue von IBM hat die Fähigkeit, Figuren auf dem Schachbrett und Vorhersagen entsprechend zu identifizieren, obwohl er nicht auf vergangene Erfahrungen zugreifen kann, um zukünftige zu informieren. Es kann die möglichen Bewegungen verwalten und analysieren. AlphaGO von Google ist ein weiteres Beispiel, das jedoch für enge Zwecke entwickelt wurde und nicht auf andere Situationen angewendet werden kann.
Theory of Mind: Allerdings sind diese Arten von KIs so entwickelt, dass Maschinen individuelle Entscheidungen treffen können. Obwohl diese KI-Technologie schon vor langer Zeit entwickelt wurde. Derzeit hat es keinen praktischen Nutzen.
Begrenztes Gedächtnis: Diese Technologie der künstlichen Intelligenz wurde entwickelt, um in Zukunft eine Aufgabe in Bezug auf vergangene Erfahrungen zu erfüllen. Es hat die Fähigkeit, Ihnen erweiterte Hinweise zu jeder wichtigen Entscheidung in Bezug auf Ihre Aufgaben zu geben. Zum Beispiel: Wenn Sie fahren, kann Ihnen das KI-Navigationssystem direkt helfen, die Spur zu wechseln, um Ihr Ziel zu erreichen.
Selbstbewusstsein: KI wird entwickelt, die wirklich einen Sinn und ein Bewusstsein haben kann, wie es ein menschlicher Körper hat. Maschinen mit integriertem Selbstbewusstsein können den aktuellen Zustand verstehen, indem sie die Informationen verwenden, um zu intervenieren, was eine dritte Person fühlt.
Prozessautomatisierung

Die Prozessautomatisierung ermöglicht es, die verschiedenen Funktionen miteinander zu verknüpfen, die Automatisierung des Arbeitsablaufs zu verarbeiten und minimale Fehler zu haben. Prozessautomatisierung ist der Einsatz von Technologie zur Geschäftsautomatisierung. Der erste Schritt besteht darin, die Prozesse zu erkennen, die automatisiert werden müssen. Wenn Sie den Automatisierungsprozess perfekt verstanden haben, sollten Sie die Ziele für die Automatisierung planen. Bevor Sie die Automatisierung durchführen, müssen Sie die Schlupflöcher und Fehler im Prozess überprüfen. Hier ist eine Liste, aus der Sie entnehmen können, warum Sie einen Automatisierungsprozess in Ihrem Unternehmen benötigen:
- Die Prozesse zu standardisieren und zu rationalisieren.
- Um den Prozess agil zu lösen, indem die Kosten gesenkt werden.
- Um eine bessere Allokation von Ressourcen zu entwickeln.
- Zur Verbesserung des Kundenerlebnisses.
- Zur Verbesserung der Compliance, um Ihre Geschäftsprozesse zu regulieren und zu standardisieren.
- Für eine hohe Mitarbeiterzufriedenheit.
- Um die Sichtbarkeit für die Verarbeitungsleistung zu verbessern.
Eine Reihe von Abteilungen kann den Geschäftsprozess übernehmen, um ihren Prozess zu automatisieren und den Zyklus komplizierter Natur zu vereinfachen.
Header-Bildquelle: https://bit.ly/2PfdWWm