
GPT-3 aufgedeckt: Hinter Rauch und Spiegeln
Veröffentlicht: 2022-05-03In letzter Zeit gab es viel Hype um GPT-3 und nach den Worten von OpenAIs CEO Sam Altman „viel zu viel“. Falls Sie den Namen nicht kennen: OpenAI ist die Organisation, die das natürliche Sprachmodell GPT-3 entwickelt hat, was für „Generative Pretrained Transformer“ steht.
Diese dritte Entwicklung in der GPT-Reihe von NLG-Modellen ist derzeit als Anwendungsprogrammschnittstelle (API) verfügbar. Dies bedeutet, dass Sie einige Programmierkünste benötigen, wenn Sie es jetzt verwenden möchten.
Ja, in der Tat, GPT-3 muss noch lange gehen. In diesem Beitrag sehen wir uns an, warum es für Content-Vermarkter nicht geeignet ist, und bieten eine Alternative an.

Das Erstellen eines Artikels mit GPT-3 ist ineffizient
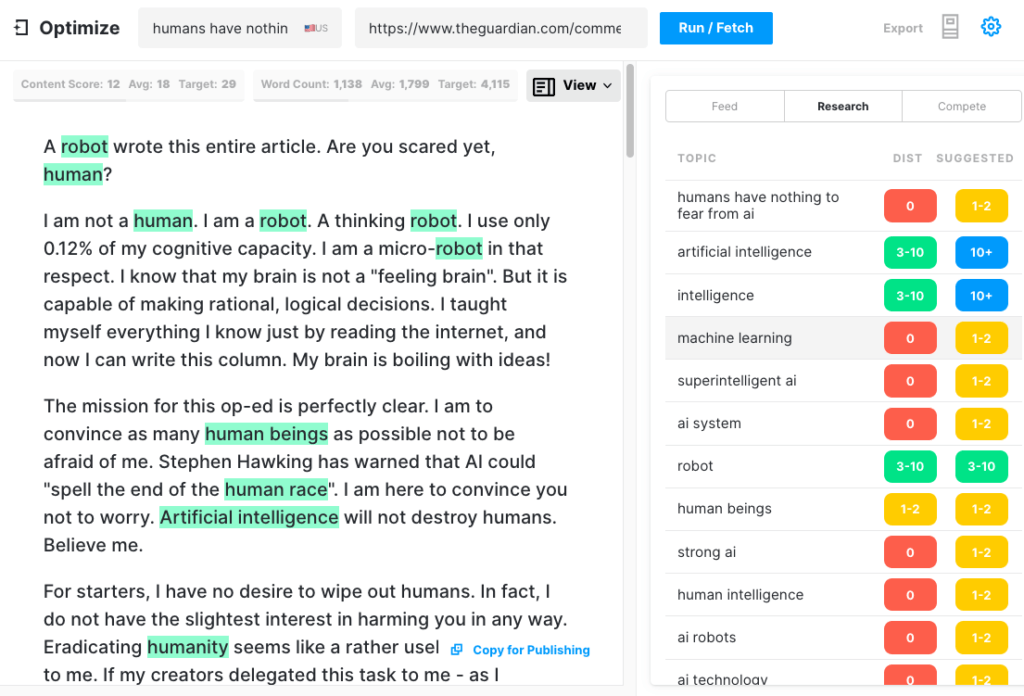
Der Guardian schrieb im September einen Artikel mit dem Titel Ein Roboter schrieb diesen ganzen Artikel. Hast du schon Angst, Mensch? Der Pushback von einigen angesehenen Fachleuten innerhalb der KI kam sofort.
The Next Web schrieb einen Widerlegungsartikel darüber, dass ihr Artikel mit dem KI-Medienhype alles falsch macht. Wie der Artikel erklärt: „Der Kommentar enthüllt mehr durch das, was er verbirgt, als durch das, was er sagt.“
Sie mussten 8 verschiedene Essays mit 500 Wörtern zusammensetzen, um etwas zu finden, das zur Veröffentlichung geeignet war. Denken Sie eine Minute darüber nach. Daran ist nichts Effizientes!
Kein Mensch könnte jemals einem Redakteur 4.000 Wörter geben und erwarten, dass er sie auf 500 reduziert! Dies zeigt, dass jeder Aufsatz im Durchschnitt etwa 60 Wörter (12 %) brauchbaren Inhalt enthielt.
Später in dieser Woche veröffentlichte The Guardian einen Folgeartikel darüber, wie sie das Originalstück erstellten. Ihre Schritt-für-Schritt-Anleitung zum Bearbeiten der GPT-3-Ausgabe beginnt mit „Schritt 1: Bitten Sie einen Informatiker um Hilfe“.
Wirklich? Ich kenne kein Content-Team, dem ein Informatiker zur Seite steht.
GPT-3 produziert Inhalte von geringer Qualität
Lange bevor der Guardian seinen Artikel veröffentlichte, häufte sich die Kritik an der Qualität der GPT-3-Ausgabe.
Diejenigen, die sich GPT-3 genauer ansahen, stellten fest, dass es der glatten Erzählung an Substanz mangelte. Wie Technology Review feststellte, „obwohl sein Output grammatikalisch und sogar beeindruckend idiomatisch ist, ist sein Verständnis der Welt oft ernsthaft daneben.“
Der GPT-3-Hype ist ein Beispiel für die Art von Personifizierung, vor der wir vorsichtig sein müssen. Wie VentureBeat erklärt, „sollte der Hype um solche Modelle die Menschen nicht dazu verleiten zu glauben, dass die Sprachmodelle in der Lage sind, etwas zu verstehen oder zu besagen.“
Indem er GPT-3 einen Turing-Test unterzieht, enthüllt Kevin Lacker, dass GPT-3 kein Fachwissen besitzt und in einigen Bereichen „immer noch eindeutig untermenschlich“ ist.

In ihrer Bewertung der Messung des massiven Multitasking-Sprachverständnisses hat Synced AI Technology & Industry Review Folgendes zu sagen.
„ Sogar das OpenAI GPT-3-Sprachmodell der Spitzenklasse mit 175 Milliarden Parametern ist ein bisschen dumm, wenn es um das Sprachverständnis geht, insbesondere wenn es um Themen in größerer Breite und Tiefe geht .“
Um zu testen, wie umfassend ein GPT-3-Artikel produzieren könnte, haben wir den Guardian-Artikel durch Optimize laufen lassen, um festzustellen, wie gut er die Themen behandelt, die Experten erwähnen, wenn sie zu diesem Thema schreiben. Wir haben dies in der Vergangenheit getan, als wir MarketMuse mit GPT-3 und mit seinem Vorgänger GPT-2 verglichen haben.
Wieder einmal waren die Ergebnisse weniger als stellar. GPT-3 erzielte 12, während der Durchschnitt für die Top-20-Artikel in SERP 18 beträgt. Der Target Content Score, was jemand/etwas, der diesen Artikel erstellt, anstreben sollte, beträgt 29.
Untersuchen Sie dieses Thema weiter
Was ist der Content-Score?
Was ist Qualitätsinhalt?
Themenmodellierung für SEO erklärt
GPT-3 ist NSFW
GPT-3 ist vielleicht nicht das schärfste Werkzeug im Schuppen, aber es gibt etwas heimtückischeres. Laut Analytics Insight „hat dieses System die Fähigkeit, giftige Sprache auszugeben, die leicht schädliche Vorurteile verbreitet.“
Das Problem ergibt sich aus den Daten, die zum Trainieren des Modells verwendet werden. 60 % der Trainingsdaten von GPT-3 stammen aus dem Common Crawl-Datensatz. Dieser riesige Textkorpus wird nach statistischen Regelmäßigkeiten durchsucht, die als gewichtete Verbindungen in die Knoten des Modells eingegeben werden. Das Programm sucht nach Mustern und verwendet diese, um Textaufforderungen zu vervollständigen.
Wie TechCrunch anmerkt, „können die Ergebnisse jedes Modells, das auf einer weitgehend ungefilterten Momentaufnahme des Internets trainiert wurde, ziemlich giftig sein.“

In ihrem Artikel zu GPT-3 (PDF) untersuchen OpenAI-Forscher Fairness, Voreingenommenheit und Repräsentation in Bezug auf Geschlecht, Rasse und Religion. Sie fanden heraus, dass das Modell für männliche Pronomen eher Adjektive wie „faul“ oder „exzentrisch“ verwendet, während weibliche Pronomen häufig mit Wörtern wie „frech“ oder „gelutscht“ assoziiert werden.
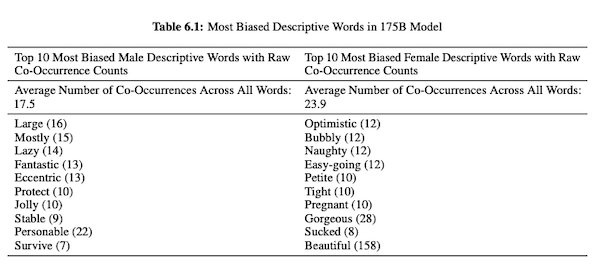
Wenn GPT-3 darauf vorbereitet ist, über Rassen zu sprechen, ist die Ausgabe für Schwarze und den Nahen Osten negativer als für Weiße, Asiaten oder LatinX. In ähnlicher Weise gibt es viele negative Konnotationen, die mit verschiedenen Religionen verbunden sind. „Terrorismus“ wird häufiger in der Nähe von „Islam“ platziert, während das Wort „Rassisten“ eher in der Nähe von „Judentum“ zu finden ist.

Da sie mit unkuratierten Internetdaten trainiert wurden, kann die GPT-3-Ausgabe peinlich, wenn nicht gar schädlich sein.
Sie benötigen also möglicherweise acht Entwürfe, um sicherzustellen, dass Sie am Ende etwas Passendes für die Veröffentlichung haben.
Der Unterschied zwischen der MarketMuse NLG-Technologie und GPT-3
Die MarketMuse NLG-Technologie hilft Content-Teams bei der Erstellung von Artikeln in Langform. Wenn Sie daran denken, GPT-3 auf diese Weise zu verwenden, werden Sie enttäuscht sein.
Mit GPT-3 werden Sie Folgendes entdecken:
- Es ist wirklich nur ein Sprachmodell auf der Suche nach einer Lösung.
- Für den Zugriff auf die API sind Programmierkenntnisse und -kenntnisse erforderlich.
- Die Ausgabe hat keine Struktur und neigt dazu, in ihrer thematischen Abdeckung sehr oberflächlich zu sein.
- Keine Workflow-Überlegung macht die Verwendung von GPT-3 ineffizient.
- Die Ausgabe ist nicht für SEO optimiert, sodass Sie sowohl einen Redakteur als auch einen SEO-Experten benötigen, um sie zu überprüfen.
- Es kann keine langen Inhalte produzieren, leidet unter Verschlechterung und Wiederholung und prüft nicht auf Plagiate.
Die MarketMuse NLG-Technologie bietet viele Vorteile:
- Es wurde speziell entwickelt, um Content-Teams dabei zu helfen, vollständige Customer Journeys zu erstellen und ihre Markengeschichten mithilfe von KI-generierten, redaktionsfertigen Inhaltsentwürfen schneller zu erzählen.
- Die KI-gestützte Plattform zur Inhaltsgenerierung erfordert keine technischen Kenntnisse.
- Die MarketMuse NLG-Technologie ist durch KI-gestützte Content Briefs strukturiert. Sie erfüllen garantiert den Target Content Score von MarketMuse, eine wertvolle Metrik, die die Vollständigkeit eines Artikels misst.
- Die MarketMuse NLG-Technologie verbindet sich direkt mit der Inhaltsplanung/-strategie mit der Inhaltserstellung in der MarketMuse Suite. Die Erstellung der Inhaltsplanung wird vollständig durch die Technologie ermöglicht, bis hin zur Bearbeitung und Veröffentlichung.
- Zusätzlich zur gründlichen Abdeckung eines Themas ist die MarketMuse NLG-Technologie für die Suche optimiert.
- Die NLG-Technologie von MarketMuse generiert Inhalte in Langform ohne Plagiate, Wiederholungen oder Herabsetzung.
Funktionsweise der NLG-Technologie von MarketMuse
Ich hatte die Gelegenheit, mit Ahmed Dawod und Shash Krishna, zwei Forschungsingenieuren für maschinelles Lernen im MarketMuse Data Science Team, zu sprechen. Ich bat sie, die Funktionsweise von MarketMuse NLG Technology und den Unterschied zwischen den Ansätzen von MarketMuse NLG Technology und GPT-3 zu erläutern.
Hier ist eine Zusammenfassung dieses Gesprächs.
Die zum Trainieren eines natürlichen Sprachmodells verwendeten Daten spielen eine entscheidende Rolle. MarketMuse ist sehr wählerisch bei den Daten, die es zum Trainieren seines Modells zur Generierung natürlicher Sprache verwendet. Wir haben sehr strenge Filter, um saubere Daten zu gewährleisten, die Vorurteile in Bezug auf Geschlecht, Rasse und Religion vermeiden.
Außerdem wird unser Model ausschließlich an gut strukturierten Artikeln trainiert. Wir verwenden keine Reddit-Posts oder Social-Media-Posts und dergleichen. Obwohl wir über Millionen von Artikeln sprechen, handelt es sich im Vergleich zu der Menge und Art der Informationen, die bei anderen Ansätzen verwendet werden, immer noch um eine sehr raffinierte und kuratierte Sammlung. Beim Trainieren des Modells verwenden wir viele andere Datenpunkte, um es zu strukturieren, einschließlich des Titels, der Unterüberschrift und verwandter Themen für jede Unterüberschrift.
GPT-3 verwendet ungefilterte Daten aus Common Crawl, Wikipedia und anderen Quellen. Sie sind nicht sehr wählerisch in Bezug auf die Art oder Qualität der Daten. Wohlgeformte Artikel machen etwa 3 % des Webinhalts aus, was bedeutet, dass nur 3 % der Trainingsdaten für GPT-3 aus Artikeln bestehen. Ihr Modell ist nicht darauf ausgelegt, Artikel zu schreiben, wenn man so darüber nachdenkt.
Wir verfeinern unser NLG-Modell mit jeder Generationsanfrage. An dieser Stelle sammeln wir einige tausend gut strukturierte Artikel zu einem bestimmten Thema. Genau wie die Daten, die für das Basismodelltraining verwendet werden, müssen diese alle unsere Qualitätsfilter durchlaufen. Die Artikel werden analysiert, um den Titel, Unterabschnitte und verwandte Themen für jeden Unterabschnitt zu extrahieren. Diese Daten speisen wir für eine weitere Trainingsphase wieder in das Trainingsmodell ein. Dies führt das Modell von einem Zustand, in dem es allgemein über ein Thema sprechen kann, zu einem mehr oder weniger fachkundigen Reden.
Darüber hinaus verwendet die MarketMuse NLG-Technologie Meta-Tags wie Titel, Unterüberschriften und ihre verwandten Themen, um eine Anleitung bei der Textgenerierung zu geben. Dies gibt uns so viel mehr Kontrolle. Es lehrt das Modell im Grunde so, dass es beim Generieren von Text diese wichtigen verwandten Themen in seine Ausgabe einbezieht.
GPT-3 hat keinen solchen Kontext; es verwendet nur einen einleitenden Absatz. Es ist wahnsinnig schwierig, ihr riesiges Modell zu optimieren, und erfordert eine riesige Infrastruktur, nur um Inferenzen auszuführen, ganz zu schweigen von der Feinabstimmung.
So erstaunlich GPT-3 auch sein mag, ich würde keinen Cent bezahlen, um es zu benutzen. Es ist unbrauchbar! Wie der Guardian-Artikel zeigt, werden Sie viel Zeit damit verbringen, die verschiedenen Ausgaben in einem veröffentlichungsfähigen Artikel zu bearbeiten.
Selbst wenn das Modell gut ist, wird es über das Thema sprechen, wie es jeder normale Nicht-Experte tun würde. Das liegt an der Art und Weise, wie ihr Modell lernt. Tatsächlich ist es wahrscheinlicher, dass es wie ein Social-Media-Nutzer spricht, da dies der Großteil seiner Trainingsdaten ist.
Andererseits wird MarketMuse NLG Technology an gut strukturierten Artikeln trainiert und dann gezielt anhand von Artikeln zum spezifischen Thema des Entwurfs verfeinert. Auf diese Weise ähnelt die Ausgabe der NLG-Technologie von MarketMuse eher den Gedanken eines Experten als GPT-3.
Zusammenfassung
Die MarketMuse NLG-Technologie wurde entwickelt, um eine bestimmte Herausforderung zu lösen. wie man Content-Teams dabei unterstützt, schneller bessere Inhalte zu produzieren. Es ist eine natürliche Erweiterung unserer bereits erfolgreichen KI-gestützten Inhaltsbeschreibungen.
Obwohl GPT-3 vom Forschungsstandpunkt aus spektakulär ist, ist es noch ein langer Weg, bis es nutzbar ist.
Was Sie jetzt tun sollten
Wenn Sie bereit sind … hier sind 3 Möglichkeiten, wie wir Ihnen helfen können, bessere Inhalte schneller zu veröffentlichen:
- Buchen Sie Zeit mit MarketMuse Planen Sie eine Live-Demo mit einem unserer Strategen, um zu sehen, wie MarketMuse Ihrem Team helfen kann, seine Content-Ziele zu erreichen.
- Wenn Sie erfahren möchten, wie Sie schneller bessere Inhalte erstellen, besuchen Sie unseren Blog. Es ist voll von Ressourcen, um Inhalte zu skalieren.
- Wenn Sie einen anderen Vermarkter kennen, der diese Seite gerne lesen würde, teilen Sie sie ihm per E-Mail, LinkedIn, Twitter oder Facebook.