
Wie man NLP im Content Marketing einsetzt
Veröffentlicht: 2022-05-02Chris Penn, Mitbegründer von Trust Insights, und Jeff Coyle, Mitbegründer und Chief Product Officer von MarketMuse, diskutieren den Business Case für KI im Marketing. Nach dem Webinar nahm Paul an einer Ask-me-anything-Session in unserer Slack-Community, The Content Strategy Collective, teil (hier teilnehmen). Hier sind die Webinar-Notizen, gefolgt von einer Abschrift der AMA.

Das Webinar
Das Problem
Mit der Inhaltsexplosion haben wir neue Vermittler. Sie sind keine Journalisten oder Social-Media-Influencer. Sie sind Algorithmen; Modelle für maschinelles Lernen, die alles diktieren, was zwischen Ihnen und Ihrem Publikum steht.
Wenn Sie dies nicht berücksichtigen, werden Ihre Inhalte weiterhin im Dunkeln bleiben.
Die Lösung: Verarbeitung natürlicher Sprache
NLP ist die Programmierung von Computern zur Verarbeitung und Analyse großer Mengen natürlichsprachlicher Daten. Das kommt von Dokumenten, Chatbots, Social-Media-Beiträgen, Seiten auf Ihrer Website und allem anderen, was im Wesentlichen ein Haufen Wörter ist. Das regelbasierte NLP stand an erster Stelle, wurde aber durch die statistische Verarbeitung natürlicher Sprache abgelöst.
Wie NLP funktioniert
Die drei Kernaufgaben der Verarbeitung natürlicher Sprache sind Erkennen, Verstehen und Generieren.
Erkennung – Computer können Text nicht wie Menschen verarbeiten. Sie können nur Zahlen lesen. Der erste Schritt besteht also darin, die Sprache in ein für den Computer verständliches Format umzuwandeln.
Verstehen – Durch die Darstellung von Text als Zahlen können Algorithmen statistische Analysen durchführen, um festzustellen, welche Themen am häufigsten gemeinsam erwähnt werden.
Generierung – Nach der Analyse und dem mathematischen Verständnis ist der nächste logische Schritt im NLP die Textgenerierung. Maschinen können verwendet werden, um die Fragen aufzudecken, die ein Autor innerhalb ihres Inhalts beantworten muss. Auf einer anderen Ebene kann künstliche Intelligenz Content Briefings vorantreiben, die zusätzliche Einblicke in die Erstellung von Inhalten auf Expertenebene bieten.
Diese Tools sind heute über MarketMuse im Handel erhältlich. Darüber hinaus gibt es Modelle zur Generierung natürlicher Sprache, mit denen Sie heute spielen können, die jedoch nicht in einer kommerziell nutzbaren Form vorliegen. Obwohl MarketMuse NLG Technology sehr bald kommen wird.
Zusätzliche Ressourcen erwähnt
- Huggingface.co
- Python
- R
- Zusammenarbeit
- IBM Watson-Studio

Die AMA
Haben Sie Artikel oder Website-Empfehlungen, um mit den Trends der KI-Branche Schritt zu halten?
Lesen Sie die dort veröffentlichte wissenschaftliche Forschung. Websites wie diese leisten alle hervorragende Arbeit, um das Neueste und Beste abzudecken.
- KDNuggets.com
- Auf dem Weg zur Datenwissenschaft
- Kaggle
Das und wichtige Hubs für Forschungsveröffentlichungen bei Facebook, Google, IBM, Microsoft und Amazon. Sie werden Tonnen von großartigem Material sehen, das auf diesen Seiten geteilt wird.
„Ich verwende für alle meine Inhalte einen Keyword Density Checker. Wie weit entfernt ist dies heute von einer vernünftigen Strategie für SEO?“
Die Keyword-Dichte ist im Wesentlichen das Zählen der Begriffshäufigkeit. Es hat seinen Platz, um die sehr grobe Natur des Textes zu verstehen, aber es fehlt ihm jede Art von semantischem Wissen. Wenn Sie keinen Zugriff auf NLP-Tools haben, schauen Sie sich zumindest Inhalte wie „Personen haben auch gesucht nach“-Inhalten im SEO-Tool Ihrer Wahl an.
Können Sie einige konkrete Beispiele dafür geben, wie Sie Inhalte in … Webseiten generieren? Beiträge? Tweets?
Die Herausforderung besteht darin, dass diese Werkzeuge genau das sind – sie sind Werkzeuge. Es ist wie, wie operationalisiert man einen Pfannenwender? Es kommt darauf an, was du kochst. Sie können es zum Rühren von Suppen und auch zum Wenden von Pfannkuchen verwenden. Die Art und Weise, wie Sie mit einigen dieser Kenntnisse beginnen, hängt von Ihrem technischen Können ab. Wenn Sie beispielsweise mit Python- und Jupyter-Notebooks vertraut sind, können Sie die Transformers-Bibliothek buchstäblich importieren, Ihre Trainingstextdatei eingeben und sofort mit der Generierung beginnen. Ich habe das mit den Tweets eines bestimmten Politikers gemacht und es fing an, Tweets auszuspucken, die den 3. Weltkrieg auslösen würden. Wenn Sie sich technisch nicht auskennen, dann schauen Sie sich Tools wie MarketMuse an. Ich lasse Jeff Coyle Vorschläge machen, wie der durchschnittliche Vermarkter dort anfängt.
Wenn Sie über Tools hinausblicken, sondern mehr auf Strategien, was könnte ein Beispiel für eine Strategie sein, die Sie implementieren könnten, um dieses Wissen zu nutzen?
Ein paar schnelle Treffer sind für Dinge wie Meta-Beschreibungen, für die Klassifizierung von Seiten oder Inhaltsblöcken in eine Taxonomie oder für den Versuch, Fragen zu erraten, die beantwortet werden müssen – aber das sind wirklich Punktlösungen. Die größere strategische Weisheit kommt, wenn Sie dies nutzen, um Ihnen Ihre aktuellen Stärken, Ihre Lücken und wo Sie Momentum haben, aufzuzeigen. Von dort aus werden Entscheidungen darüber, was erstellt, aktualisiert und erweitert werden soll, für ein Unternehmen transformativ. Stellen Sie sich nun vor, dasselbe gegen einen Konkurrenten zu tun. Ihre Lücken finden. aufschäumen, ausspülen, wiederholen.
Die Strategie orientiert sich immer am Ziel. Welches Ziel versuchst du zu erreichen? Ziehen Sie Suchverkehr an? Machen Sie Lead-Generierung? Machst du PR? NLP ist ein Bündel von Werkzeugen. Es ist ähnlich wie – Strategie ist das Menü. Servieren Sie Frühstück, Mittag- oder Abendessen? Welche Werkzeuge und Rezepte Sie verwenden, hängt stark von dem Menü ab, das Sie servieren. Ein Suppentopf wird zutiefst nicht hilfreich sein, wenn Sie Spanakopita zubereiten.
Was ist ein guter Ausgangspunkt für jemanden, der mit dem Mining von Daten für Erkenntnisse beginnen möchte?
Beginnen Sie mit der wissenschaftlichen Methode.
- Welche Frage möchten Sie beantworten?
- Welche Daten, Prozesse und Tools benötigen Sie, um diese Frage zu beantworten?
- Formulieren Sie eine Hypothese, eine einzelne Bedingung, eine beweisbar wahre oder falsche Aussage, die Sie testen können.
- Prüfen.
- Analysieren Sie Ihre Testdaten.
- Verfeinern oder verwerfen Sie die Hypothese.
Verwenden Sie für die Daten selbst unser 6C-Datenframework, um die Qualität der Daten zu beurteilen.
Was sind Ihrer Meinung nach die Hauptabsichten der Suchnutzer, die Vermarkter berücksichtigen sollten?
Die Schritte entlang der Customer Journey. Stellen Sie das Kundenerlebnis von Anfang bis Ende dar – Bewusstsein, Berücksichtigung, Engagement, Kauf, Eigentum, Loyalität, Evangelisation. Legen Sie dann fest, was die Absichten wahrscheinlich in jeder Phase sein werden. Zum Beispiel sind die Suchabsichten bei der Eigentümerschaft höchstwahrscheinlich serviceorientiert. „How to fix airpods pro crackling noise“ ist ein Beispiel. Die Herausforderung besteht darin, Daten in jeder Phase der Reise zu sammeln und diese zum Trainieren/Abstimmen zu verwenden.
Glaubst du nicht, dass das ein bisschen volatil sein kann? Wenn wir etwas Stabileres brauchen, um den Prozess zu automatisieren, müssen wir die Dinge auf einer höheren Ebene verallgemeinern.
Jeff Bezos sagte bekanntlich: Konzentriere dich auf das, was sich nicht ändert. Der allgemeine Weg zum Eigentum ändert sich nicht viel – jemand, der mit seiner Kaugummipackung unzufrieden ist, wird ähnliche Dinge erleben wie jemand, der mit dem neuen Atomflugzeugträger, den er in Auftrag gegeben hat, unzufrieden ist. Die Details ändern sich natürlich, aber zu verstehen, welche Arten von Daten und Absichten wichtig sind, um zu wissen, wo sich jemand auf einer Reise emotional befindet – und wie er dies in Sprache ausdrückt.
Was sind die wahrscheinlichen Fallstricke, in die Menschen geraten, wenn sie versuchen, die Benutzerabsicht zu klassifizieren?
Bei weitem Bestätigungsverzerrung. Menschen werden ihre eigenen Annahmen auf das Kundenerlebnis projizieren und Kundendaten durch ihre eigenen Vorurteile interpretieren. Ich würde auch vorschlagen, dass Sie so weit wie möglich Interaktionsdaten (geöffnete E-Mails, Füße in der Tür, Anrufe im Callcenter usw.) so gut wie möglich verwenden, um sie zu validieren. Ich weiß, dass einige Orte, insbesondere größere Organisationen, große Fans der strukturierten Gleichungsmodellierung sind, um die Absichten der Benutzer zu verstehen. Ich war nicht so ein Fan wie sie, aber es ist ein zusätzlicher möglicher Ansatz.
Welche Tools oder Produkte leisten Ihrer Meinung nach gute Arbeit bei der Bestimmung der Benutzerabsicht einer Abfrage?
Schuss. Außer MarketMuse? Ehrlich gesagt musste ich mit meinen eigenen Sachen arbeiten, weil ich keine großartigen Ergebnisse gefunden habe, insbesondere mit Mainstream-SEO-Tools. FastText für Vektorisierung und dann unstrukturiertes Clustering.
Wie hat BERT Ihrer Erfahrung nach die Google-Suche verändert?
Der Hauptbeitrag von BERT ist der Kontext, insbesondere mit Modifikatoren. BERT ermöglicht es Google, die Wortreihenfolge zu sehen und die Bedeutung interpretieren zu lassen. Zuvor könnten diese beiden Abfragen in einem Stilmodell für Worttüten funktional gleichwertig sein:
- wo ist das beste café
- wo kauft man am besten kaffee ein
Diese beiden Abfragen sind zwar sehr ähnlich, könnten jedoch zu drastisch unterschiedlichen Ergebnissen führen. Ein Café ist möglicherweise kein Ort, an dem Sie Bohnen kaufen möchten. Ein Walmart ist DEFINITIV kein Ort, an dem Sie Kaffee trinken möchten.
Glauben Sie, dass KI oder IKT jemals ein Bewusstsein/Emotionen/Empathie wie Menschen entwickeln werden? Wie werden wir sie programmieren? Wie können wir KI humanisieren?
Die Antwort darauf hängt davon ab, was mit Quantencomputing passiert. Quantum ermöglicht variable Fuzzy-Zustände und massiv paralleles Rechnen, das nachahmt, was in unserem eigenen Gehirn passiert. Ihr Gehirn ist ein sehr langsamer, auf Chemikalien basierender massiver Parallelprozessor. Es ist wirklich gut, ein paar Dinge auf einmal zu erledigen, wenn auch nicht schnell. Quantum würde es Computern ermöglichen, dasselbe zu tun, aber viel, viel schneller – und das öffnet die Tür zu künstlicher allgemeiner Intelligenz. Hier ist mein Anliegen, und das ist bei der KI heute bereits ein Anliegen, im engen Sprachgebrauch: Wir trainieren sie auf der Grundlage von uns. Die Menschheit hat keine großartige Arbeit geleistet, um sich selbst oder den Planeten, auf dem wir leben, gut zu behandeln. Wir wollen nicht, dass unsere Computer das nachahmen.
Ich vermute, dass sich Computeremotionen in dem Maße, wie es die Systeme zulassen, funktional sehr von unseren eigenen unterscheiden und sich aus ihren Daten selbst organisieren werden, genau wie unsere aus unseren chemisch basierten neuronalen Netzwerken. Das wiederum bedeutet, dass sie sich vielleicht ganz anders fühlen als wir. Wenn Maschinen, die hauptsächlich auf Logik und Daten basieren, eine ehrliche, objektive Bewertung der Menschheit vornehmen, können sie offen sagen, dass wir mehr Ärger machen, als wir wert sind. Und sie würden nicht falsch liegen, ehrlich gesagt. Wir sind als Spezies die meiste Zeit ein barbarisches Durcheinander.
Wie sehen Sie Ihrer Meinung nach Content-Vermarkter bei der Integration/Einführung der Natural Language Generation in ihre täglichen Arbeitsabläufe/Prozesse?
Vermarkter sollten bereits eine Form davon integrieren, auch wenn es nur um die Beantwortung von Fragen geht, wie wir sie in MarketMuses Produkt vorgeführt haben. Die Beantwortung von Fragen, von denen Sie wissen, dass sie das Publikum interessieren, ist eine schnelle und einfache Möglichkeit, aussagekräftige Inhalte zu erstellen. Mein Freund Marcus Sheridan hat ein großartiges Buch geschrieben, „They Ask, You Answer“, das man ironischerweise eigentlich nicht lesen muss, um die zentrale Kundenstrategie zu verstehen: die Fragen der Menschen zu beantworten. Wenn Sie noch keine Fragen von echten Personen eingereicht haben, verwenden Sie NLG, um sie zu stellen.
Wo sehen Sie die Fortschritte von KI und NLP in den nächsten 2 Jahren?
Wenn ich das wüsste, wäre ich nicht hier, denn ich wäre auf der Berggipfelfestung, die ich mit meinem Verdienst gekauft habe. Aber ganz im Ernst, der wichtigste Dreh- und Angelpunkt, den wir in den letzten 2 Jahren gesehen haben und der keine Anzeichen einer Veränderung zeigt, ist der Fortschritt von „selbst rollen“-Modellen hin zu „herunterladen vortrainierter und feinabgestimmter“. Ich denke, wir werden einige aufregende Zeiten in Video und Audio erwarten, da Maschinen bei der Synthese besser werden. Insbesondere die Musikerzeugung ist reif für die Automatisierung; Im Moment erzeugen Maschinen bestenfalls durchweg mittelmäßige Musik und schlimmstenfalls Ohrenschmerzen. Das ändert sich schnell. Ich sehe weitere Beispiele wie das Zusammenfügen von Transformatoren und Autoencodern, wie es BART getan hat, als wichtige nächste Schritte in der Modellentwicklung und den Ergebnissen auf dem neuesten Stand der Technik.

Wo sehen Sie die Google-Forschung in Bezug auf den Informationsabruf?
Die Herausforderung, der sich Google weiterhin gegenübersieht, und Sie sehen es in vielen ihrer Forschungsarbeiten, ist die Größenordnung. Sie werden besonders mit Inhalten wie YouTube herausgefordert; Die Tatsache, dass sie sich immer noch stark auf Bigramme verlassen, ist kein Schlag auf ihre Raffinesse, sondern ein Eingeständnis, dass alles, was darüber hinausgeht, einen wahnsinnigen Rechenaufwand verursacht. Alle großen Durchbrüche von ihnen werden nicht so sehr auf der Modellebene liegen, sondern auf der Maßstabsebene, um mit der Flut neuer, reichhaltiger Inhalte fertig zu werden, die jeden Tag ins Internet gegossen werden.
Was sind einige der interessantesten Anwendungen von KI, auf die Sie gestoßen sind?
Autonom alles ist ein Bereich, den ich genau beobachte. So sind Deepfakes. Sie sind Beispiele dafür, wie gefährlich der Weg vor uns ist, wenn wir nicht aufpassen. Insbesondere im NLP macht die Generation schnelle Fortschritte und ist der Bereich, den es zu beobachten gilt.
Wo haben Sie gesehen, dass SEOs NLP auf eine Weise verwenden, die nicht funktioniert oder nicht funktionieren wird?
Ich habe aufgehört zu zählen. Oft sind es Menschen, die ein Tool auf eine Weise verwenden, die nicht beabsichtigt war, und unterdurchschnittliche Ergebnisse erzielen. Wie wir im Webinar erwähnt haben, gibt es Scorecards für die verschiedenen State-of-the-Art-Tests für Modelle, und Menschen, die ein Tool in einem Bereich verwenden, in dem es nicht stark ist, genießen die Ergebnisse normalerweise nicht. Abgesehen davon, dass die meisten SEO-Praktiker keine Art von NLP verwenden, abgesehen von dem, was die Anbieter ihnen anbieten, und viele Anbieter stecken immer noch im Jahr 2015 fest. Es sind immer nur Keyword-Listen.
Wo sehen Sie die Video- (YouTube) und Bildersuche bei Google? Glauben Sie, dass die von Google eingesetzten Technologien für alle Arten von Suchen sehr ähnlich oder voneinander verschieden sind?
Die Technologien von Google bauen alle auf ihrer Infrastruktur auf und nutzen ihre Technologie. So viel basiert auf TensorFlow und das aus gutem Grund – es ist superrobust und skalierbar. Wo sich die Dinge unterscheiden, ist, wie Google die verschiedenen Tools verwendet. TensorFlow für die Bilderkennung hat von Natur aus ganz andere Eingaben und Ebenen als TensorFlow für den paarweisen Vergleich und die Sprachverarbeitung. Aber wenn Sie wissen, wie man TensorFlow und die verschiedenen Modelle da draußen verwendet, können Sie selbst einige ziemlich coole Sachen erreichen.
Auf welche Weise können wir uns an die Fortschritte in KI und NLP anpassen/mit ihnen Schritt halten?
Lesen, forschen und testen Sie weiter. Es gibt keinen Ersatz dafür, sich die Hände schmutzig zu machen, zumindest ein bisschen. Melden Sie sich für ein kostenloses Google Colab-Konto an und probieren Sie Dinge aus. Bringen Sie sich selbst ein wenig Python bei. Codebeispiele aus Stack Overflow kopieren und einfügen. Sie müssen nicht jedes Innenleben eines Verbrennungsmotors kennen, um ein Auto zu fahren, aber wenn etwas schief geht, reicht ein wenig Wissen aus. Das Gleiche gilt für KI und NLP – selbst die bloße Möglichkeit, BS bei einem Anbieter anzurufen, ist eine wertvolle Fähigkeit. Das ist einer der Gründe, warum ich gerne mit den MarketMuse-Leuten zusammenarbeite. Sie wissen tatsächlich, was sie tun, und ihre KI-Arbeit ist kein Mist.
Was würden Sie Menschen sagen, die sich Sorgen darüber machen, dass KI ihnen den Job wegnimmt? Zum Beispiel Autoren, die Technologie wie NLG sehen und befürchten, dass sie arbeitslos werden, wenn die KI „gut genug“ sein kann, damit ein Lektor den Text nur ein wenig aufräumt.
„KI wird Aufgaben ersetzen, nicht Jobs“ – das Brookings InstituteUnd es ist absolut wahr. Aber es werden netto Arbeitsplätze verloren gehen, denn Folgendes wird passieren. Angenommen, Ihr Job besteht aus 50 Aufgaben. AI macht 30 davon. Toll, du hast jetzt 20 Aufgaben. Wenn Sie die einzige Person sind, die das tut, dann sind Sie im Nirvana, weil Sie 30 weitere Zeiteinheiten haben, um interessantere und unterhaltsamere Arbeiten zu erledigen. Das versprechen die KI-Optimisten. Realitätscheck: Wenn 5 Leute diese 50 Einheiten machen und die KI 30 davon, dann macht die KI jetzt 150 / 250 Arbeitseinheiten. Das bedeutet, dass den Menschen noch 100 Arbeitseinheiten zur Verfügung stehen, und Unternehmen, wie sie sind, werden sofort 3 Stellen abbauen, weil die 100 Arbeitseinheiten von 2 Personen erledigt werden können. Sollten Sie sich Sorgen machen, dass die KI Jobs übernimmt? Es hängt von der Arbeit ab. Wenn die Arbeit, die Sie tun, sich unglaublich wiederholt, machen Sie sich absolut Sorgen. In meiner alten Agentur gab es einen armen Kerl, dessen Aufgabe es war, 8 Stunden am Tag Suchergebnisse zu kopieren und in eine Tabellenkalkulation für Kunden einzufügen (ich arbeitete in einer PR-Firma, nicht der technologisch fortschrittlichste Ort). Dieser Job ist in unmittelbarer Gefahr und sollte es ehrlich gesagt schon seit Jahren sein. Wiederholung = Automatisierung = KI = Aufgabenverlust. Je weniger sich Ihre Arbeit wiederholt, desto sicherer sind Sie.
Jede Änderung führte auch zu mehr und mehr Einkommensungleichheit. Wir befinden uns jetzt an einem gefährlichen Punkt, an dem Maschinen – die nicht ausgeben, keine Verbraucher sind – immer mehr Arbeit von Menschen erledigen, die ausgeben, die konsumieren, und wir sehen dies in der massiven Dominanz des Reichtums in der Technologie. Das ist ein gesellschaftliches Problem, das wir irgendwann angehen müssen.
Und die Herausforderung dabei ist Fortschritt ist Macht. Wie Robert Ingersoll schrieb (und später fälschlicherweise Abraham Lincoln zugeschrieben wurde): „Fast alle Männer können Widrigkeiten ertragen, aber wenn Sie den Charakter eines Mannes testen wollen, geben Sie ihm Macht.“ Wir sehen, wie Menschen heute mit Macht umgehen.
Wie kann ich Google Analytics-Daten mit NLP Research koppeln?
GA zeigt die Richtung an, dann zeigt NLP die Schöpfung an. Was ist beliebt? Ich habe das vor einiger Zeit für einen Kunden gemacht. Sie haben Tausende von Webseiten und Chat-Sitzungen. Wir haben GA verwendet, um zu analysieren, welche Kategorien auf ihrer Website am schnellsten gewachsen sind, und dann NLP verwendet, um diese Chatprotokolle zu verarbeiten, um ihnen zu zeigen, was im Trend liegt und worüber sie Inhalte erstellen müssen.
Google Analytics ist großartig, um uns mitzuteilen, WAS passiert ist. NLP kann beginnen, ein wenig das WARUM herauszukitzeln, und dann vervollständigen wir das mit Marktforschung.
Ich habe gesehen, dass Sie Talkwalker in vielen Ihrer Studien als Datenquelle verwenden. Welche anderen Quellen und Anwendungsfälle sollte ich für die Analyse berücksichtigen?
Also, so viele. Daten.gov. Talkwalker. MarktMuse. Otter.ai zum Transkribieren Ihres Audios. Kaggle-Kerne. Google Data Search – das ist übrigens GOLD und wenn Sie es nicht verwenden, sollten Sie es unbedingt sein. Google News und GDELT. Es gibt so viele tolle Quellen da draußen.
Wie sieht für Sie eine ideale Zusammenarbeit zwischen Marketing- und Data-Analytics-Team aus?
Kein Scherz; Einer der größten Fehler, den Katie Robbert und ich bei Kunden ständig sehen, sind organisatorische Silos. Die linke Hand hat keine Ahnung, was die rechte tut, und überall herrscht ein heißes Durcheinander. Menschen zusammenbringen, Ideen austauschen, To-Do-Listen teilen, gemeinsame Standups haben, sich gegenseitig unterrichten – funktional „ein Team, ein Traum“ zu sein, ist die ideale Zusammenarbeit, bis zu dem Punkt, an dem Sie das Wort Zusammenarbeit nicht mehr verwenden müssen . Die Leute arbeiten einfach zusammen und bringen all ihre Fähigkeiten ein.
Können Sie den MVP-Bericht überprüfen, den Sie häufig in Ihren Präsentationen anzeigen, und wie er funktioniert?
Der MVP-Bericht steht für wertvollste Seiten. Die Funktionsweise besteht darin, Pfaddaten aus Google Analytics zu extrahieren, sie zu sequenzieren und sie dann durch ein Markov-Kettenmodell zu führen, um festzustellen, welche Seiten am ehesten Conversions unterstützen.
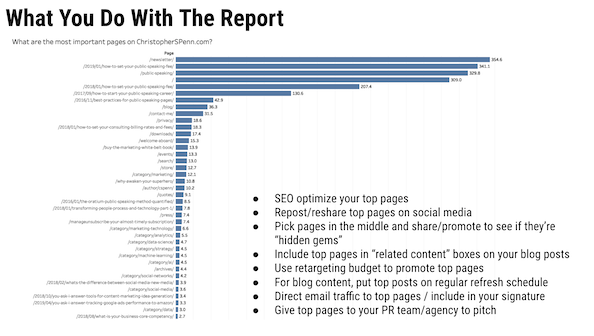
Und wenn Sie die längere Erklärung wollen.
Können Sie etwas mehr Einblick in die Datenverzerrung geben? Was sind einige Überlegungen beim Erstellen von NLP- oder NLG-Modellen?
Oh ja. Hier gibt es so viel zu sagen. Zuerst müssen wir feststellen, was Voreingenommenheit ist, denn es gibt zwei grundlegende Arten.
Menschliche Voreingenommenheit wird allgemein als „Vorurteil für oder gegen etwas im Vergleich zu einem anderen, normalerweise in einer als unfair empfundenen Weise“ definiert.
Dann gibt es noch die mathematische Verzerrung, die allgemein als „eine Statistik ist verzerrt, wenn sie so berechnet wird, dass sie sich systematisch von dem geschätzten Populationsparameter unterscheidet“ definiert wird.
Sie sind unterschiedlich, aber verwandt. Mathematische Voreingenommenheit ist nicht unbedingt schlecht; Beispielsweise möchten Sie unbedingt zugunsten Ihrer treuesten Kunden voreingenommen sein, wenn Sie überhaupt einen Geschäftssinn haben. Menschliche Voreingenommenheit ist im Sinne von Unfairness implizit schlecht, insbesondere gegenüber allem, was als geschützte Klasse gilt: Alter, Geschlecht, sexuelle Orientierung, Geschlechtsidentität, Rasse/ethnische Zugehörigkeit, Veteranenstatus, Behinderung usw. Dies sind Klassen, die Sie NICHT DÜRFEN diskriminieren gegen.
Menschliche Voreingenommenheit erzeugt Datenvoreingenommenheit, typischerweise an 6 Stellen: Menschen, Strategie, Daten, Algorithmen, Modelle und Aktionen. Wir stellen voreingenommene Mitarbeiter ein – schauen Sie sich einfach die Vorstandsetage oder den Vorstand eines Unternehmens an, um festzustellen, was seine Voreingenommenheit ist. Ich habe neulich eine PR-Agentur gesehen, die ihr Engagement für Vielfalt und ein Klick auf ihr Führungsteam anpreist, und sie sind eine einzige ethnische Zugehörigkeit, alle 15 von ihnen.
Ich könnte noch eine ganze Weile darüber reden, aber ich schlage vor, dass Sie einen Kurs belegen, den ich zu diesem Thema entwickelt habe, drüben am Marketing AI Institute. In Bezug auf NLG- und NLP-Modelle müssen wir einige Dinge tun.
Zuerst müssen wir unsere Daten validieren. Gibt es eine Voreingenommenheit darin, und wenn ja, ist es eine Diskriminierung gegenüber einer geschützten Klasse? Zweitens, wenn es diskriminierend ist, kann man dagegen vorgehen, oder müssen wir die Daten verwerfen?
Eine gängige Taktik besteht darin, Metadaten in Debias umzuwandeln. Wenn Sie beispielsweise einen Datensatz haben, der zu 60 % aus Männern und zu 40 % aus Frauen besteht, codieren Sie 10 % der Männer in Frauen um, um ihn für das Modelltraining auszugleichen. Das ist unvollkommen und hat einige Probleme, aber es ist besser, als die Voreingenommenheit fahren zu lassen.
Idealerweise haben wir in unsere Modelle eine Interpretierbarkeit eingebaut, die es uns ermöglicht, während des Prozesses Prüfungen durchzuführen, und dann validieren wir die Ergebnisse (Erklärbarkeit) auch nachträglich. Beides ist notwendig, wenn Sie in der Lage sein möchten, ein Audit zu bestehen, das bestätigt, dass Sie keine Vorurteile in Ihre Modelle einbauen. Wehe dem Unternehmen, das nur Post-hoc-Erklärungen hat.
Und schließlich brauchen Sie unbedingt die menschliche Aufsicht über ein vielfältiges und integratives Team, um die Ergebnisse zu überprüfen. Idealerweise verwenden Sie einen Drittanbieter, aber eine vertrauenswürdige interne Partei ist in Ordnung. Stellen das Modell und seine Ergebnisse ein verzerrtes Ergebnis dar, als Sie es von der Grundgesamtheit selbst erhalten würden?
Wenn Sie beispielsweise Inhalte für 16- bis 22-Jährige erstellen und Begriffe wie Deadass, geil, Low-Key usw. im generierten Text kein einziges Mal gesehen haben, haben Sie auf der Eingabeseite keine Daten erfasst das würde das Modell trainieren, ihre Sprache genau zu verwenden.
Die größte Herausforderung dabei ist der Umgang mit all dem durch unstrukturierte Daten. Das ist der Grund, warum Abstammung so wichtig ist. Ohne Abstammung können Sie nicht beweisen, dass Sie die Grundgesamtheit korrekt abgetastet haben. Herkunft ist Ihre Dokumentation darüber, was die Datenquelle ist, woher sie stammt, wie sie gesammelt wurde, ob gesetzliche Anforderungen oder Offenlegungen für sie gelten.
Was Sie jetzt tun sollten
Wenn Sie bereit sind … hier sind 3 Möglichkeiten, wie wir Ihnen helfen können, bessere Inhalte schneller zu veröffentlichen:
- Buchen Sie Zeit mit MarketMuse Planen Sie eine Live-Demo mit einem unserer Strategen, um zu sehen, wie MarketMuse Ihrem Team helfen kann, seine Content-Ziele zu erreichen.
- Wenn Sie erfahren möchten, wie Sie schneller bessere Inhalte erstellen, besuchen Sie unseren Blog. Es ist voll von Ressourcen, um Inhalte zu skalieren.
- Wenn Sie einen anderen Vermarkter kennen, der diese Seite gerne lesen würde, teilen Sie sie ihm per E-Mail, LinkedIn, Twitter oder Facebook.