
Identifizieren subjektiver Attribute von Entitäten
Veröffentlicht: 2022-05-13Identifizieren von UGC-subjektiven Attributen von Entitäten
Bei diesem kürzlich erteilten Patent geht es darum, subjektive Attribute von Entitäten zu identifizieren.
Ich habe kein Patent über subjektive Attribute von Entitäten oder Reaktionen auf diese Entitäten gesehen.
Ein kritischer Aspekt dabei ist, dass es sich um nutzergenerierte Inhalte handelt.
Uns wird gesagt, dass nutzergenerierte Inhalte (UGC) aufgrund der zunehmenden Popularität von sozialen Netzwerken, Blogs, Bewertungsseiten usw. im Web immer häufiger vorkommen.
Wir sehen oft von Benutzern generierte Inhalte in Form von Kommentaren, wie zum Beispiel:
- Ein Kommentar eines ersten Benutzers zu Inhalten, die von einem zweiten Benutzer innerhalb eines sozialen Netzwerks geteilt werden
- Benutzerkommentare als Antwort auf einen Artikel im Blog eines Kolumnisten
- Ein Kommentar aus einem Videoclip, der auf einer Content-Hosting-Website gepostet wurde
- Rezensionen (z. B. von Produkten, Filmen)
- Aktionen (wie „Gefällt mir!“, „Gefällt mir nicht!“, +1, Teilen, Lesezeichen setzen, Wiedergabelisten usw.)
- Also her
Unter diesem Patent wird ein Weg zur Identifizierung und Vorhersage subjektiver Attribute für Entitäten (wie Medienclips, Bilder, Zeitungsartikel, Blogeinträge, Personen, Organisationen, kommerzielle Unternehmen usw.) bereitgestellt.
Es beginnt mit:
- Identifizieren eines ersten Satzes subjektiver Attribute für eine erste Entität basierend auf einer Reaktion auf die erste Entität (z. B. Kommentare auf einer Website, eine Demonstration der Zustimmung der ersten Entität (z. B. „Gefällt mir!“ usw.)
- Teilen der ersten Entität
- Lesezeichen für die erste Entität setzen
- Hinzufügen der ersten Entität zu einer Wiedergabeliste
- Trainieren eines Klassifikators (z. B. einer Support-Vektor-Maschine, AdaBoost, eines neuronalen Netzwerks, eines Entscheidungsbaums auf einem Satz von Input-Output-Mappings, wobei der Satz von Input-Output-Mappings ein Input-Output-Mapping umfasst, dessen Input das Bereitstellen eines Merkmalsvektors ist für die erste Entität, deren Ausgabe auf dem ersten Satz subjektiver Attribute basiert
- Bereitstellen eines Merkmalsvektors für eine zweite Entität für den trainierten Klassifikator, um einen zweiten Satz von subjektiven Attributen für die zweite Entität zu erhalten
Ein Speicher und ein Prozessor werden bereitgestellt, um subjektive Attribute für Entitäten zu identifizieren und vorherzusagen.
Ein computerlesbares Speichermedium enthält Anweisungen, die ein Computersystem veranlassen, Operationen auszuführen, einschließlich:
- Identifizieren eines ersten Satzes von subjektiven Attributen für eine erste Entität basierend auf einer Reaktion auf die erste Entität
- Erhalten eines ersten Merkmalsvektors für die erste Entität
- Trainieren eines Klassifikators auf einem Satz von Eingabe-Ausgabe-Abbildungen, wobei der Satz von Eingabe-Ausgabe-Abbildungen eine Eingabe-Ausgabe-Abbildung umfasst, deren Eingabe auf dem ersten Merkmalsvektor basiert und deren Ausgabe auf der ersten Menge subjektiver Attribute basiert
- Erhalten eines zweiten Merkmalsvektors für eine zweite Entität
- Bereitstellen des zweiten Merkmalsvektors für den Klassifizierer nach dem Training, um einen zweiten Satz von subjektiven Attributen für die zweite Entität zu erhalten
Dieses Patent zur Identifizierung subjektiver Attribute für Entitäten = ist zu finden unter:
Identifizieren subjektiver Attribute durch Analyse von Kurationssignalen
Erfinder: Hrishikesh Aradhye und Sanketh Shetty
Zessionar: Google LLC
US-Patent: 11.328.218
Gewährt: 10. Mai 2022
Eingereicht: 6. November 2017
Abstrakt:
Offenbart werden ein System und ein Verfahren zum Identifizieren und Vorhersagen subjektiver Attribute für Entitäten (wie Medienclips, Filme, Fernsehsendungen, Bilder, Zeitungsartikel, Blogeinträge, Personen, Organisationen, kommerzielle Unternehmen usw.).
In einem Aspekt werden subjektive Attribute für ein erstes Medienelement basierend auf einer Reaktion auf das erste Medienelement identifiziert und Relevanzbewertungen für die persönlichen Eigenschaften in Bezug auf das erste Medienelement werden bestimmt.
Ein Klassifikator wird unter Verwendung von (i) einer Trainingseingabe, die einen Satz von Merkmalen für das erste Medienelement umfasst, und einer Zielausgabe für die Trainingseingabe trainiert, wobei die Zielausgabe die jeweiligen Relevanzbewertungen für die subjektiven Attribute des ersten Medienelements umfasst.
Identifizieren und Vorhersagen subjektiver Attribute für Entitäten
Möglichkeiten zur Identifizierung und Vorhersage subjektiver Attribute für Entitäten (z. B. Medienausschnitte, Bilder, Zeitungsartikel, Blogeinträge, Personen, Organisationen, Handelsunternehmen usw.).
Subjektive Attribute (wie „süß“, „lustig“, „großartig“ usw.) werden definiert, und subjektive Attribute für eine bestimmte Entität werden basierend auf der Reaktion des Benutzers auf die Entität identifiziert, wie etwa:
- Kommentare auf einer Website
- Wie!
- Teilen der ersten Entität mit anderen Benutzern
- Boommarking der ersten Entität
- Hinzufügen der ersten Entität zu einer Wiedergabeliste
- Etc
Relevanzwerte für die subjektiven Attribute werden über die Entität ermittelt
Wenn das subjektive Attribut „süß“ in einem signifikanten Anteil der Kommentare zu einem Videoclip vorkommt, dann kann „süß“ eine hohe Relevanzbewertung erhalten.
Die Entität wird dann mit den identifizierten subjektiven Attributen und Relevanzbewertungen verknüpft (z. B. über an der Entität angebrachte Tags, über Einträge in einer Tabelle einer relationalen Datenbank usw.).
Das obige Verfahren wird für jede Entität in einem gegebenen Satz von Entitäten (wie Videoclips in einem Videoclip-Repository usw.) durchgeführt, und eine umgekehrte Zuordnung von subjektiven Attributen zu Entitäten in der Gruppe wird basierend auf persönlichen Qualitäten und Relevanzbewertungen erzeugt .
Die umgekehrte Abbildung kann dann verwendet werden, um alle Entitäten in der Menge zu identifizieren, die mit einem bestimmten subjektiven Attribut übereinstimmen (z. B. alle Entitäten, die mit dem subjektiven Attribut „lustig“ usw. in Verbindung gebracht wurden), wodurch Folgendes ermöglicht wird:
- Schnelles Auffinden relevanter Entitäten zur Verarbeitung von Schlüsselwortsuchen
- Wiedergabelisten füllen
- Anzeigen liefern
- Generieren von Trainingssätzen für den Klassifikator
- Also her
Ein Klassifikator (wie z. B. eine Support-Vektor-Maschine [SVM], AdaBoost, ein neuronales Netzwerk, ein Entscheidungsbaum usw.) wird trainiert, indem ein Satz von Trainingsbeispielen bereitgestellt wird, wobei die Eingabe für ein Trainingsbeispiel einen aus a erhaltenen Merkmalsvektor umfasst bestimmte Entität (z. B. ein Merkmalsvektor für einen Videoclip.
Es kann numerische Werte enthalten über:
- Farbe
- Textur
- Intensität
- Mit dem Videoclip verknüpfte Metadaten-Tags
- Etc
Die Ausgabe hat Relevanzbewertungen für jedes subjektive Attribut im Vokabular für die bestimmte Entität.
Der trainierte Klassifikator kann dann subjektive Attribute für Entitäten vorhersagen, die nicht im Trainingssatz enthalten sind (z. B. ein neu hochgeladener Videoclip, ein Nachrichtenartikel, der noch keine Kommentare erhalten hat usw.).
Dieses Patent kann Entitäten nach subjektiven Attributen wie „lustig“, „süß“ usw. klassifizieren, basierend auf der Reaktion der Benutzer auf die Entitäten.
Dieses Patent kann die Qualität von Entitätsbeschreibungen, wie z. B. Tags für einen Videoclip, verbessern, die Qualität von Suchen und die Ausrichtung von Werbung verbessern.
Eine Systemarchitektur zur Identifizierung subjektiver Attribute
Die Systemarchitektur umfasst:
- Servermaschine
- Entitätsspeicher
- Client-Rechner sind mit einem Netzwerk verbunden
Das Netzwerk kann öffentlich (wie etwa das Internet), ein privates Netzwerk (wie etwa ein Local Area Network (LAN) oder ein Wide Area Network (WAN)) oder eine Kombination davon sein.
Die Client-Maschinen können drahtlose Endgeräte (Smartphones usw.), Personalcomputer (PC), Laptops, Tablet-Computer oder andere Computer- oder Kommunikationsgeräte sein.
Auf den Client-Maschinen kann ein Betriebssystem (OS) laufen, das die Hardware und Software der Client-Maschinen verwaltet.
Ein (nicht gezeigter) Browser kann auf den Client-Maschinen laufen (wie etwa auf dem OS der Client-Maschinen).
Der Browser kann ein Webbrowser sein, der auf Webseiten und Inhalte zugreifen kann, die von einem Webserver bereitgestellt werden.
Die Client-Rechner können auch Folgendes hochladen:
- Webseiten
- Medienclips
- Blog-Einträge
- Links zu Artikeln
- Also her
Die Servermaschine enthält einen Webserver und einen Manager für subjektive Attribute. Der Webserver und der Manager für emotionale Attribute können auf unterschiedlichen Geräten ausgeführt werden.
Der Entitätsspeicher ist ein persistenter Speicher, der Entitäten wie Medienclips (wie Videoclips, Audioclips, Clips, die sowohl Video als auch Audio enthalten, Bilder usw.) und andere Arten von Inhaltselementen (wie Webseiten, Text- basierte Dokumente, Restaurantkritiken, Filmkritiken usw.) sowie Datenstrukturen zum Markieren, Organisieren und Indizieren der Entitäten.
Der Entitätsspeicher kann von Speichergeräten gehostet werden, wie z. B. Hauptspeicher, magnetische oder optische speicherbasierte Platten, Bänder oder Festplatten, NAS, SAN usw.
Der Entitätsspeicher wird möglicherweise von einem an das Netzwerk angeschlossenen Dateiserver gehostet. Im Gegensatz dazu kann der Entitätsspeicher in anderen Implementierungen von einer anderen Art von dauerhaftem Speicher gehostet werden, wie z. B. dem der Servermaschine oder anderen Maschinen, die über das Netzwerk mit der Servermaschine gekoppelt sind.
Die im Entitätsspeicher gespeicherten Entitäten können benutzergenerierte Inhalte enthalten, die von Client-Computern hochgeladen werden, und können Inhalte enthalten, die von Dienstanbietern bereitgestellt werden, wie z.
- Nachrichtenorganisationen
- Verlag
- Bibliotheken
- Bald
Der Server kann Clients Webseiten und Inhalte aus den Entitätsspeichern bereitstellen.
Der subjektive Attributmanager:
- Identifiziert subjektive Attribute für Entitäten basierend auf Benutzerreaktionen (wie Kommentare, „Gefällt mir“!, Teilen, Lesezeichen setzen, Wiedergabelisten usw.)
- Bestimmt Relevanzbewertungen für subjektive Attribute zu Entitäten
- Ordnet Entitäten subjektive Attribute und Relevanzbewertungen zu
- Extrahiert Merkmale wie Bildmerkmale wie Farbe, Textur und Intensität; Audiomerkmale wie Amplitude, Spektralkoeffizientenverhältnisse; Textmerkmale wie Worthäufigkeiten, durchschnittliche Satzlänge, Formatierungsparameter; der Entität zugeordnete Metadaten; usw.) von Entitäten, um Merkmalsvektoren zu erzeugen
- Trainiert einen Klassifikator basierend auf den Merkmalsvektoren und den Relevanzbewertungen der subjektiven Attribute
- Verwendet den trainierten Klassifikator, um subjektive Attribute für neue Entitäten basierend auf Merkmalsvektoren der neuen Entitäten vorherzusagen
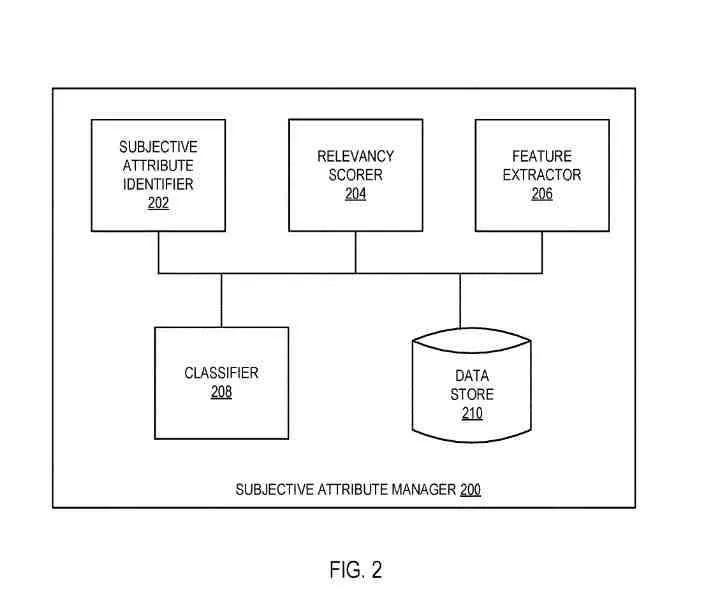
Ein Subjektiver Attributmanager
Der Manager für subjektive Attribute kann derselbe sein wie der Manager für subjektive Attribute und kann umfassen:
- Subjektiver Attributbezeichner
- Relevanz-Scorer
- Feature-Extraktor
- Klassifikator
- Datenspeicher
.
Die Komponenten können kombiniert oder in weitere Details zerlegt werden.
Der Datenspeicher kann derselbe sein wie der Entitätsspeicher oder ein anderer Datenspeicher (wie etwa ein temporärer Puffer oder ein permanenter Datenspeicher), um ein persönliches Attributvokabular, zu verarbeitende Entitäten, mit Entitäten verknüpfte Merkmalsvektoren, persönliche Attribute zu halten und Relevanzwerte in Bezug auf Entitäten oder eine Kombination dieser Daten.
Der Datenspeicher kann von Speichergeräten gehostet werden, z. B. Hauptspeicher, magnetische oder optische speicherbasierte Datenträger, Bänder oder Festplatten usw.
Der Manager für subjektive Attribute benachrichtigt Benutzer über die Arten von Informationen, die im Datenspeicher und im Entitätsspeicher gespeichert sind, und ermöglicht es Benutzern, zu wählen, dass solche Informationen nicht gesammelt und nicht mit dem Manager für subjektive Attribute geteilt werden.
Der subjektive Attributbezeichner
Der persönliche Attributidentifizierer identifiziert subjektive Attribute für Entitäten basierend auf einer Benutzerreaktion auf die Entitäten.
Der persönliche Attributidentifizierer kann subjektive Attribute durch Textverarbeitung von Benutzerkommentaren an eine Entität identifizieren, die von einem Benutzer auf einer Website eines sozialen Netzwerks gepostet wurden.
Die subjektive Attributkennung kann subjektive Attribute für Entitäten basierend auf anderen Arten von Benutzerreaktionen auf Entitäten identifizieren, wie z. B.:
- 'Wie!' oder 'Gefällt mir nicht!'
- Teilen der Entität
- Lesezeichen für die Entität setzen
- Hinzufügen der Entität zu einer Wiedergabeliste
- Also her
Der Identifizierer für persönliche Attribute kann Schwellenwerte anwenden, um zu bestimmen, welche Attribute mit einer Entität assoziiert sind (wie etwa, dass ein subjektives Attribut in mindestens N Kommentaren erscheinen sollte usw.).
Der Relevanz-Scorer bestimmt Relevanz-Scores für subjektive Attribute zu Entitäten.
Wenn beispielsweise der subjektive Attributidentifizierer die subjektiven Attribute „süß“, „lustig“ und „großartig“ basierend auf Kommentaren zu einem auf einer Website eines sozialen Netzwerks geposteten Medienclip identifiziert hat, kann der Relevanzbewerter Relevanzbewertungen für jedes dieser drei subjektiven Merkmale bestimmen Attribute basierend auf:
- Die Häufigkeit, mit der diese subjektiven Attribute in Kommentaren vorkommen
- Die jeweiligen Benutzer, die die subjektiven Attribute bereitgestellt haben
- Also her
Wenn es beispielsweise 40 Kommentare gibt und „niedlich“ in 20 Wörtern vorkommt und „fantastisch“ in 8 Kommentaren vorkommt, dann wird „niedlich“ möglicherweise ein Relevanzwert zugewiesen, der höher ist als „fantastisch“.
Die Relevanzbewertungen können basierend auf dem Anteil der Kommentare zugewiesen werden, in denen ein subjektives Attribut vorkommt (z. B. eine Bewertung von 0,5 für „süß“ und eine Bewertung von 0,2 für „großartig“ usw.).
Der Relevanz-Scorer kann nur die k relevantesten subjektiven Attribute behalten und andere persönliche Attribute verwerfen.
Angenommen, die persönliche Attributkennung identifiziert sieben emotionale Attribute, die mindestens dreimal in Benutzerkommentaren erscheinen. In diesem Fall kann der Relevanz-Scorer beispielsweise nur die fünf subjektiven Attribute mit den höchsten Relevanzwerten behalten und die anderen zwei emotionalen Attribute verwerfen (z. B. durch Setzen ihrer Relevanzwerte auf null usw.).
Ein Relevanzwert ist eine natürliche Zahl zwischen 0,0 und 1,0 einschließlich.
Der Merkmalsextrahierer erhält einen Merkmalsvektor für eine Entität unter Verwendung von Techniken wie:
- Hauptkomponentenanalyse
- Semidefinite Einbettungen
- Isokarten
- Partielle kleinste Quadrate
- Also her
Die mit dem Extrahieren von Merkmalen einer Entität verbundenen Berechnungen werden vom Merkmalsextrahierer selbst durchgeführt.
In einigen anderen Aspekten werden diese Berechnungen von einer anderen Entität durchgeführt, wie z. B. einer ausführbaren Bibliothek von:

- Bildverarbeitungsroutinen, die von einer Servermaschine gehostet werden [in den Figuren nicht dargestellt]
- Audioverarbeitungsroutinen
- Textverarbeitungsroutinen
- Etc
Die Ergebnisse werden dem Feature Extractor bereitgestellt.
Der Klassifikator ist eine lernende Maschine (wie Support Vector Machines [SVMs], AdaBoost, neuronale Netze, Entscheidungsbäume usw.), die einen mit einer Entität verknüpften Merkmalsvektor als Eingabe akzeptiert und Relevanzwerte ausgibt (wie eine tatsächliche Zahl zwischen 0 und 1 einschließlich usw.) für jedes subjektive Attribut des Vokabulars für persönliche Attribute.
Der Klassifikator besteht aus einem einzigen Klassifikator.
Der Klassifikator kann mehrere Klassifikatoren umfassen (wie beispielsweise einen Klassifikator für jedes subjektive Attribut im Vokabular für persönliche Attribute usw.).
Für jedes subjektive Attribut im Vokabular für persönliche Attribute wird eine Reihe positiver Beispiele und negativer Kriterien zusammengestellt.
Der Satz von positiven Beispielen für ein subjektives Attribut kann Merkmalsvektoren für Entitäten enthalten, die diesem bestimmten persönlichen Attribut zugeordnet sind.
Der Satz negativer Beispiele für ein subjektives Attribut kann Merkmalsvektoren für Entitäten umfassen, die nicht mit diesem bestimmten persönlichen Attribut in Verbindung gebracht wurden.
Wenn der Satz positiver Beispiele und der Satz negativer Kriterien in der Größe ungleich sind, kann der umfangreichere Satz abgetastet werden, um mit der Größe der kleineren Gruppe übereinzustimmen.
Nach dem Training kann der Klassifikator subjektive Attribute für andere Entitäten vorhersagen, die nicht im Trainingssatz enthalten sind, indem er Merkmalsvektoren für diese Entitäten als Eingabe für den Klassifikator bereitstellt.
Ein Satz subjektiver Attribute kann aus der Ausgabe des Klassifikators erhalten werden, indem alle emotionalen Attribute mit Relevanzbewertungen ungleich Null aufgenommen werden. Eine Gruppe subjektiver Punkte kann erhalten werden, indem der niedrigste Schwellenwert auf die numerischen Bewertungen angewendet wird (indem alle persönlichen Attribute, die eine Bewertung von mindestens beispielsweise 0,2 aufweisen, als Mitglieder der Menge betrachtet werden).
Identifizieren subjektiver Attribute von Entitäten
Das Verfahren wird durch eine Verarbeitungslogik durchgeführt, die Hardware (Schaltungen, dedizierte Logik usw.), Software (wie sie beispielsweise auf einem Allzweck-Computersystem oder einer dedizierten Maschine ausgeführt wird) oder beides umfassen kann.
Die Methode wird von der Servermaschine ausgeführt, während einige andere Implementierungen von einem anderen Gerät ausgeführt werden können.
Verschiedene Komponenten von Managern für subjektive Attribute können auf getrennten Maschinen laufen (z. B. können der Identifikator für persönliche Attribute und der Relevanz-Scorer auf einem Gerät laufen, während der Merkmalsextrahierer und der Klassifikator auf einem anderen Gerät laufen, usw.).
Zur Vereinfachung der Erklärung wird das Verfahren als eine Reihe von Handlungen dargestellt und beschrieben.
Aber Handlungen können in verschiedenen Reihenfolgen und mit anderen Handlungen auftreten, die hierin nicht dargestellt und beschrieben werden.
Darüber hinaus sind möglicherweise nicht alle veranschaulichten Handlungen erforderlich, um die Verfahren durch den offenbarten Gegenstand zu installieren.
Außerdem wird der Fachmann verstehen und anerkennen, dass das Verfahren als eine Reihe von zusammenhängenden Zuständen über ein Zustandsdiagramm oder Ereignisse dargestellt werden könnte.
Außerdem sollte klar sein, dass die in dieser Beschreibung offenbarten Verfahren in der Lage sind, auf einem Herstellungsartikel gespeichert zu werden, um den Transport und die Übertragung solcher Methodologien auf Computergeräte zu erleichtern.
Der Begriff Herstellungsgegenstand, wie er hier verwendet wird, soll ein Computerprogramm umfassen, auf das von einem beliebigen computerlesbaren Gerät oder Speichermedium zugegriffen werden kann.
Es entsteht ein Vokabular subjektiver Attribute.
In einigen Aspekten kann das subjektive Attributvokabular definiert werden. Im Gegensatz dazu kann das Vokabular für persönliche Attribute in einigen anderen Faktoren auf automatisierte Weise generiert werden, indem Begriffe und Phrasen gesammelt werden, die in den Reaktionen der Benutzer auf Entitäten verwendet werden. Im Gegensatz dazu kann das Vokabular in noch anderen Aspekten durch eine Kombination aus manuellen und automatisierten Techniken erzeugt werden.
Das Vokabular wird mit einer kleinen Anzahl subjektiver Attribute gesät, von denen erwartet wird, dass sie auf Entitäten zutreffen. Das Vokabular wird im Laufe der Zeit erweitert, da mehr Begriffe oder Sätze, die in Benutzerreaktionen vorkommen, durch die automatisierte Verarbeitung der Antworten identifiziert werden.
Das Vokabular der subjektiven Attribute kann hierarchisch organisiert sein, möglicherweise basierend auf „Meta-Attributen“, die mit den persönlichen Attributen verknüpft sind (wie beispielsweise das persönliche Attribut „lustig“ ein Meta-Attribut „positiv“ haben kann, während der subjektive Punkt „ekelhaft“ ein Meta-Attribut haben kann ein Metaattribut „negativ“ usw.).
Eine Menge S von Entitäten (wie etwa alle Entitäten im Entitätsspeicher, eine Teilmenge von Entitäten im Entitätsspeicher usw.) wird vorverarbeitet.
Unter einem Aspekt umfasst die Vorverarbeitung der Entitäten das Identifizieren von Benutzerreaktionen auf die Entitäten und dann das Trainieren eines Klassifikators basierend auf den Antworten.
Wenn eine Entität eine tatsächliche physische Entität ist
Es sollte beachtet werden, dass, wenn eine Entität eine tatsächliche physische Entität ist (wie eine Person, ein Restaurant usw.), die Vorverarbeitung der Entität über einen „Cyber-Proxy“ durchgeführt wird, der mit der physischen Entität (wie z Fanseite für einen Schauspieler auf einer Website eines sozialen Netzwerks, eine Restaurantbewertung auf einer Website usw.); Die subjektiven Attribute werden jedoch als mit der Entität selbst in Verbindung gebracht (z. B. der Schauspieler oder das Restaurant, nicht die Fanseite des Schauspielers oder die Restaurantbewertung).
Ein Beispiel für ein Verfahren zum Durchführen wird im Detail beschrieben.
Eine Entität E, die nicht in Satz S enthalten ist, wird empfangen (z. B. ein neu hochgeladener Videoclip, ein Nachrichtenartikel, der noch keine Kommentare erhalten hat, eine Entität im Entitätsspeicher, die nicht in der Trainingsmenge enthalten war usw.).
Themenattribute und Relevanzbewertungen für Entität E werden erhalten.
Eine Implementierung eines ersten Beispielverfahrens wird unten im Detail beschrieben, und die Leistung eines zweiten Beispielverfahrens wird beschrieben.
Die erhaltenen subjektiven Attribute und Relevanzbewertungen werden der Entität E zugeordnet (z. B. durch Anwenden entsprechender Tags auf die Entität, Hinzufügen eines Datensatzes in einer relationalen Datenbanktabelle usw.).
Die Ausführung geht weiter zurück.
Es sei darauf hingewiesen, dass der Klassifikator durch einen Neutrainingsprozess, der gleichzeitig ausgeführt werden kann, neu trainiert werden kann (z. B. nach jeweils 100 Iterationen der Schleife, alle N Tage usw.).
Vorverarbeitung einer Reihe von Entitäten
Das Verfahren wird durch eine Verarbeitungslogik durchgeführt, die Hardware (Schaltungen, dedizierte Logik usw.), Software (wie sie beispielsweise auf einem Allzweck-Computersystem oder einer dedizierten Maschine ausgeführt wird) oder beides umfassen kann.
Das Verfahren wird ausgeführt, während es in einigen anderen Implementierungen von einer anderen Maschine ausgeführt werden kann.
Der Trainingssatz wird auf den leeren Satz initialisiert. Eine Entität E wird ausgewählt und aus der Menge S von Entitäten entfernt.
Subjektive Attribute für Entität E werden basierend auf Benutzerreaktionen auf Entität E identifiziert (wie etwa Benutzerkommentare, Like!, Bookmarken, Teilen, Hinzufügen zu einer Wiedergabeliste usw.).
Die Identifizierung subjektiver Attribute umfasst die Verarbeitung von Benutzerkommentaren, wie z. B. durch:
- Abgleich von Wörtern in Benutzerkommentaren mit subjektiven Attributen im Vokabular
- Kombinieren von Wortabgleich und anderen Techniken zur Verarbeitung natürlicher Sprache wie syntaktische und semantische Analyse
- Etc
Entitäten, die in der Nähe von Standorten vorkommen
Benutzerreaktionen können für Entitäten aggregiert werden, die an vielen Orten auftreten, wie z. B.:
- Entitäten, die in den Wiedergabelisten vieler Benutzer erscheinen
- Entitäten, die geteilt wurden und in den „Newsfeeds“ einer Vielzahl von Benutzern auf einer Website eines sozialen Netzwerks erscheinen
- Etc
Die verschiedenen Standorte können in ihrem Beitrag zu den Relevanzwerten basierend auf einer Vielzahl von Faktoren gewichtet werden, z. B.:
Der bestimmte Benutzer, der mit dem Standort verbunden ist (z. B. kann ein bestimmter Benutzer eine Autorität für klassische Musik sein, und daher können Kommentare über eine Entität in seinem Newsfeed mehr Gewicht erhalten als Kommentare in einem anderen Newsfeed usw.), nicht-textliche Benutzerreaktionen (z B. „Gefällt mir!“, „Gefällt mir nicht!“, „+1“ usw.).
Darüber hinaus kann die Anzahl der Stellen, an denen die Entität erscheint, auch zur Bestimmung subjektiver Attribute und Relevanzbewertungen verwendet werden (beispielsweise können Relevanzbewertungen für einen Videoclip erhöht werden, wenn sich der Videoclip in Hunderten von Benutzer-Wiedergabelisten befindet usw.).
Die Blockierung wird durch die subjektive Attributkennung durchgeführt.
Relevanzwerte für die subjektiven Attribute werden von Entität E bestimmt.
Eine Relevanzbewertung wird für ein bestimmtes subjektives Attribut bestimmt, basierend auf der Häufigkeit, mit der das persönliche Attribut in Benutzerkommentaren vorkommt, den spezifischen Benutzern, die die subjektiven Details in ihren Worten angegeben haben (z ihre Kommentare als andere Benutzer usw.).
Wenn es beispielsweise 40 Kommentare gibt und „niedlich“ in 20 Wörtern vorkommt und „fantastisch“ in 8 Kommentaren vorkommt, dann wird „niedlich“ möglicherweise ein Relevanzwert zugewiesen, der höher ist als „fantastisch“.
Die Relevanzbewertungen können basierend auf dem Anteil der Kommentare zugewiesen werden, in denen ein subjektives Attribut vorkommt (z. B. eine Bewertung von 0,5 für „niedlich“ und eine Bewertung von 0,2 für „super“ usw.).
Unter einem Aspekt werden die Relevanzwerte so normalisiert, dass sie in Intervallen fallen [0, 1].
Gemäß einigen Aspekten können die identifizierten subjektiven Attribute basierend auf ihren Relevanzbewertungen verworfen werden (wie etwa das Beibehalten der k emotionalen Attribute mit den höchsten Relevanzbewertungen, das Verwerfen jeglicher persönlicher Attribute, deren Relevanzbewertung unter einem Schwellenwert liegt usw.).
Es sollte beachtet werden, dass ein subjektives Attribut verworfen werden kann, indem seine Relevanzbewertung in einigen Aspekten auf Null gesetzt wird.
Subjektive Attribute und Relevanzwerte werden den Entitäten zugeordnet
Die subjektiven Attribute und Relevanzwerte werden den Entitäten zugeordnet (z. B. über Tagging, Einträge in einer Tabelle in einer relationalen Datenbank usw.).
Ein Merkmalsvektor für die Entität E wird erhalten.
In einem Aspekt kann der Merkmalsvektor für einen Videoclip oder ein Standbild numerische Werte über Farbe, Textur, Intensität usw. enthalten, während der Merkmalsvektor für einen Audioclip (oder einen Videoclip mit Ton) numerische Werte über die Amplitude enthalten kann , Spektralkoeffizienten usw., während der Merkmalsvektor für ein Textdokument enthalten kann:
- Numerische Werte über Worthäufigkeiten
- Durchschnittliche Satzlänge
- Parameter formatieren
- Also her
Dies kann durch den Merkmalsextrahierer durchgeführt werden.
Der Merkmalsvektor und die erhaltenen Relevanzwerte werden dem Trainingssatz hinzugefügt.
Der Block prüft, ob die Menge S von Entitäten leer ist; wenn S nicht leer ist, wird die Ausführung fortgesetzt, andernfalls wird die Ausführung fortgesetzt.
Der Klassifikator wird an allen Beispielen des Trainingssatzes trainiert, so dass der Merkmalsvektor eines Trainingsbeispiels als Eingabe für den Klassifikator bereitgestellt wird und die subjektiven Attributrelevanzbewertungen als Ausgabe bereitgestellt werden.
Erhalten von subjektiven Attributen und Relevanzwerten für eine Entität
Ein Merkmalsvektor für Entität E wird generiert.
Wie oben beschrieben, kann der Merkmalsvektor für einen Videoclip oder ein Standbild numerische Werte über Farbe, Textur, Intensität usw. enthalten. Im Gegensatz dazu kann der Merkmalsvektor für einen Audioclip (oder einen Videoclip mit Ton) numerische Werte enthalten B. über Amplitude, Spektralkoeffizienten usw.. Im Gegensatz dazu kann der Merkmalsvektor für ein Textdokument numerische Werte über Worthäufigkeiten, durchschnittliche Satzlänge, Formatierungsparameter usw. enthalten.
Der trainierte Klassifikator stellt den Merkmalsvektor bereit, um vorhergesagte subjektive Attribute und Relevanzbewertungen für Entität E zu erhalten.
Die vorhergesagten subjektiven Attribute und Relevanzbewertungen werden der Entität E zugeordnet (z. B. über Tags, die auf die Entität E angewendet werden, über Einträge in einer Tabelle einer relationalen Datenbank usw.).
Eine zweite Methode zum Erhalten subjektiver Attribute und Relevanzbewertungen für eine Entität
Das Verfahren wird durch eine Verarbeitungslogik durchgeführt, die Hardware (Schaltkreise, dedizierte Logik usw.), Software oder eine Kombination aus beiden umfassen kann.
Die Methode wird vom Servercomputer ausgeführt, während einige andere möglicherweise von einem anderen Gerät ausgeführt werden.
Ein Merkmalsvektor für Entität E wird generiert. Der trainierte Klassifikator stellt den Merkmalsvektor bereit, um vorhergesagte subjektive Attribute und Relevanzbewertungen für Entität E zu erhalten.
Die erhaltenen vorhergesagten subjektiven Attribute werden einem Benutzer vorgeschlagen (z. B. dem Benutzer, der die Entität hochgeladen hat). Ein verfeinerter Satz persönlicher Attribute wird vom Benutzer erhalten, z. B. über eine Webseite, auf der der Benutzer aus den vorgeschlagenen Attributen und möglicherweise auswählt fügt neue Attribute hinzu usw.).
Ein Standardrelevanzwert für Entitäten
Allen neuen subjektiven Attributen, die vom Benutzer hinzugefügt wurden, wird eine Standardrelevanzbewertung zugewiesen.
Die standardmäßige Relevanzbewertung kann 1,0 auf einer Skala von 0,0 bis 1,0 betragen, die standardmäßige Relevanzbewertung kann auf dem jeweiligen Benutzer basieren (z. B. eine Bewertung von 1,0, wenn der Benutzer aus der Vergangenheit dafür bekannt ist, dass er sehr gut darin ist, Attribute vorzuschlagen, eine Bewertung von 0,8, wenn der Benutzer bekanntermaßen etwas gut darin ist, Attribute usw. vorzuschlagen).
Die Sperrverzweigungen basieren darauf, ob der Benutzer eines der vorgeschlagenen subjektiven Attribute entfernt hat (z. B. indem er das Attribut nicht ausgewählt hat).
Entität E wird als negatives Beispiel für das/die entfernte(n) Attribut(e) für zukünftiges erneutes Trainieren des Klassifikators gespeichert. Der verfeinerte Satz von subjektiven Attributen und entsprechenden Relevanzbewertungen werden der Entität E zugeordnet (z. B. über Tags, die auf die Entität E angewendet werden, über Einträge in einer Tabelle einer relationalen Datenbank usw.).