
Noindex Nofollow und Disallow: Such-Crawler-Direktiven
Veröffentlicht: 2022-12-01Es gibt drei Direktiven (Befehle), mit denen Sie bestimmen können, wie Suchmaschinen Informationen von Ihrer Website entdecken, speichern und als Suchergebnisse bereitstellen:
- NoIndex: Meine Seite nicht zu den Suchergebnissen hinzufügen.
- NoFollow: Sehen Sie sich die Links auf dieser Seite nicht an.
- Disallow: Schauen Sie sich diese Seite überhaupt nicht an.
Mit diesen Anweisungen können Sie steuern, welche Seiten Ihrer Website von Suchmaschinen gecrawlt und in der Suche angezeigt werden können.
Was bedeutet kein Index?
Die Direktive noindex weist Such-Crawler wie Googlebot an, eine Webseite nicht in ihre Suchergebnisse aufzunehmen.

Wie markieren Sie eine Seite NoIndex?
Es gibt zwei Möglichkeiten, eine noindex- Direktive abzusetzen:
- Fügen Sie dem HTML-Code der Seite ein noindex-Meta-Tag hinzu
- Geben Sie einen noindex-Header in der HTTP-Anfrage zurück
Indem Sie das Meta-Tag „kein Index“ für eine Seite oder als HTTP-Antwort-Header verwenden, verstecken Sie die Seite im Wesentlichen vor der Suche.
Die Direktive noindex kann auch verwendet werden, um nur bestimmte Suchmaschinen zu blockieren. Sie könnten beispielsweise Google daran hindern, eine Seite zu indizieren, aber Bing dennoch erlauben:
Beispiel: Blockieren der meisten Suchmaschinen*
<meta name=“robots“ content=“noindex“>
Beispiel: Nur Google blockieren
<meta name="googlebot" content="noindex">
Bitte beachten Sie: Seit September 2019 respektiert Google die noindex-Anweisungen in der robots.txt-Datei nicht mehr . Noindex MUSS jetzt per HTML-Meta-Tag oder HTTP-Response-Header ausgegeben werden. Für fortgeschrittene Benutzer funktioniert Disallow vorerst noch, wenn auch nicht für alle Anwendungsfälle.
Was ist der Unterschied zwischen noindex und nofollow?
Es ist ein Unterschied zwischen dem Speichern von Inhalten und dem Entdecken von Inhalten:
noindex wird auf Seitenebene angewendet und weist einen Suchmaschinen-Crawler an, eine Seite nicht zu indizieren und in den Suchergebnissen bereitzustellen.
nofollow wird auf Seiten- oder Linkebene angewendet und weist einen Suchmaschinen-Crawler an, den Links nicht zu folgen (zu entdecken).
Im Wesentlichen entfernt das noindex-Tag eine Seite aus dem Suchindex, und ein nofollow-Attribut entfernt einen Link aus dem Linkdiagramm der Suchmaschine.
NoFollow als Seitenattribut
Die Verwendung von nofollow auf Seitenebene bedeutet, dass Crawler keinem der Links auf dieser Seite folgen, um zusätzliche Inhalte zu entdecken, und dass die Crawler die Links nicht als Ranking-Signale für die Zielseiten verwenden.
<meta name=“robots“ content=“nofollow“>
NoFollow als Linkattribut
Die Verwendung von nofollow auf Linkebene hindert Crawler daran, einen anzeigenspezifischen Link zu erkunden, und verhindert, dass dieser Link als Ranking-Signal verwendet wird.
Die nofollow-Direktive wird auf Linkebene mithilfe eines rel-Attributs innerhalb des a href-Tags angewendet:
<a href="https://domain.com" rel="nofollow">
Speziell für Google verhindert die Verwendung des nofollow-Linkattributs, dass Ihre Website den PageRank an die Ziel-URLs weitergibt.
Warum sollten Sie eine Seite als NoFollow markieren?
Für die meisten Anwendungsfälle sollten Sie nicht eine ganze Seite als nofollow markieren – es reicht aus, einzelne Links als nofollow zu markieren.
Sie würden eine ganze Seite als nofollow markieren, wenn Sie nicht möchten, dass Google die Links auf der Seite anzeigt, oder wenn Sie der Meinung sind, dass die Links auf der Seite Ihrer Website schaden könnten.
In den meisten Fällen werden pauschale nofollow -Anweisungen auf Seitenebene verwendet, wenn Sie keine Kontrolle über die Inhalte haben, die auf einer Seite gepostet werden Einige High-End-Verlage haben auch die Nofollow-Richtlinie pauschal auf ihre Seiten angewendet, um ihre Autoren davon abzubringen, gesponserte Links in ihren Inhalten zu platzieren.
Wie verwende ich NoIndex-Seiten?
Markieren Sie Seiten als noindex, die den Benutzern wahrscheinlich keinen Mehrwert bieten und nicht als Suchergebnisse angezeigt werden sollten. Beispielsweise ist es unwahrscheinlich, dass auf Seiten, die für die Paginierung vorhanden sind, im Laufe der Zeit dieselben Inhalte angezeigt werden.
Domain.com/category/resultspage=2 zeigt einem Nutzer wahrscheinlich keine besseren Ergebnisse als domain.com/category/resultspage=1 und die beiden Seiten würden nur bei der Suche miteinander konkurrieren. Es ist am besten, Seiten zu noindexen, deren einziger Zweck die Paginierung ist.
Hier sind Arten von Seiten, die Sie in Betracht ziehen sollten: noindexing:
- Seiten, die für die Paginierung verwendet werden
- Interne Suchseiten
- Anzeigenoptimierte Zielseiten
- Beispiel: Zeigt nur einen Pitch und ein Anmeldeformular an, kein Hauptnavigationssystem
- Beispiel: Doppelte Variationen desselben Inhalts, die nur für Anzeigen verwendet werden
- Archivierte Autorenseiten
- Seiten in Kassenabläufen
- Bestätigungsseiten
- Bsp.: Dankesseiten
- Bsp.: Ganze Seiten bestellen
- Bsp.: Erfolg! Seiten
- Einige von Plugins generierte Seiten, die für Ihre Website nicht relevant sind (z. B. wenn Sie ein Commerce-Plugin verwenden, aber nicht die regulären Produktseiten verwenden)
- Admin-Seiten und Admin-Anmeldeseiten
Markieren einer Seite Noindex und Nofollow
Eine Seite, die sowohl mit noindex als auch mit nofollow gekennzeichnet ist, blockiert einen Crawler daran, diese Seite zu indizieren, und blockiert einen Crawler daran, die Links auf der Seite zu durchsuchen.
Das folgende Bild zeigt im Wesentlichen, was eine Suchmaschine auf einer Webseite sieht, je nachdem, wie Sie die Anweisungen noindex und nofollow verwendet haben:

Markieren einer bereits indizierten Seite als NoIndex
Wenn eine Suchmaschine eine Seite bereits indexiert hat und Sie sie als noindex markieren, wird die Seite beim nächsten Crawlen aus den Suchergebnissen entfernt Damit diese Methode zum Entfernen einer Seite aus dem Index funktioniert, dürfen Sie den Crawler nicht mit Ihrer robots.txt-Datei blockieren (nicht zulassen).
Wenn Sie einem Crawler sagen, dass er die Seite nicht lesen soll, wird er niemals die noindex -Markierung sehen und die Seite bleibt indexiert, obwohl ihr Inhalt nicht aktualisiert wird.
Wie verhindere ich, dass Suchmaschinen meine Website indexieren?
Wenn Sie eine Seite aus dem Suchindex entfernen möchten, nachdem sie bereits indiziert wurde, können Sie die folgenden Schritte ausführen:
- Wenden Sie die noindex-Direktive an. Fügen Sie das noindex-Attribut zum Meta-Tag oder HTTP-Antwort-Header hinzu
- Fordern Sie die Suchmaschine auf, die Seite zu crawlen . Für Google können Sie dies in der Suchkonsole tun. Fordern Sie an, dass Google die Seite neu indexiert. Dadurch wird der Googlebot veranlasst, die Seite zu crawlen, wobei der Googlebot die noindex-Anweisung entdeckt. Sie müssen dies für jede Suchmaschine tun, aus der Sie die Seite entfernen möchten.
- Bestätigen, dass die Seite aus der Suche entfernt wurde Nachdem Sie den Crawler aufgefordert haben, Ihre Webseite erneut zu besuchen, geben Sie ihm etwas Zeit und bestätigen Sie dann, dass Ihre Seite aus den Suchergebnissen entfernt wurde. Sie können dies tun, indem Sie zu einer beliebigen Suchmaschine gehen und die Ziel-URL mit Doppelpunkt eingeben, wie im Bild unten.
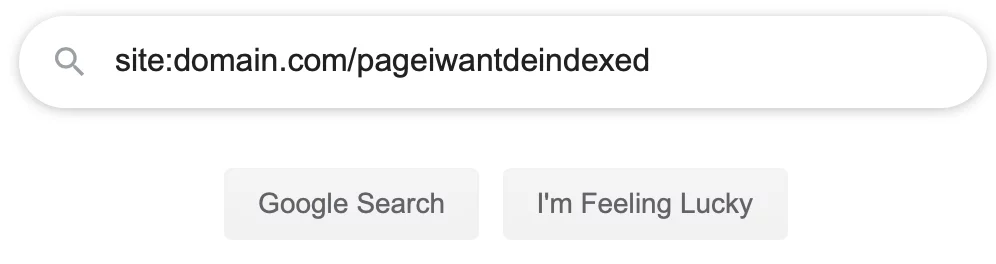
Wenn Ihre Suche keine Ergebnisse liefert, wurde Ihre Seite aus diesem Suchindex entfernt. - Wenn die Seite nicht entfernt wurde Vergewissern Sie sich, dass Ihre robots.txt-Datei keine „disallow“-Anweisung enthält. Google und andere Suchmaschinen können die noindex-Anweisung nicht lesen, wenn sie die Seite nicht crawlen dürfen. Entfernen Sie in diesem Fall die disallow-Anweisung für die Zielseite und fordern Sie das Crawlen erneut an.
- Setzen Sie eine Disallow-Anweisung für die Zielseite in Ihrer robots.txt-Datei Disallow: /page$
Sie müssen das Dollarzeichen am Ende der URL in Ihrer robots.txt-Datei einfügen oder Sie können versehentlich alle Seiten unter dieser Seite sowie alle Seiten, die mit derselben Zeichenfolge beginnen, verbieten. Beispiel: Disallow: /sweater verbietet auch /sweater-weather und /sweater/green, aber Disallow: /sweater$ verbietet nur die genaue Seite /sweater.
Wie um eine Seite aus der Google-Suche zu entfernen
Wenn sich die Seite, die Sie aus der Suche entfernen möchten, auf einer Website befindet, die Sie besitzen oder verwalten, können die meisten Websites das Tool zum Entfernen von Webmaster-URLs verwenden.
Das Tool zum Entfernen von Webmaster-URLs entfernt Inhalte nur etwa 90 Tage lang aus der Suche. Wenn Sie eine dauerhaftere Lösung wünschen, müssen Sie eine noindex-Anweisung verwenden, das Crawlen aus Ihrer robots.txt-Datei verbieten oder die Seite von Ihrer Website entfernen. Google stellt hier zusätzliche Anweisungen zum dauerhaften Entfernen von URLs zur Verfügung.

Wenn Sie versuchen, eine Seite für eine Website, die Ihnen nicht gehört, aus der Suche zu entfernen, können Sie Google bitten, die Seite aus der Suche zu entfernen, wenn sie die folgenden Kriterien erfüllt:
- Zeigt persönliche Informationen wie Ihre Kreditkarten- oder Sozialversicherungsnummer an
- Die Seite ist Teil eines Malware- oder Phishing-Schemas
- Die Seite verstößt gegen das Gesetz
- Die Seite verstößt gegen ein Urheberrecht
Wenn die Seite eines der oben genannten Kriterien nicht erfüllt, können Sie sich an eine SEO-Firma oder PR-Firma wenden, um Hilfe beim Online-Reputationsmanagement zu erhalten.
Sollten Sie Kategorieseiten noindexen?
Es wird normalerweise nicht empfohlen, Kategorieseiten zu noindexen, es sei denn, Sie sind eine Organisation auf Unternehmensebene, die Kategorieseiten programmgesteuert auf der Grundlage von benutzergenerierten Suchen oder Tags erstellt, und der doppelte Inhalt wird unhandlich.
Wenn Sie Ihre Inhalte intelligent taggen, damit die Benutzer besser auf Ihrer Website navigieren und finden können, was sie brauchen, dann sind Sie größtenteils in Ordnung.
Tatsächlich können Kategorieseiten Goldminen für SEO sein, da sie normalerweise eine Tiefe von Inhalten unter den Kategoriethemen zeigen.
Werfen Sie einen Blick auf diese Analyse, die wir im Dezember 2018 durchgeführt haben, um den Wert von Kategorieseiten für eine Handvoll Online-Publikationen zu quantifizieren.
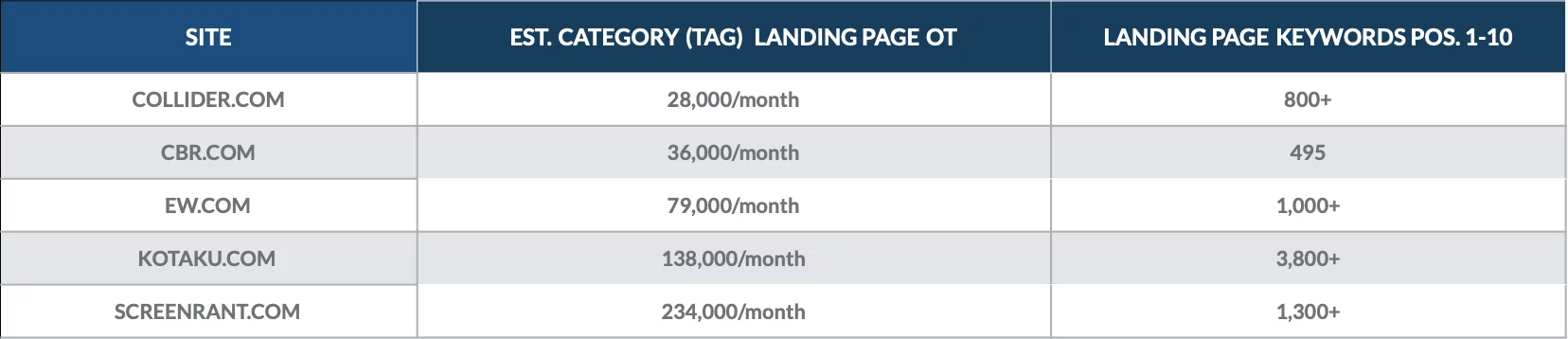
Wir haben festgestellt, dass Kategorie-Landingpages für Hunderte von Keywords auf Seite 1 gerankt sind und jeden Monat Tausende von organischen Besuchern angezogen haben.
Die wertvollsten Kategorieseiten für jede Website brachten oft Tausende von organischen Besuchern.
Werfen Sie einen Blick auf EW.com unten, wir haben den Traffic zu jeder Seite (dargestellt durch die Größe des Kreises) und den Wert des Traffics zu jeder Seite (dargestellt durch die Farbe des Kreises) gemessen.
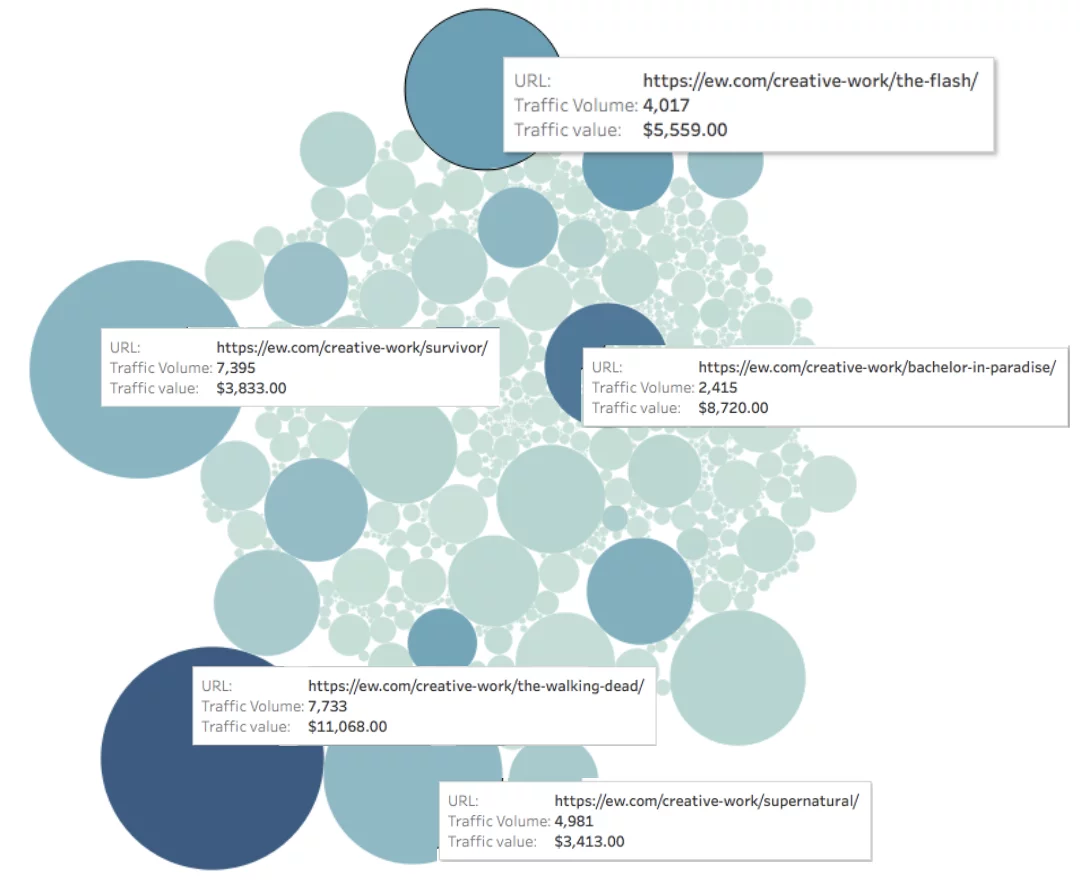
Monatlicher organischer Wert der Seite = Farbtiefe
Stellen Sie sich nun die gleichen Diagramme vor, aber für produktbasierte Websites, auf denen Besucher wahrscheinlich aktive Einkäufe tätigen.
Wenn Ihre Kategorien jedoch ähnlich genug sind, um Benutzer zu verwirren oder bei der Suche miteinander zu konkurrieren, müssen Sie möglicherweise eine Änderung vornehmen:
- Wenn Sie die Kategorien selbst festlegen, empfehlen wir, Inhalte von einer Kategorie in die andere zu migrieren und die Gesamtzahl Ihrer Kategorien insgesamt zu reduzieren.
- Wenn Sie Benutzern erlauben, Kategorien zu erstellen, sollten Sie die benutzergenerierten Kategorieseiten noindexieren, zumindest bis die neuen Kategorien einem Überprüfungsprozess unterzogen wurden.
Wie verhindere ich, dass Google Subdomains indexiert?
Es gibt einige Optionen, um Google daran zu hindern, Subdomains zu indizieren:
- Sie können ein Passwort mithilfe einer .htpasswd-Datei hinzufügen
- Sie können Crawler mit einer robots.txt-Datei verbieten
- Sie können jeder Seite in der Subdomain eine noindex-Direktive hinzufügen
- Sie können alle Subdomain-Seiten mit 404 erreichen
Hinzufügen eines Passworts zum Blockieren der Indizierung
Wenn Ihre Subdomains Entwicklungszwecken dienen, ist das Hinzufügen einer .htpasswd-Datei zum Stammverzeichnis Ihrer Subdomain die perfekte Option. Die Login-Wall hindert Crawler daran, Inhalte auf der Subdomain zu indizieren, und verhindert den Zugriff unbefugter Benutzer.
Beispielanwendungsfälle:
- dev.domain.com
- Staging.domain.com
- Testing.domain.com
- QA.domain.com
- UAT.domain.com
Verwenden von robots.txt zum Blockieren der Indizierung
Wenn Ihre Subdomains anderen Zwecken dienen, können Sie dem Stammverzeichnis Ihrer Subdomain eine robots.txt-Datei hinzufügen. Es sollte dann wie folgt zugänglich sein:
https://subdomain.domain.com/robots.txt
Sie müssen jeder Subdomain, die Sie für die Suche blockieren möchten, eine robots.txt-Datei hinzufügen. Beispiel:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
In jedem Fall sollte die robots.txt-Datei Crawler verbieten, um die meisten Crawler mit einem einzigen Befehl zu blockieren, verwenden Sie den folgenden Code:
User-Agent: *
Nicht zulassen: /
Der Stern * nach user-agent: wird als Platzhalter bezeichnet, er passt zu einer beliebigen Zeichenfolge. Die Verwendung eines Platzhalters sendet die folgende Disallow-Anweisung an alle Benutzeragenten, unabhängig von ihrem Namen, von Googlebot bis Yandex.
Der Backslash teilt dem Crawler mit, dass alle Seiten außerhalb der Subdomain in der Disallow-Anweisung enthalten sind.
So blockieren Sie selektiv die Indizierung von Subdomain-Seiten
Wenn Sie möchten, dass einige Seiten einer Subdomain in der Suche angezeigt werden, andere jedoch nicht, haben Sie zwei Möglichkeiten:
- Verwenden Sie noindex-Direktiven auf Seitenebene
- Verwenden Sie Disallow-Anweisungen auf Ordner- oder Verzeichnisebene
noindex-Direktiven auf Seitenebene sind umständlicher zu implementieren, da die Direktive zum HTML oder Header jeder Seite hinzugefügt werden muss. Noindex-Anweisungen hindern Google jedoch daran, eine Subdomain zu indizieren, unabhängig davon, ob die Subdomain bereits indiziert wurde oder nicht.
Disallow-Anweisungen auf Verzeichnisebene sind einfacher zu implementieren, funktionieren aber nur, wenn die Subdomain-Seiten nicht bereits im Suchindex enthalten sind. Aktualisieren Sie einfach die robots.txt-Datei der Subdomain, um das Crawlen der entsprechenden Verzeichnisse oder Unterordner zu unterbinden.
Woher weiß ich, ob meine Seiten NoIndexed sind?
Das versehentliche Hinzufügen von Seiten ohne Indexrichtlinie auf Ihrer Website kann drastische Folgen für Ihre Suchrankings und die Sichtbarkeit der Suche haben.
Wenn Sie feststellen, dass eine Seite trotz guter Inhalte und Backlinks keinen organischen Traffic verzeichnet, überprüfen Sie zunächst stichprobenartig, ob Sie nicht versehentlich Crawler aus Ihrer robots.txt-Datei ausgeschlossen haben. Wenn das Ihr Problem nicht löst, müssen Sie die einzelnen Seiten auf noindex-Anweisungen überprüfen.
Prüfung auf NoIndex auf WordPress-Seiten
WordPress macht es einfach, dieses Tag auf Ihren Seiten hinzuzufügen oder zu entfernen. Der erste Schritt bei der Suche nach nofollow auf Ihren Seiten besteht darin, einfach die Einstellung für die Suchmaschinensichtbarkeit auf der Registerkarte „Lesen“ des Menüs „Einstellungen“ umzuschalten.
Dies wird das Problem wahrscheinlich lösen, aber diese Einstellung funktioniert eher als „Vorschlag“ als als Regel, und einige Ihrer Inhalte werden möglicherweise trotzdem indiziert.
Um absolute Privatsphäre für Ihre Dateien und Inhalte zu gewährleisten, müssen Sie einen letzten Schritt unternehmen, um entweder Ihre Website mit einem Passwort zu schützen, indem Sie entweder cPanel-Verwaltungstools, falls verfügbar, oder ein einfaches Plugin verwenden.
Ebenso können Sie dieses Tag aus Ihren Inhalten entfernen, indem Sie den Passwortschutz entfernen und die Sichtbarkeitseinstellung deaktivieren.
Suche nach NoIndex auf Squarespace
Squarespace-Seiten können mithilfe der Code-Injection-Funktion der Plattform auch einfach NoIndexed werden. Squarespace lässt sich wie WordPress einfach per Passwortschutz für routinemäßige Suchen sperren, allerdings rät die Plattform auch davon ab, diesen Schritt zu tun, um die Integrität Ihrer Inhalte zu schützen.
Indem Sie die NoIndex-Codezeile auf jeder Seite, die Sie vor Internetsuchmaschinen verbergen möchten, und auf jeder darunter liegenden Unterseite hinzufügen, können Sie die Sicherheit von gesicherten Inhalten gewährleisten, die für den öffentlichen Zugriff gesperrt werden sollten. Wie bei anderen Plattformen ist auch das Entfernen dieses Tags ziemlich einfach: Sie müssen lediglich die Code-Injection-Funktion verwenden, um den Code wieder zu entfernen.
Squarespace ist insofern einzigartig, als seine Konkurrenten diese Option hauptsächlich als Teil der Suite von Einstellungen in Seitenverwaltungstools anbieten. Squarespace fährt hier ab und ermöglicht eine persönliche Manipulation des Codes. Dies ist interessant, da Sie im Gegensatz zu den anderen in diesem Bereich die Änderungen sehen können, die Sie am Inhalt Ihrer Seite vornehmen.
Suche nach NoIndex bei Wix
Wix ermöglicht auch eine einfache und schnelle Lösung für NoIndexing-Probleme. In den „Menüs & Seiten“-Einstellungen können Sie einfach die Option „Diese Seite in den Suchergebnissen anzeigen“ deaktivieren, wenn Sie eine einzelne Seite Ihrer Website mit NoIndex versehen möchten.
Wie bei seinen Konkurrenten schlägt Wix auch vor, Ihre Seiten oder die gesamte Website mit einem Passwort zu schützen, um mehr Privatsphäre zu gewährleisten. Wix unterscheidet sich jedoch von den anderen darin, dass das Support-Team keine parallelen Maßnahmen an beiden Fronten vorschreibt, um Inhalte vor dem Crawler zu sichern. Wix weist besonders auf den Unterschied zwischen dem Ausblenden einer Seite aus deinem Menü und dem Ausblenden vor Suchkriterien hin.
Dies ist ein besonders nützlicher Rat für weniger erfahrene Website-Ersteller, die den Unterschied möglicherweise zunächst nicht verstehen, wenn man bedenkt, dass das Entfernen aus Ihrem Website-Menü die Seite von der Website aus nicht erreichbar macht, aber nicht von einem umsichtigen Google-Suchbegriff.