
Themenmodellierung mit Word2Vec
Veröffentlicht: 2022-05-02Ein Wort wird durch die Gesellschaft definiert, die es führt. Das ist die Prämisse hinter Word2Vec, einer Methode zur Umwandlung von Wörtern in Zahlen und deren Darstellung in einem mehrdimensionalen Raum. Wörter, die in einer Sammlung von Dokumenten (Korpus) häufig dicht beieinander zu finden sind, werden in diesem Raum ebenfalls dicht beieinander erscheinen. Sie sollen kontextuell verwandt sein.
Word2Vec ist eine Methode des maschinellen Lernens, die einen Korpus und eine angemessene Schulung erfordert. Die Qualität beider beeinflusst die Fähigkeit, ein Thema genau zu modellieren. Jegliche Mängel werden leicht ersichtlich, wenn die Ausgabe für sehr spezifische und komplizierte Themen untersucht wird, da diese am schwierigsten genau zu modellieren sind. Word2Vec kann allein verwendet werden, obwohl es häufig mit anderen Modellierungstechniken kombiniert wird, um seine Grenzen zu überwinden.
Der Rest dieses Artikels bietet zusätzlichen Hintergrund zu Word2Vec, wie es funktioniert, wie es bei der Themenmodellierung verwendet wird und einige der Herausforderungen, die es mit sich bringt.
Was ist Word2Vec?
Im September 2013 veröffentlichten die Google-Forscher Tomas Mikolov, Kai Chen, Greg Corrado und Jeffrey Dean das Paper „Efficient Estimation of Word Representations in Vector Space“ (pdf). Dies bezeichnen wir jetzt als Word2Vec. Das Ziel des Papiers war es, „Techniken vorzustellen, die zum Lernen hochwertiger Wortvektoren aus riesigen Datensätzen mit Milliarden von Wörtern und mit Millionen von Wörtern im Vokabular verwendet werden können“.
Vor diesem Punkt behandelten alle Techniken zur Verarbeitung natürlicher Sprache Wörter als singuläre Einheiten. Sie berücksichtigten keine Ähnlichkeit zwischen Wörtern. Obwohl es triftige Gründe für diesen Ansatz gab, hatte er seine Grenzen. Es gab Situationen, in denen die Skalierung dieser grundlegenden Techniken keine signifikante Verbesserung bringen konnte. Daher die Notwendigkeit, fortschrittliche Technologien zu entwickeln.
Das Papier zeigte, dass einfache Modelle mit ihren geringeren Rechenanforderungen qualitativ hochwertige Wortvektoren trainieren können. Wie das Papier abschließt, ist es „möglich, sehr genaue hochdimensionale Wortvektoren aus einem viel größeren Datensatz zu berechnen“. Die Rede ist von Dokumentensammlungen (Corpora) mit einer Billion Wörtern, die eine praktisch unbegrenzte Größe des Vokabulars bieten.
Word2Vec ist eine Möglichkeit, Wörter in Zahlen, in diesem Fall Vektoren, umzuwandeln, damit Ähnlichkeiten mathematisch entdeckt werden können. Die Idee ist, dass Vektoren ähnlicher Wörter innerhalb des Vektorraums gruppiert werden.
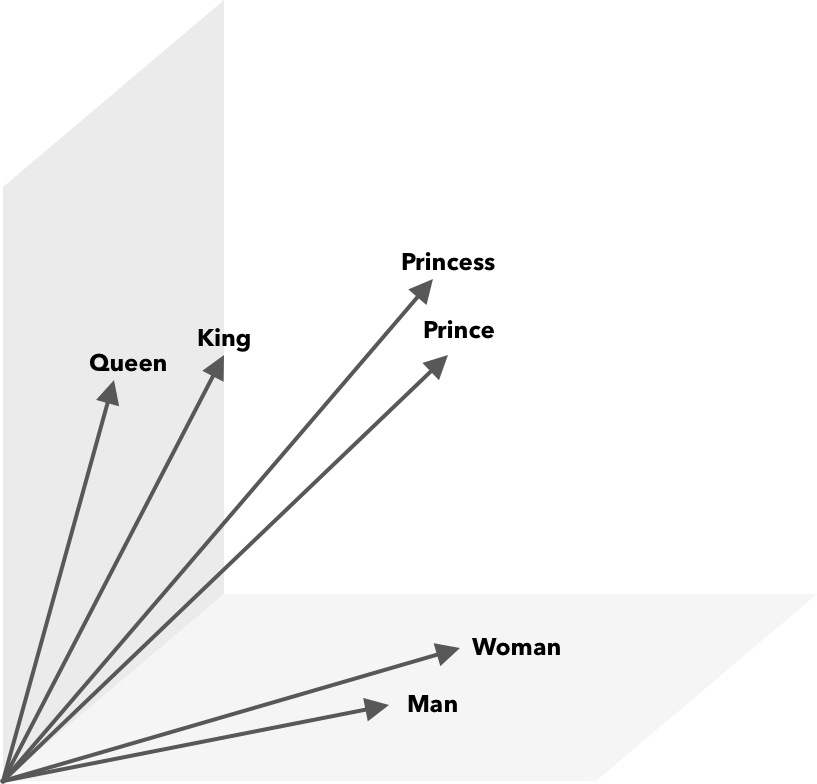
Denken Sie an die Breiten- und Längenkoordinaten auf einer Karte. Mithilfe dieses zweidimensionalen Vektors können Sie schnell feststellen, ob zwei Orte relativ nahe beieinander liegen. Damit Wörter in einem Vektorraum angemessen dargestellt werden können, reichen zwei Dimensionen nicht aus. Vektoren müssen also viele Dimensionen enthalten.
Wie funktioniert Word2Vec?
Word2Vec nimmt als Eingabe einen großen Textkorpus und vektorisiert ihn unter Verwendung eines flachen neuronalen Netzes. Die Ausgabe ist eine Liste von Wörtern (Vokabular), jedes mit einem entsprechenden Vektor. Wörter mit ähnlicher Bedeutung treten räumlich in unmittelbarer Nähe auf. Mathematisch wird dies durch Kosinusähnlichkeit gemessen, wobei die Gesamtähnlichkeit als 0-Grad-Winkel ausgedrückt wird, während keine Ähnlichkeit als 90-Grad-Winkel ausgedrückt wird.
Wörter können als Vektoren codiert werden, indem verschiedene Arten von Modellen verwendet werden. In ihrer Veröffentlichung beschreiben Mikolov et al. betrachteten zwei bestehende Modelle, Feedforward Neural Net Language Model (NNLM) und Recurrent Neural Net Language Model (RNNLM). Darüber hinaus schlagen sie zwei neue log-lineare Modelle vor, Continuous Bag of Words (CBOW) und Continuous Skip-gram.
In ihren Vergleichen schnitten CBOW und Skip-gram besser ab, also lassen Sie uns diese beiden Modelle untersuchen.
CBOW ähnelt NNLM und verlässt sich auf den Kontext, um ein Zielwort zu bestimmen. Es bestimmt das Zielwort anhand der Wörter, die davor und danach kommen. Mikolov fand heraus, dass die beste Leistung mit vier zukünftigen und vier historischen Wörtern erzielt wurde. Es wird „Beutel mit Wörtern“ genannt, weil die Reihenfolge der Wörter in der Geschichte die Ausgabe nicht beeinflusst. „Kontinuierlich“ im Begriff CBOW bezieht sich auf die Verwendung einer „kontinuierlich verteilten Darstellung des Kontexts“.
Skip-gram ist die Umkehrung von CBOW. Bei einem gegebenen Wort werden umgebende Wörter innerhalb eines bestimmten Bereichs vorhergesagt. Ein größerer Bereich sorgt für Wortvektoren besserer Qualität, erhöht aber die Rechenkomplexität. Entfernten Begriffen wird weniger Gewicht beigemessen, da sie normalerweise weniger mit dem aktuellen Wort zu tun haben.
Beim Vergleich von CBOW mit Skip-Gramm hat sich herausgestellt, dass letzteres qualitativ bessere Ergebnisse bei großen Datensätzen liefert. Obwohl CBOW schneller ist, verarbeitet Skip-gram selten verwendete Wörter besser.
Beim Training wird jedem Wort ein Vektor zugeordnet. Die Komponenten dieses Vektors werden so angepasst, dass ähnliche Wörter (basierend auf ihrem Kontext) näher beieinander liegen. Stellen Sie sich das als Tauziehen vor, bei dem jedes Mal, wenn ein weiterer Begriff dem Raum hinzugefügt wird, Wörter in diesem multidimensionalen Vektor herumgeschoben und gezogen werden.
An Wortvektoren können zusätzlich zur Kosinusähnlichkeit mathematische Operationen durchgeführt werden. Beispiel: Vektor(”König”) – Vektor(”Mann”) + Vektor(”Frau”) ergibt einen Vektor, der dem am nächsten kommt, der das Wort Königin darstellt.

Word2Vec für Themenmodellierung
Das von Word2Vec erstellte Vokabular kann direkt abgefragt werden, um Beziehungen zwischen Wörtern zu erkennen, oder in ein tieflernendes neuronales Netzwerk eingespeist werden. Ein Problem mit Word2Vec-Algorithmen wie CBOW und Skip-gram ist, dass sie jedes Wort gleich gewichten. Das Problem bei der Arbeit mit Dokumenten besteht darin, dass Wörter nicht gleichermaßen die Bedeutung eines Satzes darstellen.
Manche Wörter sind wichtiger als andere. Daher werden häufig verschiedene Gewichtungsstrategien wie TF-IDF verwendet, um mit der Situation umzugehen. Dies hilft auch, das im nächsten Abschnitt erwähnte Hubness-Problem zu lösen. Searchmetrics ContentExperience nutzt eine Kombination aus TF-IDF und Word2Vec, was Sie hier in unserem Vergleich mit MarketMuse nachlesen können.
Während Worteinbettungen wie Word2Vec morphologische, semantische und syntaktische Informationen erfassen, zielt die Themenmodellierung darauf ab, latente semantische Strukturen oder Themen in einem Korpus zu entdecken.
Laut Budhkar und Rudzicz (PDF) kann die Kombination der latenten Dirichlet-Zuordnung (LDA) mit Word2Vec Unterscheidungsmerkmale erzeugen, um „das Problem zu lösen, das durch das Fehlen von Kontextinformationen verursacht wird, die in diese Modelle eingebettet sind“. Eine einfachere Lektüre zu LDA2vec finden Sie in diesem DataCamp-Tutorial.
Herausforderungen von Word2Vec
Es gibt im Allgemeinen mehrere Probleme mit Wörterinbettungen, einschließlich Word2Vec. Wir werden auf einige davon eingehen, für eine detailliertere Analyse siehe „A Survey of Word Embedding Evaluation Methods“ (pdf) von Amir Bakarov. Der Korpus und seine Größe sowie das Training selbst werden die Ausgabequalität erheblich beeinflussen.
Wie bewerten Sie die Ausgabe?
Wie Bakarov in seinem Artikel erklärt, bewertet ein NLP-Ingenieur die Leistung von Einbettungen normalerweise anders als ein Computerlinguist oder ein Content-Vermarkter. Hier sind einige zusätzliche Probleme, die in dem Papier zitiert werden.
- Semantik ist eine vage Idee. Eine „gute“ Worteinbettung spiegelt unsere Vorstellung von Semantik wieder. Wir sind uns jedoch möglicherweise nicht bewusst, ob unser Verständnis richtig ist. Außerdem haben Wörter verschiedene Arten von Beziehungen wie semantische Verwandtschaft und semantische Ähnlichkeit. Welche Art von Beziehung soll das Wort Einbettung widerspiegeln?
- Mangel an geeigneten Trainingsdaten. Beim Training von Worteinbettungen erhöhen Forscher häufig deren Qualität, indem sie sie an die Daten anpassen. Dies bezeichnen wir als Kurvenanpassung. Anstatt das Ergebnis an die Daten anzupassen, sollten Forscher versuchen, die Beziehungen zwischen Wörtern zu erfassen.
- Das Fehlen einer Korrelation zwischen intrinsischen und extrinsischen Methoden bedeutet, dass unklar ist, welche Methodenklasse bevorzugt wird. Die extrinsische Bewertung bestimmt die Ausgabequalität für die weiter nachgelagerte Verwendung in anderen Aufgaben zur Verarbeitung natürlicher Sprache. Die intrinsische Bewertung beruht auf der menschlichen Beurteilung von Wortbeziehungen.
- Das Hubness-Problem. Hubs, Wortvektoren, die gebräuchliche Wörter darstellen, liegen in der Nähe einer übermäßigen Anzahl anderer Wortvektoren. Dieses Rauschen kann die Auswertung beeinflussen.
Darüber hinaus gibt es insbesondere bei Word2Vec zwei große Herausforderungen.
- Es kann nicht gut mit Mehrdeutigkeiten umgehen. Infolgedessen spiegelt der Vektor eines Wortes mit mehreren Bedeutungen den Durchschnitt wider, der alles andere als ideal ist.
- Word2Vec kann keine Wörter außerhalb des Vokabulars (OOV) und morphologisch ähnliche Wörter verarbeiten. Wenn das Modell auf ein neues Konzept trifft, greift es auf die Verwendung eines Zufallsvektors zurück, der keine genaue Darstellung ist.
Zusammenfassung
Die Verwendung von Word2Vec oder einer anderen Worteinbettung ist keine Erfolgsgarantie. Qualitativ hochwertige Ergebnisse basieren auf einer angemessenen Schulung unter Verwendung eines angemessenen und ausreichend großen Korpus.
Die Bewertung der Ausgabequalität kann zwar mühsam sein, aber hier ist eine einfache Lösung für Content-Vermarkter. Wenn Sie das nächste Mal einen Inhaltsoptimierer evaluieren, versuchen Sie es mit einem ganz bestimmten Thema. Topic-Modelle von schlechter Qualität versagen, wenn es darum geht, auf diese Weise zu testen. Sie sind für allgemeine Begriffe in Ordnung, brechen jedoch zusammen, wenn die Anfrage zu spezifisch wird.
Wenn Sie also das Thema „Wie man Avocados anbaut“ verwenden, stellen Sie sicher, dass die Vorschläge etwas mit dem Anbau der Pflanze zu tun haben und nicht mit Avocados im Allgemeinen.
Die natürliche Sprachgenerierung von MarketMuse NLG Technology half bei der Erstellung dieses Artikels.
Was Sie jetzt tun sollten
Wenn Sie bereit sind … hier sind 3 Möglichkeiten, wie wir Ihnen helfen können, bessere Inhalte schneller zu veröffentlichen:
- Buchen Sie Zeit mit MarketMuse Planen Sie eine Live-Demo mit einem unserer Strategen, um zu sehen, wie MarketMuse Ihrem Team helfen kann, seine Content-Ziele zu erreichen.
- Wenn Sie erfahren möchten, wie Sie schneller bessere Inhalte erstellen, besuchen Sie unseren Blog. Es ist voll von Ressourcen, um Inhalte zu skalieren.
- Wenn Sie einen anderen Vermarkter kennen, der diese Seite gerne lesen würde, teilen Sie sie ihm per E-Mail, LinkedIn, Twitter oder Facebook.