
Welche Arten von Big Data gibt es: Merkmale und Definition
Veröffentlicht: 2023-10-06Zusammenfassung: Big Data umfasst vier Typen: strukturierte, unstrukturierte, halbstrukturierte und quasistrukturierte Daten. Im Folgenden erfahren Sie mehr über jeden Big-Data-Typ im Detail!
Die meisten Unternehmen verlassen sich auf die Datensätze, um Einblicke zu gewinnen und mehr über ihre Kunden, die Branche und das Unternehmen zu erfahren. Wenn die Daten jedoch größer werden, wird es schwierig, die Daten zu handhaben und zu verarbeiten.
Diese Datensätze werden Big Data Sets genannt, die eine größere Datenvielfalt aufweisen und von Natur aus enorm sind. Big Data kann in verschiedenen Formen vorliegen, z. B. strukturiert, unstrukturiert, halbstrukturiert und quasistrukturiert.
Erfahren Sie im folgenden Artikel mehr über die verschiedenen Arten von Big Data-Sets.
Inhaltsverzeichnis
Was sind die beliebtesten Arten von Big Data?
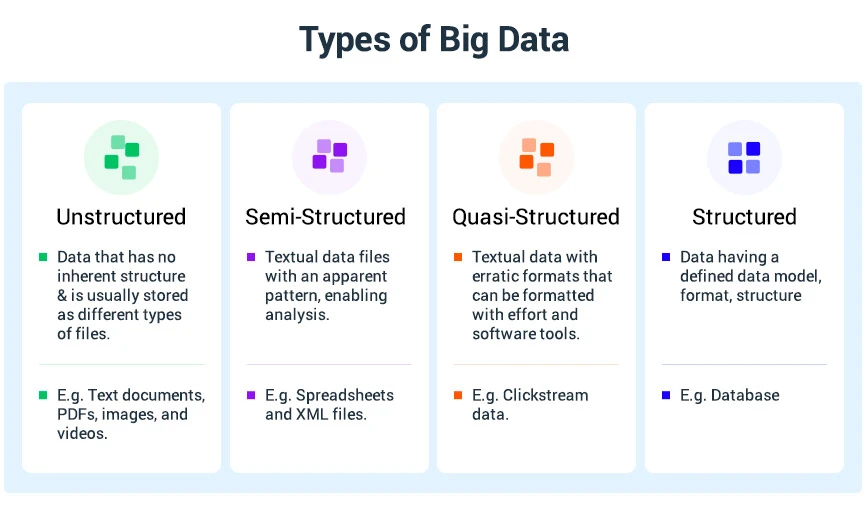
Big Data wird in die folgenden vier Haupttypen eingeteilt:
Strukturierte Daten
Strukturierte Daten sind Daten mit einem standardisierten Format, auf die Software und Benutzer problemlos zugreifen können. Es liegt im Allgemeinen in tabellarischer Form mit verschiedenen Zeilen und Spalten vor, die die Datenattribute hervorheben.
Strukturierte Daten umfassen quantitative Daten wie Alter, Kontaktnummer, Kreditkartennummern usw. Da es quantitativer Natur ist, kann die Software es problemlos verarbeiten, um wertvolle Erkenntnisse zu gewinnen.
Um die Strukturdaten zu verarbeiten, müssen Sie die Daten nicht mit relevanten Metriken verknüpfen. Darüber hinaus müssen die Strukturdaten nicht tiefgreifend konvertiert und interpretiert werden, um wertvolle Erkenntnisse zu gewinnen.
Wo werden strukturierte Datentypen verwendet?
- Kundendaten verwalten
- Rechnungsdetails pflegen
- Speicherung von Produktdatenbanken
- Kontaktliste aufzeichnen
Vor- und Nachteile strukturierter Daten
- Dies erleichtert die Verarbeitung der Daten, da diese in einem definierten Format gespeichert werden.
- Die Daten werden im Vergleich zu den unstrukturierten Daten schnell verarbeitet
- Es ist möglicherweise nicht für alle Arten von Informationen geeignet, da die Daten in einem bestimmten Format gespeichert werden.
Unstrukturierte Daten: XML, JSON, YAML

Unstrukturierte Daten sind Daten, die nicht auf ein bestimmtes Datenmodell und eine identifizierbare Struktur beschränkt sind, die von einem Computerprogramm gelesen werden kann. Diese Art von Daten ist nicht ordnungsgemäß organisiert und weist keine Reihenfolge oder kein Format für die Datenverarbeitung auf.
Im Gegensatz zu strukturierten Daten können diese Datentypen nicht in Form von Zeilen und Spalten gespeichert werden. Ein häufiges Beispiel für unstrukturierte Daten ist eine heterogene Datenbank, die eine Kombination aus Bildern, Videos, Textdateien usw. enthält.
Wo werden unstrukturierte Datentypen verwendet?
- Verwalten von Audio- und Videodaten
- Umgang mit offenen Umfrageantworten
- Umgang mit Social-Media-Beiträgen
- Geschäftsdokumente verwalten
Vor- und Nachteile unstrukturierter Daten
- Da es keine definierte Struktur gibt, können die Daten schnell erfasst werden.
- Es kann für den Umgang mit heterogenen Datenquellen verwendet werden.
- Aufgrund des Fehlens einer Struktur oder eines Schemas ist die Verwaltung schwieriger.
Halbstrukturierte Daten
Halbstrukturierte Daten sind Daten, die nicht richtig strukturiert, aber gleichzeitig nicht völlig unstrukturiert sind. Diese Daten unterliegen nicht dem starren Schema und Datenmodell. Darüber hinaus kann es auch Komponenten enthalten, die nicht einfach kategorisiert oder klassifiziert werden können.
Die halbstrukturierten Daten zeichnen sich durch Metadaten und Tags aus, die zusätzliche Informationen zu allen Datenelementen bereitstellen. Beispielsweise kann eine XML-Datei Tags enthalten, die die Dokumentstruktur angeben, sowie zusätzliche Tags, die Metadaten zum Inhalt wie Datum oder Schlüsselwörter bereitstellen.
Wo verwendet man halbstrukturierte Datentypen?
- Analyse von Webseiten über HTML
- Nutzung von E-Mail-Daten, um Erkenntnisse über Kunden zu gewinnen
- Kategorisieren und Analysieren von Videos und Bildern
Vor- und Nachteile des halbstrukturierten Datentyps
- Das Schema der Daten kann geändert werden.
- Diese Art von Daten kann Daten aufnehmen, die möglicherweise nicht in ein vordefiniertes Schema passen.
- Datenabfragen sind im Vergleich zu strukturierten Daten weniger effizient.
Quasistrukturierte Daten
Quasistrukturierte Daten sind Textdaten mit unregelmäßigen Datenformaten. Diese Art von Daten kann mit verschiedenen Datenanalysetools formatiert werden. Dazu gehören Daten wie Web-Clickstream-Daten.

Wo kann ein quasistrukturierter Datentyp verwendet werden?
- Es kann zur Analyse der Webseitendaten verwendet werden
Vor- und Nachteile eines quasistrukturierten Datentyps
- Die Daten können schnell verarbeitet werden.
- Diese Art von Daten kann mithilfe von Datenanalysetools schnell formatiert werden.
- Das Laden der Daten kann einige Zeit dauern.
Was sind die Untertypen von Daten?
Es gibt mehrere Datenuntertypen, die nicht als Big Data gelten, aber für die Analyse wichtig sind. Der Ursprung solcher Daten kann aus sozialen Medien, betrieblicher Protokollierung, ereignisgesteuert oder geografisch stammen. Es kann auch von Open-Source-Systemen, über API übertragenen Daten und verlorenen oder gestohlenen Geräten stammen.
Merkmale von Big Data
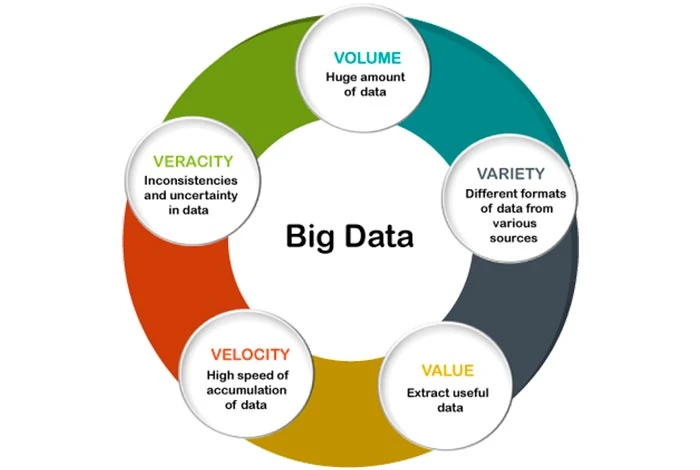
Es gibt fünf Vs , die die Merkmale von Big Data definieren. Diese Merkmale sind im Folgenden aufgeführt:
- Volumen: Das erste Merkmal von Big Data ist das Volumen. Bei Big Data handelt es sich um riesige Datenmengen, die aus mehreren Quellen gesammelt werden. Zu den Quellen können Geschäftsabläufe, Social-Media-Plattformen, Maschinen, menschliche Interaktionen usw. gehören.
- Wahrhaftigkeit: Wahrhaftigkeit kann als die Qualität und Genauigkeit gegebener Daten definiert werden. In den extrahierten Daten fehlen möglicherweise einige Elemente oder sie können möglicherweise keine wertvollen Erkenntnisse liefern. Daher ist dieses Merkmal nützlich, um die Datenqualität zu ermitteln und Erkenntnisse zu gewinnen.
- Vielfalt: Vielfalt kann als die Vielfalt verschiedener Datentypen definiert werden. Die Daten können aus mehreren Datenquellen bezogen werden, deren Wert variieren kann. Die gesammelten Daten können strukturiert, unstrukturiert oder halbstrukturiert sein. Die Datenvielfalt kann in Form von PDFs, E-Mails, Fotos, Audios usw. vorliegen.
- Wert: Dies kann als der Wert definiert werden, den Big Data bieten kann. Es ist wichtig, aus den gesammelten Daten einen Mehrwert zu ziehen, um daraus wertvolle Erkenntnisse zu gewinnen. Unternehmen können zur Analyse dieselben Big-Data-Analysetools verwenden, mit denen sie Daten gesammelt haben.
- Geschwindigkeit: Unter Geschwindigkeit versteht man die Geschwindigkeit, mit der Daten generiert und übertragen werden. Es ist ein wichtiges Element für Unternehmen, die einen schnellen Datenfluss wünschen, damit sie zum richtigen Zeitpunkt verfügbar sind, um Erkenntnisse zu gewinnen. Die Daten können aus verschiedenen Quellen wie Maschinen, Smartphones, Netzwerken usw. stammen. Sobald die Daten erfasst sind, können sie schnell analysiert werden.
Sektoren, die täglich Big Data nutzen
Big Data kann in verschiedenen Branchen eingesetzt werden, darunter im Gesundheitswesen, in der Landwirtschaft, im Bildungswesen, im Finanzwesen usw. Im Folgenden erfahren Sie mehr über die Anwendung von Big Data in den folgenden Bereichen:
- Bildung: Im Bildungsbereich können Lehrer die Leistungen und Abbrecherquoten der Schüler analysieren, um den Lehrplan zu optimieren. Darüber hinaus kann es auch dabei helfen, Verbesserungsbereiche zu identifizieren, indem die Leistung eines Schülers analysiert wird.
- E-Commerce: Der E-Commerce-Sektor kann Big-Data-Analysen nutzen, um zu verstehen, welche Abläufe in Ihrem Unternehmen gut laufen oder welche verbessert werden müssen. Darüber hinaus können Sie auch den Inhaltstyp identifizieren, der das Engagement fördert, und welche Kanäle den höchsten Traffic generieren.
- Gesundheitswesen: Im Gesundheitswesen können Big Data genutzt werden, um Erkenntnisse aus der biomedizinischen Forschung zu gewinnen und Patienten nach der Analyse ihrer Daten personalisierte Medikamentenempfehlungen zu geben. Darüber hinaus können sie durch die Überwachung des Zustands eines Patienten in Echtzeit Warnungen an das medizinische Personal senden.
- Regierung: Die Regierung kann Big Data nutzen, um die Daten der Bürger in großen Mengen über mehrere Parameter hinweg zu analysieren. Beispielsweise werden die Big Data der Volkszählung analysiert, um die Zahl der Jugendlichen im Land oder die Zahl der Arbeitslosen zu ermitteln. Die Erkenntnisse können ihnen bei der Entwicklung von Programmen und Plänen helfen, um die richtige Gruppe von Bürgern anzusprechen.
Empfohlene Lektüre: Top Business Intelligence (BI)-Tools
Abschluss
Big Data hat es für Unternehmen einfacher gemacht, große Datenmengen zu verarbeiten. Wenn die Daten in großen Mengen sortiert, organisiert und analysiert werden, können Unternehmen wertvolle Erkenntnisse gewinnen. Immer mehr Branchen verlassen sich auf Big-Data-Analysen, um komplexe Daten zu verarbeiten und die Schlussfolgerungen für ihren Wettbewerbsvorteil zu nutzen.
Häufig gestellte Fragen zu Arten von Big Data
Was ist Big Data und welche Art von Big Data?
Big Data ist eine Datenart, die eine größere Vielfalt aufweist, in größerem Umfang und mit größerer Geschwindigkeit vorliegt. Zu den Arten von Big Data gehören strukturierte, unstrukturierte und halbstrukturierte Daten.
Welche drei Arten der Big-Data-Klassifizierung gibt es?
Die drei Arten der Big-Data-Klassifizierung sind strukturierte, unstrukturierte und halbstrukturierte Daten.
Was sind die 4 Komponenten von Big Data?
Die vier Hauptkomponenten von Big Data sind Volumen, Geschwindigkeit, Vielfalt und Wahrhaftigkeit.
Was sind die 6 Merkmale von Big Data?
Big Data weist die folgenden Merkmale auf, die bei der Analyse von Daten helfen: Volumen, Vielfalt, Wahrhaftigkeit, Variabilität, Geschwindigkeit und Wert.
Was sind die Quellen von Big Data?
Die wichtigsten Quellen für Big Data lassen sich in soziale, maschinelle und transaktionale Daten einteilen. Soziale Quellen sind die am häufigsten genutzten Big-Data-Quellen für das Unternehmen. Dazu gehören Social-Media-Beiträge, gepostete Videos usw.