
Was ist Crawl-Budget und wie kann es auf intelligente Weise optimiert werden?
Veröffentlicht: 2021-08-19Inhaltsverzeichnis
Die Analyse des Crawl-Budgets gehört zu den Aufgaben eines jeden SEO-Experten (insbesondere, wenn es um große Websites geht). Eine wichtige Aufgabe, die in den von Google bereitgestellten Materialien anständig behandelt wird. Wie Sie jedoch auf Twitter sehen können, spielen sogar Google-Mitarbeiter die Rolle des Crawl-Budgets für besseren Traffic und Rankings herunter:

Haben sie Recht mit diesem?
Wie funktioniert Google und sammelt Daten?
Wenn wir das Thema anschneiden, erinnern wir uns daran, wie die Suchmaschine Informationen sammelt, indiziert und organisiert. Behalten Sie diese drei Schritte im Hinterkopf, während Sie später an der Website arbeiten:
Schritt 1: Krabbeln . Durchsuchen von Online-Ressourcen mit dem Ziel, alle vorhandenen Links, Dateien und Daten zu entdecken – und darin zu navigieren. Im Allgemeinen beginnt Google mit den beliebtesten Orten im Web und scannt dann andere, weniger trendige Ressourcen.
Schritt 2: Indizierung . Google versucht festzustellen, worum es auf der Seite geht und ob es sich bei dem analysierten Inhalt/Dokument um einzigartiges oder doppeltes Material handelt. In diesem Stadium gruppiert Google Inhalte und erstellt eine Reihenfolge nach Wichtigkeit (durch Lesen von Vorschlägen in den Tags rel=“canonical“ oder rel=“alternate“ oder auf andere Weise).
Schritt 3: Servieren . Einmal segmentiert und indiziert, werden die Daten als Antwort auf Benutzeranfragen angezeigt. In diesem Fall sortiert Google die Daten auch entsprechend, indem Faktoren wie der Standort des Benutzers berücksichtigt werden.
Wichtig: Viele der verfügbaren Materialien übersehen Schritt 4: Rendern von Inhalten . Standardmäßig indiziert der Googlebot Textinhalte. Da sich die Web-Technologien jedoch weiterentwickeln, musste Google neue Lösungen entwickeln, um nicht mehr nur zu „lesen“ sondern auch zu „sehen“. Darum geht es beim Rendern. Es dient Google dazu, seine Reichweite unter den neu gelaunchten Websites deutlich zu verbessern und den Index zu erweitern.
Hinweis : Probleme mit der Wiedergabe von Inhalten können die Ursache für ein ungenügendes Crawling-Budget sein.
Wie hoch ist das Crawl-Budget?
Das Crawl-Budget ist nichts anderes als die Häufigkeit, mit der die Crawler und Suchmaschinen-Bots Ihre Website indizieren können, sowie die Gesamtzahl der URLs, auf die sie bei einem einzigen Crawl zugreifen können. Stellen Sie sich Ihr Crawl-Budget als Credits vor, die Sie für einen Dienst oder eine App ausgeben können. Wenn Sie nicht daran denken, Ihr Crawl-Budget „aufzuladen“, wird der Roboter langsamer und besucht Sie weniger.
In der SEO bezieht sich „Aufladen“ auf die Arbeit, die in den Erwerb von Backlinks oder die Verbesserung der allgemeinen Popularität einer Website gesteckt wird. Folglich ist das Crawl-Budget ein integraler Bestandteil des gesamten Ökosystems des Webs. Wenn Sie beim Inhalt und den Backlinks gute Arbeit leisten, erhöhen Sie das Limit Ihres verfügbaren Crawl-Budgets.
Google wagt sich in seinen Ressourcen nicht daran, das Crawl-Budget explizit zu definieren. Stattdessen weist es auf zwei grundlegende Komponenten des Crawlings hin, die die Gründlichkeit des Googlebots und die Häufigkeit seiner Besuche beeinflussen:
- Begrenzung der Crawling-Rate;
- Crawl-Nachfrage.
Was ist das Crawling-Ratenlimit und wie kann es überprüft werden?
Einfach ausgedrückt ist das Crawling-Ratenlimit die Anzahl der gleichzeitigen Verbindungen, die der Googlebot beim Crawlen Ihrer Website herstellen kann. Da Google die Benutzererfahrung nicht beeinträchtigen möchte, begrenzt es die Anzahl der Verbindungen, um eine reibungslose Leistung Ihrer Website/Ihres Servers zu gewährleisten. Kurz gesagt, je langsamer Ihre Website ist, desto kleiner ist Ihr Limit für die Crawling-Rate.
Wichtig: Das Crawling-Limit hängt auch von der allgemeinen SEO-Gesundheit Ihrer Website ab – wenn Ihre Website viele Weiterleitungen oder 404/410-Fehler auslöst oder wenn der Server häufig einen 500-Statuscode zurückgibt, sinkt auch die Anzahl der Verbindungen.
Sie können Daten zum Crawling-Ratenlimit mit den in der Google Search Console verfügbaren Informationen im Crawling -Statistikbericht analysieren.
Crawling-Nachfrage oder Website-Popularität
Während die Begrenzung der Crawling-Rate erfordert, dass Sie die technischen Details Ihrer Website aufpolieren, belohnt Sie die Crawling-Nachfrage für die Popularität Ihrer Website. Grob gesagt gilt: Je größer die Aufregung um Ihre Website (und auf ihr), desto größer die Crawling-Nachfrage.
In diesem Fall zieht Google eine Bestandsaufnahme von zwei Problemen:
- Allgemeine Popularität – Google ist eher bestrebt, häufige Crawls der URLs durchzuführen, die im Allgemeinen im Internet beliebt sind (nicht unbedingt die mit Backlinks von der größten Anzahl von URLs).
- Aktualität der Indexdaten – Google ist bestrebt, nur die neuesten Informationen zu präsentieren. Wichtig: Das Erstellen von immer mehr neuen Inhalten bedeutet nicht, dass Ihr Gesamtlimit für das Crawling-Budget steigt.
Faktoren, die das Crawl-Budget beeinflussen
Im vorherigen Abschnitt haben wir das Crawl-Budget als eine Kombination aus dem Crawl-Ratenlimit und der Crawl-Nachfrage definiert. Denken Sie daran, dass Sie sich um beides gleichzeitig kümmern müssen, um ein ordnungsgemäßes Crawling (und damit eine Indexierung) Ihrer Website sicherzustellen.
Nachfolgend finden Sie eine einfache Liste mit Punkten, die bei der Optimierung des Crawl-Budgets zu berücksichtigen sind
- Server – das Hauptproblem ist die Leistung. Je niedriger Ihre Geschwindigkeit ist, desto höher ist das Risiko, dass Google weniger Ressourcen für die Indizierung Ihrer neuen Inhalte bereitstellt.
- Server-Antwortcodes – Je größer die Anzahl der 301-Weiterleitungen und 404/410-Fehler auf Ihrer Website, desto schlechtere Indizierungsergebnisse erhalten Sie. Wichtig: Achten Sie auf Umleitungsschleifen – jeder „Hop“ reduziert das Crawl-Rate-Limit Ihrer Website für den nächsten Besuch des Bots.
- Blöcke in der robots.txt – Wenn Sie Ihre robots.txt-Anweisungen auf Ihr Bauchgefühl stützen, können Sie am Ende Engpässe bei der Indizierung verursachen. Das Ergebnis: Sie bereinigen den Index, aber auf Kosten Ihrer Indizierungseffektivität für neue Seiten (wenn die blockierten URLs fest in die Struktur der gesamten Website eingebettet waren).
- Facettennavigation / Sitzungskennungen / beliebige Parameter in den URLs – achten Sie vor allem auf die Situationen, in denen eine Adresse mit einem Parameter ohne Einschränkungen weiter parametrisiert werden kann. Wenn das passieren sollte, wird Google eine unendliche Anzahl von Adressen erreichen und alle verfügbaren Ressourcen auf die weniger wichtigen Teile unserer Website verwenden.
- Duplicate Content – kopierte Inhalte (abgesehen von der Kannibalisierung) beeinträchtigen die Effektivität der Indizierung neuer Inhalte erheblich.
- Thin Content – was auftritt, wenn eine Seite ein sehr niedriges Text-zu-HTML-Verhältnis hat. Dadurch kann Google die Seite als sogenannten Soft 404 identifizieren und die Indexierung ihres Inhalts einschränken (selbst wenn der Inhalt aussagekräftig ist, was beispielsweise auf einer Herstellerseite der Fall sein kann, die ein einzelnes Produkt und kein eindeutiges Produkt präsentiert Textinhalt).
- Schlechte oder fehlende interne Verlinkung .
Nützliche Tools für die Analyse des Crawl-Budgets
Da es keinen Benchmark für das Crawl-Budget gibt (was bedeutet, dass es schwierig ist, Limits zwischen Websites zu vergleichen), rüsten Sie sich mit einer Reihe von Tools aus, die die Datenerfassung und -analyse erleichtern sollen.
Google Search Console
GSC ist im Laufe der Jahre gut gewachsen. Während einer Crawl-Budget-Analyse gibt es zwei Hauptberichte, die wir uns ansehen sollten: Indexabdeckung und Crawl-Statistiken.
Indexabdeckung in GSC
Der Bericht ist eine riesige Datenquelle. Überprüfen wir die Informationen zu URLs, die von der Indexierung ausgeschlossen sind. Es ist eine großartige Möglichkeit, das Ausmaß des Problems zu verstehen, mit dem Sie konfrontiert sind.
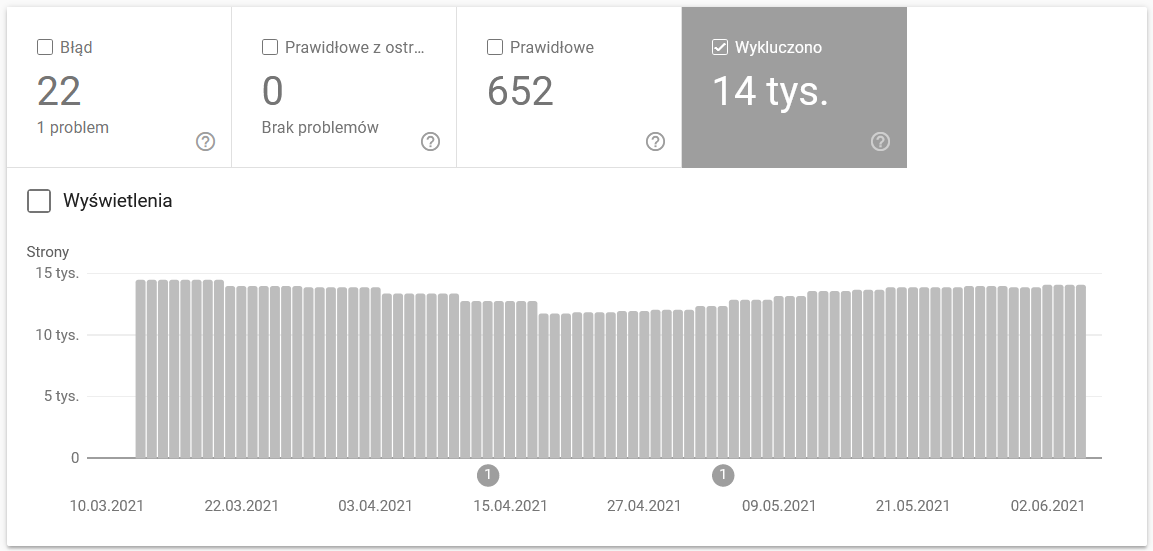
Der gesamte Bericht verdient einen separaten Artikel, also konzentrieren wir uns vorerst auf die folgenden Informationen:
- Ausgeschlossen durch 'noindex'-Tag – Im Allgemeinen bedeuten mehr noindex-Seiten weniger Verkehr. Was die Frage aufwirft – welchen Sinn hat es, sie auf der Website zu halten? Wie schränke ich den Zugriff auf diese Seiten ein?
- Gecrawlt – derzeit nicht indexiert – wenn Sie das sehen, überprüfen Sie, ob der Inhalt in den Augen des Googlebot korrekt dargestellt wird. Denken Sie daran, dass jede URL mit diesem Status Ihr Crawl-Budget verschwendet, da sie keinen organischen Traffic generiert.
- Entdeckt – derzeit nicht indiziert – eines der alarmierenderen Probleme, die es wert sind, ganz oben auf Ihre Prioritätenliste gesetzt zu werden.
- Duplizieren ohne vom Benutzer ausgewählte kanonische Seiten – alle doppelten Seiten sind äußerst gefährlich, da sie nicht nur Ihr Crawl-Budget beeinträchtigen, sondern auch das Risiko einer Kannibalisierung erhöhen.
- Duplicate, Google hat andere Canonicals als User gewählt – theoretisch kein Grund zur Sorge. Schließlich sollte Google schlau genug sein, um an unserer Stelle eine fundierte Entscheidung zu treffen. Nun, in Wirklichkeit wählt Google seine Canonicals ziemlich zufällig aus – oft werden wertvolle Seiten mit einem Canonical , das auf die Startseite verweist, abgeschnitten.
- Soft 404 – alle „weichen“ Fehler sind sehr gefährlich, da sie dazu führen können, dass kritische Seiten aus dem Index entfernt werden.
- Doppelte, eingereichte URL nicht als kanonisch ausgewählt – ähnlich der Statusmeldung zum Fehlen von vom Benutzer ausgewählten kanonischen URLs.
Crawl-Statistiken
Der Bericht ist nicht perfekt und was Empfehlungen betrifft, empfehle ich dringend, auch mit den guten alten Serverprotokollen zu spielen, die einen tieferen Einblick in die Daten (und mehr Modellierungsoptionen) geben.
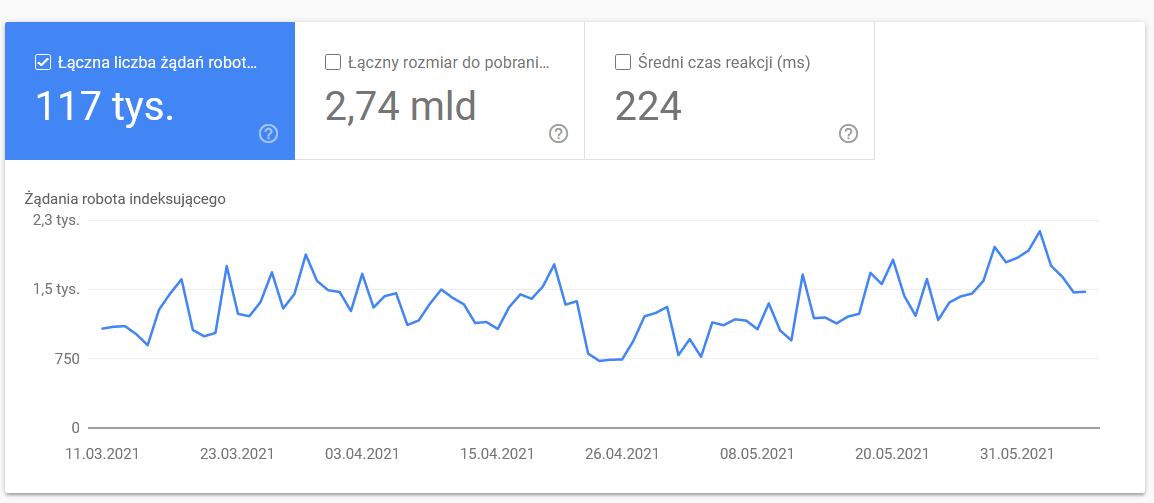
Wie ich bereits sagte, werden Sie es schwer haben, Benchmarks für die obigen Zahlen zu suchen. Es ist jedoch ein guter Aufruf, einen genaueren Blick darauf zu werfen:
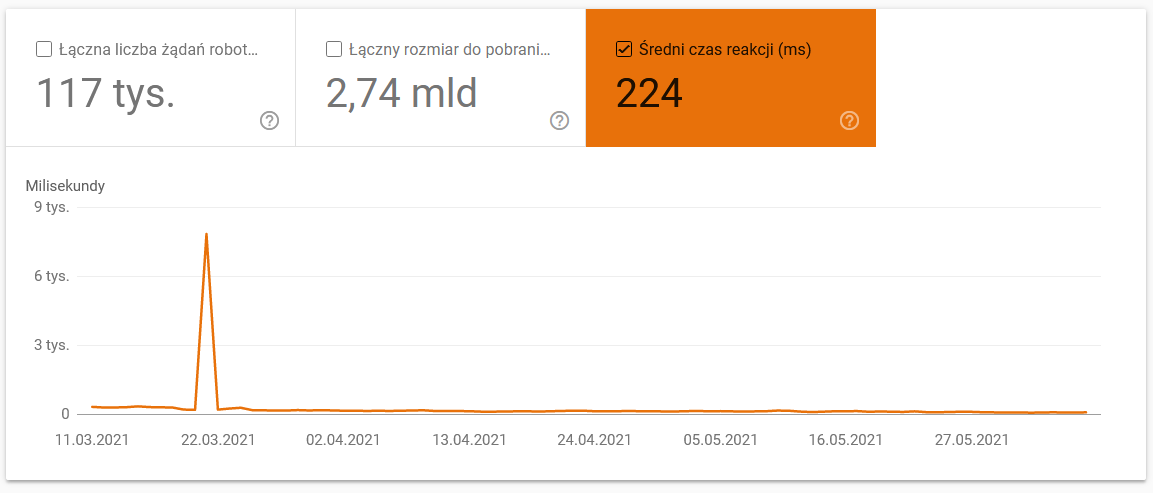
- Durchschnittliche Downloadzeit. Der folgende Screenshot zeigt, dass die durchschnittliche Antwortzeit einen dramatischen Einbruch erlitt, was auf serverbezogene Probleme zurückzuführen war:
- Crawl-Antworten. Sehen Sie sich den Bericht an, um im Allgemeinen zu sehen, ob Sie ein Problem mit Ihrer Website haben oder nicht. Achten Sie genau auf atypische Serverstatuscodes, wie die 304er unten. Diese URLs dienen keinem funktionalen Zweck, aber Google verschwendet seine Ressourcen beim Durchsuchen ihrer Inhalte.

- Crawl-Zweck. Im Allgemeinen hängen diese Daten stark von der Menge neuer Inhalte auf der Website ab. Die Unterschiede zwischen den von Google und dem Nutzer gesammelten Informationen können durchaus faszinierend sein:
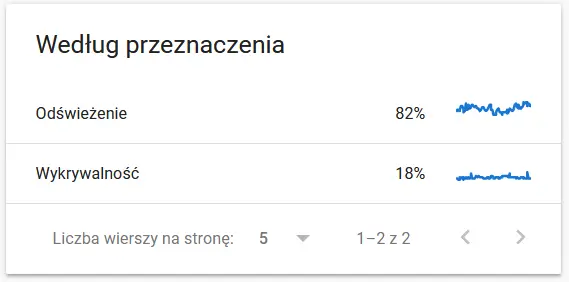
Inhalte einer erneut gecrawlten URL aus Sicht von Google:
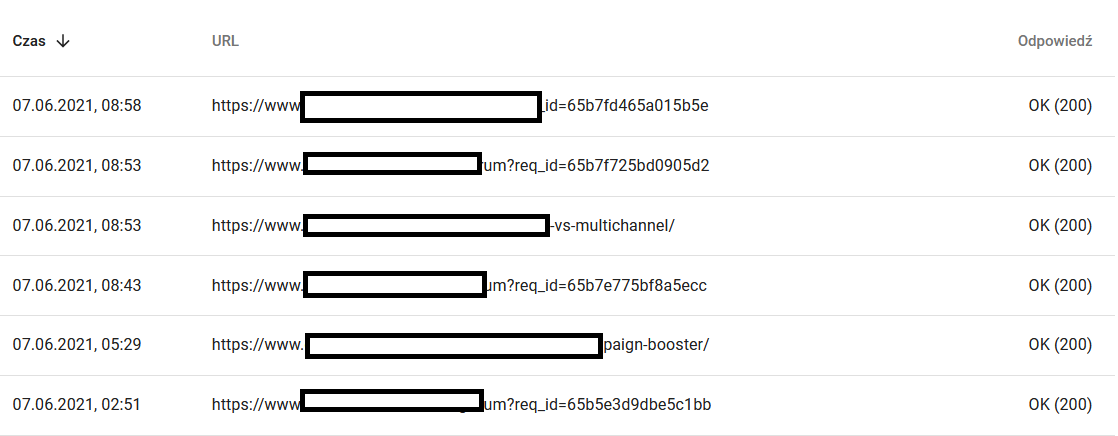
In der Zwischenzeit sieht der Benutzer Folgendes im Browser:
Definitiv ein Anlass zum Nachdenken und Analysieren :)
- Googlebot-Typ . Hier haben Sie die Bots, die Ihre Website besuchen, zusammen mit ihren Beweggründen für das Parsen Ihrer Inhalte auf einem Silbertablett. Der folgende Screenshot zeigt, dass sich 22 % der Anfragen auf die Auslastung der Seitenressourcen beziehen.
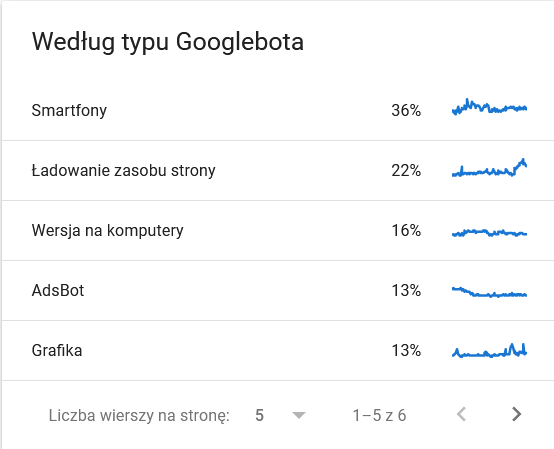
Die Gesamtsumme stieg in den letzten Tagen des Zeitrahmens an:
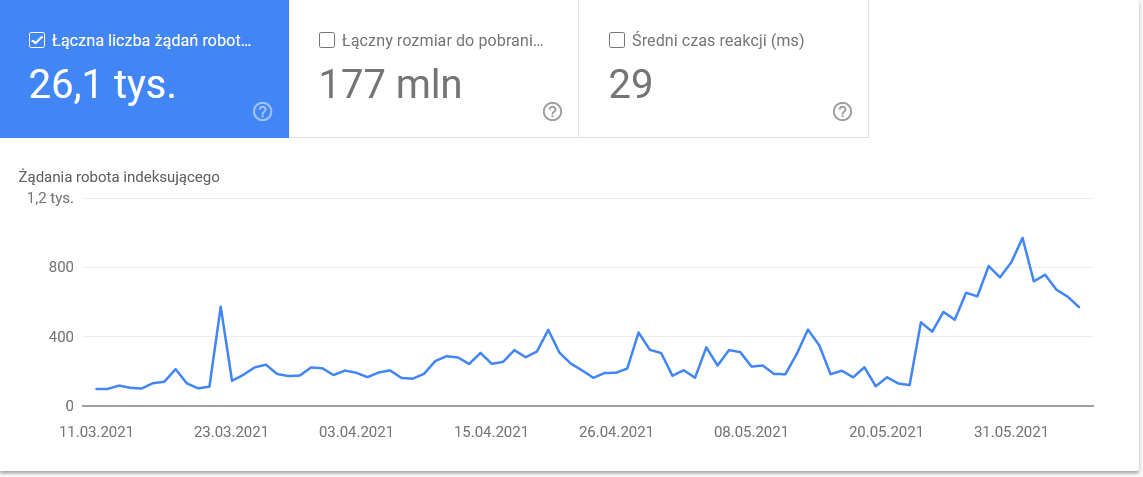
Ein Blick in die Details offenbart die URLs, die genauere Aufmerksamkeit erfordern:
Externe Crawler (mit Beispielen aus dem Screaming Frog SEO Spider)
Crawler gehören zu den wichtigsten Tools zur Analyse des Crawl-Budgets Ihrer Website. Ihr Hauptzweck besteht darin, die Bewegungen von Crawling-Bots auf der Website nachzuahmen. Die Simulation zeigt Ihnen auf einen Blick, ob alles rund läuft.
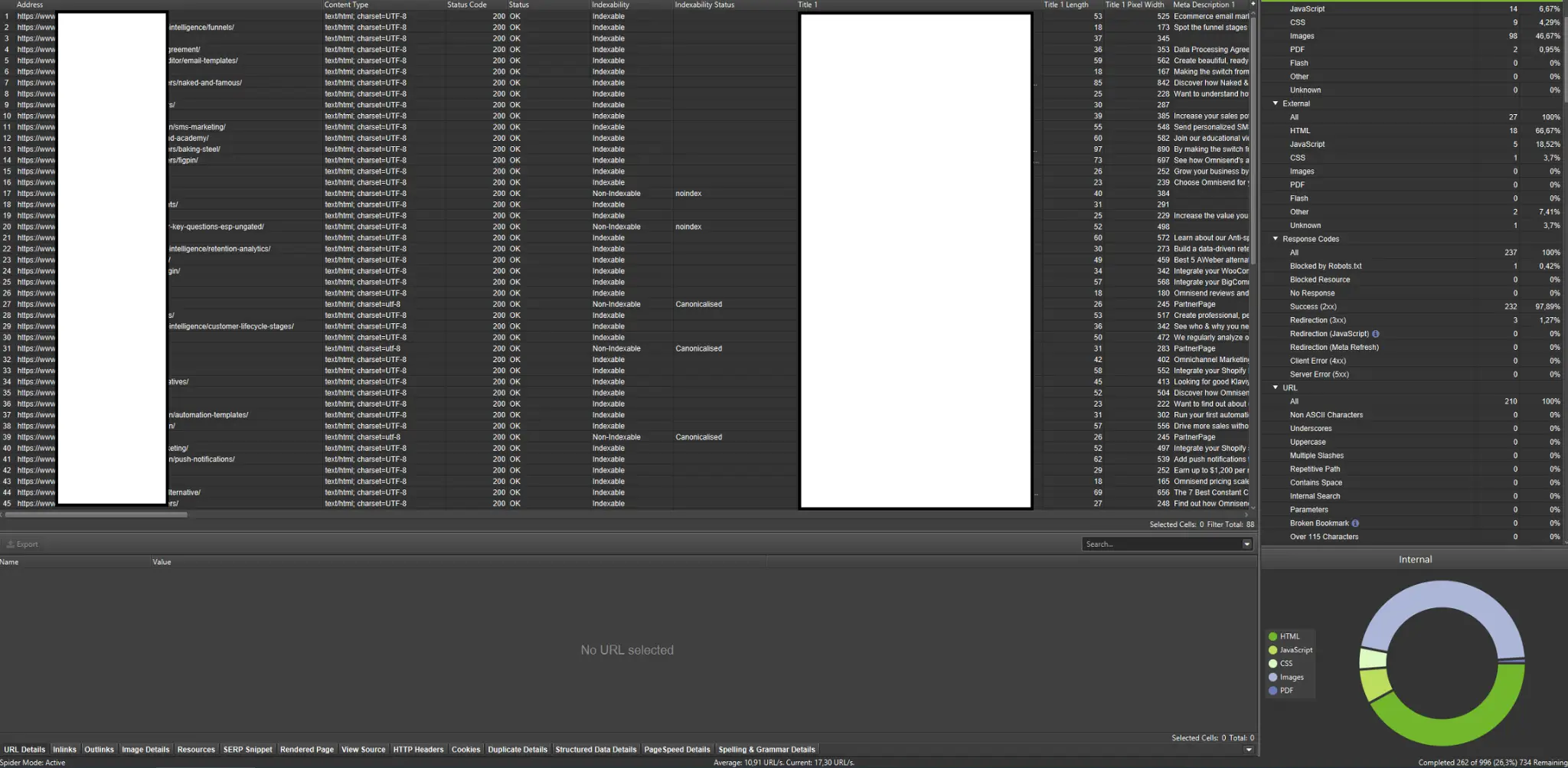
Wenn Sie ein visueller Lerner sind, sollten Sie wissen, dass die meisten auf dem Markt erhältlichen Lösungen Datenvisualisierungen anbieten.
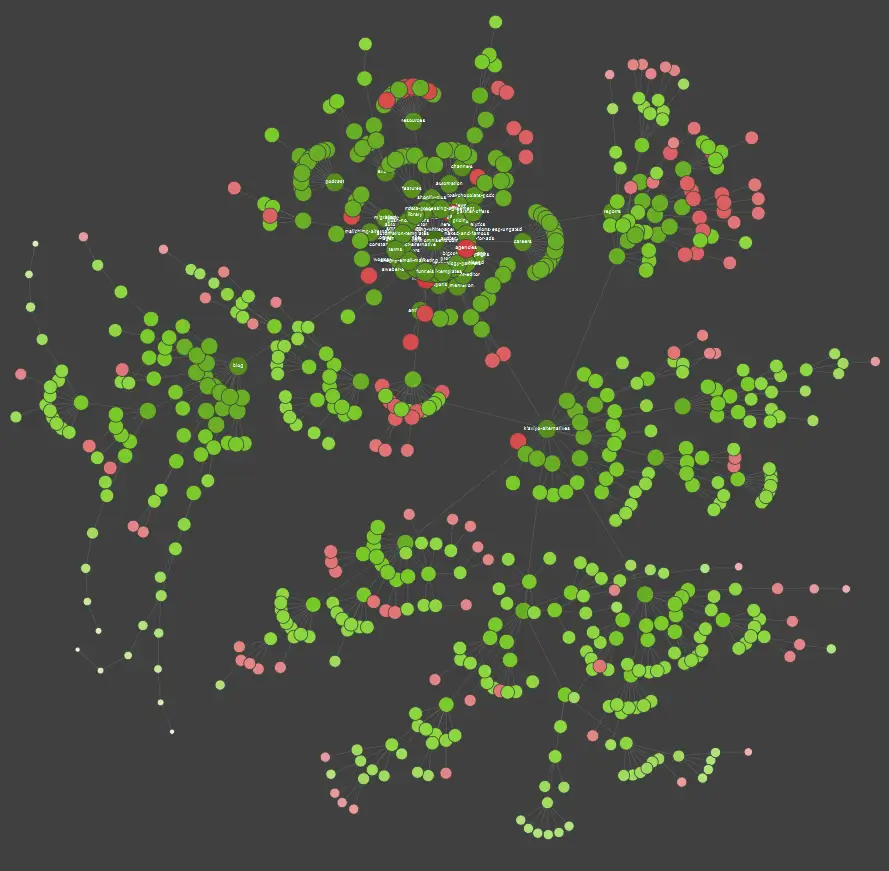
Im obigen Beispiel stehen die roten Punkte für nicht indizierte Seiten. Nehmen Sie sich eine Weile Zeit, um ihre Nützlichkeit und Auswirkungen auf den Betrieb der Website zu betrachten. Wenn Serverprotokolle zeigen, dass diese Seiten viel Zeit für Google verschwenden, ohne einen Mehrwert zu schaffen, ist es an der Zeit, den Punkt, sie auf der Website zu halten, ernsthaft zu überdenken.
Wichtig : Wenn wir das Verhalten eines Googlebots möglichst genau nachbilden wollen, sind die richtigen Einstellungen ein Muss. Hier sehen Sie Beispieleinstellungen von meinem Computer:
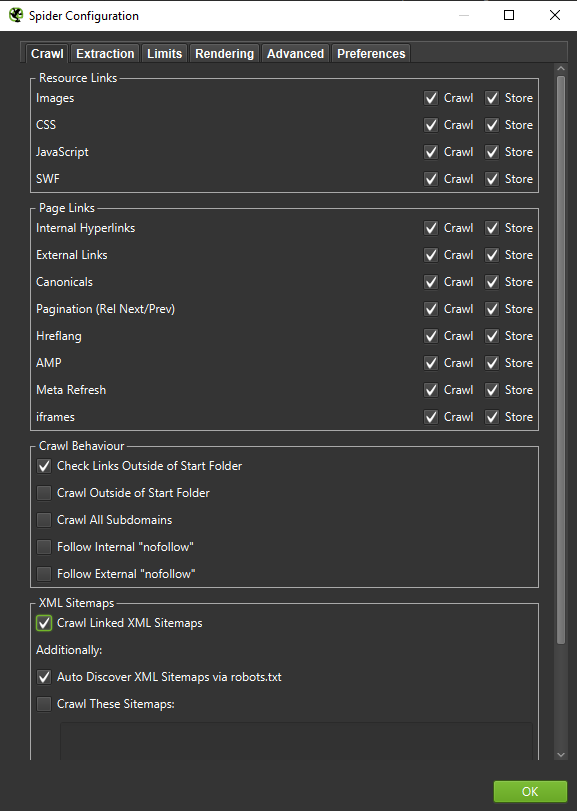
Bei einer eingehenden Analyse empfiehlt es sich, zwei Modi – Nur Text, aber auch JavaScript – zu testen, um die Unterschiede (falls vorhanden) zu vergleichen.

Schließlich schadet es nie, das oben vorgestellte Setup auf zwei verschiedenen Benutzeragenten zu testen:
In den meisten Fällen müssen Sie sich nur auf die vom mobilen Agenten gecrawlten/gerenderten Ergebnisse konzentrieren.
Wichtig: Ich schlage auch vor, die Möglichkeit von Screaming Frog zu nutzen und Ihren Crawler mit Daten aus GA und Google Search Console zu füttern. Die Integration ist eine schnelle Möglichkeit, Verschwendung von Crawling-Budget zu identifizieren, wie z. B. eine beträchtliche Menge potenziell redundanter URLs, die keinen Traffic erhalten.
Tools zur Protokollanalyse (Screaming Frog Logfile und andere)
Die Wahl eines Server-Log-Analyzers ist eine Frage der persönlichen Präferenz. Mein bevorzugtes Tool ist der Screaming Frog Log File Analyzer. Es ist vielleicht nicht die effizienteste Lösung (Laden eines riesigen Protokollpakets = Aufhängen der Anwendung), aber ich mag die Benutzeroberfläche. Der wichtige Teil besteht darin, das System anzuweisen, nur verifizierte Googlebots anzuzeigen.
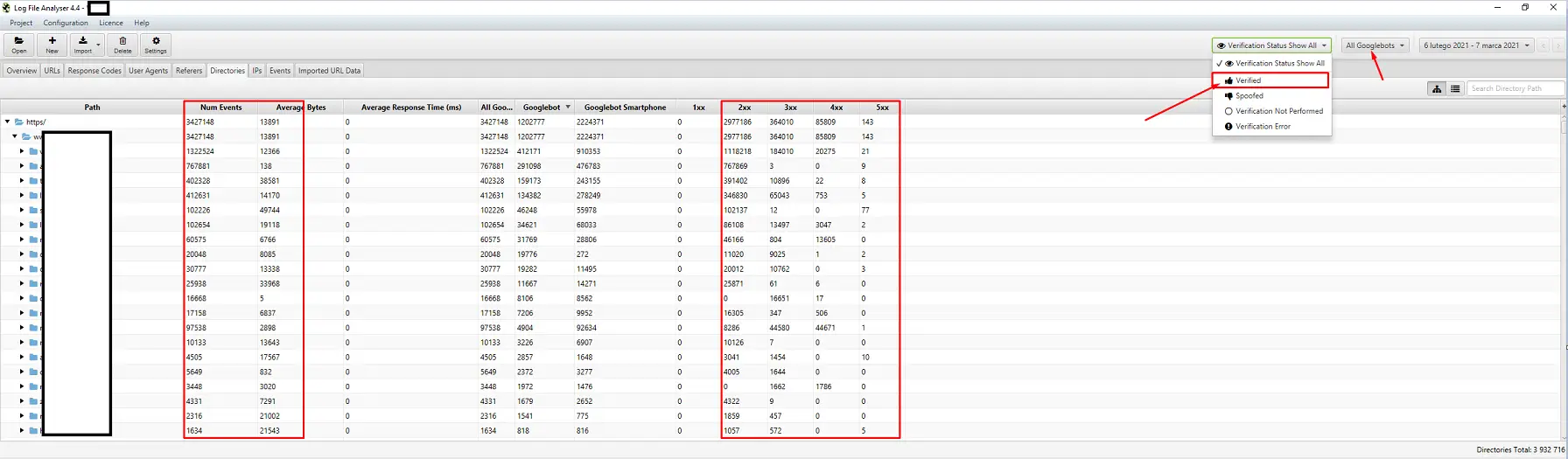
Tools zur Sichtbarkeitsverfolgung
Eine hilfreiche Hilfe, denn damit können Sie Ihre Top-Seiten identifizieren. Wenn eine Seite für viele Keywords in Google hoch rankt (= viel Traffic erhält), kann sie möglicherweise eine größere Crawl-Nachfrage haben (überprüfen Sie es in den Protokollen – generiert Google wirklich mehr Treffer für diese bestimmte Seite?).
Für unsere Zwecke benötigen wir allgemeine Berichte in Senuto – Pfade und URLs – zur weiteren Überprüfung in der Zukunft. Beide Berichte sind in der Sichtbarkeitsanalyse auf der Registerkarte Abschnitte verfügbar. Guck mal:
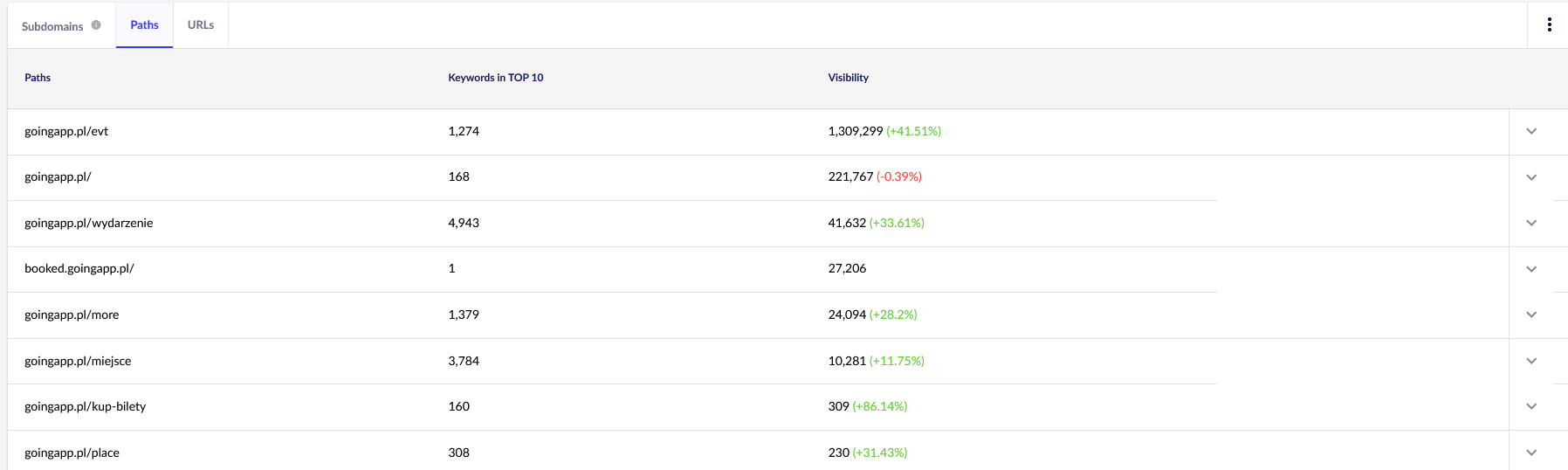
Unser Hauptinteresse gilt dem zweiten Bericht. Lassen Sie es uns sortieren, um unsere Keyword-Sichtbarkeit zu untersuchen (die Liste und die Gesamtzahl der Keywords, für die unsere Website in den TOP 10 rangiert). Die Ergebnisse werden uns dabei helfen, die Hauptachse für die Stimulierung (und effiziente Allokation) unseres Crawl-Budgets zu identifizieren.
Tools zur Backlink-Analyse (Ahrefs, Majestic)
Wenn eine Ihrer Seiten eine hohe Anzahl eingehender Links aufweist, verwenden Sie sie als Säule Ihrer Strategie zur Optimierung des Crawl-Budgets. Beliebte Seiten können die Rolle von Hubs übernehmen, die den Saft weiterleiten. Darüber hinaus hat eine beliebte Seite mit einem anständigen Pool wertvoller Links eine bessere Chance, häufig gecrawlt zu werden.
In Ahrefs brauchen wir den Seitenbericht, und um genau zu sein, seinen Teil mit dem Titel: „Best by Links“:
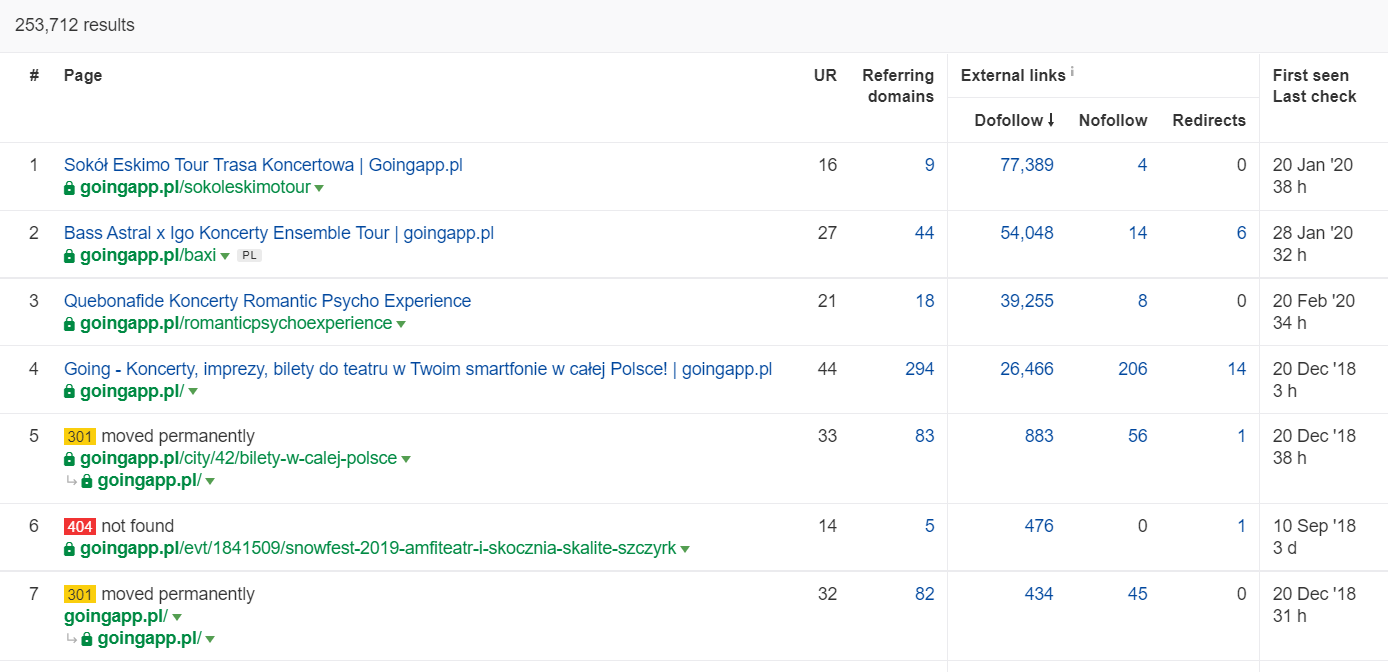
Das obige Beispiel zeigt, dass einige konzertbezogene LPs weiterhin solide Statistiken für Backlinks generierten. Selbst wenn alle Konzerte wegen der Pandemie abgesagt wurden, zahlt es sich immer noch aus, historisch starke Seiten zu verwenden, um die Neugier von Crawling Bots zu wecken und den Saft bis in die tieferen Ecken Ihrer Website zu verteilen.
Was sind die aussagekräftigen Anzeichen für ein Problem mit dem Crawl-Budget?
Die Erkenntnis, dass Sie es mit einem problematischen (zu niedrigen) Crawl-Budget zu tun haben, fällt Ihnen nicht leicht. Wieso den? Vor allem, weil SEO ein äußerst komplexes Unterfangen ist. Niedrige Ränge oder Indexierungsprobleme können ebenso die Folge eines mittelmäßigen Linkprofils oder fehlender passender Inhalte auf der Website sein.
In der Regel umfasst eine Crawl-Budget-Diagnose Folgendes:
- Wie viel Zeit vergeht von der Veröffentlichung bis zur Indexierung neuer Seiten (Blogbeiträge / Produkte), wenn Sie die Indexierung nicht über die Google Search Console anfordern?
- Wie lange behält Google ungültige URLs in seinem Index? Wichtig: Umgeleitete Adressen sind eine Ausnahme – Google speichert sie absichtlich.
- Haben Sie Seiten, die in den Index aufgenommen werden, um später wieder zu verschwinden?
- Wie viel Zeit verbringt Google mit Seiten, die keinen Wert (Traffic) generieren? Gehen Sie zur Protokollanalyse, um es herauszufinden.
Wie analysiert und optimiert man das Crawl-Budget?
Die Entscheidung, sich in die Crawl-Budget-Optimierung zu stürzen, wird hauptsächlich von der Größe Ihrer Website bestimmt. Google schlägt vor, dass sich Websites mit weniger als 1000 Seiten im Allgemeinen nicht damit quälen sollten, das Beste aus ihren verfügbaren Crawling-Limits zu machen. Meiner Meinung nach sollten Sie anfangen, für ein effizienteres und effektiveres Crawling zu kämpfen, wenn Ihre Website mehr als 300 Seiten umfasst und sich Ihre Inhalte dynamisch ändern (z. B. wenn Sie ständig neue Seiten / Blogbeiträge hinzufügen).
Wieso den? Es ist eine Frage der SEO-Hygiene. Implementieren Sie in den ersten Tagen gute Optimierungsgewohnheiten und eine solide Verwaltung des Crawl-Budgets, und Sie müssen in Zukunft weniger korrigieren und neu gestalten.
Optimierung des Crawl-Budgets. Ein Standardverfahren
Im Allgemeinen besteht die Arbeit an der Craw-Budget-Analyse und -Optimierung aus drei Phasen:
- Datenerfassung, d. h. der Prozess, alles zusammenzustellen, was wir über die Website wissen – sowohl von Webmastern als auch von externen Tools.
- Sichtbarkeitsanalyse und Identifizierung von Low Hanging Fruits. Was läuft wie am Schnürchen? Was wäre besser? Welche Bereiche haben das höchste Wachstumspotenzial?
- Empfehlungen für das Crawl-Budget.
Datenerfassung für ein Crawl-Budget-Audit
1. Ein vollständiger Website-Crawl, der mit einem der im Handel erhältlichen Tools durchgeführt wird. Das Ziel besteht darin, mindestens zwei Crawls durchzuführen: Der erste simuliert den Googlebot, während der andere die Website als Standard-User-Agent abruft (der User-Agent eines Browsers reicht aus). In diesem Stadium sind Sie nur daran interessiert, 100 % des Inhalts herunterzuladen . Wenn Sie bemerken, dass der Crawler in eine Schleife geraten ist (wenn wir nach einem Tag des Crawlens immer noch nur 10 % der Website auf unserer Festplatte haben) – lassen Sie es wissen, dass es ein Problem gibt, und Sie können den Crawl stoppen. Eine angemessene Anzahl von URLs für die Analyse liegt bei großen Websites bei etwa 250.000 bis 300.000 Seiten.
a) Was wir suchen, sind hauptsächlich interne 301-Weiterleitungen, 404-Fehler, aber auch die Situationen, in denen Ihre Texte als Thin Content eingestuft werden können. Screaming Frog hat die Möglichkeit, Near Duplicate Content zu erkennen:
2. Serverprotokolle . Der ideale Zeitraum sollte den letzten Monat umfassen, bei großen Websites können jedoch auch zwei letzte Wochen ausreichen. Im besten Fall sollten wir Zugriff auf historische Serverprotokolle haben, um die Bewegungen des Googlebots zu dem Zeitpunkt zu vergleichen, als alles rund lief.
3. Datenexporte aus der Google Search Console . In Kombination mit den obigen Punkten 1 und 2 sollten Ihnen die Daten der Indexabdeckung und der Crawl-Statistiken einen ziemlich umfassenden Überblick über alle Ereignisse auf Ihrer Website geben.
4. Organische Verkehrsdaten . Top-Seiten, ermittelt von Google Search Console, Google Analytics sowie Senuto und Ahrefs. Wir möchten alle Seiten identifizieren, die sich durch ihre hohen Sichtbarkeitsstatistiken, das Verkehrsaufkommen oder die Anzahl der Backlinks von der Masse abheben. Diese Seiten sollten das Rückgrat Ihrer Arbeit am Crawl-Budget werden . Wir werden sie verwenden, um das Crawlen der wichtigsten Seiten zu verbessern.
5. Manuelle Indexüberprüfung . In manchen Fällen ist der beste Freund eines SEO-Experten eine einfache Lösung. In diesem Fall: eine Überprüfung der Daten direkt aus dem Index! Es ist ein guter Aufruf, Ihre Website mit der Kombination aus inurl: + site: -Operatoren zu überprüfen.Schließlich müssen wir alle gesammelten Daten zusammenführen. Normalerweise verwenden wir einen externen Crawler mit Funktionen, die externe Datenimporte (GSC-Daten, Serverprotokolle und organische Verkehrsdaten) ermöglichen.
Sichtbarkeitsanalyse und niedrig hängende Früchte
Der Prozess rechtfertigt einen separaten Artikel, aber unser heutiges Ziel ist es, unsere Ziele für die Website und die erzielten Fortschritte aus der Vogelperspektive zu betrachten. Uns interessiert alles Außergewöhnliche: plötzliche Traffic-Einbrüche (die nicht durch saisonale Trends erklärt werden können) und die gleichzeitigen Verschiebungen in der organischen Sichtbarkeit. Wir prüfen, welche Gruppen von Seiten am stärksten sind, weil sie unsere HUBS werden, um den Googlebot tiefer in unsere Website zu drängen.
Im Idealfall sollte ein solcher Check die gesamte Geschichte unserer Website seit ihrem Start abdecken. Da das Datenvolumen jedoch jeden Monat weiter zunimmt, konzentrieren wir uns auf die Analyse der Sichtbarkeit und des organischen Traffics der letzten 12 Monate.
Crawl-Budget – unsere Empfehlungen
Die oben aufgeführten Aktivitäten unterscheiden sich je nach Größe der optimierten Website. Sie sind jedoch die wichtigsten Elemente, die ich immer berücksichtige, wenn ich eine Crawl-Budget-Analyse durchführe. Das übergeordnete Ziel ist es, die Engpässe auf Ihrer Website zu beseitigen. Mit anderen Worten, um eine maximale Crawlbarkeit für Googlebots (oder andere Indizierungsagenten) zu gewährleisten.
1. Beginnen wir mit den Grundlagen – der Beseitigung aller Arten von 404/410-Fehlern, der Analyse interner Weiterleitungen und deren Entfernung aus der internen Verlinkung . Wir sollten unsere Arbeit mit einem letzten Crawl beenden. Dieses Mal sollten alle Links einen 200-Antwortcode zurückgeben, ohne interne Weiterleitungen oder 404-Fehler.
- In diesem Stadium ist es eine gute Idee, alle im Backlink-Bericht erkannten Weiterleitungsketten zu korrigieren.
2. Stellen Sie nach dem Crawl sicher, dass unsere Website-Struktur frei von eklatanten Duplikaten ist .
- Achten Sie auch auf potenzielle Kannibalisierung – abgesehen von den Problemen, die sich aus der Ausrichtung auf dasselbe Keyword auf mehreren Seiten ergeben (kurz gesagt, Sie kontrollieren nicht mehr, welche Seite von Google angezeigt wird), wirkt sich Kannibalisierung negativ auf Ihr gesamtes Crawl-Budget aus.
- Konsolidieren Sie die identifizierten Duplikate in einer einzigen URL (normalerweise diejenige mit dem höheren Rang).
3. Überprüfen Sie, wie viele URLs das noindex-Tag haben . Wie wir wissen, kann Google immer noch über diese Seiten navigieren. Sie werden einfach nicht in den Suchergebnissen angezeigt. Wir versuchen, den Anteil von noindex- Tags in unserer Website-Struktur zu minimieren.
- Ein typisches Beispiel – ein Blog organisiert seine Struktur mit Tags; Die Autoren behaupten, dass die Lösung von der Benutzerfreundlichkeit bestimmt wird. Jeder Beitrag ist mit 3–5 Tags gekennzeichnet, uneinheitlich vergeben und nicht indexiert. Die Protokollanalyse zeigt, dass dies die am dritthäufigsten gecrawlte Struktur auf der Website ist.
4. Überprüfen Sie die robots.txt-Datei . Denken Sie daran, dass die Implementierung von robots.txt nicht bedeutet, dass Google die Adresse nicht im Index anzeigt.
- Überprüfen Sie, welche der blockierten Adressstrukturen noch gecrawlt werden. Vielleicht verursacht das Abschneiden einen Engpass?
- Entfernen Sie die veralteten/unnötigen Anweisungen.
5. Analysieren Sie das Volumen nicht-kanonischer URLs auf Ihrer Website. Google hat aufgehört, rel="canonical" als harte Anweisung zu betrachten. In vielen Fällen wird das Attribut von der Suchmaschine regelrecht ignoriert (Sortierparameter im Index – immer noch ein Alptraum).
6. Analysieren Sie Filter und ihre zugrunde liegenden Mechanismen . Das Filtern der Einträge ist das größte Problem bei der Optimierung des Crawl-Budgets. E-Commerce-Geschäftsinhaber bestehen darauf, Filter zu implementieren, die in beliebiger Kombination anwendbar sind (z. B. Filtern nach Farbe + Material + Größe + Verfügbarkeit … zum x-ten Mal). Die Lösung ist nicht optimal und sollte auf das Minimum beschränkt werden.
7. Informationsarchitektur auf der Website – eine, die Geschäftsziele, Traffic-Potenzial und aktuelles Linkprofil berücksichtigt. Gehen wir davon aus, dass ein Link zu den für unsere Geschäftsziele kritischen Inhalten auf der gesamten Website (auf allen Seiten) oder auf der Startseite sichtbar sein sollte. Wir vereinfachen hier natürlich, aber die Startseite und die Links im oberen Menü bzw. auf der gesamten Website sind die stärksten Indikatoren für die Wertsteigerung durch interne Verlinkung. Gleichzeitig versuchen wir, die optimale Domain-Spreizung zu erreichen: Unser Ziel ist die Situation, dass wir den Crawl von jeder Seite starten können und trotzdem die gleiche Anzahl von Seiten erreichen (jede URL sollte MINDESTENS einen eingehenden Link haben). .
- Die Arbeit an einer robusten Informationsarchitektur ist eines der Schlüsselelemente der Crawl-Budget-Optimierung. Es ermöglicht uns, einige der Ressourcen des Bots von einem Ort freizugeben und sie an einen anderen umzuleiten. Es ist auch eine der größten Herausforderungen, denn es erfordert die Zusammenarbeit von Geschäftsinteressenten – was oft zu großen Kämpfen und Kritik führt, die die SEO-Empfehlungen untergraben.
8. Rendern von Inhalten. Kritisch bei Websites, die darauf abzielen, ihre interne Verlinkung auf Empfehlungssysteme zu stützen, die das Nutzerverhalten erfassen. Vor allem verlassen sich die meisten dieser Tools auf Cookie-Dateien. Google speichert keine Cookies und erhält daher keine benutzerdefinierten Ergebnisse. Die Folge: Google sieht immer den gleichen Inhalt oder gar keinen Inhalt.
- Es ist ein häufiger Fehler, den Googlebot am Zugriff auf wichtige JS/CSS-Inhalte zu hindern. Dieser Schritt kann zu Problemen mit der Seitenindizierung führen (und Googles Zeit mit dem Rendern nicht verfügbarer Inhalte verschwenden).
9. Website-Performance – Core Web Vitals . Obwohl ich den Einfluss von CWV auf die Rankings von Websites skeptisch betrachte (aus vielen Gründen, einschließlich der Vielfalt der im Handel erhältlichen Geräte und der unterschiedlichen Geschwindigkeiten der Internetverbindung), ist es einer der Parameter, die es wert sind, mit einem Programmierer diskutiert zu werden.
10. Sitemap.xml – prüfen Sie, ob sie funktioniert und alle Schlüsselelemente enthält (nichts als kanonische URLs, die einen 200-Statuscode zurückgeben).
- Meine erste Empfehlung zur Optimierung der sitemap.xml ist, Ihre Seiten nach Typ oder – wenn möglich – Kategorie zu unterteilen. Die Abteilung gibt Ihnen die volle Kontrolle über die Bewegungen von Google und die Indexierung des Inhalts.