
ディープ ラーニングの現状: 開発者と VC の観点から
公開: 2017-09-05Nikhil Kapur が、最初は学生開発者として、現在は VC として、深層学習の現状について語ります
ある土曜日、Unilever Foundry と Padang.co の巨大なレベル 3 オフィスで、深層学習と TensorFlow のワークショップに参加しました。 再び開発の世界にどっぷり浸かる楽しい一日でした。テーブルメイトとの会話はすべて楽しかったです。そのうちの 1 人は家業を営んでおり、趣味で ML/ディープ ラーニングを学んでおり (彼はプログラミング愛好家です)、もう 1 人は地元出身でした。 Zalora のマーケティング部門は、仕事に AI を適用しようとしています。
まず、マシンに TensorFlow と Keras (TensorFlow の抽象化) を設定することから始め、その後、MNIST データセットの使用など、いくつかの一般的な深層学習の問題と例をいじくり回し始めました。 テキスト認識用のシンプルで小さな NLP モデルから始めて、畳み込みニューラル ネットワークに飛び込みました。
Inception V3 などの市販の事前トレーニング済みモデルを使用していましたが、独自のデータセットをいじってモデルを再トレーニングし、「これは猫ですか、それとも犬ですか?」などのさまざまな問題を解決していました。 このクラスの目標は、深層学習の基礎を理解し、パラメーターと機能を試すことでした。 今までに嫉妬を感じているなら、playground.tensorflow.org で遊んでみることをお勧めします。これは、ワークショップの中で最も簡単に手に入れることができる部分でした!
これを企画してくれた Sam Witteveen と Martin Andrews に心から感謝します。 ここで、私が思いついたいくつかの視点と、特に VC の視点から、ディープ ラーニングと AI が一般的な方向性を示している場所について詳しく説明します。
開発者の視点からの深層学習
少し背景を説明すると、私はかなりの量の「AI」に触れてきました。 大学 2 年生のとき、デロイトのテクノロジー コンサルティング部門でインターンをしました。 友人の Ujjwal Dasgupta と一緒に、後に ML の修士号を取得し、現在は Google に勤務しており、データ ウェアハウジング ソフトウェアである IBM Datastage で改良された ETL (Extract-Transform-Load) プロセスを開発するのに数か月を費やしました。 当時、私よりずっと前向きだった Ujjwal がデータ マイニングを紹介してくれたので、Andrew Ng の講義やオンライン コースを受講するようになりました。
来年の夏、このテーマにすでに費やした時間に興味をそそられ、ML をさらに深く掘り下げたいと思いました。 幸運にも、機械学習ベースのコンパイラーである Milespot GCC を使用して Firefox のパフォーマンスを改善する Mozilla のプロジェクトに配属されました。 この ML コンパイラを使用して、Mozilla Firefox のコードをコンパイルし、プログラムの読み込み時間を約 10% 改善することができました。
そして、私の最終論文では、ML を手放すことはできませんでした。 ドイツの人工知能研究所である DFKI と協力して、アイ トラッキング用のシンプルなウェブカメラを使用して、非常に挑戦的なプロジェクトに取り組みました。 DFKI のチームは、これを特定のアプリケーション Text 2.0 に使用していました。 彼らは特別な HD カメラを使用してあなたの目を追跡し、それに応じて自動スクロール、自動翻訳、ポップアップ辞書などの超クールな機能でテキストを補強していました。
インドの誰もその特別な HD カメラを購入するお金を持っていなかったので、シンプルな Web カメラで同じことをすることにしました。 正確に言えば、追跡で約 70% の精度しか達成できず、失敗しました。 しかし、これは私が携わった中で最もエキサイティングなプロジェクトの 1 つでした。
あなたにおすすめ:

メタバースがインドの自動車産業をどのように変革するか

反営利条項はインドのスタートアップ企業にとって何を意味するのか?

Edtech スタートアップがインドの労働力のスキルアップと将来への準備をどのように支援しているか...

今週の新時代のテック株:Zomatoのトラブルは続き、EaseMyTripはスト...

インドの新興企業は資金調達を求めて近道をする

デジタル マーケティング プラットフォームの Logicserve が 80 億ルピーの資金を調達し、LS Dig...
では、なぜ私はこれの詳細であなたを退屈させているのですか? ほとんどの場合、私がエンジニアリングをすりつぶしていたときの AI の歴史を少し紹介します。 ディープ ラーニングと ML は数十年前にすでに存在していましたが、この分野が本格化したのはここ 10 年のことです。 ここ数年で具体的に何が変わったのですか?

たとえば、ムーアの法則により、ストレージと処理のコストが最小になり、自宅で ML を実装できるようになりました。 ほとんどすべての基本モデルを自分のマシンで実行できるようになりました。優れた GPU (もはやそれほど高価ではありません) を購入すると、計算時間をほぼ 10 倍最適化して複雑なモデルを実行できるようになります。
Wired マガジンには、この変更に関するすばらしい記事があります。
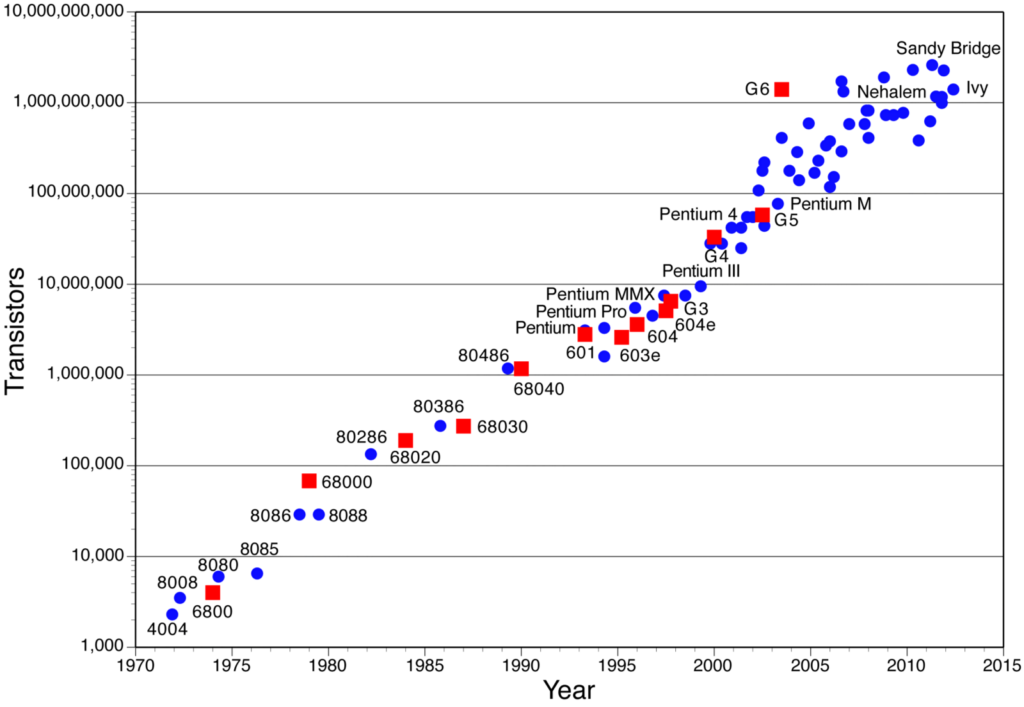
年間のチップ内トランジスタ数 (Y 軸は対数スケールであることに注意してください!)。 出典: Assured-Systems
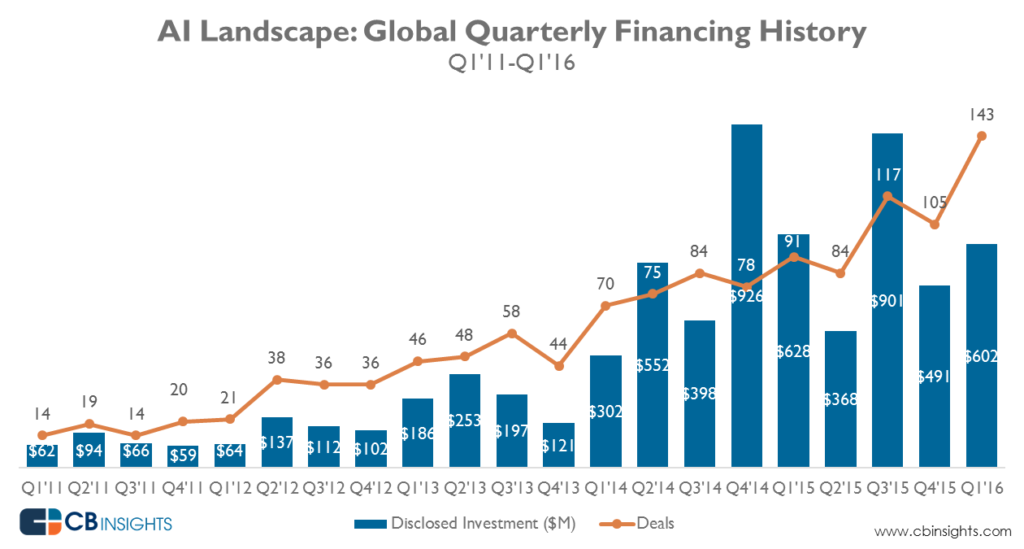
もう 1 つの変化は、企業が自動化の必要性を認識したことです。 この結果、この分野での M&A 活動が大幅に増加する一方で、VC は過去 5 年間、この分野に資金を注ぎ込んできました。
深層学習に対する投資家の見通し
では、私たちは現在どのような立場にあり、投資家や新興企業はこの極端な AI の話題をどのように見るべきなのでしょうか? 私が見ているように、AI スタートアップには 4 つの重要な側面があり、それらすべてを組み合わせて強力な企業を形成する必要があります。
- 才能:すべてはここから始まります。 スタートアップではチームが最も重要な側面であることは明らかですが、AI スタートアップではそれが会社の真のエンジンです。 事前に構築されたモデルを微調整するための強力なデータ サイエンスおよびコンピューター エンジニアリングの才能へのアクセスは、AI スタートアップにとって重要であり、これが米国と中国のスタートアップが他の地域でリードする可能性が高い理由です。 シンガポールにはデータ サイエンスの才能がわずかにあり、AI 企業を立ち上げるのに適した場所になる可能性があります。 とはいえ、最高の人材は、有機的または無機的にテクノロジーの巨人に行く可能性が高い. Google による DeepMind の買収は、まさにこれであり、ディープ ラーニングの最高の頭脳を獲得するための戦略でした。
- データ:チームがエンジンである場合、データは AI スタートアップのガソリンです。 大量のクリーンで構造化されたデータがなければ、トレーニング済みのシステムから正確性を引き出すことができず、ビジネス アプリケーションの妨げになります。 モデルの予測機能は、供給されるデータに大きく依存しているため、大規模な企業は、より優れた、より正確なシステムを考案する上で、小規模な新興企業よりも大きな利点を持つ可能性があります。 これは厄介な考えであり、型を破る唯一の方法は、独自の独自データを生成して活用することです。 この点では、Salesforce などの記録システムが非常に重要になります。
- モデル:すべての大手テクノロジー企業は現在、独自の AI システム (開発プラットフォーム、ライブラリ、トレーニング済みモデル) を立ち上げ、明日の AI 開発のためのプラットフォームを作成しています。 どちらが戦争に勝つかはまだ決まっていませんが、ゼロからモデルを作成する必要は遅かれ早かれなくなります。 本当に複雑なシステムの場合にのみ、基本からモデルの構築を開始する必要がありますが、ほとんどの場合、データ サイエンティストは既製のモデルを再利用し、独自のデータを使用して再トレーニングすることができます。 しかし、可能な限り最高のモデルに到達したことをどのように確認できますか? Union Square Ventures の支援を受けている Numerai は、機械学習の専門家にクラウドソーシングを行い、より良いモデルを構築するよう金銭的に奨励することで、この問題に非常に賢明な方法で取り組んでいます。
- ビジネス上の問題:ここからが興味深いところです。 まず、ユーザーはシステムが自動化されているかどうかを気にしません。 AI システムは、ユーザーを驚かせるためではなく、組織を最適化し、マシンに人間のタスクを実行させることを目的としています。 したがって、特定のビジネス上の問題を解決することは、優れたユーザー エクスペリエンスを提供し、それによって定着率を高めるための鍵となります。
第二に、ほとんどのハイテク大手は、広範で汎用的なプラットフォームの構築に限定しようとしています。 Salesforce や Hubspot などのテクノロジー企業が AI に飛びついていますが、それらの企業は買収ルートになる可能性があります。 Salesforce はすでに Einstein を発表しており (ただし、その宣言を適切にフォローしていません)、Hubspot はブログで AI について毎週書いています。 彼らがその分野にどれだけ興味を持っているかを示しているだけでなく、特定の問題をターゲットにすることがいかに難しいかを示しています。 これは、スタートアップが利用できるギャップが存在する場所であり、私たちのポートフォリオ企業であるSaleswhaleはまさにこのルートを追求しています.
私の目には、スタートアップが、そのシステムが途中で収集する独自のデータを使用して、十分な数の人々に影響を与える非常に的を絞った問題を自動化によって解決する場合、参入障壁の高い非常に収益性の高いビジネスになる可能性があります。 しかし、私が見る限り、これはこの地域でユニコーンサイズの機会になる可能性は低く、テクノロジーの巨人がまだ生きている間ではありません.
[Nikhil Kapur によるこの投稿は、Medium に最初に掲載され、許可を得て複製されました。]