
未来を形作る 5 つの認知技術
公開: 2019-12-04コグニティブ テクノロジーは、AI ベースの高度なドライバー支援システムです。 Hackett Group が提案した調査によると、調達リーダーの 85% が、今後 3 ~ 5 年間で運用プログラムを進化させる認知技術の研究に取り組んでいます。 テクノロジーを実装するための戦略を持っているのは全体の 32% だけであり、そのうちの 25% はテクノロジーを実行するのに十分な資本と機知を持っています。 私はあなたの未来を形作ることができる最も潜在的な認知技術を提案しています.
AIが私たちの日常生活の進歩の基盤になるにつれて。 IT 組織は、市場での地位を維持するために、この新たに出現したテクノロジを採用する必要があります。 サービス管理では、全体的なシステムをエスカレートするために、コグニティブ テクノロジを統合することが重要です。 このアプローチは、ユーザーとサービス管理の両方の未来を形作る上で、大きな潜在的利益をもたらします。 コグニティブ テクノロジを統合することで、パーソナライズされた高度な会話型のエクスペリエンスをユーザーに提供し、結果の向上と迅速化を実現できます。 スマートフォン ユーザーが日常のさまざまなタスクを支援するためにアシスタントに命令するのと同じように、人間の介入なしにさまざまなアクティビティを支援するようにチャットボットに依頼するサービス デスクで正確な経験を得ることができます。 これにより、高い顧客満足度を得ることができます。
ビッグデータ分析

ビッグデータ分析は、高度なテクノロジーと計算機能を利用して、膨大な量のデータを管理し、パターン、傾向、および実用的な洞察を引き出すプロセスです。 これは、予測モデルと統計アルゴリズムを備えた複雑なアプリケーションを含む高度な分析の一種であり、これらのタスクは高性能分析システムによって実行されます。 この専門的な分析システムとソフトウェアは、より良い収益機会、リマーキング マーケティング ベース、高度な顧客サービス、運用効率、競争力の向上など、多くのメリットを提供します。 ビッグデータ分析アプリケーションに基づくアプリケーションは、データ アナリスト、予測モデラー、統計学者、この分野の他の専門家に、従来の BI および分析プログラムでは実践されていない構造化されたトランザクション データやその他の形式のデータの増加を分析する余地を与えます。 これは、構造化データと非構造化データの融合を取り囲んでいます。 センサー接続により、これらのデータが収集され、IoT (Internet of Things) に接続されます。 多くのツールとテクノロジーが使用されています。
- NoSQL データベース
- Hadoop
- 糸
- MapReduce
- スパーク
- Hbase
- ハイブ
- 豚
ビッグ データ分析アプリには、内部システムからのデータと、サード パーティの情報サービス プロバイダーによってコンパイルされた消費者の気象データなどの外部ソースからのデータが含まれます。 ストリーミング分析アプリケーションは、ビッグデータ環境で一般的になり、Spark、Flink、Storm などのストリーム処理エンジンを介して Hadoop システムに供給されたデータをリアルタイムで分析します。 複雑な分析システムがこのテクノロジーと統合され、大量のデータを管理および分析します。 ビッグ データは、サプライ チェーンの分析において非常に有益になっています。 2011 年までに、ビッグデータ分析は、組織や世間の注目の中で確固たる地位を築き始めました。 ビッグ データ Hadoop およびその他の関連するビッグ データ テクノロジは、それに関連して出現し始めました。 主に、Hadoop エコシステムが形成され始め、時間とともに成熟していきました。 ビッグデータは、主に大規模なインターネット システムおよび電子商取引企業のプラットフォームでした。 現在、小売業者、金融サービス会社、保険会社、医療機関、製造業、およびその他の潜在的な企業に採用されています。 場合によっては、データのランディング パッドおよびステージング領域として、Hadoop クラスターと NoSQL システムが予備レベルで使用されます。 アクション全体は、分析データベースにロードされて一般的に構成された形式で分析される前に実行されます。 データの準備ができたら、高度な分析プロセスに使用されるソフトウェアで分析できます。 データ マイニング、予測分析、機械学習、ディープ ラーニングは、アクション全体を完了するための典型的なツールです。 この範囲では、テキスト マイニングおよび統計分析ソフトウェアがビッグ データ分析プロセスで極めて重要な役割を果たしていることに言及することは非常に重要です。 ETL アプリケーションと分析アプリケーションの両方で、クエリは R、Python、Scala、SQL などのさまざまなプログラミング言語を使用して MapReduce でスクリプト化されています。
機械学習:

機械学習は、機械が人間のようにタスクを実行できるように開発される高度な継続的なプロセスです。 これらのマシンは、ハイテク データを使用して開発され、人間の介入なしでタスクを実行します。 機械学習は AI のアプリケーションであり、機械に直接的かつ明示的なアクションなしでプログラムを学習および改善する能力を与えます。 基本的に、データにアクセスし、それを利用して自分で学習できるコンピュータープログラムの開発に焦点を当てています。 その主な目標は、機械が人間の支援なしに自動的に学習できるようにすることです。 機械学習は計算統計学と密接に関連しており、機械学習のタスクである数学的最適化の研究が行われています。 機械学習のタスクは、いくつかの大きなカテゴリに分類できます。
- 教師あり学習。
- 半教師あり学習。
- 教師なし機械学習。
- 強化機械学習。
これらすべての分類された機械学習カテゴリは、データと情報の分析においてさまざまな色合いのタスクを提供し、重要な決定を下します。
- 学習アルゴリズムは、出力値に関する予測を行うための推定関数を作成します。 学習アルゴリズムは、その出力を計算された出力と比較し、要件に従ってモデルを修正するためのエラーを見つけることができます。
- 教師なし機械学習アルゴリズムは、適切な出力を修正することはできませんが、データを探索し、データセットから推論を引き出して、ラベルのないデータから隠された構造を説明します。
- 半教師付き機械学習アルゴリズムは、ラベル付きデータとラベルなしデータの両方に使用されます。
- 強化機械学習アルゴリズムは環境と相互作用してアクションを生成し、報酬とエラーを発見します。 試行錯誤のプロセスがたまたまこの学習の最大の特徴です。 このプロセスを可能にするためには、一般的に強化信号と呼ばれるどの行動が最適かを学習するために、単純な報酬フィードバックが不可欠です。
ビッグデータ分析と同様に、機械学習も大量のデータの分析を可能にします。 有益な機会を特定したり、リスク管理システムを管理したりするために、迅速かつ最も正確な結果をもたらす傾向があります。 ただし、プログラム全体を適切に実行するには、余分な時間とリソースが必要になる場合もあります。 膨大な量のデータと情報を管理および監視するための非常に効果的なプロセスです。

自然言語処理 (NLP)
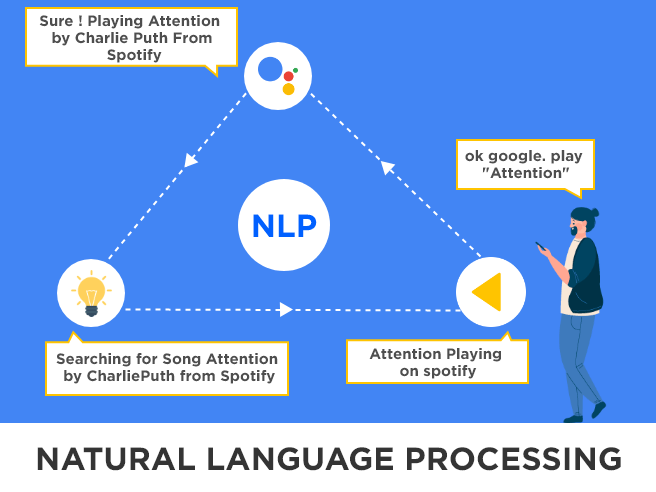
自然言語処理とは、人間の知性を備えた機械を訓練して、言語と応答を変化させ、より人間らしくすることです。 それは実際に私たちがお互いにどのようにコミュニケーションするかを指します。 NLP は、ソフトウェアを使用した自然言語の自動操作と定義されています。 自然言語処理の研究は 50 年以上前に開始されました。 他の種類のデータとは異なります。 それにもかかわらず、何年にもわたって自然言語プロセスの課題が解決されていないにもかかわらず、熱心な科学者によって出版された数学的言語学のジャーナルでは、次のように述べられています。 … 大人の言語学習者にとっても、関連する現象をモデル化しようとする科学者にとっても、自然言語の入力と出力を処理するシステムを構築しようとするエンジニアにとっても難しいことです。 これらのタスクは、チューリングが自然言語での流暢な会話を彼の知性テストの中心に正しくすることができるほど難しいものではありません。」
機械学習の科学者や研究者はデータを扱うことに関心があり、言語学は NLP のプロセスで機能します。 現代の開発者は次のように示唆しています。 その一部は、人間がどのように言語を獲得し、生成し、理解するかという認知規模に関係しており、言語発話と世界との関係を理解することに関係しており、言語構造を理解することに関係している。どの言語がコミュニケーションするか」
人工知能

AI は、コンピューターを使用して主要なタスクの自動化を推進し、高度なデジタル アシスタントとして機能します。 人間の知性は、環境を感知し、環境から学び、環境からの情報を処理するために根ざしています。 つまり、AI には以下が組み込まれています。
- 触覚、味覚、視覚、嗅覚、聴覚などの人間の感覚の欺瞞。
- 人間の反応の欺瞞:ロボティクス。
- 学習と処理の欺瞞: 機械学習と深層学習。
コグニティブ コンピューティングは一般に、人間の行動を模倣し、人間の知性よりも優れている可能性がある問題を解決することに重点を置いています。 コグニティブ コンピューティングは、情報を補足するだけで、これまで以上に簡単に意思決定を行うことができます。 人工知能は自分自身で決定を下し、人間の役割を最小限に抑える責任があります。 コグニティブ コンピューティングの背後にあるテクノロジは、ディープ ラーニング、機械学習、ニューラル ネットワーク、NLP などを含む AI の背後にあるテクノロジに似ています。は完全に異なります。 AI は、「機械、特にコンピューター システムによる人間の知能プロセスのシミュレーション」と定義されています。 これらのプロセスには、学習(情報と情報を使用するためのルールの取得)、推論(ルールを使用しておおよそのまたは明確な結論に達する)、および自己修正が含まれます。 AI は、多数のテクノロジー、アルゴリズム、理論、および方法によって、コンピューターまたはスマート デバイスが人間の知性を備えたハイテク テクノロジーで実行できるようにする包括的な用語です。 機械学習、ロボティクスはすべて人工知能の下にあり、機械が拡張知能を提供し、人間の洞察と精度を超えることができます。 AI ツールは、ビジネスにさまざまな新しい機能を提供します。 最も高度な AI ツールと統合されたディープ ラーニング アルゴリズム。 研究者やマーケティング担当者は、拡張知能の導入にはより中立的な意味合いがあり、製品やサービスを改善するために AI が使用されていることを理解できるようになると考えています。 AI は次の 4 つのカテゴリに分類できます。
リアクティブ マシン: IBM の Deep Blue チェス コンピューターには、チェス盤の駒を識別し、それに応じて予測する能力がありますが、過去の経験にアクセスして将来の経験を知らせることはできません。 可能な動きを管理および分析できます。 Google の AlphaGO は別の例ですが、狭い目的で機能するように設計されており、別の状況には適用できません。
心の理論:ただし、このタイプの AI は、マシンが個々の決定を下せるように開発されています。 この AI 技術はかなり前に開発されましたが。 現在、実用的な用途はありません。
リミテッド メモリ:この人工知能技術は、過去の経験に基づいて将来のタスクを実行するために開発されました。 タスクに関する重要な決定について、高度なヒントを取得して提供する機能があります。 たとえば、車を運転している場合、AI 設計のナビゲーション システムにより、車線を変更して目的地に到着することができます。
自己認識: AI は、人間の体のような感覚と意識を真に持つことができるように開発されています。 自己認識と統合された機械は、情報を使用して現在の状態を理解し、第三者が感じていることをインターンすることができます。
プロセスの自動化

プロセスの自動化により、さまざまな機能を相互に連携させ、ワークフローの自動化を処理し、エラーを最小限に抑えることができます。 プロセスの自動化は、ビジネス自動化のためのテクノロジーの使用です。 最初のステップは、自動化が必要なプロセスを認識することから始めます。 自動化プロセスを完全に理解したら、自動化の目標を計画する必要があります。 自動化を開始する前に、プロセスの抜け穴とエラーを確認する必要があります。 ビジネスで自動化プロセスが必要な理由を解読できるリストを次に示します。
- プロセスを標準化し、合理化する。
- コストを削減して機敏にプロセスを解決する。
- リソースのより良い配分を開発する。
- 顧客体験の向上のため。
- コンプライアンスを改善して、ビジネス プロセスを規制および標準化します。
- 従業員満足度の高いサービスを提供します。
- 処理性能の視認性を向上させる。
一連の部門は、ビジネス プロセスを採用してプロセスを自動化し、複雑な性質のサイクルを緩和できます。
ヘッダー画像のソース: https://bit.ly/2PfdWWm