
より良いコンテンツSEOのためのGoogleNLPアルゴリズムを理解する
公開: 2022-06-04
自然言語処理(NLP)は、人工知能(AI)および検索エンジンアルゴリズムにおける最も複雑で革新的な進歩の1つです。 そして、当然のことながら、GoogleはNLP分野のリーダーになりました。 2021年にSMITHアルゴリズムと以前の自然言語アルゴリズムであるBERTが追加されたことで、Googleは人間の言語を上手に理解するAIを開発しました。 このテクノロジーには、AIで生成されたコンテンツの作成に使用できる機能があります。
並外れた精度で、GoogleのNLPアルゴリズムはAIゲームを変えました。 では、これはSEOにとって何を意味するのでしょうか。 この記事では、GoogleのNLPテクノロジーのすべての詳細と、それらを使用して検索エンジンの結果でランクを上げる方法について詳しく説明します。
自然言語処理とは何ですか?

自然言語処理(NLP)は、コンピューターに人間の言語を理解させる方法の研究を含む、コンピューターサイエンスと人工知能の分野です。 以前の形式のAIとは異なり、NLPはディープラーニングを使用します。
NLPは、コンピューターが自然に感じる方法で人間と対話できるようにするため、人工知能の重要なコンポーネントと見なされています。
NLPの目的は、Googleの検索結果を改善し、ライターを廃業させることのように聞こえるかもしれませんが、このテクノロジーは、SEO以外にもさまざまな方法で使用されています。
最も一般的なものは次のとおりです。
1.感情分析:顧客満足度などを判断するために人々の感情レベルを測定するNLP。
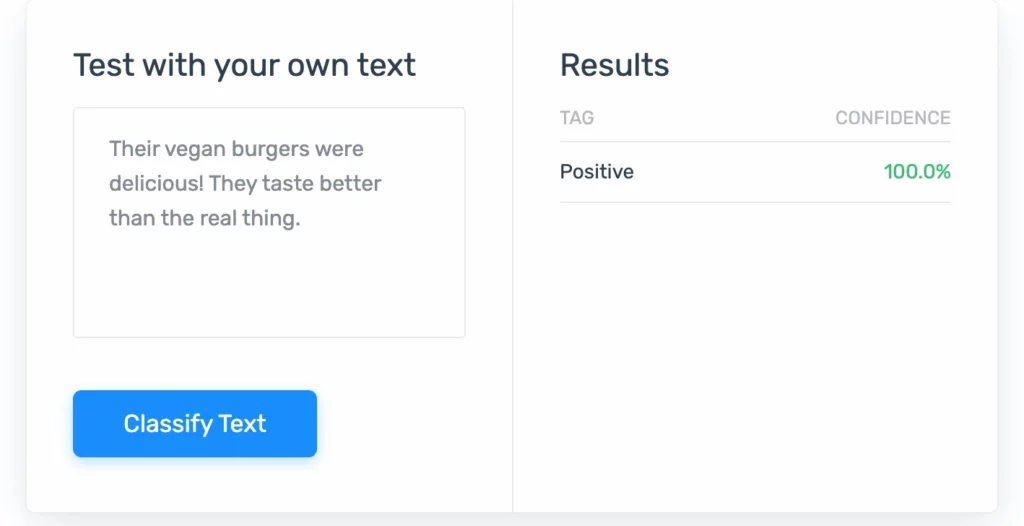
2.チャットボット:これらは、ヘルプページまたは一般的なWebサイトにポップアップ表示されるチャット画面です。 彼らはカスタマーサポートセンターの作業負荷を減らすためのコツを持っています。

4.音声認識:このNLPは音声を受け取り、コマンドなどに変換します。

テキストの分類、抽出、および要約:これらの形式のNLPは、テキストを分析してから、人間が使用、分析、および理解しやすいように再フォーマットすることができます。 テキスト抽出は、医療コーディングや請求のエラーの検出などのタスクに関して非常に役立ちます。
ディープラーニングとは何ですか?

ディープラーニングは、人間の脳のニューラルネットワークをモデルにした機械学習のカテゴリです。 この形式の機械学習は、通常のAI学習モデルよりも洗練されていると見なされることがよくあります。
それらは人間の脳を反映しているため、人間の行動を反映することもでき、多くのことを学ぶことができます。 多くの場合、深層学習アルゴリズムは2つの部分からなるシステムを使用します。 一方のシステムは予測を行い、もう一方のシステムは結果を改善します。
ディープラーニングは、しばらくの間、家庭用デバイス、公共環境、および職場で使用されてきました。 最も一般的なアプリケーションは次のとおりです。
- 自動運転車
- 音声リモコン
- クレジットカード詐欺の検出
- 医療機器
- 衛星ベースの国防
NLPはSEOにどのように影響しますか?

GoogleのPageRankの更新はほとんどなく、自然言語処理ボットなどのSEO標準を混乱させています。 GoogleのSMITHの展開に伴い、SEOスペシャリストが、アルゴリズムがどのように機能するか、およびアルゴリズムの基準を満たすコンテンツを作成する方法を理解するためにスクランブリングを行っているのを見ました。 ただし、ほとんどのアルゴリズムの更新と同様に、コンテンツがSERPに組み込まれる可能性が最も高いことを確認するために、コンテンツの基準を満たし、それを超える方法が明らかになることがよくあります。
基本的に、NLPは、Googleが検索者に、サイトのコンテンツの意図とより明確な理解に基づいて、より良い検索結果を提供するのに役立ちます。 これは、最高のコンテンツを提供しているサイトだけがSERPでの地位を保持していることを意味します。 さらに、検索者の意図を提供しないその他のコンテンツは、より深いSERPに埋もれてしまうか、まったく表示されなくなります。
Google BERTとは何ですか?

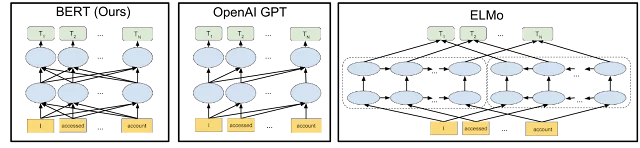
BERT(トランスフォーマーからの双方向エンコーダー表現)アルゴリズムは2019年に展開され、PageRank以来の最大の変化として波を起こしました。 このアルゴリズムは、優れた検索結果を提供するためにテキストを理解するために機能するNLPです。
より具体的には、 BERTは、文中の単語のコンテキストをよりよく理解するように設計されたニューラルネットワークです。 アルゴリズムは、事前トレーニングと呼ばれる手法を使用して、文内の単語間の関係を学習できます。
BERTアルゴリズムの目標は、機械翻訳や質問応答などの自然言語処理タスクの精度を向上させることです。
Google BERTアルゴリズムはどのように機能しますか?
BERTアルゴリズムは、転移学習と呼ばれる手法を使用してその目標を達成することができます。 転移学習は、大規模なデータセットですでにトレーニングされている事前トレーニング済みネットワークを使用して、ニューラルネットワークの精度を向上させるために使用される手法です。
Googleのアップデートの多くとは異なり、BERTの内部動作はオープンソースです。 BERTアルゴリズムは、2018年にGoogleが発行した論文に基づいています。このオープンソースの説明には、BERTが双方向のコンテキストモデルを使用して、個々の単語やフレーズの意味をよりよく理解することが含まれています。 その結果、コンテンツの分類が細かく調整されます。
例えば:
ハッピーアワー用のバーとベンチプレス機器用のバーをお探しの場合、Googleは、ページ内のコンテキストで単語がどのように使用されているかに基づいて、正しい種類のバーを表示します。
他に何がBERTを違うのですか?
BERTは、クラウドテンソルプロセッシングユニット(TPU)を使用して、事前トレーニングシステムとして既存のテキストサンプルから学習するNLPの機能を高速化しました。 事前トレーニングは、データの処理に使用される前に、大規模なデータセットでニューラルネットワークをトレーニングするために使用される手法です。 次に、事前にトレーニングされたネットワークを使用して、ネットワークのトレーニングに使用されたデータと同様のデータを処理します。 クラウドTPUを使用することで、BERTはデータを超高速で処理することができました。 また、GoogleCloudもテストできました。
何百万ものトレーニングセッションの後、BERTアルゴリズムは、文中の単語のコンテキストをよりよく理解できるため、以前の自然言語処理アルゴリズムよりも高い精度を達成できます。
BERTにはいくつのテキストサンプルが必要でしたか? BERTは、(英語だけでなく)自然言語を完全に把握するために、数百万、さらには数十億のサンプルを使用しました。
GoogleのBertUpdateはWebサイトにどのように影響しましたか?

ウェブサイトへのBERTアップデートの影響は2つありました。 まず、このアップデートにより、Googleの検索結果の精度が向上しました。 これは、Googleの検索結果で上位にランク付けされたWebサイトのクリック率(CTR)が高いことを意味します。
第二に、BERTの更新により、Webサイトコンテンツの重要性が高まりました。 これは、高品質で関連性の高いコンテンツを含むWebサイトが、Googleの検索結果で上位にランク付けされる可能性が高いことを意味します。
Google Bertの制限は何ですか?

BERTは強力なツールですが、その機能にはいくつかの制限があります。 このNLPモデルがいかに優れているかに夢中になるのは簡単ですが、BERTモデルがすべての人間の認知プロセスに対応できるわけではないことを覚えておくことが重要です。 そして、これらはコンテンツ理解機能の制限になる可能性があります。
BERTはテキストのみのアルゴリズムです
まず、BERTは、テキストを含む自然言語処理タスクにのみ効果的です。 画像やその他の形式のデータを含むタスクには使用できません。 ただし、 BERTは代替テキストを読み取ることができるため、Google画像検索に表示するのに役立ちます。
BERTは「全体像」を理解していません
第二に、BERTは非常に高度な理解を必要とするタスクには効果的ではありません。 基本的に、BERTは文中の単語のプロですが、記事全体を理解することはできません。
たとえば、BERTは、次の文の「バット」が木製の野球用バットではなく哺乳類を指していることを理解できます。バットは蚊を食い尽くしました。 ただし、複雑な文や段落の理解が必要なタスクには効果的ではありません。
Google SMITHアルゴリズムとは何ですか?

Google SMITH(またはSiamese Multi-depth Transformer-based Hierarchical)アルゴリズムは、Googleのエンジニアによって設計されたランキングアルゴリズムです。 このアルゴリズムは、自然言語を調べ、フレーズとの関係における意味のパターンを、それらの相互の距離に関連して学習し、ページをより正確に索引付けできるようにする情報の階層を作成します。
これにより、SMITHはコンテンツ分類をより効率的に実行できます。
SMITHのもう1つの興味深い機能は、テキスト予測子として機能できることです。 NLPで大きな波を起こしている他の企業があります(昨年のOpen AIの悪名高いGPT-3ベータを考えてみてください)。 これらのテクノロジーのいくつかは、他の人が独自の検索エンジンを構築するのに役立つ可能性があります。
GoogleのSMITHアップデートはウェブサイトにどのように影響しましたか?
GoogleのSMITHアップデートは、Webサイトに大きな影響を与えました。 このアップデートは、検索結果の精度を向上させるように設計されており、操作手法を使用してランクに影響を与えていたWebサイトにペナルティを課すことでこれを実現しました。 SMITHは、スパムリンク、ブラックハットSEO、人工知能など、さまざまな操作手法をターゲットにするように設計されており、高品質のコンテンツと有機的なリンク構築の水準を引き上げました。
SMITHが対象とした最も一般的な操作技術のいくつかは次のとおりです。
- キーワードの乱用
- リンク購入
- アンカーテキストの過度の使用。
これらの手法を使用していることが判明したWebサイトは、Googleによってペナルティが科せられ、その結果、検索ランキングが低下しました。
GoogleのSMITHアップデートとGoogleBERTの違いは何ですか?

BERTモデルとSMITHモデルはどちらも、Googleのウェブクローラーに言語の理解とページのインデックス作成を提供します。 グーグルはすでに長い形式のコンテンツを好んでいることを私たちは知っていますが、SMITHがライブであるとき、グーグルはより長いコンテンツをさらに効果的に理解します。 SMITHは、ニュースの推奨事項、関連記事の推奨事項、およびドキュメントのクラスタリングの領域を改善します。
GoogleNLPアルゴリズムのSEO戦略を調整する方法
Googleは、BERTまたはSMITHを最適化することはできないと主張していますが、NLPを最適化する方法を理解すると、SERPでのサイトのパフォーマンスに影響を与える可能性があります。 ただし、BERTがユーザーの意図を提供することに重点を置いていることを知っているということは、最適化する検索クエリの意図を理解する必要があることを意味します。
Googleは、アルゴリズムをいつロールアウトするかについて少し気が狂うことがよくあり、SMITHがいつ完全にロールアウトするかについては引き続き秘密にしています。 ただし、変更に合わせて最適化を開始したと想定するのが常に最善です。
SMITHは、NLPと機械学習テクノロジーでの優位性を維持するというGoogleの長期目標における多くの反復の1つにすぎない可能性があります。 Googleが完全なドキュメントの理解を深めるにつれて、優れた情報アーキテクチャがさらに重要になります。
GoogleのNLPアルゴリズム用にコンテンツを最適化するにはどうすればよいですか?

- コンテンツが適切にフォーマットされ、読みやすいことを確認してください。 見出しのベストプラクティスとその他の読みやすさのベストプラクティスを維持します。 これらには以下が含まれます:
- 文章を20語以内に収める
- 2より大きいリストされたアイテムには、箇条書きリストを使用します
- 正しい見出し階層を使用する
- 読者に侵入できないテキストのブロックを提示することは避けてください
- わかりやすい明確で簡潔な言葉を使用してください。 文の構造を過度に複雑にしないでください。 文の長さを制限することで、思考も合理化される可能性があります。
- Googleのアルゴリズムを混乱させる可能性のある複雑な単語や難しい単語の使用は避けてください。 シソーラスを捨てて、文章をわかりやすくします。 多くの場合、何かへの最短の道が最善であることを覚えておいてください。
- トピックに関連するキーワードとフォーカス用語を使用します。 意味的に関連するフォーカス用語は、Google自然言語プロセッサがページ全体をよりよく理解するのに役立ちます。
- コンテンツが新鮮で最新であることを確認してください。 これらのNLPアルゴリズムの動機は、スパムで古くなったコンテンツを排除しながら検索結果を改善することであることを忘れないでください。
- 人々が読みたくなるような、興味深く魅力的なコンテンツを書きましょう。 検索者に彼らのニーズに最適なコンテンツを提供することで間違いを犯すことは決してありません。 検索の意図とトピックの深さを覚えておいてください。
- あなたの顧客のレビューは重要です。 GoogleのNLPはエンティティの感情分析を実行できる可能性が高いため、悪いレビューを無視しないでください。 否定的なレビューを受け取った場合(英語であろうと火星人であろうと)、Googleのエンティティ感情分析がSERPを押し下げることは間違いありません。
- 検索者の質問に明確な答えを提供します。 注目のスニペットを作成したい場合、GoogleのNLPは、エンティティ分析を使用したテキスト抽出を行った場合にのみ、そこに到達します。 これは、Googleが検索者に表示する特定の情報に焦点を当てる能力を持っていることを意味します。
GoogleNLPの未来
Google自然言語APIとクラウドTPUが、誰でも使用できるようになりました。 したがって、深層学習機械学習プラットフォームを使用してNLPタスクを実行できる場合は、Googleの自然言語APIを使用できます。 必要に応じて、 GoogleCloudNLPのトレーニングに参加することもできます。
Google Natural Language API向けに最適化して、結果を取得する
1つ明らかなことは、自然言語APIが残っているということです。 BERTモデルとSMITHモデルの間の進歩からわかるように、Google検索アルゴリズムはコンテンツをよりよく理解し続けるだけです。
あなたのマントラを同じままにしましょう:コンテンツに焦点を合わせ、品質に焦点を合わせます。 SEOは、GoogleのNLPアルゴリズムに最適なものを見つけるために学習と実験を続けますが、常にSEOのベストプラクティスに固執します。 あなたが書いたものはあなたのランキングに影響を与えることを覚えておいてください、しかしあなたの顧客と訪問者が書いたものは感情分析のおかげで同様に影響を及ぼします。 BERTアルゴリズムの詳細をご覧ください。
SearchAtlasのAIコンテンツ生成ツールはGoogleのNaturalLanguageAPIに基づいて構築されているため、少ない労力で最高品質のコンテンツを作成できます。