
エンティティの主観的属性の識別
公開: 2022-05-13エンティティのUGC主観的属性の識別
この最近付与された特許は、エンティティの主観的な属性を識別することに関するものです。
私は、実体の主観的な属性またはそれらの実体への反応についての特許を見たことがありません。
それの重要な側面は、それがユーザー生成コンテンツであるということです。
ソーシャルネットワーク、ブログ、レビューWebサイトなどの人気が高まっているため、ユーザー生成コンテンツ(UGC)がWeb上でより一般的になっていると言われています。
ユーザーが作成したコンテンツは、次のようなコメントの形式で表示されることがよくあります。
- ソーシャルネットワーク内で2番目のユーザーが共有するコンテンツに関する最初のユーザーによるコメント
- コラムニストのブログの記事に対するユーザーのコメント
- コンテンツホスティングウェブサイトに投稿されたビデオクリップからのコメント
- レビュー(製品、映画など)
- アクション(いいね!、嫌い!、+ 1、共有、ブックマーク、プレイリストなど)
- など
この特許の下で、エンティティ(メディアクリップ、画像、新聞記事、ブログエントリ、人物、組織、営利事業など)の主観的な属性を識別および予測する方法が提供されます。
それでは始まります:
- 最初のエンティティへの反応に基づいて、最初のエンティティの主観的な属性の最初のセットを識別します(Webサイトへのコメント、最初のエンティティの承認のデモンストレーション(「いいね!」など)
- 最初のエンティティを共有する
- 最初のエンティティをブックマークする
- プレイリストに最初のエンティティを追加する
- 分類器(サポートベクターマシン、AdaBoost、ニューラルネットワーク、入出力マッピングのセットに関する決定ツリーなど)のトレーニング。入出力マッピングのセットは、入力が特徴ベクトルを提供する入出力マッピングで構成されます。最初のエンティティの場合、その出力は主観的な属性の最初のセットに基づいて取得されます
- 訓練された分類器に2番目のエンティティの特徴ベクトルを提供して、2番目のエンティティの主観的な属性の2番目のセットを取得します
エンティティの主観的な属性を識別および予測するために、メモリとプロセッサが提供されます。
コンピュータ可読記憶媒体には、コンピュータシステムに以下を含む操作を実行させる命令があります。
- 最初のエンティティへの反応に基づいて、最初のエンティティの主観的な属性の最初のセットを特定する
- 最初のエンティティの最初の特徴ベクトルを取得する
- 入出力マッピングのセットで分類器をトレーニングします。ここで、入出力マッピングのセットは、入力が最初の特徴ベクトルに基づいて取得され、出力が主観的属性の最初のセットに基づいて取得される入出力マッピングを含みます。
- 2番目のエンティティの2番目の特徴ベクトルを取得する
- トレーニング後、2番目のエンティティの主観的属性の2番目のセットを取得するための2番目の特徴ベクトルを分類器に提供します。
エンティティの主観的属性の識別に関するこの特許は、次の場所にあります。
キュレーション信号の分析による主観的属性の特定
発明者:HrishikeshAradhyeおよびSankethShetty
譲受人:Google LLC
米国特許:11,328,218
付与:2022年5月10日
提出日:2017年11月6日
概要:
エンティティ(メディアクリップ、映画、テレビ番組、画像、新聞記事、ブログエントリ、個人、組織、営利事業など)の主観的属性を識別および予測するためのシステムと方法が開示されます。
一態様では、第1のメディアアイテムの主観的属性は、第1のメディアアイテムに対する反応に基づいて識別され、第1のメディアアイテムについての個人的資質の関連性スコアが決定される。
分類器は、(i)最初のメディアアイテムの機能のセットを含むトレーニング入力とトレーニング入力のターゲット出力を使用してトレーニングされます。ターゲット出力は、最初のメディアアイテムの主観的属性のそれぞれの関連性スコアを含みます。
エンティティの主観的属性の識別と予測
エンティティ(メディアクリップ、画像、新聞記事、ブログエントリ、個人、組織、営利事業など)の主観的な属性を識別および予測する方法。
主観的な属性(「かわいい」、「面白い」、「素晴らしい」など)が定義され、特定のエンティティの主観的な属性が、次のようなエンティティに対するユーザーの反応に基づいて識別されます。
- ウェブサイトへのコメント
- 好き!
- 最初のエンティティを他のユーザーと共有する
- 最初のエンティティをブーマークする
- プレイリストに最初のエンティティを追加する
- 等
主観的属性の関連性スコアは、エンティティについて決定されます
主観的な属性「かわいい」がビデオクリップのコメントのかなりの割合で表示される場合、「かわいい」には高い関連性スコアが割り当てられる可能性があります。
次に、エンティティは、識別された主観的な属性と関連性スコアに関連付けられます(エンティティに適用されたタグ、リレーショナルデータベースのテーブルのエントリなど)。
上記の手順は、特定のエンティティセット(ビデオクリップリポジトリのビデオクリップなど)の各エンティティに対して実行され、主観的な属性からグループ内のエンティティへの逆マッピングが、個人の資質と関連性スコアに基づいて生成されます。 。
次に、逆マッピングを使用して、特定の主観的属性に一致するセット内のすべてのエンティティ(主観的属性「面白い」などに関連付けられたすべてのエンティティなど)を識別し、それによって次のことが可能になります。
- キーワード検索を処理するための関連エンティティの迅速な検索
- プレイリストへの入力
- 広告の配信
- 分類器のトレーニングセットの生成
- など
分類器(サポートベクターマシン[SVM]、AdaBoost、ニューラルネットワーク、決定木など)は、トレーニング例のセットを提供することによってトレーニングされます。トレーニング例の入力は、特定のエンティティ(ビデオクリップの特徴ベクトルなど)。
以下に関する数値が含まれる場合があります。
- 色
- テクスチャ
- 強度
- ビデオクリップに関連付けられたメタデータタグ
- 等
出力には、特定のエンティティの語彙の各主観的属性の関連性スコアが含まれます。
トレーニングを受けた分類器は、トレーニングセットに含まれていないエンティティの主観的な属性を予測できます(新しくアップロードされたビデオクリップ、コメントをまだ受け取っていないニュース記事など)。
この特許は、エンティティに対するユーザーの反応に基づいて、「面白い」、「かわいい」などの主観的な属性に従ってエンティティを分類できます。
この特許は、ビデオクリップのタグなどのエンティティの説明の品質を向上させ、検索の品質と広告のターゲティングを向上させることができます。
主観的属性を識別するためのシステムアーキテクチャ
システムアーキテクチャには次のものが含まれます。
- サーバーマシン
- エンティティストア
- クライアントマシンがネットワークに接続されている
ネットワークは、パブリック(インターネットなど)、プライベートネットワーク(ローカルエリアネットワーク(LAN)や広大なエリアネットワーク(WAN)など)、またはそれらの組み合わせの場合があります。
クライアントマシンは、ワイヤレス端末(スマートフォンなど)、パーソナルコンピューター(PC)、ラップトップ、タブレットコンピューター、またはその他のコンピューティングデバイスや通信デバイスです。
クライアントマシンは、クライアントマシンのハードウェアとソフトウェアを管理するオペレーティングシステム(OS)を実行する場合があります。
ブラウザ(図には示されていません)は、クライアントマシン(クライアントマシンのOSなど)で実行できます。
ブラウザは、Webサーバーによって提供されるWebページおよびコンテンツにアクセスできるWebブラウザである場合があります。
クライアントマシンは以下をアップロードすることもできます。
- ウェブページ
- メディアクリップ
- ブログエントリ
- 記事へのリンク
- など
サーバーマシンには、Webサーバーと主観的な属性マネージャーが含まれます。 Webサーバーと感情属性マネージャーは異なるデバイスで実行される場合があります。
エンティティストアは、メディアクリップ(ビデオクリップ、オーディオクリップ、ビデオとオーディオの両方を含むクリップ、画像など)やその他の種類のコンテンツアイテム(Webページ、テキストなど)などのエンティティを保存できる永続的なストレージです。ベースのドキュメント、レストランのレビュー、映画のレビューなど)、およびエンティティにタグを付け、整理し、インデックスを付けるためのデータ構造。
エンティティストアは、メインメモリ、磁気または光ストレージベースのディスク、テープまたはハードドライブ、NAS、SANなどのストレージデバイスによってホストされる場合があります。
エンティティストアは、ネットワークに接続されたファイルサーバーによってホストされる場合があります。 対照的に、他の実装では、エンティティストアは、サーバーマシンまたはネットワークを介してサーバーマシンに結合された異なるマシンのストレージなど、他のタイプの永続ストレージによってホストされる場合があります。
エンティティストアに格納されているエンティティには、クライアントマシンによってアップロードされるユーザー生成コンテンツが含まれる場合があり、次のようなサービスプロバイダーによって提供されるコンテンツが含まれる場合があります。
- ニュース組織
- 出版社
- ライブラリ
- 後で
サーバーは、エンティティストアからクライアントにWebページとコンテンツを提供する場合があります。
主観的属性マネージャー:
- ユーザーの反応(コメント、いいね!、共有、ブックマーク、プレイリストなど)に基づいてエンティティの主観的な属性を識別します
- エンティティに関する主観的な属性の関連性スコアを決定します
- 主観的な属性と関連性スコアをエンティティに関連付けます
- 色、テクスチャ、強度などの画像の特徴などの特徴を抽出します。 振幅、スペクトル係数比などのオーディオ機能。 単語の頻度、平均的な文の長さ、フォーマットパラメータなどのテキスト機能。 エンティティに関連付けられたメタデータ。 など)エンティティから特徴ベクトルを生成する
- 特徴ベクトルと主観的属性の関連性スコアに基づいて分類器をトレーニングします
- 訓練された分類器を使用して、新しいエンティティの特徴ベクトルに基づいて新しいエンティティの主観的な属性を予測します
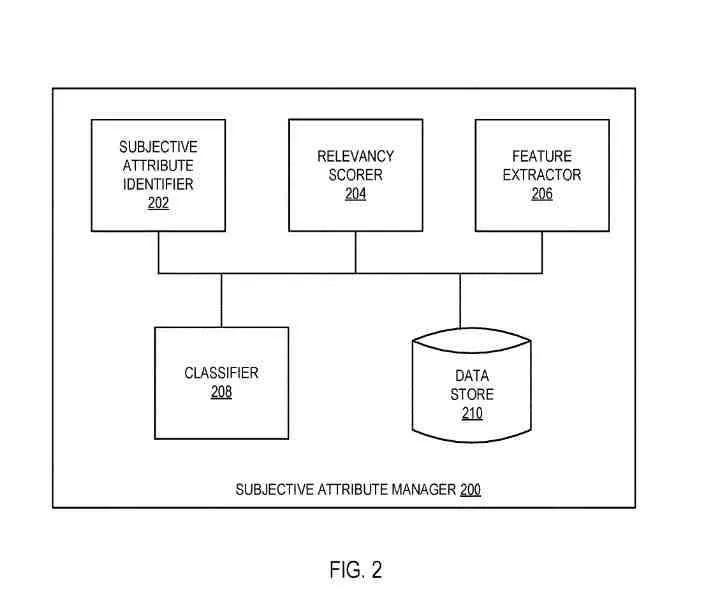
主観的属性マネージャー
主観的属性マネージャーは、主観的属性マネージャーと同じであり、以下を含み得る:
- 主観的属性識別子
- 関連性スコアラー
- 特徴抽出器
- 分類子
- データストア
。
コンポーネントを組み合わせたり、さらに詳細に分離したりできます。
データストアは、エンティティストアまたは別のデータストア(一時バッファや永続データストアなど)と同じで、個人属性の語彙、処理されるエンティティ、エンティティに関連付けられたフィーチャベクトル、個人属性を保持できます。エンティティに関連する関連性スコア、またはこれらのデータの組み合わせ。
データストアは、メインメモリ、磁気または光ストレージベースのディスク、テープ、ハードドライブなどのストレージデバイスによってホストされる場合があります。
主観的属性マネージャーは、データストアおよびエンティティストアに格納されている情報の種類をユーザーに通知し、ユーザーがそのような情報を収集して主観的属性マネージャーと共有しないように選択できるようにします。
主観的属性識別子
個人属性識別子は、エンティティに対するユーザーの反応に基づいて、エンティティの主観的な属性を識別します。
個人属性識別子は、ソーシャルネットワーキングウェブサイトにユーザーによって投稿されたエンティティへのユーザーのコメントのテキスト処理を介して主観的な属性を識別することができます。
主観的属性識別子は、エンティティに対する他のタイプのユーザーの反応に基づいて、エンティティの主観的属性を識別できます。
- '好き!' または「嫌い!」
- エンティティの共有
- エンティティのブックマーク
- エンティティをプレイリストに追加する
- など
個人属性識別子は、どの属性がエンティティに関連付けられているかを決定するためにしきい値を適用する場合があります(たとえば、主観的な属性は少なくともN個のコメントに表示される必要があります)。
関連性スコアラーは、エンティティに関する主観的な属性の関連性スコアを決定します。
たとえば、主観的属性識別子が、ソーシャルネットワーキングWebサイトに投稿されたメディアクリップへのコメントに基づいて主観的属性「かわいい」、「面白い」、および「素晴らしい」を識別した場合、関連性スコアラーは、これら3つの主観的それぞれの関連性スコアを決定できます。に基づく属性:
- これらの主観的な属性がコメントに表示される頻度
- 主観的な属性を提供した特定のユーザー
- など
たとえば、コメントが40あり、「かわいい」が20語で表示され、「素晴らしい」が8つのコメントで表示される場合、「かわいい」には「素晴らしい」よりも高い関連性スコアが割り当てられる可能性があります。
関連性スコアは、主観的な属性が表示されるコメントの割合に基づいて割り当てることができます(たとえば、「かわいい」のスコアは0.5、「素晴らしい」のスコアは0.2など)。
関連性スコアラーは、k個の最も関連性の高い主観的属性のみを保持し、他の個人属性を破棄する場合があります。
たとえば、個人属性識別子が、ユーザーのコメントに少なくとも3回表示される7つの感情的な属性を識別するとします。 その場合、関連性スコアラーは、たとえば、関連性スコアが最も高い5つの主観的属性のみを保持し、他の2つの感情的属性を破棄することができます(関連性スコアをゼロに設定するなど)。

関連性スコアは、0.0から1.0までの自然数です。
特徴抽出器は、次のような手法を使用してエンティティの特徴ベクトルを取得します。
- 主成分分析
- 半確定埋め込み
- アイソマップ
- 部分最小二乗
- など
エンティティの特徴の抽出に関連する計算は、特徴抽出自体によって実行されます。
他のいくつかの側面では、これらの計算は、次の実行可能ライブラリなどの別のエンティティによって実行されます。
- サーバーマシンによってホストされる画像処理ルーチン[図には示されていません]
- オーディオ処理ルーチン
- テキスト処理ルーチン
- 等
結果は特徴抽出器に提供されます。
分類器は、エンティティに関連付けられた特徴ベクトルを入力として受け入れ、関連性スコア(0の間の実際の数など)を出力する学習マシン(サポートベクターマシン[SVM]、AdaBoost、ニューラルネットワーク、決定木など)です。個人属性語彙の主観的属性ごとに1つなど)。
分類器は単一の分類器で構成されます。
分類器には、複数の分類器(個人属性語彙の各主観的属性の分類器など)を含めることができます。
一連の肯定的な例と否定的な基準は、個人属性の語彙の主観的な属性ごとに組み立てられます。
主観的属性の肯定的な例のセットには、その特定の個人属性に関連付けられたエンティティの特徴ベクトルが含まれる場合があります。
主観的属性の一連の否定的な例には、その特定の個人属性に関連付けられていないエンティティの特徴ベクトルが含まれる場合があります。
肯定的な例のセットと否定的な基準のセットのサイズが等しくない場合、より広範なセットが、より小さなグループのサイズに一致するようにサンプリングされる可能性があります。
トレーニング後、分類器は、分類器への入力としてこれらのエンティティの特徴ベクトルを提供することにより、トレーニングセットにない他のエンティティの主観的な属性を予測できます。
主観的属性のセットは、関連性スコアがゼロ以外のすべての感情的属性を含めることにより、分類器の出力から取得できます。 主観的なポイントのグループは、数値スコアに最もマイナーなしきい値を適用することによって取得できます(少なくとも、たとえば0.2のスコアを持つすべての個人属性をセットのメンバーと見なすことによって)。
エンティティの主観的属性の識別
この方法は、ハードウェア(回路、専用ロジックなど)、ソフトウェア(汎用コンピュータシステムまたは専用マシンで実行されるなど)、あるいはその両方を含むロジックを処理することによって実行されます。
このメソッドはサーバーマシンによって実行されますが、他のいくつかの実装は別のデバイスによって実行される場合があります。
主観的属性マネージャーのさまざまなコンポーネントが別々のマシンで実行される場合があります(たとえば、個人属性識別子と関連性スコアラーが1つのデバイスで実行され、特徴抽出器と分類子が別のデバイスで実行される場合など)。
説明を簡単にするために、この方法は一連の行為として描かれ、説明されています。
しかし、行為はさまざまな順序で発生する可能性があり、ここに提示および説明されていない他の行為とともに発生する可能性があります。
さらに、開示された主題による方法をインストールするために、すべての図示された行為が必要とされるわけではない。
さらに、当技術分野の当業者は、この方法が、状態図またはイベントを介して一連の相互に関連する状態として表すことができることを理解し、理解するであろう。
さらに、本明細書に開示された方法は、そのような方法論をコンピューティングデバイスに輸送および転送することを容易にするために、製品に格納することができることを理解されたい。
本明細書で使用される製造品という用語は、任意のコンピュータ可読デバイスまたは記憶媒体からアクセス可能なコンピュータプログラムを包含することを意図する。
主観的な属性の語彙が生成されます。
いくつかの側面では、主観的な属性の語彙が定義される場合があります。 対照的に、他のいくつかの要因では、個人属性の語彙は、エンティティに対するユーザーの反応で使用される用語やフレーズを収集することにより、自動化された方法で生成される場合があります。 対照的に、さらに他の側面では、語彙は、手動および自動化された技術の組み合わせによって生成される可能性がある。
語彙には、エンティティに適用されると予想される少数の主観的な属性がシードされます。 ユーザーの反応に現れるより多くの用語やフレーズが応答の自動処理によって識別されるにつれて、語彙は時間とともに拡張されます。
主観的属性の語彙は、おそらく個人的属性に関連付けられた「メタ属性」に基づいて階層的に編成される場合があります(たとえば、個人的属性「面白い」はメタ属性「ポジティブ」を持ち、主観的ポイント「嫌な」は持つ可能性があります)メタ属性「ネガティブ」など)。
エンティティのセットS(エンティティストア内のすべてのエンティティ、エンティティストア内のエンティティのサブセットなど)は前処理されます。
一態様では、エンティティの前処理は、エンティティに対するユーザの反応を識別し、次に、応答に基づいて分類器を訓練することを含む。
エンティティが実際の物理エンティティである場合
エンティティが実際の物理エンティティ(人、レストランなど)である場合、エンティティの前処理は、物理エンティティに関連付けられた「サイバープロキシ」(ソーシャルネットワーキングWebサイトの俳優のファンページ、Webサイトのレストランレビューなど)。 ただし、主観的な属性は、エンティティ自体に関連付けられていると見なされます(俳優のファンページやレストランのレビューではなく、俳優やレストランなど)。
getを実行する方法の例を詳細に説明します。
セットSに含まれていないAtnエンティティEが受信されます(新しくアップロードされたビデオクリップ、まだコメントを受け取っていないニュース記事、トレーニングセットに含まれていないエンティティストア内のエンティティなど)。
エンティティEのサブジェクト属性と関連性スコアが取得されます。
以下に、第1の例示的な方法の実施について詳細に説明し、第2の例示的な方法の性能について説明する。
得られた主観的属性と関連性スコアは、エンティティEに関連付けられます(対応するタグをエンティティに適用する、リレーショナルデータベーステーブルにレコードを追加するなど)。
実行は続行されます。
同時に実行される可能性のある再トレーニングプロセスによって、分類器が再トレーニングされる可能性があることに注意してください(ループの100回の反復ごと、N日ごとなど)。
一連のエンティティの前処理
この方法は、ハードウェア(回路、専用ロジックなど)、ソフトウェア(汎用コンピュータシステムまたは専用マシンで実行されるなど)、あるいはその両方を含むロジックを処理することによって実行されます。
メソッドは実行されますが、他のいくつかの実装では別のマシンによって実行される場合があります。
トレーニングセットは空のセットに初期化されます。 エンティティEが選択され、エンティティのセットSから削除されます。
エンティティEの主観的な属性は、エンティティEに対するユーザーの反応(ユーザーのコメント、いいね!、ブックマーク、共有、プレイリストへの追加など)に基づいて識別されます。
主観的な属性の識別には、次のようなユーザーコメントの処理の実行が含まれます。
- ユーザーコメントの単語と語彙の主観的属性の照合
- 単語照合と、構文分析や意味分析などの他の自然言語処理技術の組み合わせ
- 等
場所の近くで発生するエンティティ
ユーザーの反応は、次のような多くの場所で発生するエンティティに対して集約される可能性があります。
- 多くのユーザーのプレイリストに表示されるエンティティ
- 共有され、ソーシャルネットワーキングWebサイトの複数のユーザーの「ニュースフィード」に表示されるエンティティ
- 等
さまざまな場所は、次のようなさまざまな要因に基づいて、関連性スコアへの貢献度に重みが付けられる場合があります。
場所に関連付けられた特定のユーザー(特定のユーザーはクラシック音楽の権威である可能性があるため、ニュースフィード内のエンティティに関するコメントは、別のニュースフィード内のコメントよりも重み付けされる可能性がありますなど)、非テキストユーザーの反応( 「いいね!」、「嫌い!」、「+ 1」など)。
さらに、エンティティが表示される場所の数は、主観的な属性と関連性スコアの決定にも使用できます(たとえば、ビデオクリップが数百のユーザープレイリストにある場合、ビデオクリップの関連性スコアが増加する可能性があります)。
ブロックは主観的な属性識別子によって実行されます。
主観的属性の関連性スコアは、エンティティEによって決定されます。
関連性スコアは、ユーザーのコメントに個人属性が表示される頻度に基づいて特定の主観的属性に対して決定されます。特定のユーザーは、主観的な詳細を言葉で提供します(一部のユーザーは、経験からより正確であることがわかっている場合があります)。他のユーザーよりもコメントなど)。
たとえば、コメントが40あり、「かわいい」が20語で表示され、「素晴らしい」が8つのコメントで表示される場合、「かわいい」には「素晴らしい」よりも高い関連性スコアが割り当てられる可能性があります。
関連性スコアは、主観的な属性が表示されるコメントの割合に基づいて割り当てることができます(たとえば、「かわいい」のスコアは0.5、「素晴らしい」のスコアは0.2など)。
一態様では、関連性スコアは、間隔[0、1]に収まるように正規化されます。
一部の側面では、識別された主観的属性は、関連性スコアに基づいて破棄される場合があります(たとえば、関連性スコアが最も高いk個の感情的属性を保持する、関連性スコアがしきい値を下回る個人属性を破棄するなど)。
主観的な属性は、いくつかの側面でその関連性スコアをゼロに設定することによって破棄される可能性があることに注意する必要があります。
主観的属性と関連性スコアはエンティティに関連付けられています
主観的な属性と関連性のスコアは、エンティティに関連付けられています(タグ付け、リレーショナルデータベースのテーブルのエントリなど)。
エンティティEの特徴ベクトルが取得されます。
一態様では、ビデオクリップまたは静止画像の特徴ベクトルは、色、テクスチャ、強度などに関する数値を含み得、一方、オーディオクリップ(または音声付きビデオクリップ)の特徴ベクトルは、振幅に関する数値を含み得る。 、スペクトル係数など。テキストドキュメントの特徴ベクトルには次のものが含まれる場合があります。
- 単語の頻度に関する数値
- 平均文長
- パラメータのフォーマット
- など
これは、特徴抽出器によって実行される場合があります。
得られた特徴ベクトルと関連性スコアがトレーニングセットに追加されます。
ボックは、エンティティのセットSが空かどうかをチェックします。 Sが空でない場合は実行が続行され、そうでない場合は実行が続行されます。
分類器は、トレーニングセットのすべての例でトレーニングされ、トレーニング例の特徴ベクトルが分類器への入力として提供され、主観的な属性の関連性スコアが出力として提供されます。
エンティティの主観的属性と関連性スコアの取得
エンティティEの特徴ベクトルが生成されます。
上記のように、ビデオクリップまたは静止画像の特徴ベクトルは、色、テクスチャ、強度などに関する数値を含み得る。対照的に、オーディオクリップ(または音声付きビデオクリップ)の特徴ベクトルは、数値を含み得る。振幅、スペクトル係数などについて。対照的に、テキストドキュメントの特徴ベクトルには、単語の頻度、平均文長、フォーマットパラメータなどに関する数値が含まれる場合があります。
訓練された分類器は、エンティティEの予測された主観的属性と関連性スコアを取得するための特徴ベクトルを提供します。
予測された主観的属性と関連性スコアは、エンティティEに関連付けられます(エンティティEに適用されたタグ、リレーショナルデータベースのテーブルのエントリなど)。
エンティティの主観的属性と関連性スコアを取得するための2番目の方法
この方法は、ハードウェア(回路、専用ロジックなど)、ソフトウェア、または両方の組み合わせで構成されるロジックを処理することによって実行されます。
このメソッドはサーバーマシンによって実行されますが、他のメソッドは別のデバイスによって実行される場合があります。
エンティティEの特徴ベクトルが生成されます。 訓練された分類器は、エンティティEの予測された主観的属性と関連性スコアを取得するための特徴ベクトルを提供します。
得られた予測された主観的属性は、ユーザー(エンティティをアップロードしたユーザーなど)に提案されます。洗練された個人属性のセットは、ユーザーが提案された属性の中から選択するWebページなどを介して、ユーザーから取得されます。新しい属性などを追加します)。
エンティティのデフォルトの関連性スコア
デフォルトの関連性スコアは、ユーザーによって追加された新しい主観的属性に割り当てられます。
デフォルトの関連性スコアは、0.0から1.0までのスケールで1.0である可能性があり、デフォルトの関連性スコアは、特定のユーザーに基づく可能性があります(たとえば、ユーザーが過去の履歴から属性の提案に非常に優れていることがわかっている場合のスコア1.0など)。ユーザーが属性の提案などにある程度優れていることがわかっている場合は、0.8になります)。
ブロックブランチは、ユーザーが提案された主観的属性のいずれかを削除したかどうかに基づいて取得されます(属性を選択しないなど)。
エンティティEは、分類器の将来の再トレーニングのために、削除された属性の否定的な例として保存されます。 洗練された主観的属性のセットと対応する関連性スコアは、エンティティEに関連付けられます(エンティティEに適用されたタグ、リレーショナルデータベースのテーブルのエントリなど)。