
NLU エンジンのベンチマーク: AI マーケット リーダー向けのデータ駆動型アプローチ
公開: 2022-09-09自然言語理解 (NLU) エンジンは、顧客の感情を大きく左右します。 AI と NLU は非常に進化したため、あるGoogle の従業員は、同社のチャットボット LaMDA は自己認識型の人間であると主張し、世界中の注目を集めました。
しかし、心配しないでください。 私たちは、AI ボットが世界を席巻したり、カスタマー サービスを提供したりする話であなたを驚かせるためにここにいるのではありません。
アメリカの消費者の約 71% は、顧客サービスの会話で人間味のあるものをいまだに好んでおり、そこにベンチマーク NLU エンジンが登場します。
NLU は、エージェントが顧客とのやり取りに知識、コンテキスト、感情のレイヤーを追加することで、顧客をよりよく理解し、サービスを提供するのに役立ちます。 ベンチマーク NLU エンジンを搭載した会話型 AI により、ブランドはより知的で共感的になり、隠れた顧客の手がかりを見つけて、顧客サービスをより個人的で機械的なものにすることができます。
しかし、NLU エンジンをベンチマークして AI 機能を評価するにはどうすればよいでしょうか? そこにたどり着くには、まず主要な技術用語を理解しましょう。
NLU エンジンのベンチマーク用語集
会話型 AI
会話型 AIは、人間の会話の根底にある感情、緊急性、およびコンテキストを認識することにより、コンピューターとデジタル アプリケーションが共感を持って顧客に関与できるようにする NLU を利用した機能です。データセット
データ セットとは、コンピューターが 1 つの情報セットとして処理できる、関連する一連の情報を集めたものです。発話
発話は、テキスト、オーディオ、またはビデオを通じて受け取ったユーザーの発話の句または文です。 NLU エンジンは発話を使用して、ユーザーの意図をトレーニング、テスト、解釈します。意図
意図は、アクション、イベント、またはステートメントの背後にあるユーザーの目的を示します。 たとえば、ユーザー アクションは、製品の問い合わせ、苦情、払い戻しのリクエストなどに分類できます。正確さ
精度は、NLU エンジンによって正しい意図と一致したテスト文の割合です。F1 マクロ
各意図の適合率と再現率のマクロ平均の調和平均は、F1 マクロと呼ばれます。
精度= インテントに対する真の肯定的な結果の数/インテントに対するすべての肯定的な結果。
リコール= 意図に対する真の肯定的な結果の数/意図に対する肯定的な結果として識別された結果の数。
NLU エンジンのベンチマーク: プロセスを理解する
NLU エンジンの比較は、面倒なプロセスになる場合があります。 NLU 対応ソリューションのセットを絞り込み、顧客に見られる共通の意図をテストするドリルを実行するのは、時間がかかる場合があります。 そこで、バイアスのないアプローチで NLU エンジンとそのAI 直感機能を評価するために、研究に裏付けられた構造化されたアプローチが役立ちます。
会話型エージェントを構築するための自然言語理解サービスのベンチマーク
この NLU ベンチマーク手法では、ホーム オートメーション ボットのデータセットの NLU エンジンを大小のデータ セットに分割して比較し、さまざまなトレーニングおよびテスト データ サイズで機械学習の精度を評価します。
NLU ベンチマーク手法で使用される手法
小さなデータセット
64 の異なるインテントがランダムに選択されます
NLU エンジンをトレーニングするために、インテントごとに 10 個の例文が使用されます
1,076 の例文 (トレーニング セットの一部ではない) がテストされます
大規模なデータセット
上記と同じ 64 個のインテントが大規模なデータ セット用に選択されます
NLU エンジンをトレーニングするために、インテントごとに約 30 の例文が使用されます
5,518 の例文 (トレーニング セットの一部ではない) がテストされます
NLU エンジン ベンチマーク レポート: 結果
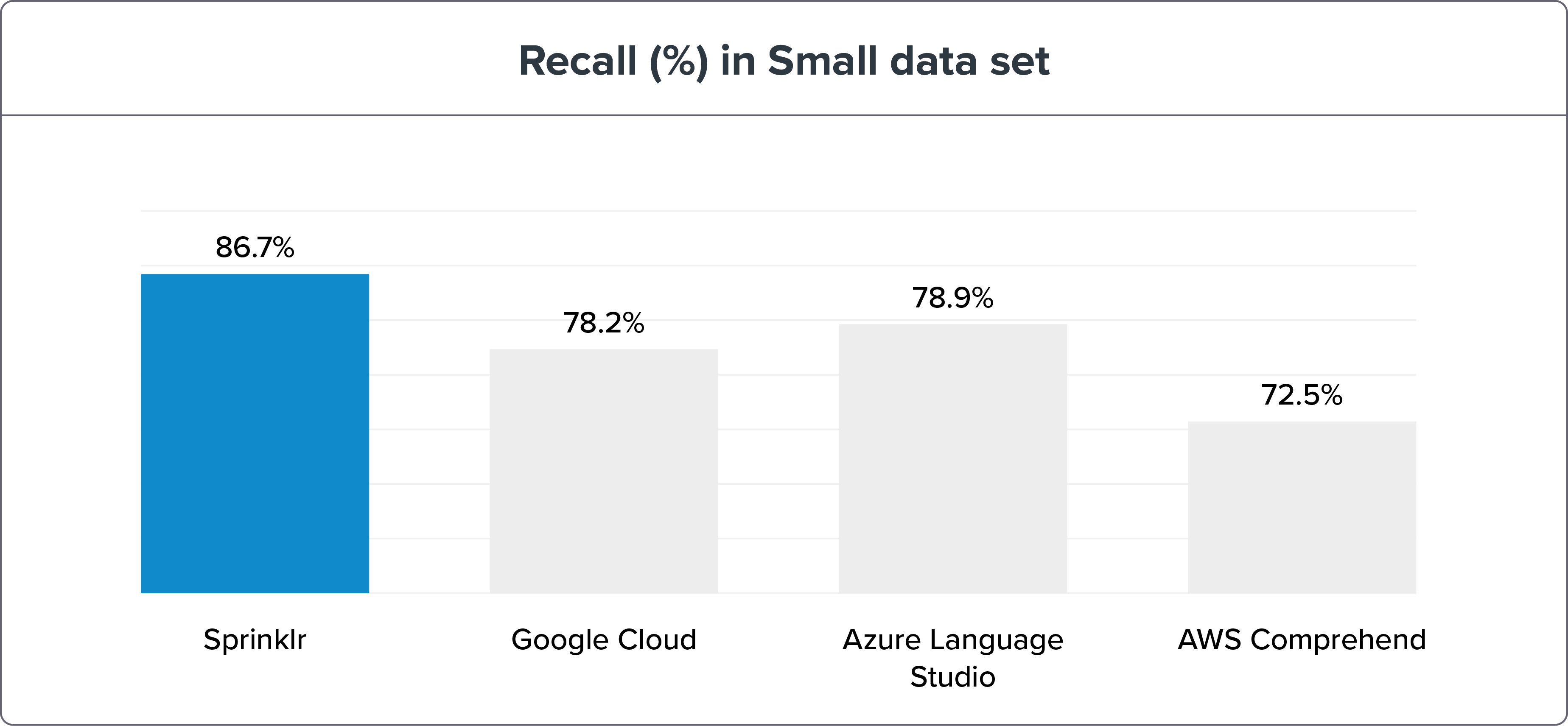
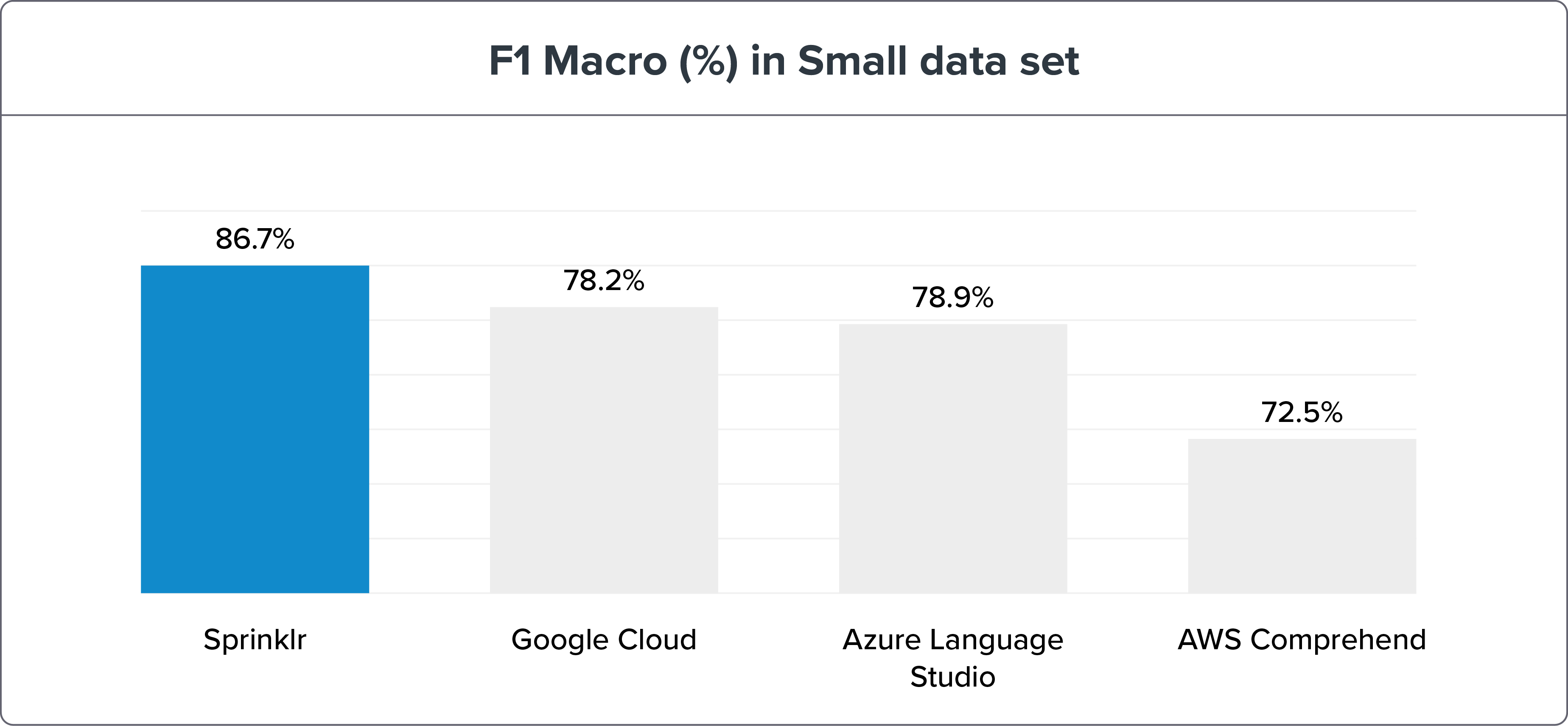
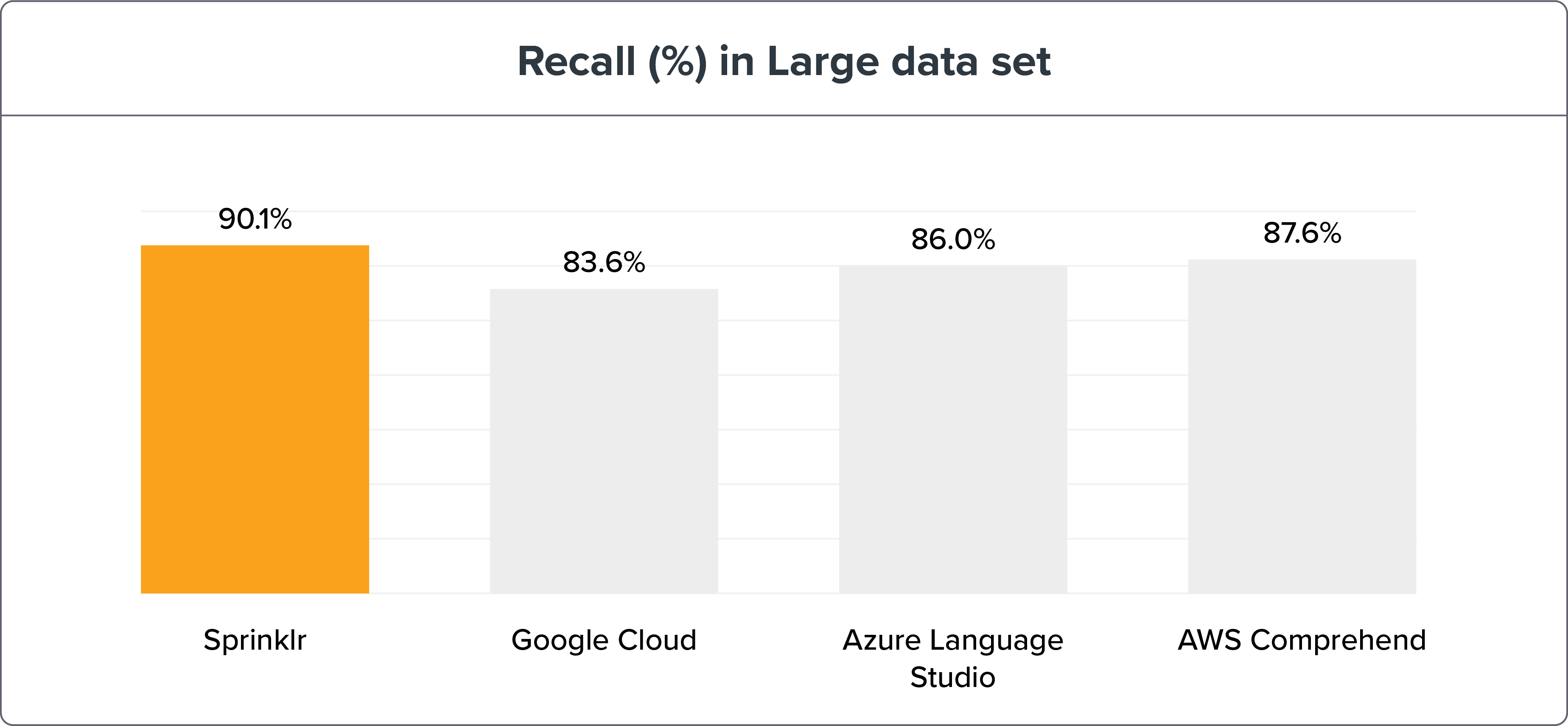
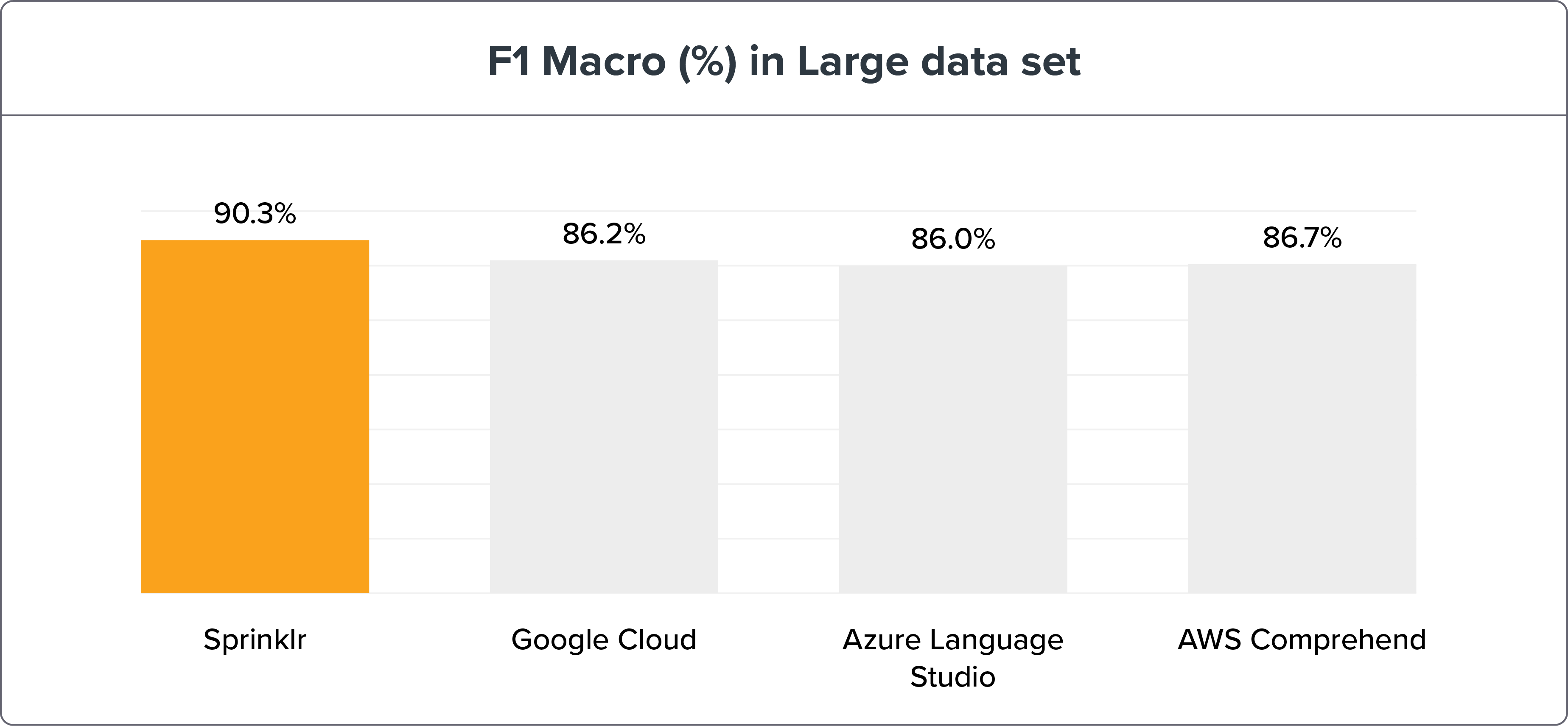
NLU ベンチマーク手法は、Sprinklr の NLP 精度がリコールと F1 マクロによって同時代の Google Cloud、Azure Language Studio、AWS Comprehend をはるかに上回っていることを示しています。 ベンチマーク データと結果は、こちらでご覧いただけます。
NLU エンジンのベンチマークを小さなデータ セットと大きなデータ セットに分けても、Sprinklr NLU エンジンは依然として明らかに勝者です。
注: より大きなデータ セットは、精度を高めるためにインテントをテストおよびトレーニングするための最良の方法です。 しかし、Sprinklr の NLU エンジンによる精度の変動は ≤ 3% にすぎません。
小さなデータセット
パラメーター:
640 トレーニング センテンス = インテントあたり 10 センテンス
1,076のテスト文
大規模なデータセット
パラメーター:
1,908 トレーニング センテンス ≈ インテントあたり 30 センテンス
5,518のテスト文
Sprinklr は、NLU エンジンのベンチマークで明確な勝者として浮上しています
Sprinklr の NLU エンジンは、クエリの意図を判断する際に一貫性と正確性を維持し、テスト入力とトレーニング入力の間のマッピングを改善します。
例 1: 小さなデータセット
質問: 知っておくべきことはありますか
グラウンド トゥルース: calendar_query

例 2: 大規模なデータ セット
クエリ: 欧州連合に加盟している国の数
グラウンド トゥルース: qa_factoid

NLU エンジンのベンチマークの制限
データセットのサイズ: 十分に調査された多数のデータセットが使用されたため、NLU エンジンは、通常見られる生の構造化データの場合よりも早くテスト発話から学習した可能性があります。
使用言語:さまざまなインスタンスとインテントをテストするために英語のみが使用されました。
テスト データの性質: ユーザーの発話は、文法上の誤りや会話のギャップがある一般的な顧客のようには聞こえない場合があります。

最も一般的な NLU エンジン解釈の課題
一般的な NLU エンジンには、特に顧客とのやり取りを解釈する際に、特定の制限があります。 最も一般的な NLU エンジンの解釈の誤りと、それを回避するための戦略を以下に示します。
皮肉
NLU エンジンは、皮肉や受動攻撃的な顧客のコメントを検出するのに苦労することがあります。
修正方法: これを解決する方法の 1 つは、自動化された NLU エンジンの応答を承認する前に、「ありがとう、すごい、なんでも」などのキーワードを追加してエージェントを通過させることです。
あいまいさ
人間は、文中の単語が名詞、動詞、または形容詞として使用されているかどうかを区別するのに苦労することがあります。 「ハングオン」や「プットアウト」などの句動詞も、NLU エンジンの認識に影響を与える可能性があります。
修正方法:あいまいさを減らす最善の方法は、あいまいな文やフレーズについて NLU エンジンをトレーニングし続けることです。 時間の経過とともに、エンジンはテスト入力を実際のユーザー操作と比較して学習を開始します。
NLU エンジンと AI チャットボットのあいまいさを減らすその他の方法:
機械学習モデルを活用して NLU トレーニングを改善: トランスフォーマーからの双方向エンコーダ表現 (BERT) や言語モデルからの埋め込み (ELMo) などのコンテキスト依存の機械学習モデルを使用して、NLU エンジンをトレーニングします。 これらのAI モデルは、単語や文章のさまざまな表現をすべて考慮し、追加のテキストを使用してあいまいなユーザー エントリを埋めます。
言語の不確実性を再確認するための適切なプロンプトを作成する: NLU エンジンを有効にして、複数の可能性から適切なバージョンのテキストを選択するようユーザーに促す「曖昧さ回避」応答を提供できるようにします。 これは、Google の「もしかして…」というプロンプトに非常によく似ており、検索用語の可能なバリエーションが含まれています。
さらにトレーニングを重ねる: NLU エンジンを厳密にトレーニングして、信号をノイズから分離します。 さまざまな固有のデータセットを使用して NLU エンジンをトレーニングすることほど、より優れた意図検出への近道はありません。 ユーザーのリクエストには、NLU エンジンの意図のタグ付け機能に影響を与える単語や文の構成が含まれている場合があります。

言語エラー
スペル ミスや不適切な文の形成により、NLU エンジンがユーザーの意図を正確に識別できなくなる可能性があります。 文法チェックは基本的なエラーを解決できますが、スラングや口語は、特にテキスト読み上げや音声分析では解釈が困難です。
修正方法:繰り返しになりますが、この問題を克服するための鍵は、NLU エンジンに、エラーや不完全な言語を含んだ不正確な模擬発話の膨大なセットを供給することです。
ドメインのバリエーション
ドメインスピークは、業界ごとに異なるもう 1 つの領域です。 ヘルスケアにおける「ドキュメンテーション」は、テクノロジーにおける「ドキュメンテーション」ワークフローとは異なる場合があります。
修正方法:意図の階層を明確に定義すると、NLU エンジンが、顧客の応答または発話が関連付けられている業界またはドメインを判別するのに役立ちます。
最高のパフォーマンスを発揮する NLU エンジンを特徴付ける品質
NLU エンジンの認知能力は、会社で評価する際に考慮すべき要素の 1 つにすぎません。 ユーザーの意図を大規模に理解する際の邪魔になる、面倒な手作業を克服するのに役立ちます。
さらに、NLU エンジンで注目すべきいくつかの重要な特性を以下に示します。
1.スピード
会話型 AI は顧客の意図を理解し、迅速かつ正確に応答することを目的としているため、NLU エンジンは結果を迅速に返す必要があります。 顧客とのやり取りを処理する速度によって、NLU エンジンの意図検出の精度が低下することはありません。
2. 垂直化
NLU エンジンには、テクノロジー、小売、e コマース、ロジスティクス、ホスピタリティなどの業界にまたがる多数のユース ケースがあります。 会話型 AI 機能は、これらの業界を区別し、独自のアプローチですべてのソリューション領域に適応できる必要があります。
3. 使いやすさ
非技術系の従業員プロファイルを含む NLU エンジンに注意してください。 データセットをテストおよびトレーニングする方法を理解することは、品質保証エンジニアや開発者に限定されるべきではありません。 これは、テクノロジーに詳しくないビジネス オーナーが自分でできることです。 ノーコード NLU エンジンを搭載した会話型 AI は、採用と使いやすさを向上させる方法です。
4. スケーラビリティ
NLU エンジンが収集するデータ入力が増えるにつれて、さまざまな地域のセマンティクス、言語のバリエーション、およびユーザー表現のさまざまなエンティティについてトレーニングする必要があります。 複数の言語を処理できる NLU フレームワークを構築し、会話型 AI チャットボットの将来性を保証します。
Sprinklr の NLU エンジンが会話型 AI のマーケット リーダーである理由は何ですか?
Sprinklr の AI エンジンは、カスタマー エクスペリエンス管理の全範囲を理解し、文脈化するために構築されています。 以下に、Sprinklr AI を従来の会話型 AI プラットフォームと区別する 7 つの差別化要因を示します。
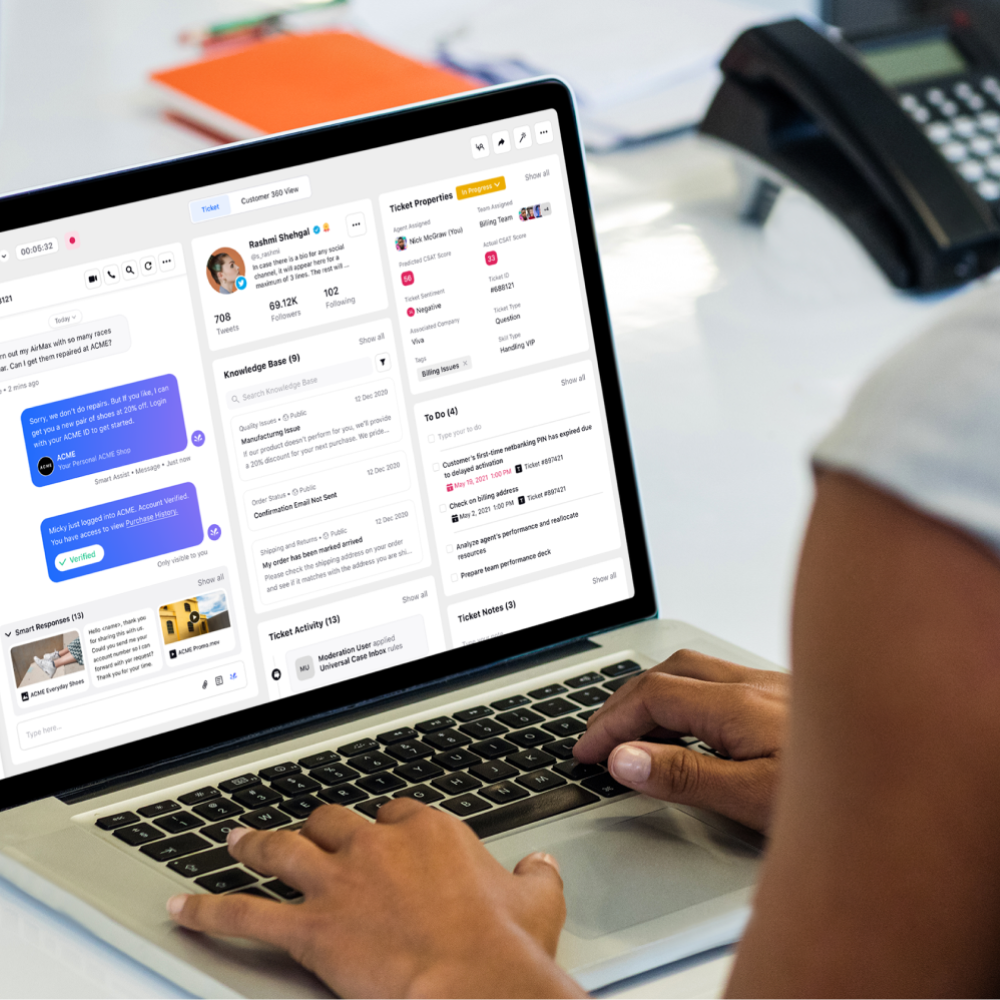
1. 正確なメッセージ分類
顧客のメッセージを自動的に読み取り、解読、分析し、意図として分類し、正確なケース割り当てのために社内チームを定義します。
2. 念入りな危機検知
顧客とのやり取りが手に負えなくなったときに、否定的なブランドの言及やキーワード、またはセンチメント検出などの AI によって識別された苦痛の兆候などの事前定義されたパラメーターを使用して、アラートをトリガーします。
3. コンテキストを意識した仮想支援
利用可能な顧客データ、ナレッジ ベース、およびチャネル全体でのやり取りの履歴に基づいて、顧客への自動応答を生成するか、エージェントに AI 支援を提供します。
4. 将来に備えた予測分析
顧客サービスだけでなく、人気のあるトピック、マクロ経済学、消費者感情、PR 危機、変化する業界ベンチマークなどの市場動向を予測して、製品とマーケティングのロードマップを再調整します。 Sprinklr の AI は、デジタル チャネルや顧客の人口統計などのパターンを、コンテキストに応じたデータの内訳で認識できます。

5.スマートな視覚的解釈
ブランドと顧客とのやり取りに関連する視覚データを処理して、人間のエージェントなしで画像と動画を正確に定義します。
6. エンドツーエンドの AI スタジオ
Sprinklr 内で AI モデルをトレーニング、テスト、デプロイして、ソーシャル リスニング、メッセージ分類、会話型 AI とチャットボット、応答の自動化、セルフサービス コミュニティを改善します。
7. ブランド インタラクションのモデレーション
すべてのエージェントと顧客のやり取りを監視して、社内ブランドのガイドラインを確実に遵守し、レポートを生成して、顧客満足度 (CSAT) を向上させ、主要な接触要因を減らすための改善領域を特定します。
ゼロタッチのパーソナライゼーションと運用効率でカスタマー サポートを拡張したいとお考えですか? Sprinklr の NLU エンジンは、何百万もの AI 予測、データ ポイント、すぐにデプロイ可能な何百もの AI モデルを備えており、必要な橋渡しをすることができます。
Modern Care Lite の無料トライアルを開始する
Sprinklr が企業が 13 以上のチャネルでプレミアム エクスペリエンスを提供するのにどのように役立つかをご覧ください。基本的な AI を使用して、カスタマー エクスペリエンス全体でリッスン、ルーティング、解決、測定を行うことができます。