
Lograr la resiliencia con las colas: construir un sistema que nunca se salte un latido en un billón
Publicado: 2018-12-21Braze procesa miles y miles de millones de eventos por día en nombre de sus clientes, lo que da como resultado miles de millones de mensajes personalizados hiperenfocados que se envían a sus usuarios finales. No enviar uno de esos mensajes tiene consecuencias, ya sea un recibo perdido o, lo que es peor, una notificación perdida que le informa al usuario que su comida está lista. Para asegurarse de que esos mensajes clave sean siempre correctos y puntuales, Braze adopta un enfoque estratégico sobre cómo aprovechamos las colas de trabajo.
¿Qué es una cola de trabajos?
Una cola de trabajos típica es un patrón arquitectónico en el que los procesos envían trabajos de cálculo a una cola y otros procesos ejecutan los trabajos. Esto suele ser algo bueno: cuando se usa correctamente, le brinda grados de simultaneidad, escalabilidad y redundancia que no puede obtener con un paradigma tradicional de solicitud-respuesta. Muchos trabajadores pueden ejecutar diferentes trabajos simultáneamente en múltiples procesos, múltiples máquinas o incluso múltiples centros de datos para una concurrencia máxima. Puede asignar ciertos nodos trabajadores para trabajar en ciertas colas y enviar trabajos particulares a colas específicas, lo que le permite escalar los recursos según sea necesario. Si un proceso de trabajo falla o un centro de datos se desconecta, otros trabajadores pueden ejecutar los trabajos restantes.
Si bien puede aplicar estos principios y ejecutar fácilmente un sistema de colas de trabajos a pequeña escala, las costuras comienzan a mostrarse (e incluso explotar) cuando procesa miles y miles de millones de trabajos. Echemos un vistazo a algunos problemas a los que se ha enfrentado Braze a medida que hemos pasado de procesar miles a millones y ahora a miles de millones de trabajos por día.
La falta de consistencia es una debilidad
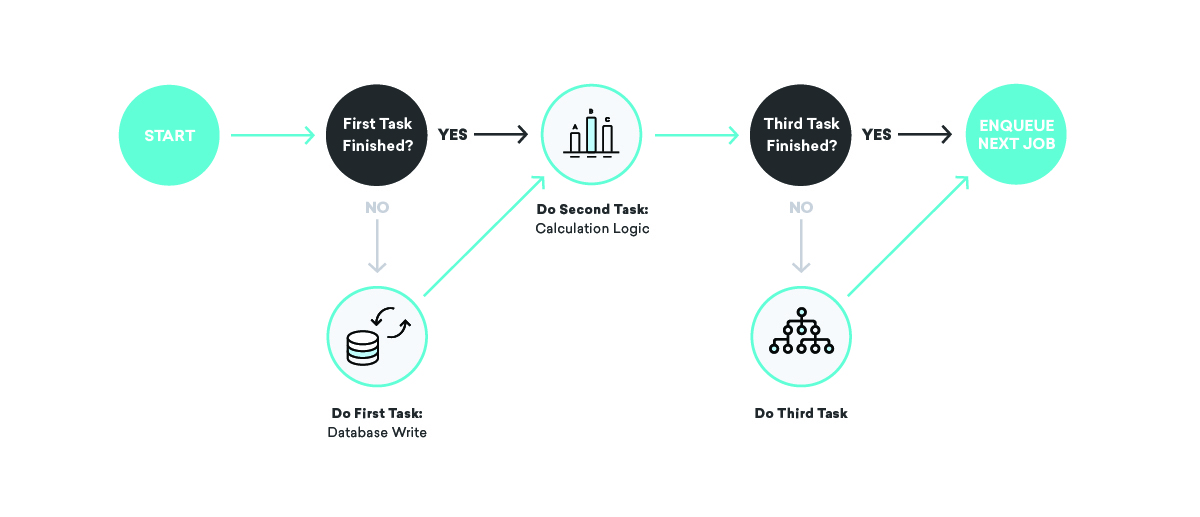
¿Qué sucede si enviamos un mensaje, pero nos bloqueamos antes de registrar el hecho de que acabamos de enviar ese mensaje?
Un par de malos resultados diferentes son posibles aquí. Primero, puede reprogramar el trabajo fallido y enviar el mensaje nuevamente. Eso... no es lo ideal: nadie quiere recibir lo mismo dos veces. En cambio, considere no reprogramarlo en absoluto. En ese caso, nuestra contabilidad interna será incorrecta, por lo que las atribuciones, las conversiones y todo tipo de cosas no serán correctas en el futuro.
¿Cómo arreglamos eso? Al escribir nuestras definiciones de trabajo, pensamos mucho en la idempotencia y el comportamiento de reintento.
Cuando se habla de colas, la idempotencia significa que un solo trabajo puede finalizar en un punto arbitrario, el trabajo que se volvió a poner en cola se volvió a ejecutar en su totalidad y el resultado final será el mismo que si hubiéramos ejecutado con éxito el trabajo exactamente una vez. tiempo. Esto está íntimamente ligado a nuestro comportamiento de reintento preferido: entrega al menos una vez. Al tener en cuenta que todos nuestros trabajos se ejecutarán al menos una vez, y tal vez varias veces, podemos escribir definiciones de trabajo idempotentes que garanticen la coherencia incluso ante fallas aleatorias.
Volviendo a nuestro ejemplo de envío de mensajes, ¿cómo podemos usar estos conceptos para garantizar la coherencia? En este caso, podríamos dividir el trabajo en dos partes, la primera enviando el mensaje y poniendo en cola al segundo, y el segundo escribiendo en la base de datos. En ese escenario, podemos reintentar cualquiera de los trabajos tantas veces como queramos: si el proveedor de envío de mensajes está inactivo o la base de datos de contabilidad interna está inactiva, ¡reintentaremos adecuadamente hasta que tengamos éxito!
Buenas vallas hacen buenos vecinos
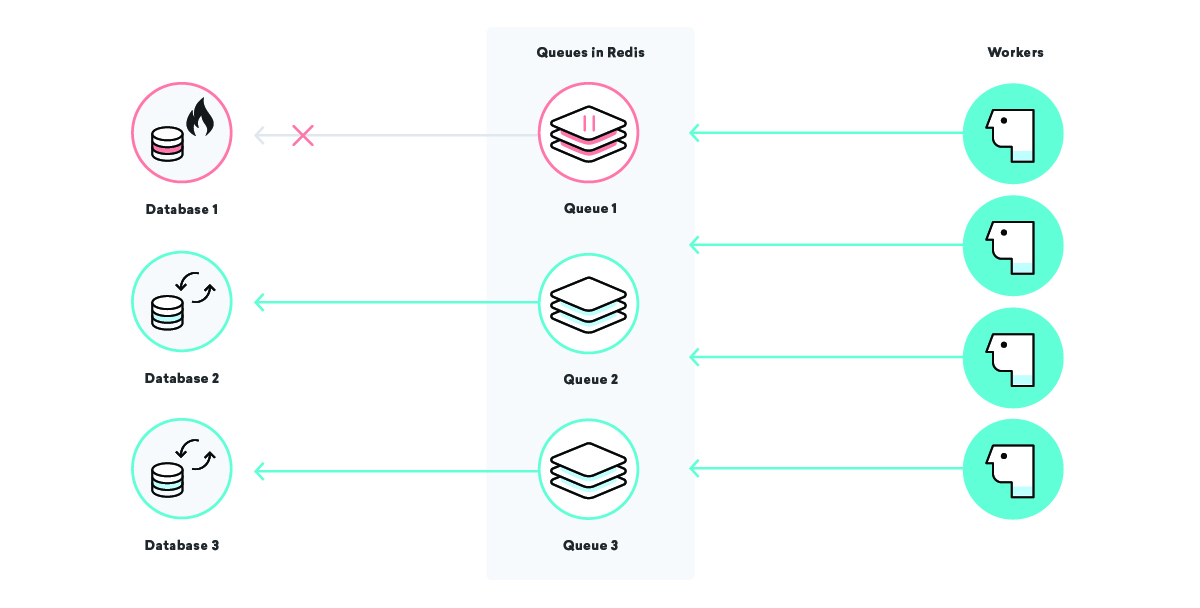
¿Qué sucede con el procesamiento de datos de Consolidated Widgets de nuestra empresa de ejemplo cuando la base de datos de Global Gizmos no funciona?
En este escenario, si nuestra estrategia de entrega al menos una vez está en juego, esperaríamos que todos los trabajos de procesamiento de datos para Global Gizmos se vuelvan a intentar una y otra vez hasta que tengan éxito. Esto es genial: no perderemos ningún dato, incluso si su base de datos está inactiva. Sin embargo, para Consolidated Widgets, puede que no sea tan bueno: si los trabajadores constantemente vuelven a intentarlo y fallan, es posible que estén demasiado ocupados para procesar el trabajo de Consolidated Widgets de manera oportuna.
Podemos arreglar esto usando nombres de cola bien elegidos y pausando ciertas colas según sea necesario. Con esto en nuestro cinturón de herramientas, podemos aliviar la tensión en piezas de infraestructura de manera quirúrgica. En nuestro escenario anterior, una vez que sabemos que la base de datos de Global Gizmos está inactiva, podemos pausar su cola de procesamiento de datos hasta que sepamos que está nuevamente activa, ¡asegurándonos de que una interrupción específica no afecte a ningún otro cliente!

Esperar es doloroso
¿Qué pasa si Consolidated Widgets y Global Gizmos envían campañas de correo electrónico a 50 millones de usuarios cada uno, con 5 minutos de diferencia? ¿Quién va primero?
Los sistemas de colas de trabajo simples tienen una cola de "trabajo" simple de la que los trabajadores extraen trabajos. Una vez que tenga una buena variedad de diferentes trabajos y tipos de trabajo, probablemente pase a tener múltiples tipos de colas, cada una con diferentes prioridades o tipos de trabajadores que extraen de esas colas. En ese sentido, tenemos una variedad de colas simples para procesamiento de datos, mensajería y varias tareas de mantenimiento.
Avance rápido hasta cuando envía miles de millones de mensajes personalizados por día, una cola de "mensajes" no va a ser suficiente. ¿Qué sucede cuando esa cola crece extremadamente, como en nuestro ejemplo anterior? ¿Priorizamos los trabajos que llegaron primero?
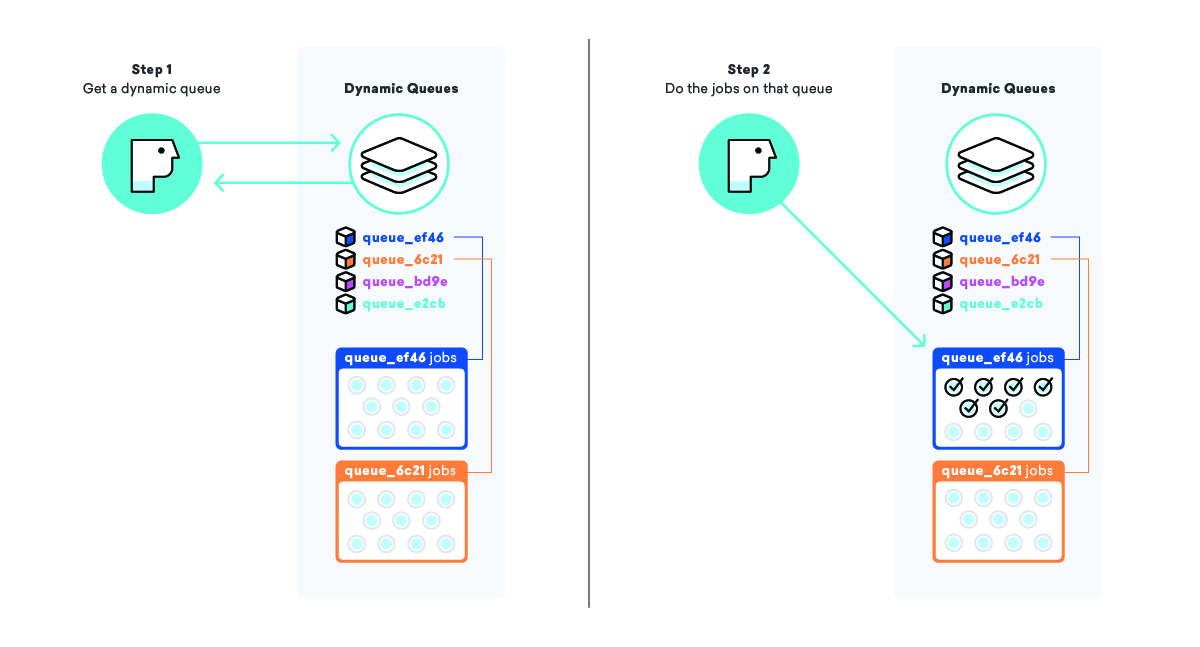
Nuestro sistema de colas dinámicas busca abordar un fenómeno llamado agotamiento de trabajos, donde un trabajo que está listo para ejecutarse espera mucho tiempo antes de ejecutarse, generalmente debido a algún tipo de prioridad. En una cola simple de "mensajería", la prioridad es simplemente el momento en que el trabajo entró en la cola, lo que significa que los trabajos agregados al final de una cola grande pueden terminar esperando durante mucho tiempo.
Cuando vamos a poner en cola una campaña y todos sus mensajes, en lugar de agregar los trabajos a una gran cola de "mensajes", creamos una cola totalmente nueva solo para esta campaña, completa con un nombre especial para que sepamos qué es y como encontrarlo Después de agregar los trabajos a la cola, tomamos nuestra lista de "colas dinámicas" y agregamos este nuevo nombre de cola al final.
Al emplear esta estrategia, podemos indicar a los trabajadores que seleccionen el nombre de una cola dinámica de la lista de "colas dinámicas" y luego procesen todos los trabajos en esa cola en particular. Esto nos permite asegurarnos de que los mensajes se envíen lo más rápido posible Y que todos nuestros clientes sean tratados con la misma prioridad.
En consecuencia, esto tiene otros beneficios, como tasas de aciertos de caché más altas y menos conexiones a bases de datos, debido al aumento en la localidad de trabajo para trabajadores particulares. ¡Todos ganan!
Tenga siempre un plan de respaldo
¿Qué sucede cuando una base de datos está inactiva, algunas colas están en pausa y las colas de trabajos comienzan a llenarse?
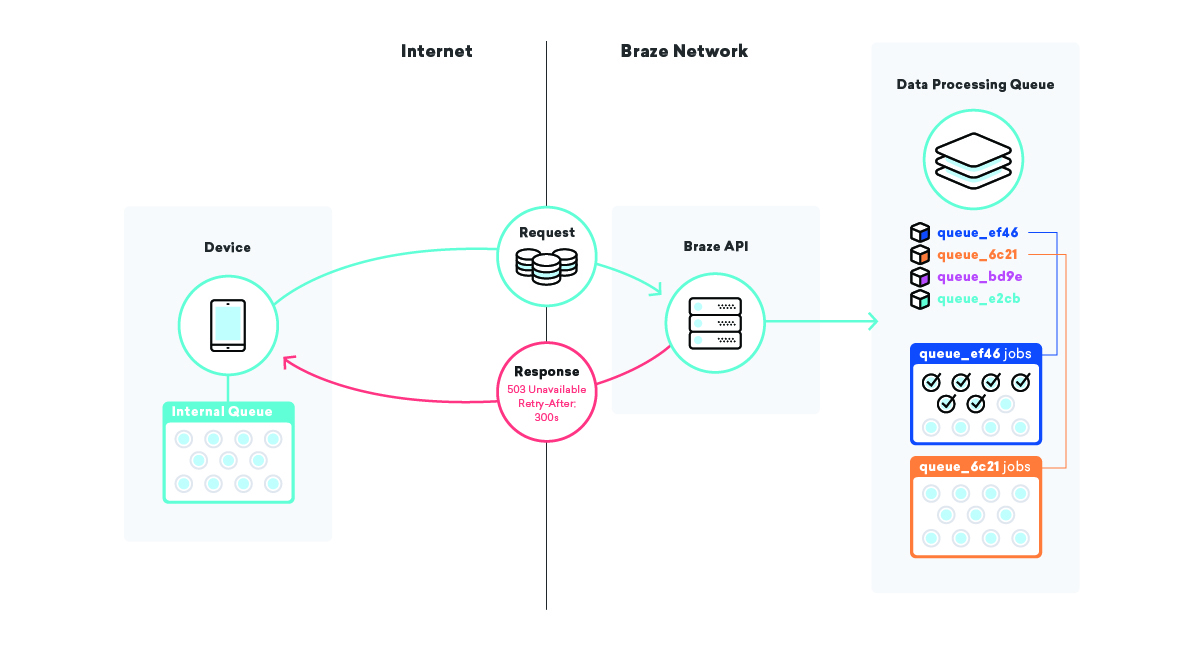
A veces, las piezas importantes de la infraestructura simplemente mueren. Tenemos secundarios y copias de seguridad, pero el tiempo que se tarda en promover la infraestructura de copia de seguridad casi nunca es cero. Tener varias capas de colas en toda la infraestructura de la aplicación puede ser muy útil para mitigar el impacto de este tipo de eventos.
Una de esas estrategias que empleamos es hacer cola en los propios dispositivos. Millones y millones de dispositivos tienen diferentes aplicaciones que utilizan un SDK de Braze y, en esas aplicaciones, utilizamos una cola para enviar datos a nuestras API.
Cuando nuestro SDK va a enviar esos datos y falla, por cualquier motivo, el SDK pone en cola un reintento utilizando un algoritmo de retroceso exponencial hasta que tiene éxito. Esta estrategia minimiza el impacto de las fallas de infraestructura o código, ya que los dispositivos simplemente pondrán en cola sus propios datos y los enviarán a Braze cuando todo vuelva a estar en línea.
Moverse rápido y no romper cosas
Al final del día, nuestro objetivo es enviar mensajes personalizados e hiperenfocados mejor que nadie, y eso implica moverse rápidamente, ser resistente y hacer todo bien. Las colas de trabajo están en el corazón de la infraestructura de Braze, por lo que siempre estamos observando nuestro desempeño, empleando las mejores prácticas y experimentando con nuevas estrategias y técnicas avanzadas para ser los mejores en el juego.
Si este tipo de ingeniería de sistemas de alto rendimiento y baja latencia en el espacio de la automatización de marketing te entusiasma, entonces definitivamente deberías consultar nuestra bolsa de trabajo.