
Aprendizaje efectivo: el futuro cercano de la IA
Publicado: 2017-11-09Estas técnicas de aprendizaje efectivas no son nuevas técnicas de aprendizaje profundo/aprendizaje automático, sino que mejoran las técnicas existentes como trucos
Ciertamente, no hay duda de que el futuro final de la IA es alcanzar y superar la inteligencia humana. Pero esta es una hazaña descabellada de lograr. Incluso los más optimistas entre nosotros apuestan a que la IA de nivel humano (AGI o ASI) estará tan lejos como dentro de 10 a 15 años, y los escépticos incluso están dispuestos a apostar que tomará siglos, si es que es posible. Bueno, de eso no se trata el post.
Aquí vamos a hablar sobre un futuro más tangible y cercano y discutir los potentes y emergentes algoritmos y técnicas de IA que, en nuestra opinión, van a dar forma al futuro cercano de la IA.
La IA ha comenzado a mejorar a los humanos en algunas tareas seleccionadas y específicas. Por ejemplo, vencer a los médicos en el diagnóstico de cáncer de piel y derrotar a los jugadores de Go en el campeonato mundial. Pero los mismos sistemas y modelos fallarán al realizar las tareas diferentes de las que fueron entrenados para resolver. Esta es la razón por la que, a largo plazo, un sistema generalmente inteligente que realiza un conjunto de tareas de manera eficiente sin necesidad de reevaluación se denomina futuro de la IA.
Pero, en el futuro cercano de la IA, mucho antes de que surja el AGI, ¿cómo es posible que los científicos hagan que el algoritmo impulsado por la IA supere los problemas que enfrentan hoy para salir de los laboratorios y convertirse en objetos de uso diario?
Cuando miras a tu alrededor, la IA está ganando un castillo a la vez (lee nuestras publicaciones sobre cómo la IA está superando a los humanos, parte uno y parte dos). ¿Qué podría salir mal en un juego de ganar-ganar? Los humanos están produciendo más y más datos (que es el forraje que consume la IA) con el tiempo y nuestras capacidades de hardware también están mejorando. Después de todo, los datos y una mejor computación son las razones por las que la revolución del aprendizaje profundo comenzó en 2012, ¿verdad? La verdad es que más rápido que el crecimiento de los datos y la computación es el crecimiento de las expectativas humanas. Los científicos de datos tendrían que pensar en soluciones más allá de lo que existe en este momento para resolver problemas del mundo real. Por ejemplo, la clasificación de imágenes, como pensaría la mayoría de la gente, es un problema científicamente resuelto (si resistimos la tentación de decir 100% de precisión o GTFO).
Podemos clasificar imágenes (digamos en imágenes de gatos o imágenes de perros) que coincidan con la capacidad humana usando IA. Pero, ¿se puede usar esto para casos de uso del mundo real? ¿Puede la IA ofrecer una solución para problemas más prácticos a los que se enfrentan los humanos? En algunos casos, sí, pero en muchos casos aún no hemos llegado.
Lo guiaremos a través de los desafíos que son los principales obstáculos para desarrollar una solución del mundo real utilizando IA. Supongamos que desea clasificar imágenes de perros y gatos. Usaremos este ejemplo a lo largo de la publicación.

Nuestro algoritmo de ejemplo: Clasificación de las imágenes de perros y gatos
El siguiente gráfico resume los desafíos:

Desafíos involucrados en el desarrollo de una IA del mundo real
Analicemos estos desafíos en detalle:
Aprendiendo con menos datos
- Los datos de entrenamiento que consumen los algoritmos de aprendizaje profundo más exitosos requieren que se etiqueten de acuerdo con el contenido o la característica que contienen. Este proceso se llama anotación.
- Los algoritmos no pueden usar los datos que se encuentran naturalmente a su alrededor. La anotación de unos pocos cientos (o unos pocos miles de puntos de datos) es fácil, pero nuestro algoritmo de clasificación de imágenes a nivel humano tomó un millón de imágenes anotadas para aprender bien.
- Entonces, la pregunta es si es posible anotar un millón de imágenes. Si no, ¿cómo puede la IA escalar con una menor cantidad de datos anotados?
Resolver diversos problemas del mundo real
- Si bien los conjuntos de datos son fijos, el uso en el mundo real es más diverso (por ejemplo, un algoritmo entrenado en imágenes en color puede fallar gravemente en imágenes en escala de grises a diferencia de los humanos).
- Si bien hemos mejorado los algoritmos de Computer Vision para detectar objetos para que coincidan con los humanos. Pero como se mencionó anteriormente, estos algoritmos resuelven un problema muy específico en comparación con la inteligencia humana, que es mucho más genérica en muchos sentidos.
- Nuestro algoritmo de IA de ejemplo, que clasifica gatos y perros, no podrá identificar una especie rara de perro si no se alimenta con imágenes de esa especie.
Ajuste de los datos incrementales
- Otro desafío importante son los datos incrementales. En nuestro ejemplo, si estamos tratando de reconocer gatos y perros, podríamos entrenar nuestra IA para una cantidad de imágenes de gatos y perros de diferentes especies mientras implementamos por primera vez. Pero en el descubrimiento de una nueva especie por completo, necesitamos entrenar el algoritmo para reconocer "Kotpies" junto con las especies anteriores.
- Si bien las nuevas especies pueden ser más similares a otras de lo que pensamos y pueden entrenarse fácilmente para adaptar el algoritmo, hay puntos en los que esto es más difícil y requiere un nuevo entrenamiento y una reevaluación completos.
- La pregunta es ¿podemos hacer que la IA sea al menos adaptable a estos pequeños cambios?
Para hacer que la IA se pueda usar de inmediato, la idea es resolver los desafíos antes mencionados mediante un conjunto de enfoques llamados Aprendizaje efectivo (tenga en cuenta que no es un término oficial, solo lo estoy inventando para evitar escribir Meta-Learning, Transfer Learning, Pocos Shot Learning, Adversarial Learning y Multi-Task Learning todo el tiempo). Nosotros, en ParallelDots, ahora estamos utilizando estos enfoques para resolver problemas específicos con la IA, ganando pequeñas batallas mientras nos preparamos para una IA más integral para conquistar guerras más grandes. Permítanos presentarle estas técnicas una a la vez.
Cabe destacar que la mayoría de estas técnicas de Aprendizaje Efectivo no son algo nuevo. Simplemente están viendo un resurgimiento ahora. Los investigadores de SVM (Support Vector Machines) han estado utilizando estas técnicas durante mucho tiempo. El aprendizaje adversario, por otro lado, es algo que surgió del trabajo reciente de Goodfellow en GAN y Neural Reasoning es un nuevo conjunto de técnicas para las cuales los conjuntos de datos han estado disponibles muy recientemente. Profundicemos en cómo estas técnicas ayudarán a dar forma al futuro de la IA.
Transferencia de aprendizaje
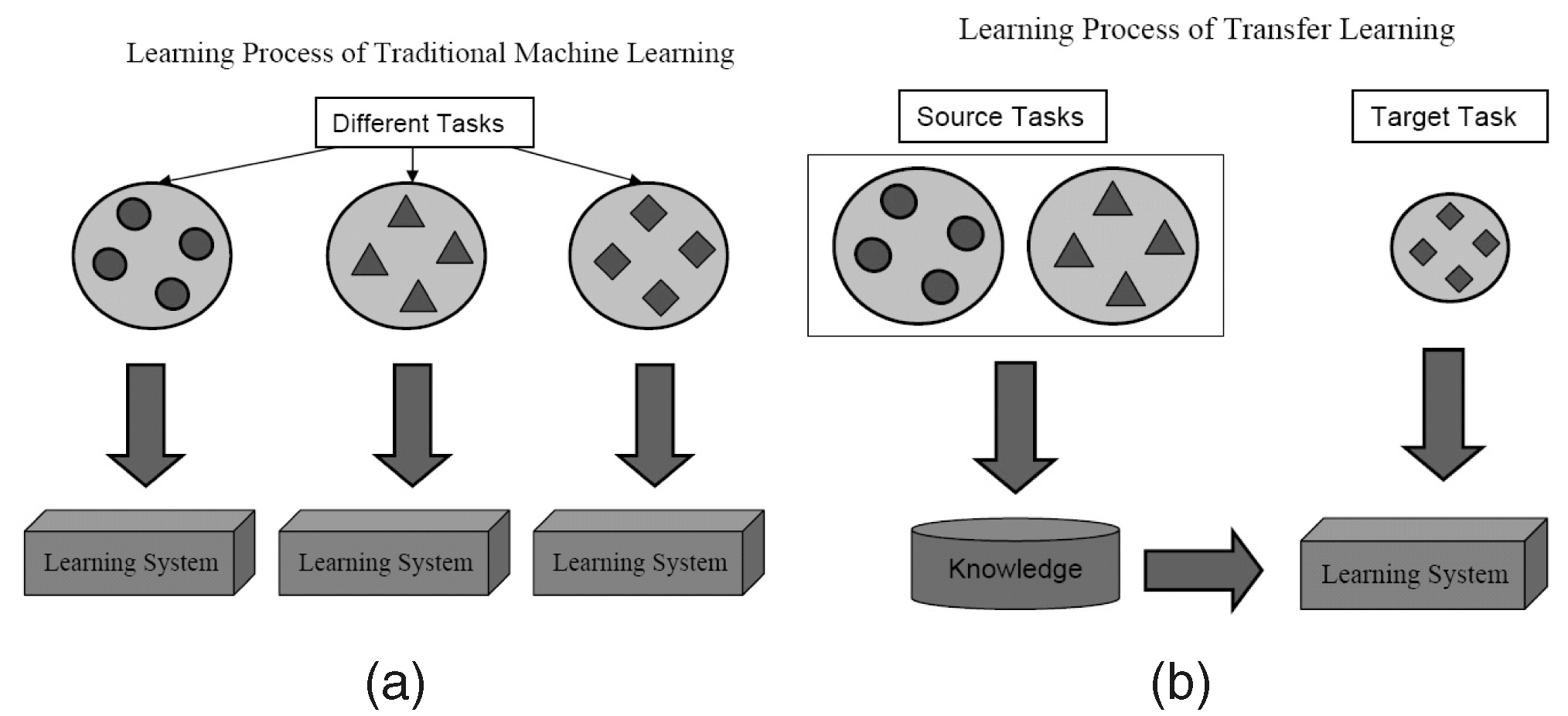
¿Qué es?
Como sugiere el nombre, el aprendizaje se transfiere de una tarea a otra dentro del mismo algoritmo en Transfer Learning. Los algoritmos entrenados en una tarea (tarea de origen) con un conjunto de datos más grande se pueden transferir con o sin modificaciones como parte del algoritmo que intenta aprender una tarea diferente (tarea de destino) en un conjunto de datos (relativamente) más pequeño.
Algunos ejemplos
El uso de parámetros de un algoritmo de clasificación de imágenes como extractor de características en diferentes tareas, como la detección de objetos, es una aplicación simple de Transfer Learning. Por el contrario, también se puede utilizar para realizar tareas complejas. El algoritmo que Google desarrolló para clasificar la retinopatía diabética mejor que los médicos hace un tiempo atrás se hizo usando Transfer Learning. Sorprendentemente, el detector de retinopatía diabética era en realidad un clasificador de imágenes del mundo real (clasificador de imágenes de perros/gatos) Transfer Learning para clasificar escaneos oculares.
¡Dime más!
Encontrará a los científicos de datos llamando a las partes transferidas de las redes neuronales desde la tarea de origen a la de destino como redes preentrenadas en la literatura de aprendizaje profundo. El ajuste fino se produce cuando los errores de la tarea de destino se propagan ligeramente hacia atrás en la red preentrenada en lugar de utilizar la red preentrenada sin modificar. Se puede ver una buena introducción técnica a Transfer Learning en Computer Vision aquí. Este concepto simple de Aprendizaje por Transferencia es muy importante en nuestro conjunto de metodologías de Aprendizaje Efectivo.
Recomendado para ti:

Cómo Metaverse transformará la industria automotriz india

¿Qué significa la disposición contra la especulación para las nuevas empresas indias?

Cómo las empresas emergentes de Edtech están ayudando a la fuerza laboral de la India a mejorar y prepararse para el futuro...

Acciones tecnológicas de la nueva era esta semana: los problemas de Zomato continúan, EaseMyTrip publica...

Startups indias toman atajos en busca de financiación

La plataforma de marketing digital Logicserve obtiene fondos de INR 80 Cr, cambia de marca como LS Dig...
Aprendizaje multitarea
¿Qué es?
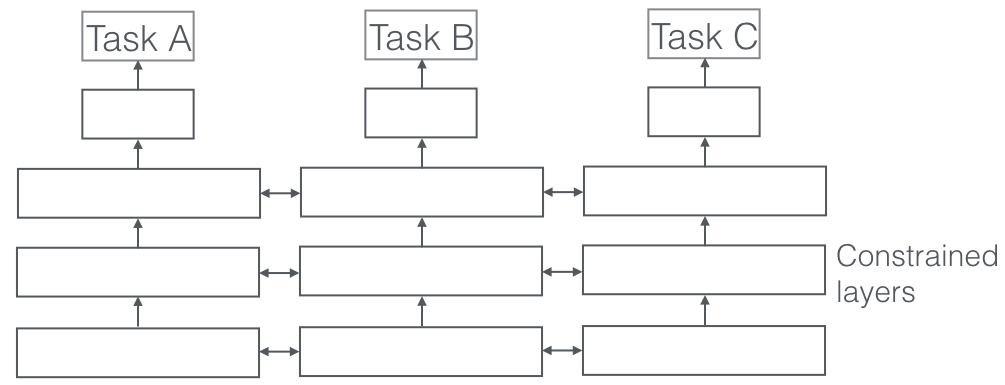

En el aprendizaje multitarea, se resuelven múltiples tareas de aprendizaje al mismo tiempo, mientras se aprovechan los puntos en común y las diferencias entre las tareas. Es sorprendente, pero a veces aprender dos o más tareas juntas (también llamadas tarea principal y tareas auxiliares) puede mejorar los resultados de las tareas. Tenga en cuenta que no todos los pares, tríos o cuartetos de tareas pueden considerarse auxiliares. Pero cuando funciona, es un incremento gratuito en la precisión.
Algunos ejemplos
Por ejemplo, en ParallelDots, nuestros clasificadores de detección de sentimientos, intenciones y emociones se entrenaron como aprendizaje multitarea, lo que aumentó su precisión en comparación con si los entrenáramos por separado. El mejor sistema de etiquetado de roles semánticos y etiquetado de POS en NLP que conocemos es un sistema de aprendizaje multitarea, por lo que es uno de los mejores sistemas para la segmentación semántica y de instancias en visión artificial. Google ideó aprendices multitarea multimodales (un modelo para gobernarlos a todos) que pueden aprender de conjuntos de datos de visión y texto en la misma toma.
¡Dime más!
Un aspecto muy importante del aprendizaje multitarea que se ve en las aplicaciones del mundo real es que, entrenando cualquier tarea para que sea a prueba de balas, debemos respetar muchos dominios de los que provienen los datos (también llamado adaptación de dominio). Un ejemplo en nuestros casos de uso de gatos y perros será un algoritmo que puede reconocer imágenes de diferentes fuentes (por ejemplo, cámaras VGA y cámaras HD o incluso cámaras infrarrojas). En tales casos, se puede agregar una pérdida auxiliar de clasificación de dominio (de donde provienen las imágenes) a cualquier tarea y luego la máquina aprende de tal manera que el algoritmo sigue mejorando en la tarea principal (clasificar imágenes en imágenes de gatos o perros), pero empeorando deliberadamente en la tarea auxiliar (esto se hace retropropagando el gradiente de error inverso de la tarea de clasificación de dominio). La idea es que el algoritmo aprenda características discriminatorias para la tarea principal, pero olvide características que diferencian dominios y esto lo mejoraría. El aprendizaje multitarea y sus primos de adaptación de dominio son una de las técnicas de aprendizaje efectivo más exitosas que conocemos y tienen un papel importante que desempeñar en la configuración del futuro de la IA.
Aprendizaje adversario
¿Qué es?
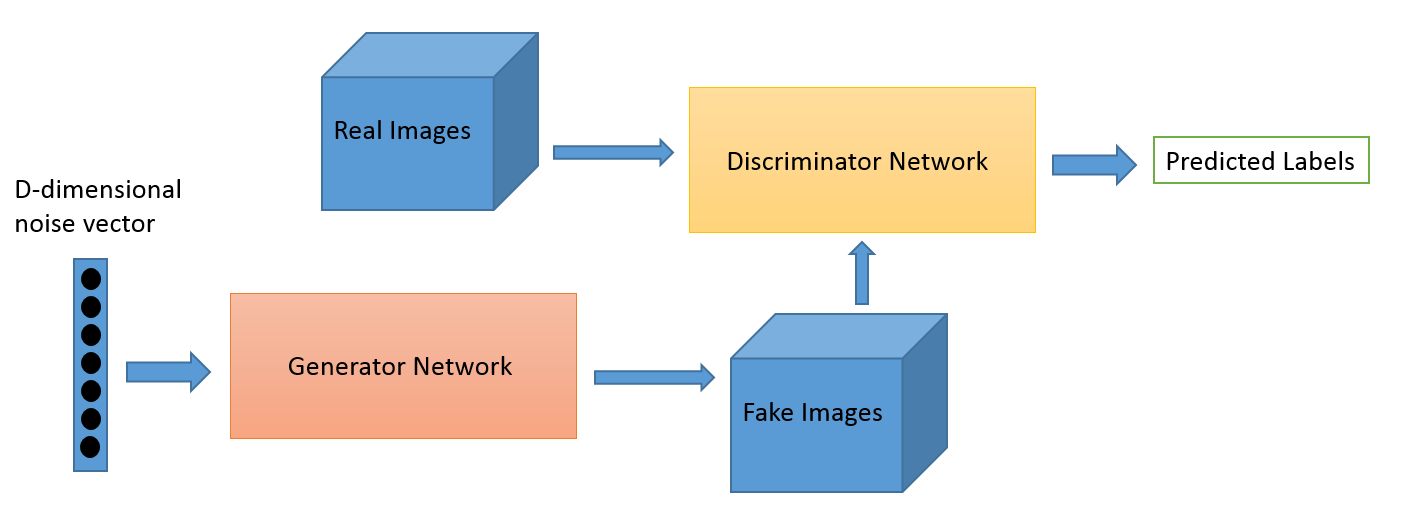
El aprendizaje adversario como campo evolucionó a partir del trabajo de investigación de Ian Goodfellow. Si bien las aplicaciones más populares de Adversarial Learning son, sin duda, Generative Adversarial Networks (GAN), que se pueden usar para generar imágenes sorprendentes, existen muchas otras formas de este conjunto de técnicas. Normalmente, esta técnica inspirada en la teoría de juegos tiene dos algoritmos, un generador y un discriminador, cuyo objetivo es engañarse mutuamente mientras se entrenan. El generador se puede usar para generar nuevas imágenes novedosas como discutimos, pero también puede generar representaciones de cualquier otro dato para ocultar detalles del discriminador. Esto último es por lo que este concepto nos interesa tanto.
Algunos ejemplos
Este es un campo nuevo y la capacidad de generación de imágenes es probablemente en lo que se centran la mayoría de las personas interesadas, como los astrónomos. Pero creemos que esto también dará lugar a casos de uso más nuevos, como explicaremos más adelante.
¡Dime más!
El juego de adaptación de dominio se puede mejorar usando la pérdida de GAN. La pérdida auxiliar aquí es un sistema GAN en lugar de una clasificación de dominio pura, donde un discriminador intenta clasificar de qué dominio provienen los datos y un componente generador intenta engañarlo presentando ruido aleatorio como datos. En nuestra experiencia, esto funciona mejor que la simple adaptación de dominio (que también es más errática para el código).
Pocos tiros de aprendizaje
¿Qué es?
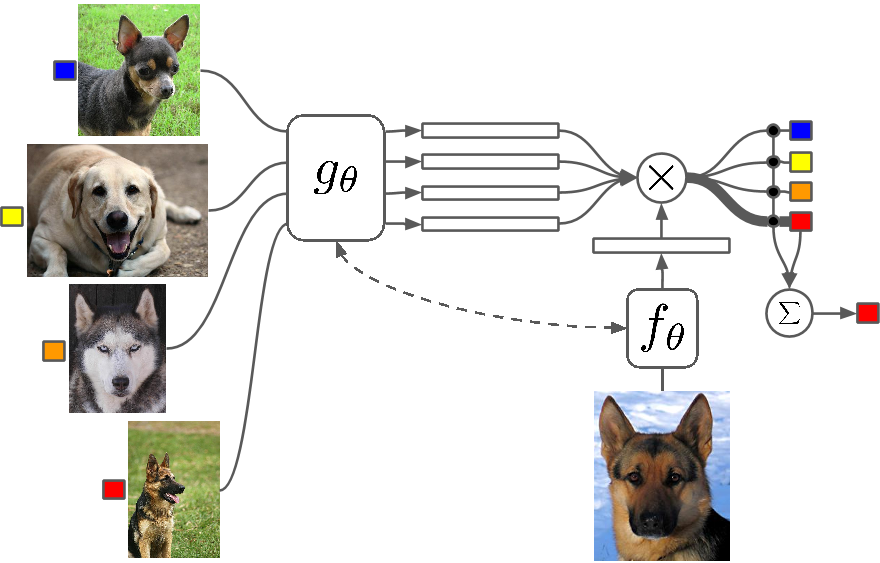
Few Shot Learning es un estudio de técnicas que hacen que los algoritmos de aprendizaje profundo (o cualquier algoritmo de aprendizaje automático) aprendan con menos ejemplos en comparación con lo que haría un algoritmo tradicional. One Shot Learning es básicamente aprender con un ejemplo de una categoría, inductivamente k-shot learning significa aprender con k ejemplos de cada categoría.
Algunos ejemplos
Pocos Shot Learning como campo está viendo una afluencia de artículos en todas las principales conferencias de Deep Learning y ahora hay conjuntos de datos específicos para comparar los resultados, al igual que MNIST y CIFAR para el aprendizaje automático normal. One-shot Learning está viendo una serie de aplicaciones en ciertas tareas de clasificación de imágenes, como la detección y representación de características.
¡Dime más!
Hay varios métodos que se utilizan para el aprendizaje de pocos disparos, incluido el aprendizaje de transferencia, el aprendizaje de tareas múltiples y el metaaprendizaje como todo o parte del algoritmo. Hay otras formas, como tener una función de pérdida inteligente, usar arquitecturas dinámicas o usar trucos de optimización. Zero Shot Learning, una clase de algoritmos que afirman predecir respuestas para categorías que el algoritmo ni siquiera ha visto, son básicamente algoritmos que pueden escalar con un nuevo tipo de datos.
Meta-aprendizaje
¿Qué es?

Meta-Learning es exactamente lo que parece, un algoritmo que entrena de tal manera que, al ver un conjunto de datos, produce un nuevo predictor de aprendizaje automático para ese conjunto de datos en particular. La definición es muy futurista si le das un primer vistazo. Te sientes "¡guau! eso es lo que hace un científico de datos” y está automatizando el “trabajo más sexy del siglo XXI”, y en algunos sentidos, los Meta-Learners han comenzado a hacer eso.
Algunos ejemplos
El metaaprendizaje se ha convertido recientemente en un tema candente en el aprendizaje profundo, con una gran cantidad de trabajos de investigación que se publican, más comúnmente utilizando la técnica para la optimización de hiperparámetros y redes neuronales, encontrando buenas arquitecturas de red, reconocimiento de imágenes de pocos disparos y aprendizaje de refuerzo rápido.
¡Dime más!
Algunas personas se refieren a esta automatización completa de decidir tanto los parámetros como los hiperparámetros, como la arquitectura de red, como autoML y es posible que encuentre personas que se refieren a Meta Learning y AutoML como campos diferentes. A pesar de todo el revuelo que los rodea, la verdad es que los metaaprendices siguen siendo algoritmos y vías para escalar el aprendizaje automático con el aumento de la complejidad y la variedad de los datos.
La mayoría de los artículos de metaaprendizaje son trucos inteligentes que, según Wikipedia, tienen las siguientes propiedades:
- El sistema debe incluir un subsistema de aprendizaje, que se adapta con la experiencia.
- La experiencia se gana explotando el metaconocimiento extraído en un episodio de aprendizaje anterior en un solo conjunto de datos o de diferentes dominios o problemas.
- El sesgo de aprendizaje debe elegirse dinámicamente.
Básicamente, el subsistema es una configuración que se adapta cuando se le introducen los metadatos de un dominio (o un dominio completamente nuevo). Estos metadatos pueden informar sobre el aumento del número de clases, la complejidad, el cambio de colores y texturas y objetos (en imágenes), estilos, patrones de lenguaje (lenguaje natural) y otras características similares. Consulte algunos documentos geniales aquí: jerarquías compartidas de metaaprendizaje y metaaprendizaje mediante convoluciones temporales. También puede crear algoritmos Few Shot o Zero Shot utilizando arquitecturas de metaaprendizaje. El metaaprendizaje es una de las técnicas más prometedoras que ayudará a dar forma al futuro de la IA.
Razonamiento neuronal
¿Qué es?

El razonamiento neuronal es la próxima gran novedad en los problemas de clasificación de imágenes. El razonamiento neuronal es un paso por encima del reconocimiento de patrones donde los algoritmos van más allá de la idea de simplemente identificar y clasificar texto o imágenes. Neural Reasoning está resolviendo preguntas más genéricas en análisis de texto o análisis visual. Por ejemplo, la siguiente imagen representa un conjunto de preguntas que Neural Reasoning puede responder a partir de una imagen.
¡Dime más!
Este nuevo conjunto de técnicas surge después del lanzamiento del conjunto de datos bAbi de Facebook o el reciente conjunto de datos CLEVR. Las técnicas que surgen para descifrar las relaciones y no solo los patrones tienen un inmenso potencial para resolver no solo el razonamiento neuronal, sino también muchos otros problemas difíciles, incluidos los problemas de aprendizaje de pocos disparos.
Volver
Ahora que sabemos cuáles son las técnicas, retrocedamos y veamos cómo resuelven los problemas básicos con los que comenzamos. La siguiente tabla ofrece una instantánea de las capacidades de las técnicas de aprendizaje efectivo para abordar los desafíos:
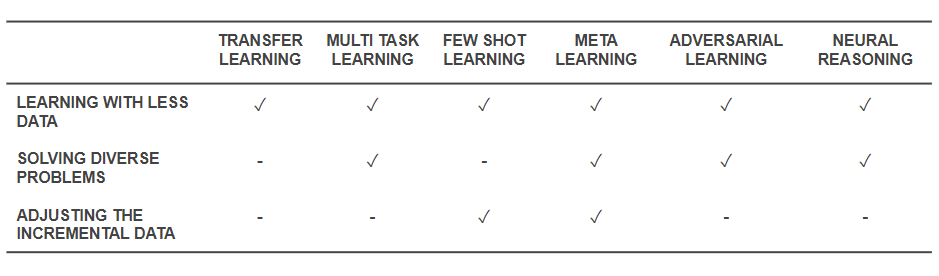
Capacidades de las técnicas de aprendizaje efectivo
- Todas las técnicas mencionadas anteriormente ayudan a resolver el entrenamiento con una menor cantidad de datos de una forma u otra. Si bien Meta-Learning brindaría arquitecturas que simplemente se moldearían con datos, Transfer Learning está haciendo que el conocimiento de algún otro dominio sea útil para compensar una menor cantidad de datos. Few Shot Learning se dedica al problema como disciplina científica. El aprendizaje adversario puede ayudar a mejorar los conjuntos de datos.
- Las arquitecturas de adaptación de dominio (un tipo de aprendizaje multitarea), aprendizaje adversario y (a veces) metaaprendizaje ayudan a resolver los problemas que surgen de la diversidad de datos.
- Meta-Learning y Few Shot Learning ayudan a resolver problemas de datos incrementales.
- Los algoritmos de razonamiento neuronal tienen un potencial inmenso para resolver problemas del mundo real cuando se incorporan como Meta-Learners o Few Shot Learners.
Tenga en cuenta que estas técnicas de aprendizaje efectivo no son técnicas nuevas de aprendizaje profundo/aprendizaje automático, sino que aumentan las técnicas existentes como trucos para que sean más rentables. Por lo tanto, seguirá viendo nuestras herramientas habituales, como las redes neuronales convolucionales y las LSTM, en acción, pero con especias añadidas. Estas técnicas de aprendizaje efectivo que funcionan con menos datos y realizan muchas tareas a la vez pueden ayudar a facilitar la producción y comercialización de productos y servicios basados en IA. En ParallelDots, reconocemos el poder del aprendizaje eficiente y lo incorporamos como una de las características principales de nuestra filosofía de investigación.
Esta publicación de Parth Shrivastava apareció por primera vez en el blog ParallelDots y se ha reproducido con permiso.