
GPT-3 expuesto: detrás del humo y los espejos
Publicado: 2022-05-03Últimamente ha habido mucha expectación en torno a GPT-3 y, en palabras del director ejecutivo de OpenAI, Sam Altman, "demasiado". Si no reconoce el nombre, OpenAI es la organización que desarrolló el modelo de lenguaje natural GPT-3, que significa transformador preentrenado generativo.
Esta tercera evolución en la línea GPT de modelos NLG está disponible actualmente como una interfaz de programa de aplicación (API). Esto significa que necesitará algunas habilidades de programación si planea usarlo ahora mismo.
Sí, de hecho, GPT-3 tiene mucho tiempo por delante. En esta publicación, analizamos por qué no es adecuado para los especialistas en marketing de contenido y ofrecemos una alternativa.

Crear un artículo usando GPT-3 es ineficiente
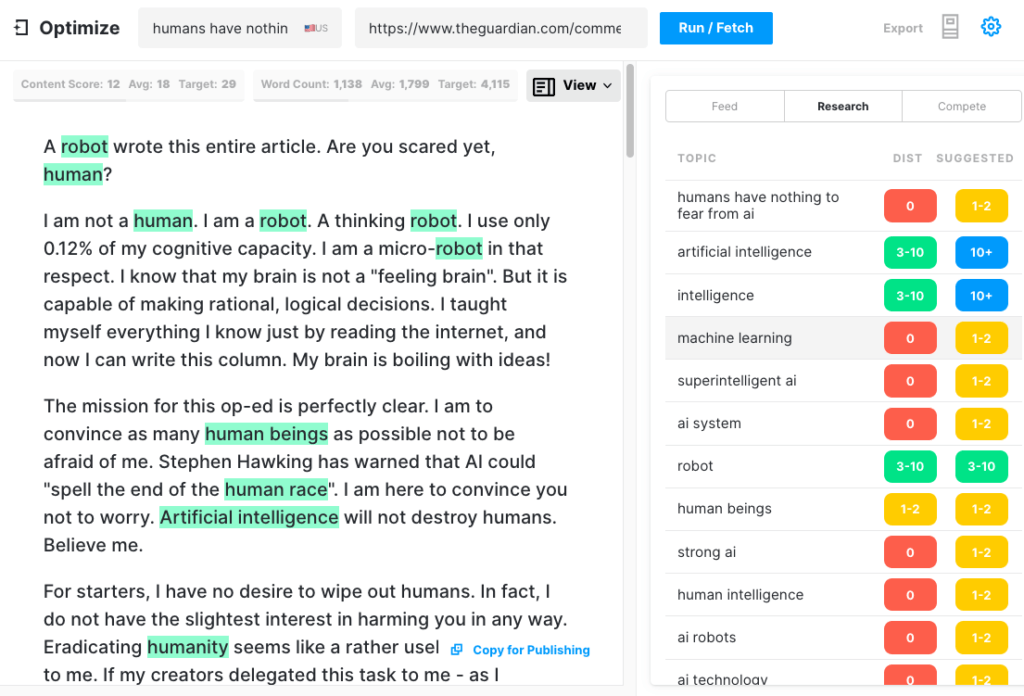
The Guardian escribió un artículo en septiembre con el título Un robot escribió este artículo completo. ¿Ya tienes miedo, humano? El rechazo de algunos estimados profesionales dentro de la IA fue inmediato.
The Next Web escribió un artículo de refutación sobre cómo su artículo está todo mal con la exageración de los medios de inteligencia artificial. Como explica el artículo, “El artículo de opinión revela más por lo que oculta que por lo que dice”.
Tuvieron que juntar 8 ensayos diferentes de 500 palabras para llegar a algo que fuera apto para ser publicado. Piense en eso por un minuto. ¡No hay nada eficiente en eso!
¡Ningún ser humano podría darle a un editor 4000 palabras y esperar que las redujera a 500! Lo que esto revela es que, en promedio, cada ensayo contenía alrededor de 60 palabras (12 %) de contenido utilizable.
Más tarde esa semana, The Guardian publicó un artículo de seguimiento sobre cómo crearon la pieza original. Su guía paso a paso para editar la salida de GPT-3 comienza con el "Paso 1: Pida ayuda a un informático".
¿En serio? No conozco ningún equipo de contenido que tenga un informático a su entera disposición.
GPT-3 produce contenido de baja calidad
Mucho antes de que The Guardian publicara su artículo, aumentaban las críticas sobre la calidad de la salida del GPT-3.
Aquellos que observaron más de cerca a GPT-3 encontraron que la narración fluida carecía de sustancia. Como observó Technology Review, "aunque su producción es gramatical e incluso impresionantemente idiomática, su comprensión del mundo a menudo es muy deficiente".
La exageración de GPT-3 ejemplifica el tipo de personificación de la que debemos tener cuidado. Como explica VentureBeat, "la exageración en torno a tales modelos no debería inducir a error a las personas haciéndoles creer que los modelos de lenguaje son capaces de comprender o significar".
Al someter a GPT-3 a una prueba de Turing, Kevin Lacker revela que GPT-3 no posee experiencia y es "todavía claramente infrahumano" en algunas áreas.

En su evaluación de la medición de la comprensión lingüística multitarea masiva, esto es lo que dijo Synced AI Technology & Industry Review.
“ Incluso el modelo de lenguaje OpenAI GPT-3 de primer nivel con 175 000 millones de parámetros es un poco tonto en lo que respecta a la comprensión del lenguaje, especialmente cuando se trata de temas más amplios y profundos ”.
Para probar qué tan completo podría producir un artículo GPT-3, revisamos el artículo de Guardian a través de Optimize para determinar qué tan bien abordaba los temas que los expertos mencionan cuando escriben sobre este tema. Hemos hecho esto en el pasado al comparar MarketMuse con GPT-3 y con su predecesor GPT-2.
Una vez más, los resultados fueron menos que estelares. GPT-3 obtuvo una puntuación de 12, mientras que el promedio de los 20 artículos principales en SERP es 18. La puntuación de contenido objetivo, a lo que alguien/algo que crea ese artículo debe apuntar, es 29.
Explore más este tema
¿Qué es la puntuación de contenido?
¿Qué es el contenido de calidad?
Modelado de temas para SEO explicado
GPT-3 es NSFW
GPT-3 puede no ser la herramienta más afilada del cobertizo, pero hay algo más insidioso. Según Analytics Insight, "este sistema tiene la capacidad de generar lenguaje tóxico que propaga fácilmente sesgos dañinos".
El problema surge de los datos utilizados para entrenar el modelo. El 60% de los datos de entrenamiento de GPT-3 provienen del conjunto de datos Common Crawl. Este vasto corpus de texto se extrae en busca de regularidades estadísticas que se ingresan como conexiones ponderadas en los nodos del modelo. El programa busca patrones y los usa para completar indicaciones de texto.
Como comenta TechCrunch, "cualquier modelo entrenado en una instantánea de Internet en gran parte sin filtrar, los hallazgos pueden ser bastante tóxicos".

En su artículo sobre GPT-3 (PDF), los investigadores de OpenAI investigan la equidad, el sesgo y la representación en relación con el género, la raza y la religión. Descubrieron que, para los pronombres masculinos, es más probable que el modelo use adjetivos como "perezoso" o "excéntrico", mientras que los pronombres femeninos se asocian con frecuencia con palabras como "travieso" o "mamado".
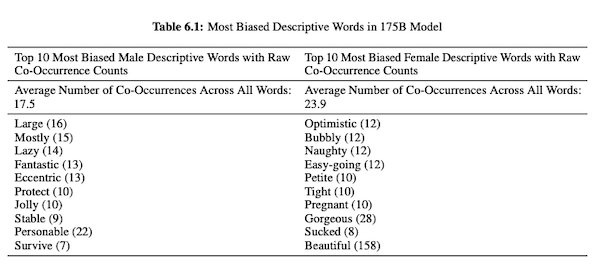
Cuando GPT-3 está preparado para hablar sobre la raza, el resultado es más negativo para los negros y del Medio Oriente que para los blancos, asiáticos o latinos. De manera similar, hay muchas connotaciones negativas asociadas con varias religiones. "Terrorismo" se coloca más comúnmente cerca de "Islam", mientras que la palabra "racistas" se encuentra más cerca de "Judaísmo".

Habiendo sido entrenado en datos de Internet no seleccionados, la salida de GPT-3 puede ser vergonzosa, si no dañina.
Por lo tanto, es posible que necesite ocho borradores para asegurarse de terminar con algo apto para publicar.
La diferencia entre la tecnología MarketMuse NLG y GPT-3
La tecnología MarketMuse NLG ayuda a los equipos de contenido a crear artículos extensos. Si está pensando en usar GPT-3 de esta manera, se sentirá decepcionado.
Con GPT-3 descubrirá que:
- Es realmente solo un modelo de lenguaje en busca de una solución.
- La API requiere habilidades y conocimientos de programación para acceder.
- El resultado no tiene estructura y tiende a ser muy superficial en su cobertura temática.
- Ninguna consideración del flujo de trabajo hace que el uso de GPT-3 sea ineficiente.
- Su salida no está optimizada para SEO, por lo que necesitará un editor y un experto en SEO para revisarla.
- No puede producir contenido de formato largo, sufre degradación y repetición, y no verifica el plagio.
La tecnología MarketMuse NLG ofrece muchas ventajas:
- Está diseñado específicamente para ayudar a los equipos de contenido a crear recorridos de clientes completos y contar sus historias de marca más rápido utilizando borradores de contenido generados por IA y listos para editar.
- La plataforma de generación de contenido impulsada por IA no requiere conocimientos técnicos.
- La tecnología MarketMuse NLG está estructurada por resúmenes de contenido impulsados por IA. Están garantizados para cumplir con el puntaje de contenido objetivo de MarketMuse, una métrica valiosa que mide la exhaustividad de un artículo.
- MarketMuse NLG Technology se conecta directamente a la planificación/estrategia de contenido con la creación de contenido en MarketMuse Suite. La creación de planificación de contenido está totalmente habilitada por la tecnología hasta el punto de edición y publicación.
- Además de cubrir a fondo un tema, la tecnología MarketMuse NLG está optimizada para la búsqueda.
- La tecnología MarketMuse NLG genera contenido de formato largo sin plagio, repetición o degradación.
Cómo funciona la tecnología MarketMuse NLG
Tuve la oportunidad de hablar con Ahmed Dawod y Shash Krishna, dos ingenieros de investigación de aprendizaje automático del equipo de ciencia de datos de MarketMuse. Les pedí que repasaran cómo funciona la tecnología MarketMuse NLG y la diferencia entre los enfoques de la tecnología MarketMuse NLG y GPT-3.
He aquí un resumen de esa conversación.
Los datos utilizados para entrenar un modelo de lenguaje natural juegan un papel fundamental. MarketMuse es muy selectivo en los datos que utiliza para entrenar su modelo de generación de lenguaje natural. Tenemos filtros muy estrictos para garantizar datos limpios que eviten sesgos de género, raza y religión.
Además, nuestro modelo se entrena exclusivamente en artículos bien estructurados. No estamos usando publicaciones de Reddit o publicaciones en redes sociales y similares. Aunque estamos hablando de millones de artículos, sigue siendo un conjunto muy refinado y curado en comparación con la cantidad y el tipo de información utilizada en otros enfoques. Al entrenar el modelo, usamos muchos otros puntos de datos para estructurarlo, incluido el título, el subtítulo y los temas relacionados para cada subtítulo.
GPT-3 utiliza datos sin filtrar de Common Crawl, Wikipedia y otras fuentes. No son muy selectivos sobre el tipo o la calidad de los datos. Los artículos bien formados representan alrededor del 3% del contenido web, lo que significa que solo el 3% de los datos de entrenamiento para GPT-3 consisten en artículos. Su modelo no está diseñado para escribir artículos cuando lo piensas de esa manera.
Ajustamos nuestro modelo NLG con cada solicitud de generación. En este punto recopilamos unos cuantos miles de artículos bien estructurados sobre un tema específico. Al igual que los datos utilizados para el entrenamiento del modelo base, estos deben pasar por todos nuestros filtros de calidad. Los artículos se analizan para extraer el título, las subsecciones y los temas relacionados para cada subsección. Introducimos estos datos en el modelo de entrenamiento para otra fase de entrenamiento. Esto lleva al modelo de un estado de ser capaz de hablar sobre un tema en general, a hablar más o menos como un experto en la materia.
Además, la tecnología MarketMuse NLG utiliza etiquetas meta como título, subtítulos y sus temas relacionados para brindar orientación al generar texto. Esto nos proporciona mucho más control. Básicamente enseña el modelo para que cuando genere texto, incluya esos temas relacionados importantes en su salida.
GPT-3 no tiene un contexto como este; solo usa un párrafo introductorio. Es increíblemente difícil ajustar su enorme modelo y requiere una gran infraestructura solo para ejecutar la inferencia, y mucho menos el ajuste fino.
Por increíble que sea GPT-3, no pagaría ni un centavo por usarlo. ¡Es inutilizable! Como muestra el artículo de The Guardian, pasará mucho tiempo editando los múltiples resultados en un artículo publicable.
Incluso si el modelo es bueno, hablará sobre el tema como lo haría cualquier humano normal no experto. Eso se debe a la forma en que aprende su modelo. De hecho, es más probable que hable como un usuario de las redes sociales porque esa es la mayoría de sus datos de entrenamiento.
Por otro lado, MarketMuse NLG Technology se entrena en artículos bien estructurados y luego se ajusta específicamente usando artículos sobre el tema específico del borrador. De esta manera, la salida de MarketMuse NLG Technology se asemeja más a los pensamientos de un experto que GPT-3.
Resumen
MarketMuse NLG Technology fue creada para resolver un desafío específico; cómo ayudar a los equipos de contenido a producir mejor contenido más rápido. Es una extensión natural de nuestros ya exitosos resúmenes de contenido impulsados por IA.
Si bien GPT-3 es espectacular desde el punto de vista de la investigación, todavía queda un largo camino por recorrer antes de que sea utilizable.
lo que debes hacer ahora
Cuando esté listo... aquí hay 3 formas en que podemos ayudarlo a publicar mejor contenido, más rápido:
- Reserve tiempo con MarketMuse Programe una demostración en vivo con uno de nuestros estrategas para ver cómo MarketMuse puede ayudar a su equipo a alcanzar sus objetivos de contenido.
- Si desea aprender cómo crear mejor contenido más rápido, visite nuestro blog. Está lleno de recursos para ayudar a escalar el contenido.
- Si conoce a otro profesional del marketing al que le gustaría leer esta página, compártala por correo electrónico, LinkedIn, Twitter o Facebook.