
Noindex Nofollow y Disallow: Directivas de rastreadores de búsqueda
Publicado: 2022-12-01Hay tres directivas (comandos) que puede usar para dictar cómo los motores de búsqueda descubren, almacenan y entregan información de su sitio como resultados de búsqueda:
- NoIndex: no agregar mi página a los resultados de búsqueda.
- NoFollow: no mires los enlaces de esta página.
- No permitir: No mire esta página en absoluto.
Estas directivas le permiten controlar cuáles de las páginas de su sitio pueden ser rastreadas por los motores de búsqueda y aparecer en la búsqueda.
¿Qué significa Sin índice?
La directiva noindex les dice a los rastreadores de búsqueda, como Googlebot, que no incluyan una página web en sus resultados de búsqueda.

¿Cómo se marca una página como NoIndex?
Hay dos formas de emitir una directiva noindex :
- Agregue una metaetiqueta noindex al código HTML de la página
- Devuelve un encabezado noindex en la solicitud HTTP
Al usar la metaetiqueta "sin índice" para una página, o como un encabezado de respuesta HTTP, básicamente está ocultando la página de la búsqueda.
La directiva noindex también se puede usar para bloquear solo motores de búsqueda específicos. Por ejemplo, podría bloquear a Google para que no indexe una página pero aún así permitir que Bing:
Ejemplo: bloqueo de la mayoría de los motores de búsqueda*
<meta nombre=”robots” content=”noindex”>
Ejemplo: bloqueo solo de Google
<meta nombre=”googlebot” content=”noindex”>
Tenga en cuenta: a partir de septiembre de 2019, Google ya no respeta las directivas noindex en el archivo robots.txt . Noindex ahora DEBE emitirse a través de una metaetiqueta HTML o un encabezado de respuesta HTTP. Para usuarios más avanzados, no permitir aún funciona por ahora, aunque no para todos los casos de uso.
¿Cuál es la diferencia entre noindex y nofollow?
Es una diferencia entre almacenar contenido y descubrir contenido:
noindex se aplica a nivel de página y le dice al rastreador de un motor de búsqueda que no indexe ni publique una página en los resultados de búsqueda.
nofollow se aplica a nivel de página o enlace y le dice al rastreador de un motor de búsqueda que no siga (descubra) los enlaces.
Esencialmente, la etiqueta noindex elimina una página del índice de búsqueda y un atributo nofollow elimina un enlace del gráfico de enlaces del motor de búsqueda.
NoFollow como atributo de página
El uso de nofollow a nivel de página significa que los rastreadores no seguirán ninguno de los enlaces en esa página para descubrir contenido adicional, y los rastreadores no usarán los enlaces como señales de clasificación para los sitios de destino.
<meta nombre=”robots” content=”nofollow”>
NoFollow como atributo de enlace
El uso de nofollow a nivel de enlace evita que los rastreadores exploren un enlace específico del anuncio y evita que ese enlace se use como una señal de clasificación.
La directiva nofollow se aplica a nivel de enlace usando un atributo rel dentro de la etiqueta a href:
<a href=”https://dominio.com” rel=”nofollow”>
Para Google específicamente, usar el atributo de enlace nofollow evitará que su sitio pase PageRank a las URL de destino.
¿Por qué debería marcar una página como NoFollow?
Para la mayoría de los casos de uso, no debe marcar una página completa como nofollow; bastará con marcar enlaces individuales como nofollow.
Marcaría una página completa como nofollow si no quisiera que Google viera los enlaces en la página, o si pensara que los enlaces en la página podrían dañar su sitio.
En la mayoría de los casos, las directivas generales de no seguimiento a nivel de página se utilizan cuando no tiene control sobre el contenido que se publica en una página Algunos editores de alto nivel también han aplicado de forma generalizada la directiva nofollow a sus páginas para disuadir a sus escritores de colocar enlaces patrocinados en su contenido.
¿Cómo uso las páginas NoIndex?
Marque las páginas como sin índice que probablemente no proporcionen valor a los usuarios y no deberían aparecer como resultados de búsqueda. Por ejemplo, es poco probable que las páginas que existen para la paginación muestren el mismo contenido con el tiempo.
Es poco probable que Domain.com/category/resultspage=2 muestre a un usuario mejores resultados que domain.com/category/resultspage=1 y las dos páginas solo competirían entre sí en la búsqueda. Es mejor no indexar páginas cuyo único propósito sea la paginación.
Estos son los tipos de páginas que debería considerar no indexar:
- Páginas utilizadas para la paginación
- Páginas de búsqueda interna
- Páginas de destino optimizadas para anuncios
- Ej.: solo muestra un formulario de lanzamiento y registro, no tiene navegación principal
- Ej.: Variaciones duplicadas del mismo contenido, solo utilizadas para anuncios
- Páginas de autor archivadas
- Páginas en flujos de pago
- Páginas de confirmación
- Ej: páginas de agradecimiento
- Ej: Ordenar páginas completas
- Ej: ¡Éxito! Paginas
- Algunas páginas generadas por complementos que no son relevantes para su sitio (por ejemplo, si usa un complemento de comercio pero no usa sus páginas de productos regulares)
- Páginas de administración y páginas de inicio de sesión de administrador
Marcar una página como Noindex y Nofollow
Una página marcada como noindex y nofollow impedirá que un rastreador indexe esa página y bloqueará que un rastreador explore los enlaces en la página.
Esencialmente, la siguiente imagen demuestra lo que un motor de búsqueda verá en una página web dependiendo de cómo hayas usado las directivas noindex y nofollow:

Marcar una página ya indexada como NoIndex
Si un motor de búsqueda ya ha indexado una página y la marca como noindex , la próxima vez que se rastree la página se eliminará de los resultados de búsqueda Para que este método de eliminar una página del índice funcione, no debe bloquear (no permitir) el rastreador con su archivo robots.txt.
Si le dice a un rastreador que no lea la página, nunca verá el marcador noindex y la página permanecerá indexada aunque su contenido no se actualizará.
¿Cómo evito que los motores de búsqueda indexen mi sitio?
Si desea eliminar una página del índice de búsqueda, después de que ya se haya indexado, puede completar los siguientes pasos:
- Aplique la directiva noindex Agregue el atributo noindex a la etiqueta meta o al encabezado de respuesta HTTP
- Solicite al motor de búsqueda que rastree la página Para Google, puede hacerlo en la consola de búsqueda, solicite que Google vuelva a indexar la página. Esto hará que Googlebot rastree la página, donde Googlebot descubrirá la directiva noindex. Deberá hacer esto para cada motor de búsqueda en el que desee eliminar la página.
- Confirme que la página se eliminó de la búsqueda Una vez que haya solicitado que el rastreador vuelva a visitar su página web, espere un poco y luego confirme que su página se eliminó de los resultados de búsqueda. Puede hacer esto yendo a cualquier motor de búsqueda e ingresando la URL de destino de dos puntos del sitio, como en la imagen a continuación.
Si su búsqueda no arroja resultados, entonces su página ha sido eliminada de ese índice de búsqueda. - Si la página no se eliminó Verifique que no tenga una directiva de "no permitir" en su archivo robots.txt. Google y otros motores de búsqueda no pueden leer la directiva noindex si no tienen permiso para rastrear la página. Si lo hace, elimine la directiva de rechazo para la página de destino y luego solicite el rastreo nuevamente.
- Establezca una directiva de rechazo para la página de destino en su archivo robots.txt Disallow: /page$
Tendrá que poner el signo de dólar al final de la URL en su archivo robots.txt o puede rechazar accidentalmente cualquier página debajo de esa página, así como cualquier página que comience con la misma cadena. Ej.: Disallow: /sweater también deshabilitará /sweater-weather y /sweater/green, pero Disallow: /sweater$ solo deshabilitará la página exacta /sweater.
Cómo para eliminar una página de la búsqueda de Google
Si la página que desea eliminar de la búsqueda se encuentra en un sitio que posee o administra, la mayoría de los sitios pueden usar la Herramienta de eliminación de URL para webmasters.
La herramienta de eliminación de URL para webmasters solo elimina el contenido de la búsqueda durante aproximadamente 90 días. Si desea una solución más permanente, deberá usar una directiva sin índice, prohibir el rastreo de su archivo robots.txt o eliminar la página de su sitio. Google proporciona instrucciones adicionales para la eliminación permanente de URL aquí.
Si está intentando eliminar una página de la búsqueda de un sitio que no es de su propiedad, puede solicitar a Google que elimine la página de la búsqueda si cumple con los siguientes criterios:

- Muestra información personal como su tarjeta de crédito o número de seguro social
- La página es parte de un esquema de malware o phishing
- La pagina viola la ley
- La página viola un copyright.
Si la página no cumple con uno de los criterios anteriores, puede comunicarse con una empresa de SEO o una empresa de relaciones públicas para obtener ayuda con la gestión de la reputación en línea.
¿Deberías no indexar páginas de categorías?
Por lo general, no se recomienda no indexar páginas de categoría, a menos que sea una organización de nivel empresarial que activa páginas de categoría mediante programación en función de búsquedas o etiquetas generadas por el usuario y el contenido duplicado se está volviendo difícil de manejar.
En su mayor parte, si está etiquetando su contenido de manera inteligente, de una manera que ayude a los usuarios a navegar mejor por su sitio y encontrar lo que necesitan, entonces estará bien.
De hecho, las páginas de categorías pueden ser minas de oro para el SEO, ya que suelen mostrar una profundidad de contenido en los temas de las categorías.
Eche un vistazo a este análisis que hicimos en diciembre de 2018 para cuantificar el valor de las páginas de categoría para un puñado de publicaciones en línea.
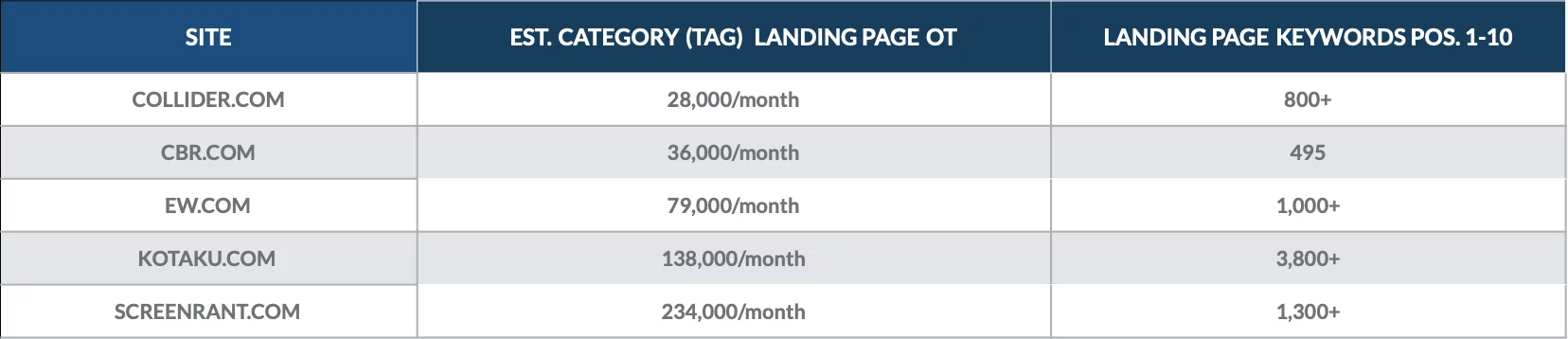
Descubrimos que las páginas de destino de la categoría se clasificaron para cientos de palabras clave de la página 1 y atrajeron a miles de visitantes orgánicos cada mes.
Las páginas de categoría más valiosas para cada sitio a menudo atrajeron a miles de visitantes orgánicos cada una.
Eche un vistazo a EW.com a continuación, medimos el tráfico de cada página (representado por el tamaño del círculo) y el valor del tráfico de cada página (representado por el color del círculo).
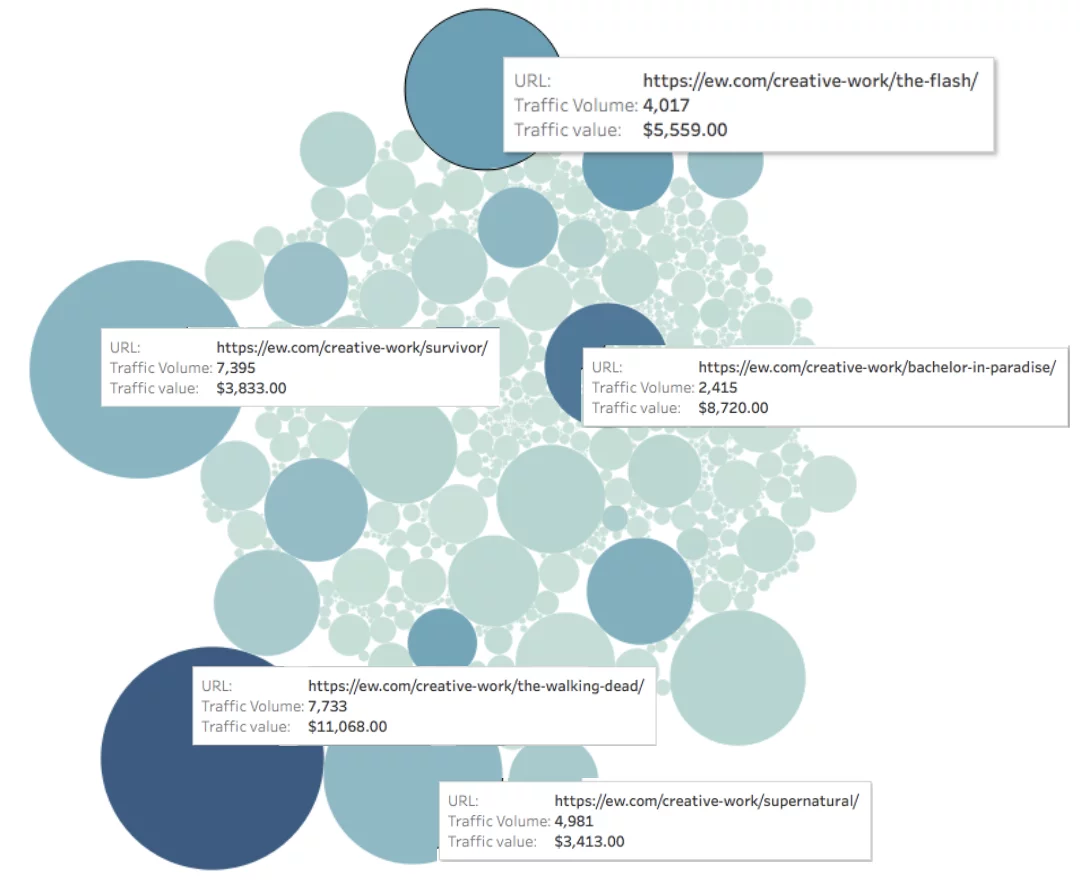
Valor orgánico mensual de la página = Profundidad de color
Ahora imagine los mismos gráficos, pero para sitios basados en productos donde es probable que los visitantes realicen compras activas.
Dicho esto, si sus categorías son lo suficientemente similares como para causar confusión en el usuario o competir entre sí en la búsqueda, es posible que deba hacer un cambio:
- Si está configurando las categorías usted mismo, le recomendamos que migre el contenido de una categoría a otra y reduzca la cantidad total de categorías que tiene en general.
- Si está permitiendo a los usuarios activar categorías, es posible que desee no indexar las páginas de categorías generadas por los usuarios, al menos hasta que las nuevas categorías se hayan sometido a un proceso de revisión.
¿Cómo evito que Google indexe subdominios?
Hay algunas opciones para evitar que Google indexe subdominios:
- Puede agregar una contraseña usando un archivo .htpasswd
- Puede prohibir los rastreadores con un archivo robots.txt
- Puede agregar una directiva noindex a cada página en el subdominio
- Puede 404 todas las páginas de subdominio
Agregar una contraseña para bloquear la indexación
Si sus subdominios son para fines de desarrollo, agregar un archivo .htpasswd al directorio raíz de su subdominio es la opción perfecta. El muro de inicio de sesión evitará que los rastreadores indexen contenido en el subdominio y evitará el acceso de usuarios no autorizados.
Ejemplos de casos de uso:
- Dev.dominio.com
- Staging.dominio.com
- Prueba.dominio.com
- control de calidad.dominio.com
- UAT.dominio.com
Uso de robots.txt para bloquear la indexación
Si sus subdominios sirven para otros fines, puede agregar un archivo robots.txt al directorio raíz de su subdominio. Entonces debería ser accesible de la siguiente manera:
https://subdominio.dominio.com/robots.txt
Deberá agregar un archivo robots.txt a cada subdominio que intente bloquear de la búsqueda. Ejemplo:
https://ayuda.dominio.com/robots.txt
https://dominio.público.com/robots.txt
En cada caso, el archivo robots.txt debe prohibir los rastreadores, para bloquear la mayoría de los rastreadores con un solo comando, use el siguiente código:
Agente de usuario: *
No permitir: /
El asterisco * después de user-agent: se denomina comodín y coincidirá con cualquier secuencia de caracteres. El uso de un comodín enviará la siguiente directiva de rechazo a todos los agentes de usuario, independientemente de su nombre, desde googlebot hasta yandex.
La barra invertida le dice al rastreador que todas las páginas fuera del subdominio están incluidas en la directiva de rechazo.
Cómo bloquear selectivamente la indexación de páginas de subdominios
Si desea que algunas páginas de un subdominio aparezcan en la búsqueda, pero no otras, tiene dos opciones:
- Usar directivas noindex a nivel de página
- Usar directivas de rechazo a nivel de carpeta o directorio
Las directivas noindex a nivel de página serán más engorrosas de implementar, ya que la directiva debe agregarse al HTML o encabezado de cada página. Sin embargo, las directivas noindex evitarán que Google indexe un subdominio, ya sea que el subdominio ya haya sido indexado o no.
Las directivas de rechazo a nivel de directorio son más fáciles de implementar, pero solo funcionarán si las páginas del subdominio aún no están en el índice de búsqueda. Simplemente actualice el archivo robots.txt del subdominio para impedir el rastreo de los directorios o subcarpetas correspondientes.
¿Cómo sé si mis páginas no están indexadas?
Agregar accidentalmente páginas directivas sin índice en su sitio puede tener consecuencias drásticas para sus clasificaciones de búsqueda y visibilidad de búsqueda.
Si encuentra que una página no está viendo ningún tráfico orgánico a pesar de un buen contenido y vínculos de retroceso, primero verifique que no haya rechazado accidentalmente a los rastreadores de su archivo robots.txt. Si eso no resuelve su problema, deberá verificar las páginas individuales en busca de directivas noindex.
Comprobación de NoIndex en las páginas de WordPress
WordPress facilita agregar o eliminar esta etiqueta en sus páginas. El primer paso para verificar si no sigue en sus páginas es simplemente alternar la configuración de visibilidad del motor de búsqueda dentro de la pestaña "Lectura" del menú "Configuración".
Es probable que esto resuelva el problema, sin embargo, esta configuración funciona como una "sugerencia" en lugar de una regla, y parte de su contenido puede terminar siendo indexado de todos modos.
Para garantizar la privacidad absoluta de sus archivos y contenido, tendrá que dar un último paso, ya sea para proteger su sitio con una contraseña utilizando las herramientas de administración de cPanel, si están disponibles, o mediante un complemento simple.
Del mismo modo, puede eliminar esta etiqueta de su contenido eliminando la protección con contraseña y desmarcando la configuración de visibilidad.
Comprobación de NoIndex en Squarespace
Las páginas de Squarespace también se indexan fácilmente mediante la capacidad de inyección de código de la plataforma. Al igual que WordPress, Squarespace puede bloquearse fácilmente de las búsquedas de rutina mediante la protección con contraseña; sin embargo, la plataforma también desaconseja dar este paso para proteger la integridad de su contenido.
Al agregar la línea de código NoIndex dentro de cada página que desea ocultar de los motores de búsqueda de Internet y en cada subpágina debajo de ella, puede garantizar la seguridad del contenido protegido que debe prohibirse el acceso público. Al igual que otras plataformas, eliminar esta etiqueta también es bastante sencillo: simplemente usar la función de inyección de código para recuperar el código es todo lo que necesita hacer.
Squarespace es único en el sentido de que sus competidores ofrecen esta opción principalmente como parte del conjunto de configuraciones en las herramientas de administración de páginas. Squarespace parte de aquí, lo que permite la manipulación personal del código. Esto es interesante porque puede ver el cambio que está realizando en el contenido de su página, a diferencia de los demás en este espacio.
Buscando NoIndex en Wix
Wix también permite una solución simple y rápida para problemas de no indexación. En la configuración de "Menús y páginas", simplemente puede desactivar la opción para 'mostrar esta página en los resultados de búsqueda' si desea No indexar una sola página dentro de su sitio.
Al igual que con sus competidores, Wix también sugiere proteger con contraseña tus páginas o todo el sitio para mayor privacidad. Sin embargo, Wix se diferencia de los demás en que el equipo de soporte no prescribe una acción paralela en ambos frentes para proteger el contenido del rastreador. Wix hace una nota particular sobre la diferencia entre ocultar una página de tu menú y ocultarla de los criterios de búsqueda.
Este es un consejo particularmente útil para los creadores de sitios web menos experimentados que pueden no entender inicialmente la diferencia considerando que la eliminación del menú de su sitio hace que la página sea inaccesible desde el sitio, pero no desde un término de búsqueda prudente de Google.