
Modelado de temas con Word2Vec
Publicado: 2022-05-02Una palabra se define por la compañía que guarda. Esa es la premisa detrás de Word2Vec, un método para convertir palabras en números y representarlos en un espacio multidimensional. Las palabras que se encuentran frecuentemente juntas en una colección de documentos (corpus) también aparecerán juntas en este espacio. Se dice que están relacionados contextualmente.
Word2Vec es un método de aprendizaje automático que requiere un corpus y una formación adecuada. La calidad de ambos afecta su capacidad para modelar un tema con precisión. Cualquier deficiencia se vuelve evidente al examinar el resultado de temas muy específicos y complicados, ya que estos son los más difíciles de modelar con precisión. Word2Vec se puede usar solo, aunque con frecuencia se combina con otras técnicas de modelado para abordar sus limitaciones.
El resto de este artículo proporciona antecedentes adicionales sobre Word2Vec, cómo funciona, cómo se usa en el modelado de temas y algunos de los desafíos que presenta.
¿Qué es Word2Vec?
En septiembre de 2013, los investigadores de Google, Tomas Mikolov, Kai Chen, Greg Corrado y Jeffrey Dean, publicaron el artículo 'Estimación eficiente de las representaciones de palabras en el espacio vectorial' (pdf). Esto es a lo que ahora nos referimos como Word2Vec. El objetivo del documento era "presentar técnicas que se pueden usar para aprender vectores de palabras de alta calidad a partir de grandes conjuntos de datos con miles de millones de palabras y con millones de palabras en el vocabulario".
Antes de este punto, cualquier técnica de procesamiento del lenguaje natural trataba las palabras como unidades singulares. No tuvieron en cuenta ninguna similitud entre las palabras. Si bien había razones válidas para este enfoque, tenía sus limitaciones. Hubo situaciones en las que escalar estas técnicas básicas no podía ofrecer una mejora significativa. De ahí la necesidad de desarrollar tecnologías avanzadas.
El documento mostró que los modelos simples, con sus requisitos computacionales más bajos, podrían entrenar vectores de palabras de alta calidad. Como concluye el documento, es "posible calcular vectores de palabras de alta dimensión muy precisos a partir de un conjunto de datos mucho más grande". Están hablando de colecciones de documentos (corpora) con un billón de palabras que proporcionan un tamaño virtualmente ilimitado del vocabulario.
Word2Vec es una forma de convertir palabras en números, en este caso vectores, para que las similitudes se puedan descubrir matemáticamente. La idea es que los vectores de palabras similares se agrupen dentro del espacio vectorial.
Piense en las coordenadas latitudinales y longitudinales en un mapa. Usando este vector bidimensional, puede determinar rápidamente si dos ubicaciones están relativamente juntas. Para que las palabras se representen adecuadamente en un espacio vectorial, las dos dimensiones no son suficientes. Entonces, los vectores necesitan incorporar muchas dimensiones.
¿Cómo funciona Word2Vec?
Word2Vec toma como entrada un gran corpus de texto y lo vectoriza utilizando una red neuronal poco profunda. La salida es una lista de palabras (vocabulario), cada una con un vector correspondiente. Las palabras con un significado similar aparecen espacialmente muy cerca. Matemáticamente, esto se mide por la similitud del coseno, donde la similitud total se expresa como un ángulo de 0 grados, mientras que la no similitud se expresa como un ángulo de 90 grados.
Las palabras se pueden codificar como vectores usando diferentes tipos de modelos. En su artículo, Mikolov et al. analizó dos modelos existentes, el modelo de lenguaje de red neuronal feedforward (NNLM) y el modelo de lenguaje de red neuronal recurrente (RNNLM). Además, proponen dos nuevos modelos log-lineales, bolsa de palabras continua (CBOW) y Skip-gram continuo.
En sus comparaciones, CBOW y Skip-gram se desempeñaron mejor, así que examinemos estos dos modelos.
CBOW es similar a NNLM y se basa en el contexto para determinar una palabra objetivo. Determina la palabra objetivo en función de las palabras que vienen antes y después. Mikolov encontró que el mejor desempeño ocurrió con cuatro palabras futuras y cuatro históricas. Se llama 'bolsa de palabras' porque el orden de las palabras en el historial no influye en la salida. 'Continuo' en el término CBOW se refiere a su uso de "representación distribuida continua del contexto".
Skip-gram es el reverso de CBOW. Dada una palabra, predice las palabras que la rodean dentro de un rango específico. Un mayor rango proporciona vectores de palabras de mejor calidad pero aumenta la complejidad computacional. Se da menos peso a los términos lejanos porque suelen estar menos relacionados con la palabra actual.
Al comparar CBOW con Skip-gram, se descubrió que este último ofrece resultados de mejor calidad en grandes conjuntos de datos. Aunque CBOW es más rápido, Skip-gram maneja mejor las palabras que se usan con poca frecuencia.
Durante el entrenamiento, se asigna un vector a cada palabra. Los componentes de ese vector se ajustan para que palabras similares (según su contexto) estén más juntas. Piense en esto como un tira y afloja, donde las palabras son empujadas y tiradas en este vector multidimensional cada vez que se agrega otro término al espacio.
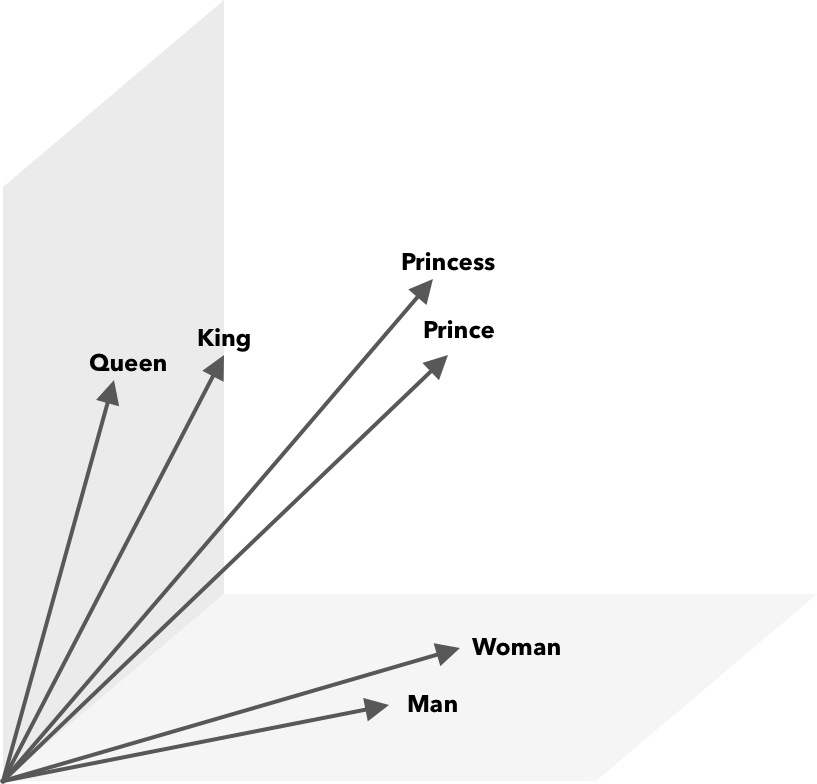
Las operaciones matemáticas, además de la similitud de coseno, se pueden realizar en vectores de palabras. Por ejemplo, el vector(”Rey”) – vector(”Hombre”) + vector(”Mujer”) da como resultado un vector más cercano al que representa la palabra Reina.

Word2Vec para el modelado de temas
El vocabulario creado por Word2Vec se puede consultar directamente para detectar relaciones entre palabras o alimentar una red neuronal de aprendizaje profundo. Un problema con los algoritmos de Word2Vec como CBOW y Skip-gram es que ponderan cada palabra por igual. El problema que surge cuando se trabaja con documentos es que las palabras no representan por igual el significado de una oración.
Algunas palabras son más importantes que otras. Por lo tanto, a menudo se emplean diferentes estrategias de ponderación, como TF-IDF, para hacer frente a la situación. Esto también ayuda a abordar el problema de hubness mencionado en la siguiente sección. Searchmetrics ContentExperience utiliza una combinación de TF-IDF y Word2Vec, sobre la que puede leer aquí en nuestra comparación con MarketMuse.
Mientras que las incrustaciones de palabras como Word2Vec capturan información morfológica, semántica y sintáctica, el modelado de temas tiene como objetivo descubrir temas estructurados o semánticos latentes en un corpus.
Según Budhkar y Rudzicz (PDF), la combinación de la asignación latente de Dirichlet (LDA) con Word2Vec puede producir características discriminatorias para "abordar el problema causado por la ausencia de información contextual integrada en estos modelos". Se puede encontrar una lectura más fácil en LDA2vec en este tutorial de DataCamp.
Desafíos de Word2Vec
Hay varios problemas con las incrustaciones de palabras en general, incluido Word2Vec. Abordaremos algunos de estos, para un análisis más detallado, consulte 'A Survey of Word Embedding Evaluation Methods' (pdf) de Amir Bakarov. El corpus y su tamaño, así como la formación en sí, tendrán un impacto significativo en la calidad de salida.
¿Cómo evalúas la salida?
Como explica Bakarov en su artículo, un ingeniero de PNL normalmente evaluará el rendimiento de las incrustaciones de manera diferente a un lingüista computacional o un especialista en marketing de contenido. Aquí hay algunos problemas adicionales citados en el documento.
- La semántica es una idea vaga. Una incrustación de palabras "buenas" refleja nuestra noción de semántica. Sin embargo, es posible que no seamos conscientes de si nuestra comprensión es correcta. Además, las palabras tienen diferentes tipos de relaciones, como la relación semántica y la similitud semántica. ¿Qué tipo de relación debería reflejar la palabra incrustación?
- Falta de datos de entrenamiento adecuados. Al entrenar incrustaciones de palabras, los investigadores suelen aumentar su calidad ajustándolas a los datos. Esto es a lo que nos referimos como ajuste de curvas. En lugar de hacer que el resultado se ajuste a los datos, los investigadores deberían tratar de capturar las relaciones entre las palabras.
- La ausencia de correlación entre los métodos intrínsecos y extrínsecos significa que no está claro qué clase de método se prefiere. La evaluación extrínseca determina la calidad de salida para su uso posterior en otras tareas de procesamiento de lenguaje natural. La evaluación intrínseca se basa en el juicio humano de las relaciones entre palabras.
- El problema del hubness. Los hubs, vectores de palabras que representan palabras comunes, están cerca de un número excesivo de otros vectores de palabras. Este ruido puede sesgar la evaluación.
Además, hay dos desafíos importantes con Word2Vec en particular.
- No puede manejar ambigüedades muy bien. Como resultado, el vector de una palabra con múltiples significados refleja el promedio, que está lejos de ser ideal.
- Word2Vec no puede manejar palabras fuera de vocabulario (OOV) y palabras morfológicamente similares. Cuando el modelo encuentra un concepto nuevo, recurre al uso de un vector aleatorio, que no es una representación precisa.
Resumen
Usar Word2Vec o cualquier otra palabra incrustada no es garantía de éxito. La producción de calidad se basa en una formación adecuada utilizando un corpus apropiado y suficientemente grande.
Si bien evaluar la calidad de la salida puede ser engorroso, aquí hay una solución simple para los especialistas en marketing de contenido. La próxima vez que evalúe un optimizador de contenido, intente usar un tema muy específico. Los modelos de temas de baja calidad fallan cuando se trata de probar de esta manera. Están bien para los términos generales, pero fallan cuando la solicitud se vuelve demasiado específica.
Entonces, si usa el tema 'cómo cultivar aguacates', asegúrese de que las sugerencias tengan algo que ver con el cultivo de la planta y no con los aguacates en general.
La generación de lenguaje natural de MarketMuse NLG Technology ayudó a crear este artículo.
lo que debes hacer ahora
Cuando esté listo... aquí hay 3 formas en que podemos ayudarlo a publicar mejor contenido, más rápido:
- Reserve tiempo con MarketMuse Programe una demostración en vivo con uno de nuestros estrategas para ver cómo MarketMuse puede ayudar a su equipo a alcanzar sus objetivos de contenido.
- Si desea aprender cómo crear mejor contenido más rápido, visite nuestro blog. Está lleno de recursos para ayudar a escalar el contenido.
- Si conoce a otro profesional del marketing al que le gustaría leer esta página, compártala por correo electrónico, LinkedIn, Twitter o Facebook.