
¿Cuáles son los tipos de Big Data: características y definición?
Publicado: 2023-10-06Resumen: Big data se compone de cuatro tipos denominados datos estructurados, no estructurados, semiestructurados y cuasiestructurados. ¡Aprendamos sobre cada tipo de big data en detalle a continuación!
La mayoría de las organizaciones dependen de los conjuntos de datos para obtener conocimientos y aprender sobre sus clientes, su industria y su empresa. Sin embargo, cuando los datos aumentan de tamaño, resulta difícil manejarlos y procesarlos.
Estos conjuntos de datos se denominan conjuntos de grandes datos, que tienen una mayor variedad de datos y son de naturaleza enorme. Los big data pueden presentarse en varias formas, como estructuradas, no estructuradas, semiestructuradas y cuasiestructuradas.
Aprendamos más sobre los diferentes tipos de conjuntos de big data en el artículo siguiente.
Tabla de contenido
¿Cuáles son los tipos populares de Big Data?
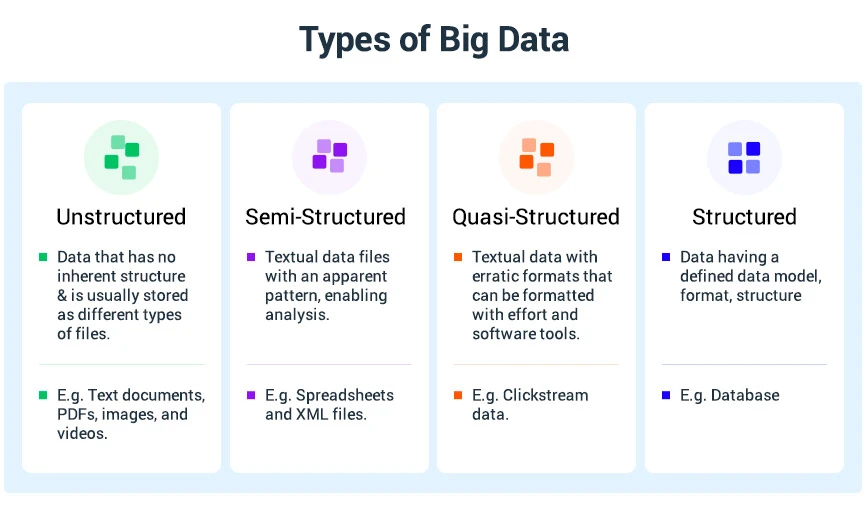
Big data se clasifica en estos cuatro tipos principales que se enumeran a continuación:
Datos estructurados
Los datos estructurados son un tipo de datos que tienen un formato estandarizado al que el software y las personas pueden acceder fácilmente. Generalmente tiene forma de tabla con varias filas y columnas que resaltan los atributos de los datos.
Los datos estructurados comprenden datos cuantitativos como edad, número de contacto, números de tarjetas de crédito, etc. Dado que es de naturaleza cuantitativa, el software puede procesarlo fácilmente para obtener información valiosa.
Para procesar los datos de la estructura, no es necesario colocar los datos en métricas relevantes. Además, no es necesario convertir e interpretar los datos de la estructura en profundidad para obtener información valiosa.
¿Dónde utilizar el tipo de datos estructurados?
- Gestionar datos de clientes
- Mantener los detalles de las facturas
- Almacenamiento de bases de datos de productos
- Lista de contactos de grabación
Pros y contras de los datos estructurados
- Esto facilita el procesamiento de los datos porque se almacenan en un formato definido.
- Los datos se procesan rápidamente en comparación con los datos no estructurados.
- Puede que no sea adecuado para todo tipo de información porque los datos se almacenan en un formato específico.
Datos no estructurados: XML, JSON, YAML

Los datos no estructurados son un tipo de datos que no se limitan a un modelo de datos específico y una estructura identificable que pueda ser leída por un programa de computadora. Este tipo de datos no está organizado de manera adecuadamente definida y carece de secuencia o formato para procesar los datos.
En comparación con los datos estructurados, este tipo de datos no se pueden almacenar en forma de filas y columnas. Un ejemplo común de datos no estructurados es una base de datos heterogénea que contiene una combinación de imágenes, vídeos, archivos de texto, etc.
¿Dónde utilizar el tipo de datos no estructurados?
- Gestión de datos de audio y vídeo
- Manejo de respuestas abiertas a encuestas
- Manejo de publicaciones en redes sociales
- Gestión de documentos comerciales
Pros y contras de los datos no estructurados
- Como no existe una estructura definida, los datos se pueden recopilar rápidamente.
- Puede utilizarse para tratar con fuentes de datos heterogéneas.
- Debido a la falta de estructura o esquema, es más difícil de gestionar.
Datos semiestructurados
Los datos semiestructurados son un tipo de datos que no están estructurados adecuadamente pero al mismo tiempo no están completamente desestructurados. Estos datos no se ciñen al esquema rígido ni al modelo de datos. Además, también podría contener componentes que no se pueden categorizar o clasificar fácilmente.
Los datos semiestructurados se caracterizan por metadatos y etiquetas que proporcionan información adicional sobre todos los elementos de datos. Por ejemplo, un archivo XML puede contener etiquetas que indiquen la estructura del documento e incluir etiquetas adicionales que proporcionen metadatos sobre el contenido, como la fecha o las palabras clave.
¿Dónde utilizar el tipo de datos semiestructurados?
- Analizar páginas web a través de HTML
- Uso de datos de correos electrónicos para obtener información sobre los clientes
- Categorizar y analizar vídeos e imágenes.
Pros y contras del tipo de datos semestructurados
- El esquema de los datos se puede cambiar.
- Este tipo de datos puede acomodar datos que pueden no encajar en un esquema predefinido.
- Las consultas de datos son menos eficientes en comparación con los datos estructurados.
Datos cuasi estructurados
Los datos cuasi estructurados son un tipo de datos textuales que vienen con formatos de datos erráticos. Este tipo de datos se puede formatear con diferentes herramientas de análisis de datos. Incluye datos como datos de secuencia de clics web.

¿Dónde utilizar el tipo de datos cuasiestructurados?
- Se puede utilizar para analizar los datos de las páginas web.
Pros y contras del tipo de datos cuasi estructurados
- Los datos se pueden procesar rápidamente.
- Este tipo de datos se puede formatear rápidamente mediante herramientas de análisis de datos.
- Es posible que la carga de datos tarde algún tiempo.
¿Cuáles son los subtipos de datos?
Hay varios subtipos de datos que no se consideran big data pero que son importantes para el análisis. El origen de dichos datos puede ser de redes sociales, registros operativos, desencadenados por eventos o geoespaciales. También puede provenir de sistemas de código abierto, datos transmitidos a través de API y dispositivos perdidos o robados.
Características de los grandes datos
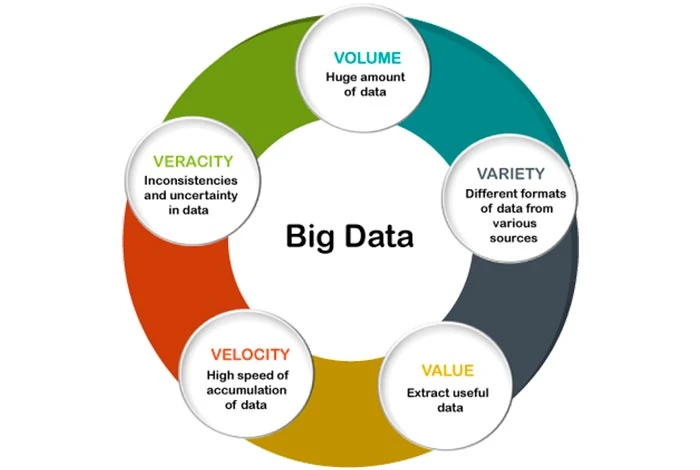
Hay cinco V que definen las características del big data. Estas características se enumeran a continuación:
- Volumen: La primera característica del big data es el volumen. Big data son el gran “volumen” de datos recopilados de varias fuentes. Las fuentes pueden incluir procedimientos comerciales, plataformas de redes sociales, máquinas, interacciones humanas, etc.
- Veracidad: La veracidad se puede definir como la calidad y exactitud de los datos dados. Es posible que a los datos extraídos les falten algunos elementos o que no puedan proporcionar información valiosa. Por lo tanto, esta característica es útil para identificar la calidad de los datos y obtener información.
- Variedad: La variedad se puede definir como la diversidad de varios tipos de datos. Los datos se pueden obtener de varias fuentes de datos que pueden variar en valor. Los datos recopilados pueden ser estructurados, no estructurados o semiestructurados. La variedad de datos puede ser en forma de archivos PDF, correos electrónicos, fotos, audios, etc.
- Valor: Se puede definir como el valor que el big data puede aportar. Es importante extraer valor de los datos recopilados para obtener información valiosa de ellos. Las organizaciones pueden utilizar las mismas herramientas de análisis de big data a través de las cuales recopilaron datos para analizarlos.
- Velocidad: La velocidad se refiere a la rapidez con la que se generan y mueven los datos. Es un elemento importante para las empresas que desean que sus datos fluyan rápidamente para que estén disponibles en el momento adecuado para obtener información valiosa. Los datos pueden fluir de diversas fuentes, como máquinas, teléfonos inteligentes, redes, etc. Una vez recopilados los datos, se pueden analizar rápidamente.
Sectores que utilizan Big Data a diario
Los macrodatos se pueden utilizar en múltiples industrias, incluidas la atención médica, la agricultura, la educación, las finanzas, etc. Conozcamos en detalle la aplicación de big data en los siguientes sectores a continuación:
- Educación: en el sector educativo, los profesores pueden analizar el rendimiento de los estudiantes y las tasas de abandono para optimizar el plan de estudios. Además, también puede ayudar a identificar áreas de mejora mediante el análisis del desempeño de un estudiante.
- Comercio electrónico: el sector del comercio electrónico puede utilizar el análisis de big data para comprender qué procedimientos de su empresa están funcionando bien o cuáles necesitan mejorar. Además, también puede identificar el tipo de contenido que genera participación y qué canales generan mayor tráfico.
- Atención sanitaria: en la atención sanitaria, los big data se pueden utilizar para obtener conocimientos de la investigación biomédica y proporcionar recomendaciones de medicamentos personalizados a los pacientes después de analizar sus datos. Además, al monitorear el estado de un paciente en tiempo real, pueden enviar alertas al personal médico.
- Gobierno: El gobierno puede utilizar big data para analizar los datos de los ciudadanos de forma masiva a través de múltiples parámetros. Por ejemplo, se analiza el big data del censo para conocer el número de jóvenes que hay en el país o la población de desempleados. Los hallazgos pueden ayudarlos a desarrollar esquemas y planes dirigidos al grupo adecuado de ciudadanos.
Lectura sugerida: Principales herramientas de inteligencia empresarial (BI)
Conclusión
Big data ha facilitado a las empresas el procesamiento de conjuntos de datos masivos. Cuando los datos se clasifican, organizan y analizan en masa, pueden ayudar a las empresas a obtener información valiosa. Cada vez más industrias confían en el análisis de big data para procesar datos complejos y aprovechar la inferencia para obtener una ventaja competitiva.
Preguntas frecuentes relacionadas con los tipos de Big Data
¿Qué es big data y qué tipo de big data?
Big data es un tipo de datos que contiene mayor variedad, viene en mayor volumen y con más velocidad. Los tipos de big data incluyen estructurados, no estructurados y semiestructurados.
¿Cuáles son los tres tipos de clasificación de Big Data?
Los tres tipos de clasificación de Big Data son datos estructurados, no estructurados y semiestructurados.
¿Cuáles son los 4 componentes del Big Data?
Los cuatro componentes principales del big data son volumen, velocidad, variedad y veracidad.
¿Cuáles son las 6 características del Big Data?
Big data tiene las siguientes características que ayudan a analizar los datos: volumen, variedad, veracidad, variabilidad, velocidad y valor.
¿Cuáles son las fuentes de big data?
Las principales fuentes de big data podrían agruparse en sociales, mecánicas y transaccionales. Las fuentes sociales son las fuentes de big data más utilizadas por la organización. Incluye publicaciones en redes sociales, videos publicados, etc.