
Qu'est-ce qu'un budget de crawl et comment l'optimiser
Publié: 2022-11-25
Un budget de crawl peut sembler un concept étranger lorsque vous découvrez pour la première fois comment fonctionnent les robots des moteurs de recherche. Bien qu'ils ne soient pas le concept de référencement le plus simple, ils sont moins compliqués qu'il n'y paraît. Une fois que vous commencez à comprendre ce qu'est un budget d'exploration et comment fonctionne l'exploration des moteurs de recherche, vous pouvez commencer à optimiser votre site Web pour optimiser l'exploration. Ce processus aidera votre site à atteindre son meilleur potentiel de classement dans les résultats de recherche de Google.
Qu'est-ce qu'un budget de crawl ?
Un budget de crawl est le nombre d'URL d'un site Web que les robots des moteurs de recherche peuvent indexer au cours d'une session d'indexation. Le « budget » d'une session d'exploration diffère d'un site Web à l'autre en fonction de la taille, des statistiques de trafic et de la vitesse de chargement des pages de chaque site.
Si vous êtes arrivé jusqu'ici et que les termes SEO ne vous sont pas familiers, utilisez notre glossaire SEO pour vous familiariser avec les définitions .
Quels facteurs affectent le budget de crawl d'un site Web ?
 Google ne consacre pas le même temps ou le même nombre de crawls à chaque site Web sur Internet. Les robots Web déterminent également les pages qu'ils explorent et à quelle fréquence en fonction de plusieurs facteurs. Ils déterminent la fréquence et la durée d'exploration de chaque site en fonction de :
Google ne consacre pas le même temps ou le même nombre de crawls à chaque site Web sur Internet. Les robots Web déterminent également les pages qu'ils explorent et à quelle fréquence en fonction de plusieurs facteurs. Ils déterminent la fréquence et la durée d'exploration de chaque site en fonction de :
- Popularité : plus un site ou une page est visité, plus il doit être analysé souvent pour les mises à jour. De plus, les pages les plus populaires accumuleront plus de liens entrants plus rapidement.
- Taille : les sites Web volumineux et les pages contenant davantage d'éléments à forte intensité de données prennent plus de temps à explorer.
- Santé/Problèmes : Lorsqu'un robot d'exploration atteint une impasse via des liens internes, il lui faut du temps pour trouver un nouveau point de départ ou il abandonne l'exploration. Les erreurs 404, les redirections et les temps de chargement lents ralentissent et bloquent les robots d'exploration.
Comment votre budget de crawl affecte-t-il le référencement ?

Le processus d'indexation du webcrawler rend la recherche possible. Si votre contenu est introuvable puis indexé par les robots d'indexation de Google, vos pages Web et votre site Web ne seront pas détectables par les internautes. Cela conduirait à ce que votre site manque beaucoup de trafic de recherche.
Pourquoi Google explore-t-il les sites Web ?
Les Googlebots parcourent systématiquement les pages d'un site Web pour déterminer de quoi traitent la page et le site Web dans son ensemble. Les robots d'exploration traitent, catégorisent et organisent les données de ce site Web page par page afin de créer un cache d'URL avec leur contenu, afin que Google puisse déterminer quels résultats de recherche doivent apparaître en réponse à une requête de recherche.
En outre, Google utilise ces informations pour déterminer quels résultats de recherche correspondent le mieux à la requête de recherche afin de déterminer où chaque résultat de recherche doit apparaître dans la liste hiérarchique des résultats de recherche.
Que se passe-t-il lors d'un crawl ?
Google alloue un laps de temps défini à un Googlebot pour traiter un site Web. En raison de cette limitation, le bot n'explorera probablement pas un site entier au cours d'une session d'exploration. Au lieu de cela, il parcourra toutes les pages du site en fonction du fichier robots.txt et d'autres facteurs (tels que la popularité d'une page).
Au cours de la session d'exploration, un Googlebot utilisera une approche systématique pour comprendre le contenu de chaque page qu'il traite.
Cela inclut l'indexation d'attributs spécifiques, tels que :
- Balises Meta et utilisation de la PNL pour déterminer leur signification
- Liens et texte d'ancrage
- Fichiers multimédia enrichis pour les recherches d'images et les recherches de vidéos
- Balisage de schéma
- Balisage HTML
Le robot d'exploration Web effectuera également une vérification pour déterminer si le contenu de la page est un doublon d'un canonique. Si tel est le cas, Google déplacera l'URL vers une exploration de faible priorité, afin de ne pas perdre de temps à explorer la page aussi souvent.
Que sont le taux de crawl et la demande de crawl ?
Les robots d'exploration Web de Google attribuent un certain temps à chaque exploration qu'ils effectuent. En tant que propriétaire de site Web, vous n'avez aucun contrôle sur ce laps de temps. Cependant, vous pouvez modifier la vitesse à laquelle ils explorent les pages individuelles de votre site pendant qu'ils sont sur votre site. Ce nombre est appelé votre taux de crawl .
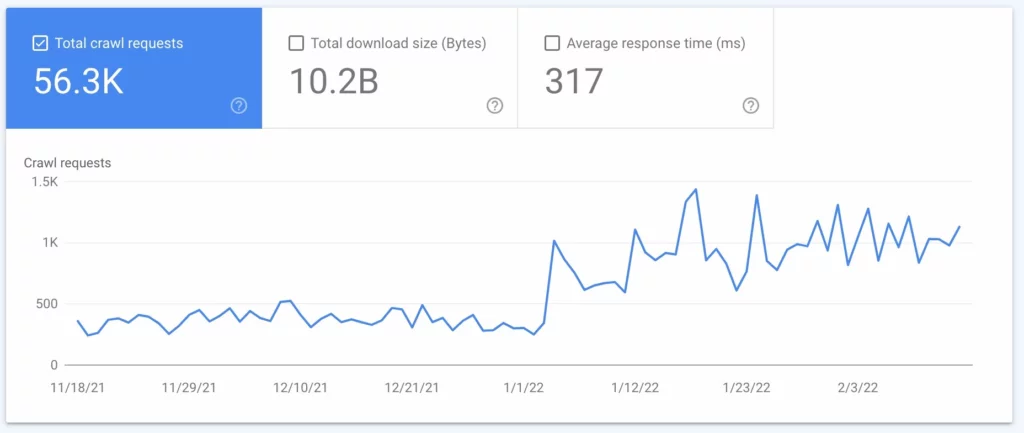
La demande d' exploration correspond à la fréquence à laquelle Google explore votre site. Cette fréquence est basée sur la demande de votre site par les internautes et sur la fréquence à laquelle le contenu de votre site doit être mis à jour lors des recherches. Vous pouvez découvrir à quelle fréquence Google explore votre site à l'aide d'une analyse de fichier journal (voir #2 ci-dessous).
Comment puis-je déterminer le budget de crawl de mon site ?

Étant donné que Google limite le nombre de fois où ils explorent votre site et pendant combien de temps, vous voulez connaître votre budget d'exploration. Cependant, Google ne fournit pas ces données aux propriétaires de sites, en particulier si votre budget est si restreint que le nouveau contenu n'atteindra pas les SERP en temps opportun. Cela peut être désastreux pour le contenu important et les nouvelles pages comme les pages de produits qui pourraient vous rapporter de l'argent.
Pour comprendre si votre site est confronté à des limitations de budget de crawl (ou pour confirmer que votre site est A-OK), vous voudrez : Obtenez un inventaire du nombre d'URL présentes sur votre site. Si vous utilisez Yoast, votre total sera affiché en haut de l'URL de votre sitemap .
Comment pouvez-vous optimiser votre budget de crawl ?
Lorsque viendra le moment où votre site sera devenu trop gros pour son budget de crawl, vous devrez vous plonger dans l'optimisation du budget de crawl. Étant donné que vous ne pouvez pas demander à Google d'explorer votre site plus souvent ou plus longtemps, vous devez vous concentrer sur ce que vous pouvez contrôler.
L'optimisation du budget de crawl nécessite une approche multidimensionnelle et une compréhension des bonnes pratiques de Google . Par où commencer pour tirer le meilleur parti de votre taux de crawl ? Cette liste complète est écrite dans l'ordre hiérarchique, alors commencez par le haut.
1. Envisagez d'augmenter la limite de vitesse d'exploration de votre site
Google envoie des requêtes simultanément à plusieurs pages de votre site. Cependant, Google essaie d'être courtois et de ne pas enliser votre serveur, ce qui ralentirait le temps de chargement des visiteurs de votre site. Si vous remarquez que votre site est à la traîne de nulle part, cela peut être le problème.
Pour éviter d'affecter l'expérience de vos utilisateurs, Google vous permet de réduire votre taux de crawl. Cela limitera le nombre de pages que Google peut indexer simultanément.
Chose intéressante, cependant, Google vous permet également d'augmenter votre limite de vitesse d'exploration, l'effet étant qu'ils peuvent extraire plus de pages à la fois, ce qui entraîne l'exploration simultanée de plus d'URL. Cependant, tous les rapports suggèrent que Google est lent à réagir à une augmentation de la limite de vitesse d'exploration, et cela ne garantit pas que Google explorera plus de sites simultanément.
Comment augmenter votre limite de taux de crawl :
- Dans la Search Console, accédez à "Paramètres".
- À partir de là, vous pouvez voir si votre taux de crawl est optimal ou non.
- Ensuite, vous pouvez augmenter la limite à une vitesse d'exploration plus rapide pendant 90 jours.
2. Effectuer une analyse du fichier journal

Une analyse de fichier journal est un rapport du serveur qui reflète chaque demande envoyée au serveur. Ce rapport vous dira exactement ce que font les Googlebots sur votre site. Bien que ce processus soit souvent effectué par des SEO techniques, vous pouvez parler à votre administrateur de serveur pour en obtenir un.
À l'aide de votre analyse de fichier journal ou du fichier journal du serveur, vous apprendrez :
- À quelle fréquence Google explore votre site
- Quelles pages sont le plus crawlées
- Quelles pages ont un code de serveur qui ne répond pas ou est manquant
Une fois que vous avez ces informations, vous pouvez les utiliser pour effectuer les étapes 3 à 7.
3. Gardez votre sitemap XML et Robots.txt à jour
Si votre fichier journal indique que Google passe trop de temps à explorer des pages que vous ne souhaitez pas voir apparaître dans les SERP, vous pouvez demander aux robots d'exploration de Google d'ignorer ces pages. Cela libère une partie de votre budget de crawl pour des pages plus importantes.

Votre sitemap (que vous pouvez obtenir auprès de Google Search Console ou SearchAtlas ) donne aux Googlebots une liste de toutes les pages de votre site que vous souhaitez que Google indexe afin qu'elles puissent apparaître dans les résultats de recherche. Garder votre sitemap à jour avec toutes les pages Web que vous voulez que les moteurs de recherche trouvent et omettre celles que vous ne voulez pas qu'ils trouvent peut maximiser la façon dont les robots d'exploration passent leur temps sur votre site.
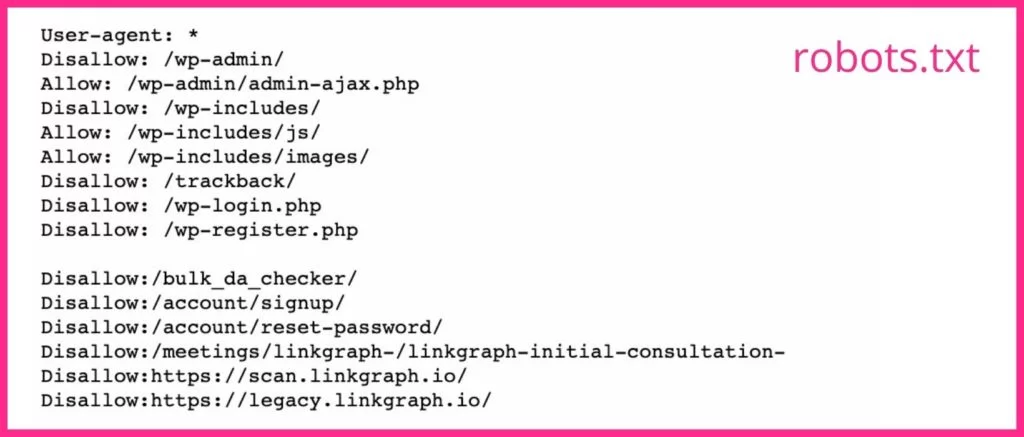
Votre fichier robots.txt indique aux robots des moteurs de recherche les pages que vous voulez et ne voulez pas qu'ils explorent. Si vous avez des pages qui ne font pas de bonnes pages de destination ou des pages fermées, vous devez utiliser la balise noindex pour leurs URL dans votre fichier robots.txt. Googlebots ignorera probablement toute page Web avec la balise noindex.
4. Réduisez les redirections et les chaînes de redirection
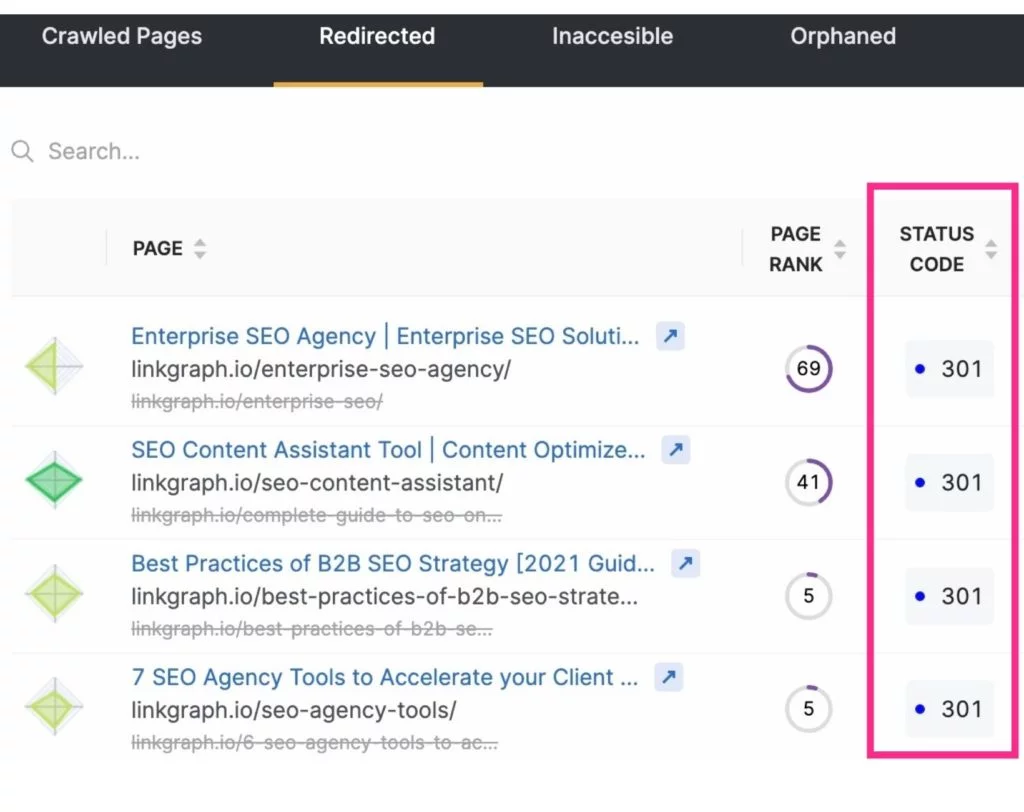
En plus de libérer le budget de crawl en excluant les pages inutiles des crawls des moteurs de recherche, vous pouvez également maximiser les crawls en réduisant ou en éliminant les redirections. Il s'agira de toutes les URL qui aboutiront à un code d'état 3xx.
Les URL redirigées prennent plus de temps à être récupérées par un Googlebot, car le serveur doit répondre avec la redirection, puis récupérer la nouvelle page. Alors qu'une redirection ne prend que quelques millisecondes, elles peuvent s'additionner. Et cela peut rendre l'exploration de votre site plus longue dans l'ensemble. Ce temps est multiplié lorsqu'un Googlebot rencontre une chaîne de redirections d'URL.
Pour réduire les redirections et les chaînes de redirection, soyez attentif à votre stratégie de création de contenu et sélectionnez soigneusement le texte de vos slugs.
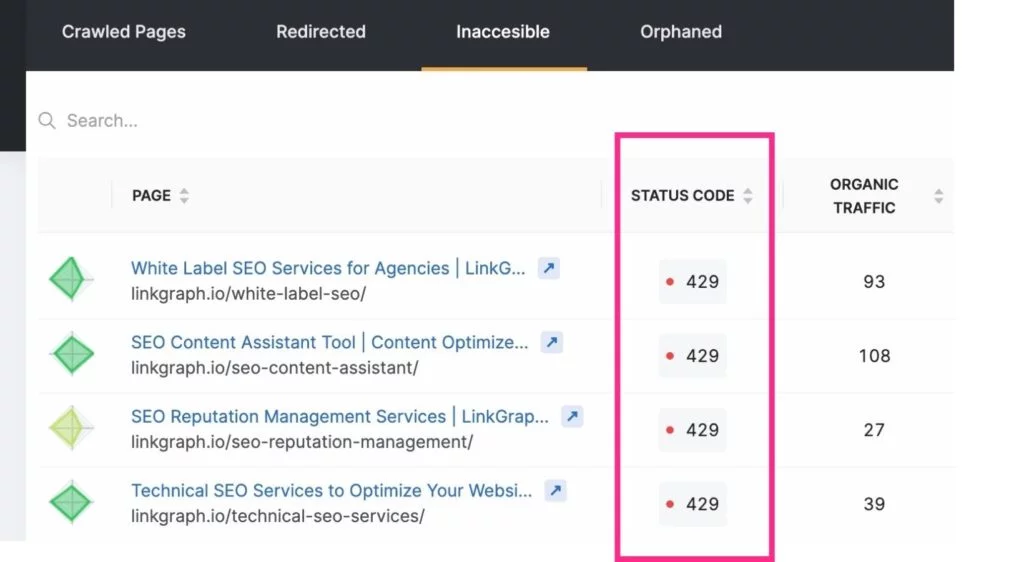
5. Réparez les liens brisés
La façon dont Google explore souvent un site est de naviguer via votre structure de liens internes. Au fur et à mesure qu'il parcourt vos pages, il notera si un lien mène à une page inexistante (ceci est souvent appelé une erreur logicielle 404). Il passera alors à autre chose, ne voulant pas perdre de temps à indexer ladite page.
Les liens vers ces pages doivent être mis à jour pour envoyer l'utilisateur ou Googlebot vers une vraie page. OU (bien que ce soit difficile à croire) le Googlebot peut avoir mal identifié une page comme une erreur 4xx ou 404 alors que la page existe réellement. Lorsque cela se produit, vérifiez que l'URL ne contient aucune faute de frappe, puis soumettez une demande d'exploration pour cette URL via votre compte Google Search Console.
Pour vous tenir au courant de ces erreurs d'exploration, vous pouvez utiliser le rapport Index > Couverture de votre compte Google Search Console. Ou utilisez l'outil d'audit de site de SearchAtlas pour trouver le rapport d'erreur de votre site à transmettre à votre développeur Web.
Remarque : Les nouvelles URL peuvent ne pas apparaître immédiatement dans votre analyse de fichier journal. Donnez à Google le temps de les trouver avant de demander une exploration.
6. Travailler sur l'amélioration des vitesses de chargement des pages
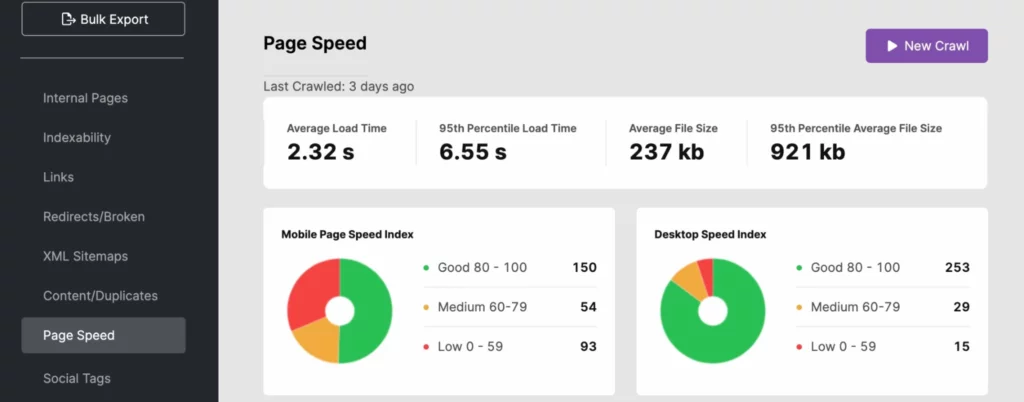
Les robots des moteurs de recherche peuvent parcourir un site à un rythme rapide. Cependant, si la vitesse de votre site n'est pas à la hauteur, cela peut vraiment peser lourdement sur votre budget de crawl. Utilisez votre analyse de fichier journal, SearchAtlas ou PageSpeedInsights pour déterminer si le temps de chargement de votre site affecte négativement votre visibilité de recherche.
Pour améliorer le temps de réponse de votre site, utilisez des URL dynamiques et suivez les bonnes pratiques Core Web Vitals de Google . Cela peut inclure l'optimisation de l'image pour les médias au-dessus du pli.
Si le problème de vitesse du site se situe côté serveur, vous pouvez investir dans d'autres ressources serveur telles que :
- Un serveur dédié (surtout pour les gros sites)
- Mise à niveau vers un matériel serveur plus récent
- Augmenter la RAM
Ces améliorations donneront également un coup de pouce à votre expérience utilisateur, ce qui peut aider votre site à mieux performer dans la recherche Google puisque la vitesse du site est un signal pour le PageRank.
7. N'oubliez pas d'utiliser des balises canoniques
Le contenu dupliqué est mal vu par Google, du moins lorsque vous ne reconnaissez pas que le contenu dupliqué a une page source. Pourquoi? Googlebot parcourt chaque page, sauf inévitablement, sauf indication contraire. Cependant, lorsqu'il rencontre une page en double ou une copie de quelque chose qui lui est familier (sur votre page ou hors site), il arrête d'explorer cette page. Et même si cela fait gagner du temps, vous devriez faire gagner encore plus de temps au robot d'exploration en utilisant une balise canonique qui identifie l'URL canonique.

Les canoniques indiquent au Googlebot de ne pas prendre la peine d'utiliser votre période d'exploration pour indexer ce contenu. Cela donne au robot du moteur de recherche plus de temps pour examiner vos autres pages.
8. Concentrez-vous sur votre structure de liens internes
Avoir une pratique de liens bien structurée au sein de votre site peut augmenter l'efficacité d'un crawl Google. Les liens internes indiquent à Google quelles pages de votre site sont les plus importantes, et ces liens aident les robots à trouver des pages plus facilement.
Les meilleures structures de liens relient les utilisateurs et les Googlebots au contenu de votre site Web. Utilisez toujours un texte d'ancrage pertinent et placez vos liens naturellement dans votre contenu.
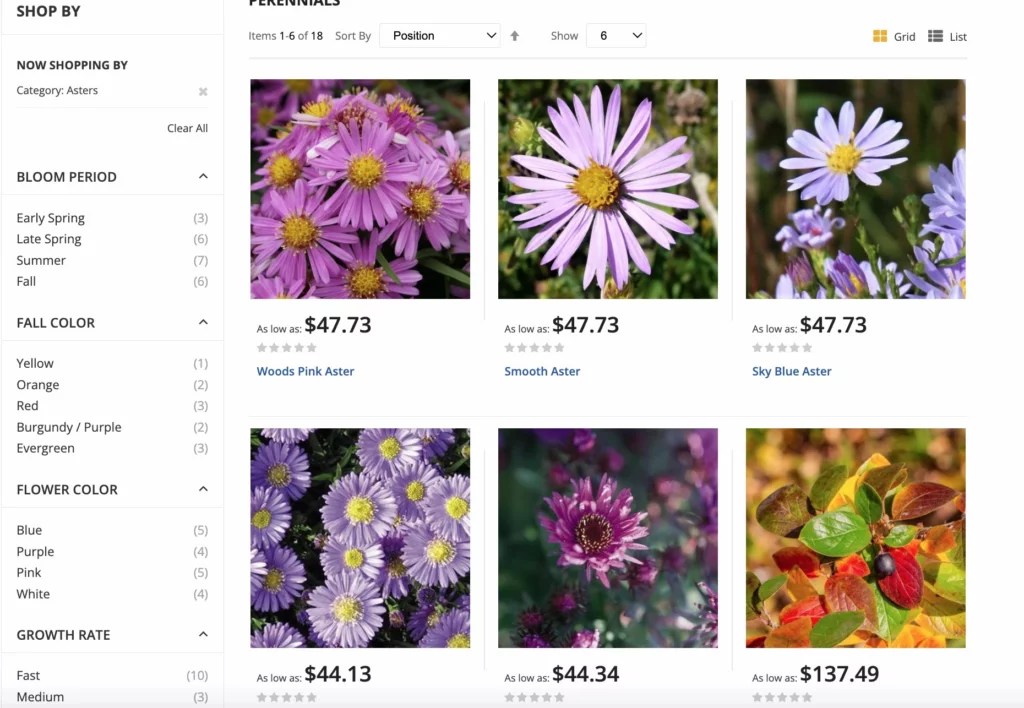
Pour les sites de commerce électronique, Google a des bonnes pratiques pour les options de navigation à facettes afin de maximiser les crawls. La navigation à facettes permet aux utilisateurs du site de filtrer les produits par attributs, ce qui améliore l'expérience d'achat. Cette mise à jour permet d'éviter la confusion canonique et les problèmes de duplication en plus des explorations d'URL excessives.
9. Élaguez le contenu inutile

Les Googlebots ne peuvent se déplacer que si vite et indexer autant de pages à chaque fois qu'ils explorent un site. Si vous avez un grand nombre de pages qui ne reçoivent pas de trafic ou qui ont un contenu obsolète ou de mauvaise qualité, coupez-les ! Le processus d'élagage vous permet de supprimer l'excédent de bagages de votre site qui peut l'alourdir.
Avoir des pages excessives sur votre site peut détourner les Googlebots vers des pages sans importance tout en ignorant les pages.
N'oubliez pas de rediriger tous les liens vers ces pages, afin de ne pas vous retrouver avec des erreurs d'exploration.
10. Accumulez plus de backlinks
Tout comme les Googlebots arrivent sur votre site puis commencent à indexer les pages en fonction des liens internes, ils utilisent également des liens externes dans le processus d'indexation. Si d'autres sites sont liés au vôtre, Googlebot se rendra sur votre site et indexera les pages afin de mieux comprendre le contenu lié.
De plus, les backlinks donnent à votre site un peu plus de popularité et de récence, ce que Google utilise pour déterminer la fréquence à laquelle votre site doit être indexé.
11. Éliminer les pages orphelines
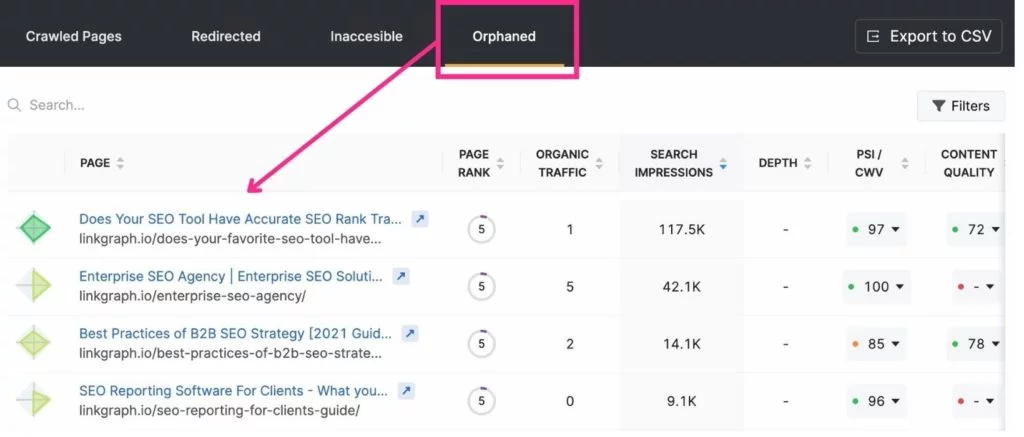
Étant donné que le robot d'exploration de Google saute d'une page à l'autre via des liens internes, il peut trouver les pages auxquelles ils sont liés sans effort. Cependant, les pages qui ne sont pas liées quelque part sur votre site passent souvent inaperçues de Google. Celles-ci sont appelées « pages orphelines ».
Quand est-ce une page orpheline appropriée ? S'il s'agit d'une page de destination qui a un objectif ou un public très spécifique. Par exemple, si vous envoyez un e-mail à des golfeurs qui vivent à Miami avec une page de destination qui ne s'applique qu'à eux, vous ne voudrez peut-être pas créer de lien vers la page d'un autre.
Les meilleurs outils pour l'optimisation du budget de crawl
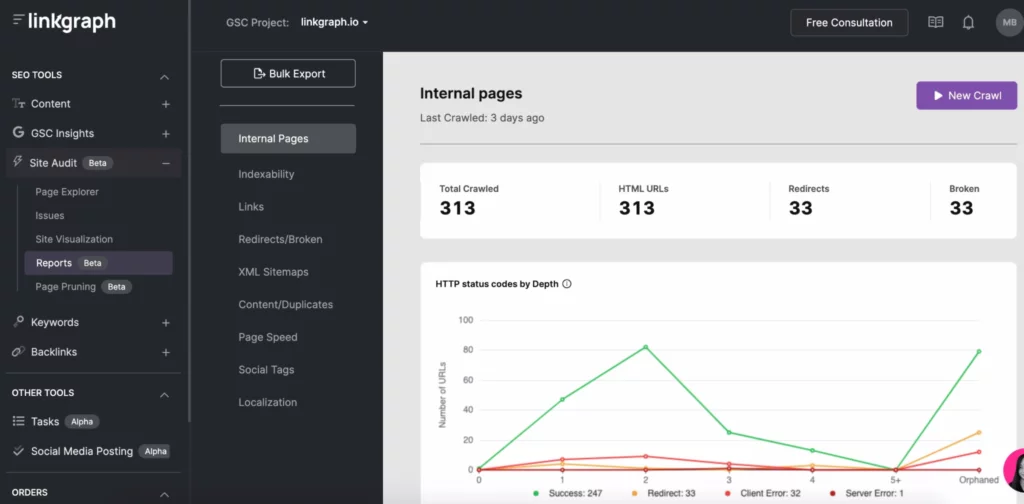
La Search Console et Google Analytics peuvent s'avérer très utiles pour optimiser votre budget de crawl. La Search Console vous permet de demander à un robot d'exploration d'indexer les pages et de suivre vos statistiques d'exploration. Google Analytics vous aide à suivre votre parcours de liens internes.
D'autres outils de référencement, tels que SearchAtlas, vous permettent de trouver facilement des problèmes d'exploration grâce aux outils d'audit de site. Avec un seul rapport, vous pouvez voir votre site :
- Rapport d'exploration d'indexabilité
- Profondeur d'index
- Vitesse des pages
- Contenu dupliqué
- Plan du site XML
- Liens
Optimisez votre budget de crawl et devenez l'un des moteurs de recherche les plus performants
Bien que vous ne puissiez pas contrôler la fréquence à laquelle les moteurs de recherche indexent votre site ou pendant combien de temps, vous pouvez optimiser votre site pour tirer le meilleur parti de chacune de vos explorations des moteurs de recherche. Commencez par les journaux de votre serveur et examinez de plus près votre rapport d'exploration sur la Search Console. Ensuite, plongez dans la résolution des erreurs d'exploration, de la structure de vos liens et des problèmes de vitesse de page.
Au fur et à mesure que vous travaillez sur votre activité d'exploration GSC, concentrez-vous sur le reste de votre stratégie de référencement, y compris la création de liens et l'ajout de contenu de qualité . Au fil du temps, vous constaterez que vos pages de destination grimpent dans les pages de résultats des moteurs de recherche.