
Qu'est-ce qu'un budget de crawl et comment l'optimiser pour le référencement ?
Publié: 2023-06-14Chez FATJOE, nous nous efforçons de créer un contenu de qualité pour les pages Web et de sécuriser des liens puissants vers ces pages.
Mais comment les moteurs de recherche comme Google trouvent-ils ces pages ? La réponse est rampante.
Les robots d'exploration de Google accèdent aux sites Web, suivent les liens et analysent le contenu de chaque page pour ajouter l'URL à son index.
Le budget d'exploration correspond aux ressources que les moteurs de recherche allouent pour explorer les pages Web dans un laps de temps spécifique. Il détermine le nombre de pages de votre site que les robots exploreront et la fréquence à laquelle ils reviendront.
La gestion du budget de crawl est vraiment importante pour les propriétaires de sites Web et les équipes de référencement,en particulier ceux qui ont de grands sites .
En optimisant le budget de crawl, vous pouvez vous assurer que les moteurs de recherche indexent les pages importantes de votre site. Cela peut améliorer votre visibilité dans les résultats de recherche et garantir que les moteurs de recherche voient votre contenu .
Dans ce guide, nous aborderons :
- Qu'est-ce qu'un budget de crawl ?
- Comment ça fonctionne
- Pourquoi c'est important pour le référencement
- Comment augmenter son budget de crawl
Qu'est-ce qu'un budget de crawl ?
Le budget de crawl correspond aux ressources que les moteurs de recherche accordent à un site Web pour explorer et indexer ses pages Web.
C'est un gros problème dans l'optimisation des moteurs de recherche (SEO) car il détermine l'efficacité avec laquelle Google et les autres moteurs de recherche peuvent trouver et inclure vos pages dans les résultats de recherche.
Pourquoi les moteurs de recherche attribuent-ils des budgets de crawl ?
Google a son propre robot d'exploration appelé GoogleBot, qui explore et indexe les pages Web.
Mais Internet est énorme.
Google n'a aucun moyen d'explorer et d'indexerchaquepage dechaquesite Web.
Ainsi, pour s'assurer qu'il atteint les pages les plus pertinentes pour les utilisateurs de recherche, Google attribue des budgets d'exploration aux sites Web.
C'est la même chose pour les moteurs de recherche autres que Google, mais nous nous concentrerons sur Google étant donnéque c'est Google.
Quels sont les différents types de robots d'exploration Google ?
Les moteurs de recherche ont différents types de robots d'exploration pour recueillir des informations sur les pages Web. Nous avons résumé ici les principaux types de robots d'exploration et de récupération :

GoogleBot
Il s'agit du principal robot d'exploration utilisé par Google pour découvrir et indexer les pages Web. Il examine tout le contenu HTML, suit les liens et analyse le contenu des pages Web.
Robots d'exploration de cas spéciaux
Ces robots d'exploration sont utilisés pour des tâches spécifiques, telles que la collecte d'informations sur l'accessibilité. Les robots d'exploration de cas particuliers peuvent ou non respecter les règles de robots.txt.
Extracteurs déclenchés par l'utilisateur
Ce type de robot est utilisé lorsqu'un utilisateur final déclenche une récupération. Par exemple, certains outils de la console de recherche Google enverront des demandes de récupération en fonction des actions de l'utilisateur. Les récupérations déclenchées par l'utilisateur ignorent généralement les règles robots.txt.
Robot d'exploration Google Actualités
Celui-ci se concentre sur l'exploration de contenu lié aux actualités. Il rassemble les dernières informations sur l'actualité et veille à ce qu'elles apparaissent dans les résultats de recherche de Google et sur la plate-forme Google Actualités.
Robot d'exploration d'images Google
Comme son nom l'indique, ce robot est tout au sujet des images. Il parcourt le Web pour trouver des images et analyse des éléments tels que le texte alternatif, les légendes et les noms de fichiers pour comprendre le contexte.
Robot d'exploration vidéo Google
Semblable au robot d'exploration d'images, celui-ci est dédié à la découverte et à l'indexation de contenus vidéo. Il examine les métadonnées vidéo, les légendes et d'autres informations.
Pour un résumé plus complet de chaque robot d'exploration et de récupération Google (y compris le jeton d'agent utilisateur et le cas d'utilisation), passez à la fin pour notre tableau utile !
Exploration mobile d'abord
Étant donné que de plus en plus de personnes utilisent des appareils mobiles pour naviguer sur Internet, Google est passé à l'indexation mobile d'abord.
Google utilise un agent pour smartphone pour explorer et indexer la version mobile des sites Web, avant la version de bureau. S'assurer que votre site Web est adapté aux mobiles est essentiel pour l'exploration de votre site et l'optimisation de votre budget d'exploration.
Le moteur de recherche a récemment achevé le passage massif final à l'indexation mobile d'abord en mai 2023 :
Google effectue un autre premier lot d'indexation mobile en vrac le 22 mai 2023 - finalisant une transition vers la recherche en explorant comme si un navigateur mobile, 6 ans de préparation ! https://t.co/9CxsrRFkcE
– Michael Stricker (@RadioMS) 22 mai 2023
Comment Google affecte-t-il le budget de crawl ?
Le budget de crawl est basé sur deux facteurs : la limite de capacité de crawl et la demande de crawl.
Limite de capacité d'exploration
Les moteurs de recherche surveillent les performances du serveur d'un site Web et sa rapidité de réponse. Ils ajustent la limite de capacité de crawl en fonction des performances du serveur.
La limite est également affectée par les ressources d'exploration disponibles à un moment donné et les préférences du propriétaire du site Web.
Vous pouvez ajuster manuellement votre limite de vitesse d'exploration à partir de la page Paramètres de vitesse d'exploration dans Google Search Console.
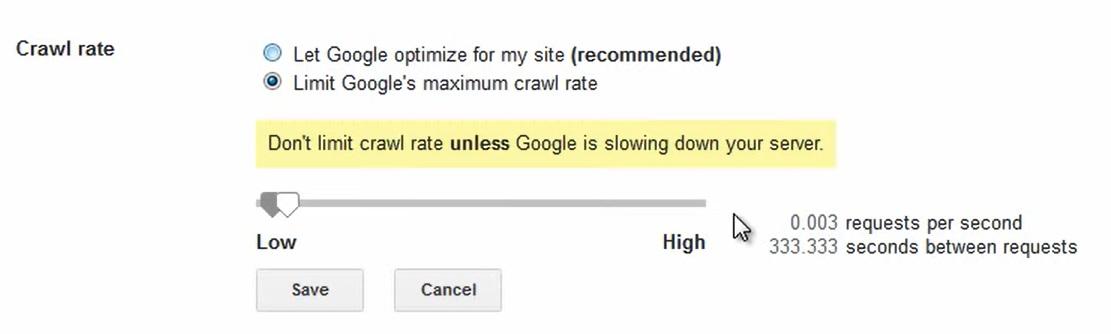
Si vous rencontrez des problèmes de disponibilité, vous pouvez réduire la fréquence d'exploration.
Mais l'augmenter manuellement ne fera pas venir Google explorer votre site Web plus rapidement.Vous ne pouvez pas non plus influencer les pages queGoogle explorera.
Demande d'exploration
La demande de crawl aide les moteurs de recherche à décider quelles pages explorer plus souvent.
Il prend en compte des éléments tels que la taille du site, la fréquence de mise à jour d'une page et la valeur perçue de la page.
Les problèmes techniques de référencement peuvent également avoir un impact sur la demande de crawl.
Est-ce que le budget de crawl n'inclut que les pages Web ?
Non, le budget de crawlne concerne pas seulement les pages .
Nous parlons vraiment de tout document que les moteurs de recherche explorent et de tous les différents éléments qui existent sur une page. Cela inclut des éléments tels que les fichiers JavaScript et CSS, les variantes de pages mobiles, les données structurées et les fichiers PDF.
Comment fonctionne la limite d'exploration ?
La limite d'exploration consiste à maintenir un équilibre entre l'exploration et les ressources du serveur.
Lors de l'exploration d'un site Web, les moteurs de recherche surveillent la réponse du serveur. Si le serveur répond rapidement, la vitesse d'exploration peut augmenter.
Si le serveur montre des signes de fatigue, le moteur de recherche peut réduire la vitesse d'exploration pour alléger la charge du serveur.
Les propriétaires de sites Web peuvent également implémenter des retards d'exploration dans le fichier robots.txt du site. Cela demande aux robots de faire une pause pendant une certaine durée entre des requêtes consécutives sur le site Web.

Comment fonctionne la demande de crawl ?
La demande de crawl est une mesure de l'importance d'une page pour GoogleBot.
Les moteurs de recherche prêtent attention à la structure de liens internes, aux liens externes et aux signaux d'engagement des utilisateurs pour déterminer quelles pages ont une plus forte demande d'exploration.
Voici comment il est décrit sur Google Search Central :
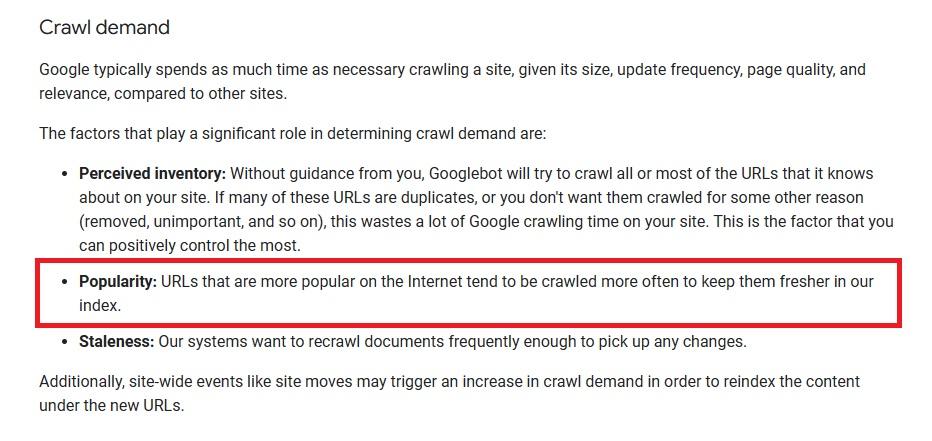
Les backlinks indiquent qu'une page Web est fiable, populaire et mérite d'être explorée.
Les sites Web contenant de nombreux backlinks de haute qualité provenant de sources faisant autorité bénéficient d'un budget d'exploration plus important .
Google souhaite également fournir aux utilisateurs des résultats de recherche à jour, il donne donc la priorité à l'exploration et à l'indexation du nouveau contenu.
Pourquoi le budget de crawl est-il important pour le référencement ?
Le budget de crawl affecte directement la manière dont les moteurs de recherche découvrent et indexent les pages de votre site Web.
Mais il convient de noter que le budget de crawl seul n'est pas un facteur de classement.
C'est aussi quelque chose qui n'affecte généralement pas les petits sites.
Dans une vidéo récente , Google Search Advocate Daniel Waisberg a révélé :
« C'est plus pertinent si vous travaillez avec un grand site Web.Si vous avez un site avec moins de quelques milliers de pages, vous n'avez pas à vous en soucier.
Vous n'avez vraiment à vous soucier du budget de crawl que si vous avez un grand site Web ou une boutique en ligne avec un nombre élevé de pages.
Le budget de crawl peut affecter ou être affecté par les éléments suivants :
Visibilité dans les résultats de recherche
Lorsque le budget d'exploration est limité, l'exploration et le classement des nouvelles pages et du contenu peuvent prendre plus de temps à Google. Si Google ne trouve pas une page en raison de problèmes de budget d'exploration, elle n'apparaîtra pas dans les résultats de recherche .
Structure du site
Si vous gaspillez votre budget d'exploration en ayant un tableau de pages dupliquées ou de faible valeur, Google aura du mal à comprendre quelles pages sont importantes. GoogleBot passera du temps à explorer des parties de votre site qui ne vous aideront pas à vous classer pour vos mots clés cibles.
Une bonne structure de site aide les moteurs de recherche à déterminer les relations entre vos pages, ce qui peut, à son tour, construire votre référencement sémantique.
Autorité thématique
Donner la priorité à l'exploration des pages importantes et se concentrer sur un contenu de haute qualité peut renforcer votre autorité thématique.
Cela augmente vos chances de vous classer plus haut pour les termes de recherche pertinents.
Cannibalisation des mots-clés
La cannibalisation des mots-clés se produit lorsque deux pages d'un site Web se disputent les mêmes mots-clés dans les résultats de recherche.
L'optimisation du budget de crawl vous aide à éviter cela.
Organiser la structure de votre site et éviter le contenu en double permet à Google d'explorer plus facilement votre site et de comprendre votre contenu tout en garantissant que vos pages sont uniques et évitent la concurrence les unes avec les autres dans les résultats de recherche.
Comment optimiser le budget de crawl pour le SEO ?
Alors, comment optimiser le budget de crawl pour de meilleurs résultats SEO ?
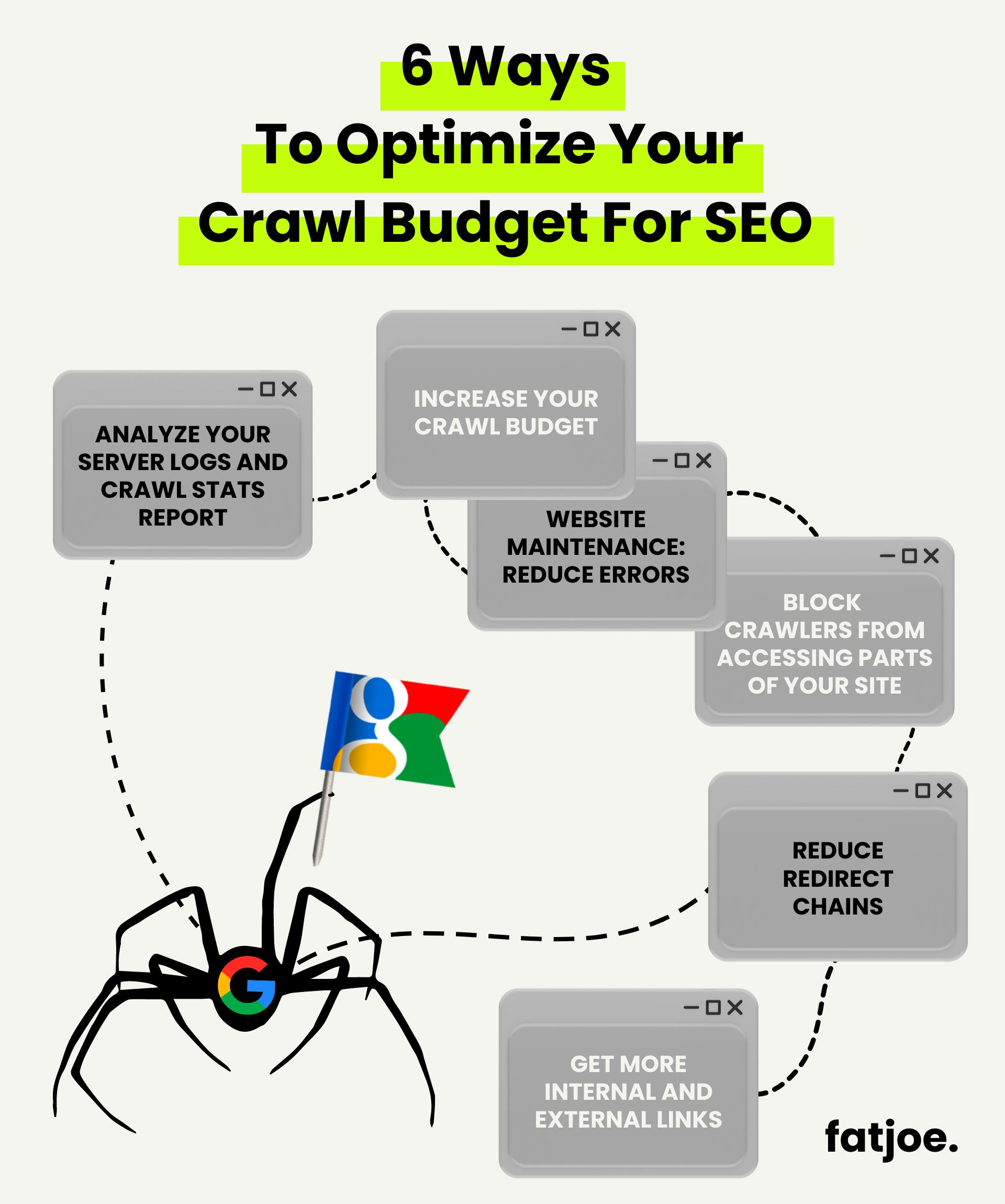
Voici six stratégies que vous pouvez mettre en œuvre :
Stratégie 1 : Jetez un œil à vos journaux de serveur et à votre rapport de statistiques d'exploration
Commencez par analyser les fichiers journaux de votre serveur.
Ces journaux contiennent des informations précieuses sur la façon dont les robots des moteurs de recherche interagissent avec votre site Web. Vous pouvez savoir quelles pages sont explorées, à quelle fréquence elles sont consultées et si des erreurs d'exploration se produisent.
Le rapport Crawl Stats dans Google Search Console peut également fournir des informations utiles.
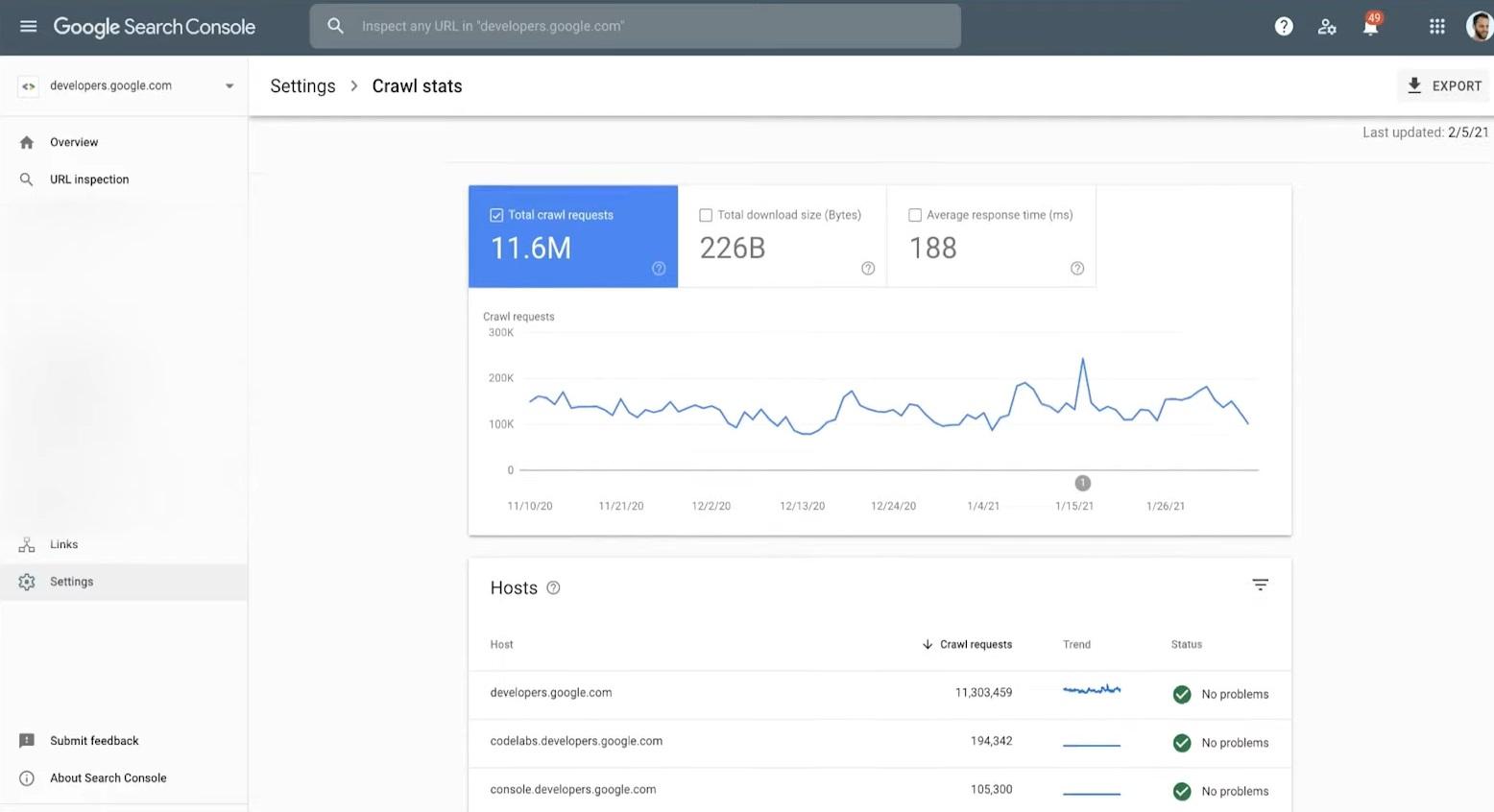
Vous pouvez voir le graphique des tendances d'exploration, les détails de l'état de l'hôte et une répartition des demandes d'exploration.
Stratégie 2 : Augmentez votre budget de crawl
Bien que vous ne puissiez pas contrôler directement le budget de crawl attribué par les moteurs de recherche, vous pouvez toujours l'influencer.
La clé est d'améliorer la qualité globale et la pertinence de votre site Web.
Voici une ventilation par Peter Nikolow, PDG de Mobilo :
"Crawl budget" & votre site :
– Budget de crawl – demande de crawl vs capacité vs nécessité
Augmenter la demande - créer un site génial
Augmenter la capacité - rendre le site rapide
Réduisez la nécessité - moins d'URL, mieux c'est#WMCZRH– Peter Nikolow (@PeterNikolow) 11 décembre 2019
Voici comment vous pouvez mettre ces conseils en pratique :
Publiez régulièrement du contenu frais et de haute qualité
Garder votre site Web à jour avec du nouveau contenu montre aux moteurs de recherche que votre site est actif.
Il signale aux moteurs de recherche que votre contenu offre des informations précieuses, augmentant potentiellement le budget de crawl de votre site Web.
Améliorer le temps de chargement des pages
Les pages à chargement lent peuvent entraver le processus d'exploration et d'indexation.
Voici comment Google le décrit :

Si vos pages se chargent rapidement, Google peut explorer davantage votre site et indexer davantage de vos pages.
Travaillez sur la compression des images et utilisez des techniques de mise en cache pour améliorer la vitesse du site.
Garantir la compatibilité mobile
Google utilise la version mobile de votre site pour l'indexation et le classement.
Il est donc crucial d'avoir un site Web adapté aux mobiles.
Voici quelques conseils du blog Google Search Central :
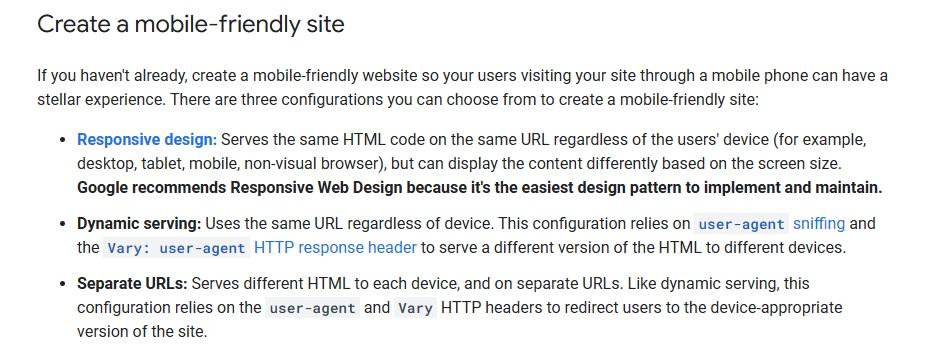
Stratégie 3 : Maintenance du site Web : réduire les erreurs
Les liens brisés, les pages 404 et les erreurs de serveur peuvent ralentir les robots des moteurs de recherche et grignoter votre budget d'exploration.
Cela peut inclure des liens brisés qui ne mènent nulle part, des pages introuvables ou des problèmes de serveur qui causent des perturbations.
Effectuez des audits de routine du site Web pour identifier les pages qui ne sont pas explorées correctement ou qui causent des erreurs.
Stratégie 4 : empêcher les robots d'exploration d'accéder à certaines parties de votre site
Parfois, vous pouvez avoir des parties de votre site Web qui ne sont pas vraiment pertinentes pour les moteurs de recherche à explorer ou à indexer.
Pensez aux pages d'administration et au contenu dupliqué.
Vous pouvez utiliser le fichier "robots.txt" pour indiquer aux robots des moteurs de recherche d'éviter ces sections.
De cette façon, GoogleBot peut se concentrer sur l'exploration et l'indexation des pages importantes de votre site Web.
Stratégie 5 : Réduire les chaînes de redirection
Les chaînes de redirection peuvent utiliser votre budget de crawl.
GoogleBot doit parcourir plusieurs redirections à la suite avant d'atterrir finalement sur l'URL de destination.
Toutes ces redirections inutiles accaparent le budget de crawl sans donner de valeur supplémentaire.
Astuce SEO technique : chaque redirection que vous ajoutez ralentit votre site Web.
Ajouter trop de redirections peut avoir un impact négatif sur le Time To First Byte de votre site : pic.twitter.com/hzW8ehgRMg
– Chris Long (@gofishchris) 1er juin 2023
Minimiser les chaînes de redirection peut aider les moteurs de recherche à atteindre les pages de destination plus rapidement. Cela facilite le voyage d'un point A à un point B pour les crawlers et les utilisateurs.
Stratégie 6 : Obtenez plus de liens internes et externes
Obtenir plus de backlinks de sites Web dignes de confiance peut augmenter la visibilité et l'autorité de votre site.
Comme les moteurs de recherche vous reconnaissent comme une source faisant autorité, ils seront plus susceptibles d'allouer une plus grande partie du budget de crawl à votre site Web.
Les liens internes sont également importants.
Les pages orphelines sont l'un des plus gros gaspillages de budget de crawl.
Ce sont des pages Web qui n'ont pas de liens internes ou de liens externes pointant vers elles.
Selon une étude récente de Botify, les pages qui ne sont pas liées consomment 26% du budget de crawl de Google :
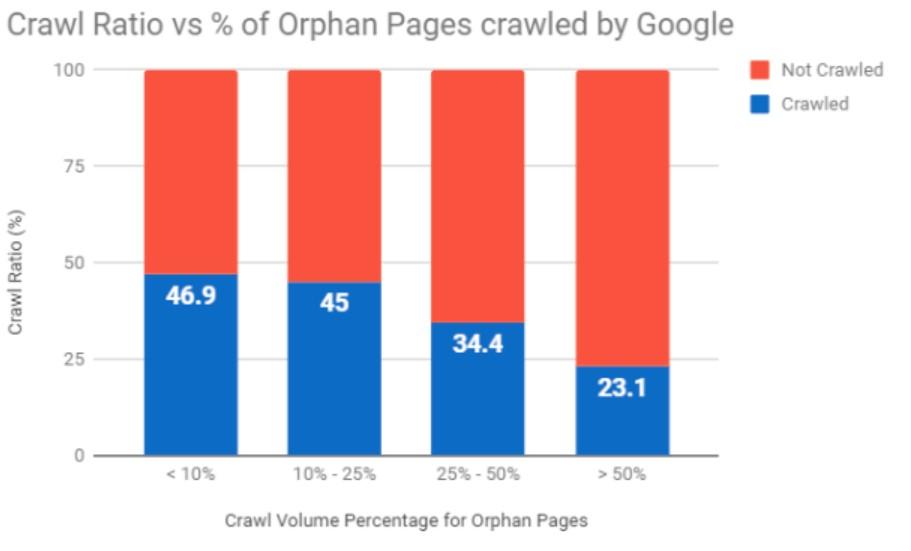
Source : Botifier
Les liens internes contextuels aident GoogleBot à trouver et à indexer toutes les pages de votre site Web.
Vous pouvez utiliser plus efficacement votre budget de crawl en vous assurant que chaque page que vous souhaitez indexer comporte au moins un lien interne pointant vers elle.
Tirez le meilleur parti du budget de crawl de votre site
L'optimisation du budget de crawl est un élément important d'une stratégie de référencement réussie.
Il s'agit de le rendre aussi simple que possible pour GoogleBot. En comprenant comment fonctionne le budget de crawl et comment l'optimiser, vous pouvez vous assurer que Google explore et indexe vos pages aussi souvent que possible.
Cela améliorera votre visibilité dans les résultats de recherche et vous aidera à attirer plus de trafic organique.
Vous consacrez du temps, des efforts et de l'argent à la production de pages Web de haute qualité avec un excellent contenu ; assurez-vous que ce n'est pas du travail inutile en vous assurant que vos pages peuvent être explorées et vues par les moteurs de recherche.
Enfin, recherchez-vous une ventilation complète de tous les robots d'exploration et de récupération Google , y compris leur jeton d'agent utilisateur et leur cas d'utilisation ? Consultez notre infographie pratique ci-dessous!
