
L'état de l'apprentissage en profondeur : du point de vue d'un développeur et d'un VC
Publié: 2017-09-05Nikhil Kapur discute de l'état de l'apprentissage en profondeur, d'abord en tant qu'étudiant développeur et maintenant en tant que VC
J'ai passé un samedi dans un atelier d'apprentissage en profondeur et TensorFlow dans le gigantesque bureau de niveau 3 d'Unilever Foundry et Padang.co. Ce fut une journée amusante à nouveau immergée dans le monde du développement, et j'ai apprécié toutes les conversations avec mes compagnons de table, l'un d'eux dirigeant une entreprise familiale et apprenant le ML/apprentissage en profondeur comme passe-temps (il est un passionné de programmation) et l'autre de Le département marketing de Zalora cherche à appliquer de l'IA dans son travail.
Nous avons commencé par configurer TensorFlow et Keras (une abstraction sur TensorFlow) sur nos machines, puis nous avons commencé à bricoler certains des problèmes courants d'apprentissage en profondeur et des exemples tels que l'utilisation de l'ensemble de données MNIST. En partant d'un simple petit modèle NLP pour la reconnaissance de texte, nous nous sommes plongés dans les réseaux de neurones convolutifs , qui se sont avérés très amusants à utiliser.
Nous utilisions des modèles pré-formés prêts à l'emploi, tels que Inception V3, mais jouions avec nos propres ensembles de données et réentraînions le modèle pour résoudre différents problèmes tels que "Est-ce un chat ou un chien?" L'objectif de la classe était de comprendre les bases de l'apprentissage en profondeur et d'expérimenter des paramètres et des fonctionnalités. Si vous vous sentez jaloux maintenant, alors je vous suggère d'aller jouer avec playground.tensorflow.org, c'était la partie la plus facile à obtenir de l'atelier !
Un grand bravo à Sam Witteveen et Martin Andrews pour avoir organisé cela. Je raconte ici certaines des perspectives avec lesquelles je suis sorti, et où je vois l'apprentissage en profondeur et l'IA en général, en particulier du point de vue du VC.
Apprentissage en profondeur du point de vue d'un développeur
Pour donner un peu de contexte, j'ai eu ma juste dose d'exposition à "l'IA". En deuxième année de collège, j'ai effectué un stage dans la branche Technology Consulting de Deloitte. Avec mon ami Ujjwal Dasgupta, qui a ensuite fait une maîtrise en ML et qui est maintenant chez Google, j'ai passé quelques mois à élaborer un processus ETL (Extract-Transform-Load) amélioré sur IBM Datastage, un logiciel d'entreposage de données. À l'époque, Ujjwal, qui était toujours beaucoup plus tourné vers l'avenir que moi, m'a initié à l'exploration de données, et j'ai commencé à suivre les conférences et les cours en ligne d'Andrew Ng.
L'été suivant, intrigué par le temps que j'avais déjà passé sur le sujet, j'ai voulu plonger plus profondément dans le ML. J'ai eu la chance d'être affecté à un projet chez Mozilla pour améliorer les performances de Firefox à l'aide d'un compilateur basé sur l'apprentissage automatique - Milespot GCC. À l'aide de ce compilateur ML, j'ai pu compiler le code de Mozilla Firefox pour obtenir une amélioration d'environ 10 % du temps de chargement du programme.
Et puis pour ma thèse de fin d'études, il était hors de question que je lâche ML. J'ai collaboré avec DFKI, l'Institut allemand d'intelligence artificielle, pour travailler sur un projet extrêmement difficile, en utilisant une simple webcam pour le suivi oculaire. L'équipe de DFKI l'utilisait pour une application particulière, Text 2.0. Ils utilisaient une caméra HD spéciale pour suivre vos yeux et augmenter en conséquence le texte avec des fonctionnalités méga-cool telles que le défilement automatique, la traduction automatique, le dictionnaire contextuel, etc.
Nous avons décidé de faire la même chose avec une simple webcam car personne en Inde n'avait l'argent pour acheter cette caméra HD spéciale. Pour être précis, nous avons échoué, n'atteignant qu'environ 70% de précision dans notre suivi. Mais c'était l'un des projets les plus excitants sur lesquels j'avais travaillé.
Recommandé pour vous:

Comment Metaverse va transformer l'industrie automobile indienne

Que signifie la disposition anti-profit pour les startups indiennes ?

Comment les startups Edtech aident la main-d'œuvre indienne à se perfectionner et à se préparer pour l'avenir...

Stocks technologiques de la nouvelle ère cette semaine : les problèmes de Zomato continuent, EaseMyTrip publie des...

Les startups indiennes prennent des raccourcis à la recherche de financement

La plate-forme de marketing numérique Logicserve met en sac un financement INR 80 Cr et se rebaptise LS Dig ...
Alors pourquoi est-ce que je t'ennuie avec les détails de ça ? Principalement pour vous donner un peu d'histoire sur l'endroit où se trouvait l'IA lorsque je parcourais mon ingénierie. Il y a même des décennies, l'apprentissage en profondeur et le ML existaient déjà, mais ce n'est qu'au cours des 10 dernières années que le domaine a atteint sa maturité. Qu'est-ce qui a changé exactement ces dernières années ?

Eh bien, d'une part, la loi de Moore nous a amenés à un point où le coût de stockage et de traitement est devenu minime pour que quelqu'un puisse mettre en œuvre le ML chez lui. Vous pouvez maintenant exécuter à peu près tous les modèles de base sur votre propre machine, et si vous achetez un bon GPU (qui n'est plus si cher), il peut optimiser votre temps de calcul de près de 10 fois pour pouvoir exécuter des modèles complexes.
Le magazine Wired a un excellent article sur ce changement.
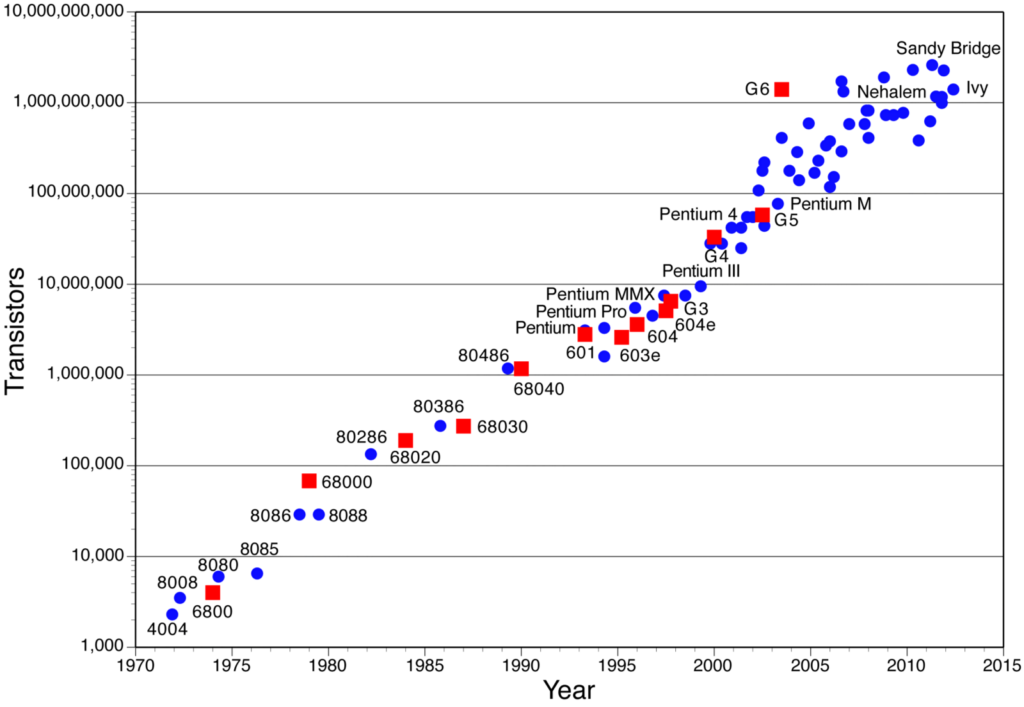
Nombre de transistors dans les puces au cours de l'année (notez que l'axe Y est à l'échelle logarithmique !). Source : Systèmes assurés
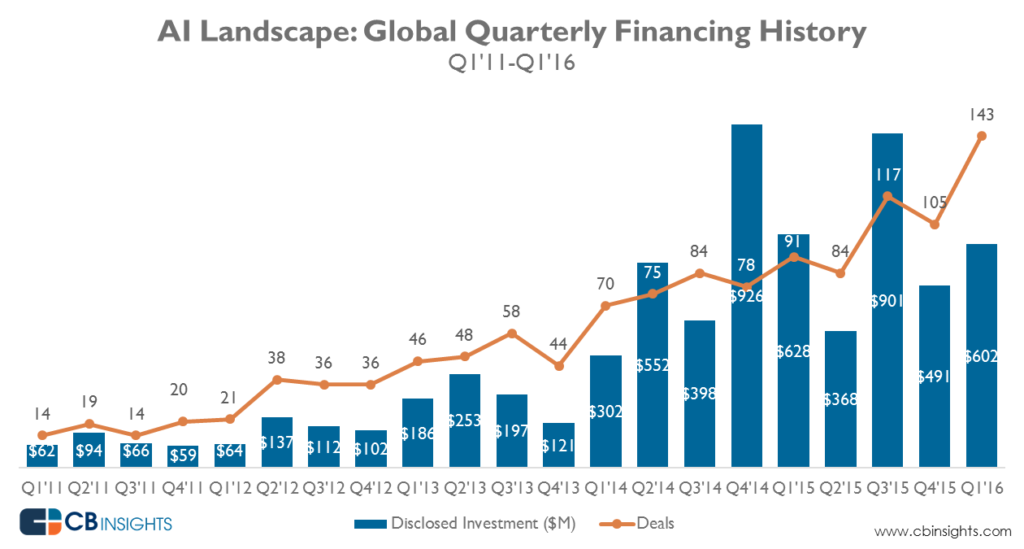
Une autre chose qui a changé est que les entreprises ont réalisé la nécessité d'automatiser. En conséquence, alors que l'activité de fusions et acquisitions dans le domaine a considérablement augmenté, les VC ont versé de l'argent dans le domaine au cours des 5 dernières années.
Perspectives des investisseurs sur l'apprentissage en profondeur
Alors, où en sommes-nous maintenant et comment un investisseur ou une startup devrait-il voir ce buzz extrême de l'IA ? Selon moi, il y a quatre aspects clés dans une startup d'IA, qui doivent tous être réunis pour former une entreprise solide.
- Talent : Tout commence ici. Alors que dans une startup, l'équipe est évidemment l'aspect le plus important, dans une startup IA c'est le véritable moteur de l'entreprise. L'accès à de solides talents en science des données et en ingénierie informatique pour affiner ces modèles prédéfinis sera essentiel pour les startups d'IA, et c'est pourquoi les startups américaines et chinoises sont susceptibles d'avoir une avance sur d'autres zones géographiques. Singapour possède un petit échantillon de talents en science des données et est probablement un bon endroit pour créer votre entreprise d'IA. Cela dit, les meilleurs talents finiront probablement par aller vers les géants de la technologie, de manière organique ou inorganique. L'acquisition de DeepMind par Google était exactement cela, un jeu pour acquérir certains des meilleurs esprits du Deep Learning.
- Données : Si l'équipe est le moteur, alors les données sont l'essence d'une startup d'IA. Sans de grandes quantités de données propres et structurées, il est peu probable que vous puissiez obtenir une quelconque précision de votre système formé, ce qui entrave les applications métier. En raison de la dépendance essentielle des capacités de prédiction d'un modèle sur les données fournies, les grandes entreprises sont susceptibles d'avoir un avantage significatif sur les start-ups à petite échelle pour proposer des systèmes meilleurs et plus précis. C'est une pensée troublante et la seule façon de briser le moule sera de générer et d'exploiter vos propres données propriétaires. Un système d'enregistrements tel que Salesforce va être extrêmement critique à cet égard.
- Modèle : Tous les grands géants de la technologie lancent actuellement leurs propres systèmes d'IA (plateforme de développement, bibliothèques, modèles entraînés) pour créer LA plate-forme du développement de l'IA de demain. Il reste à déterminer qui gagnera la guerre, mais la nécessité de créer des modèles à partir de zéro sera tôt ou tard terminée. Ce n'est que pour les systèmes vraiment complexes qu'il serait nécessaire de commencer à construire vos modèles à partir des bases, mais dans la plupart des cas, votre scientifique des données pourra réutiliser des modèles prêts à l'emploi et les recycler en utilisant ses propres données. Comment savez-vous que vous avez atteint le meilleur modèle possible ? Numerai, soutenu par Union Square Ventures, s'attaque à ce problème de manière très intelligente, en faisant appel à des experts en ML et en les incitant financièrement à créer de meilleurs modèles.
- Problème commercial : C'est là que les choses deviennent intéressantes. Premièrement, un utilisateur ne se soucie pas de savoir si vos systèmes sont automatisés ou non. Les systèmes d'IA sont destinés à optimiser votre propre organisation et à faire en sorte qu'une machine exécute la tâche d'un humain, et non à épater un utilisateur. Par conséquent, la résolution d'un problème métier particulier est essentielle pour offrir une bonne expérience utilisateur et donc augmenter l'adhérence.
Deuxièmement, la plupart des géants de la technologie vont se limiter à construire une plate-forme large et générique. Alors que les entreprises technologiques telles que Salesforce, Hubspot, etc. sautent sur l'IA, la leur sera probablement une voie d'acquisition. Salesforce a déjà annoncé Einstein (mais n'a pas encore suivi correctement ses proclamations) et Hubspot écrit chaque semaine sur l'IA sur son blog. Cela montre seulement à quel point ils sont intéressés par le terrain mais aussi à quel point il leur est difficile de cibler des problèmes spécifiques. C'est là qu'existent les lacunes qu'une startup peut exploiter et notre société de portefeuille Saleswhale suit exactement cette voie.
À mes yeux, si une startup résout grâce à l'automatisation un problème très ciblé qui affecte un nombre suffisant de personnes utilisant des données propriétaires que ses systèmes collectent en cours de route, il est probable que ce soit une activité très lucrative avec de fortes barrières à l'entrée. Cependant, pour autant que je sache, il est peu probable que ce soit une opportunité de la taille d'une licorne dans la région, pas tant que les géants de la technologie sont encore en vie.
[Ce message de Nikhil Kapur est apparu pour la première fois sur Medium et a été reproduit avec permission.]