
Apprentissage efficace : le futur proche de l'IA
Publié: 2017-11-09Ces techniques d'apprentissage efficaces ne sont pas de nouvelles techniques d'apprentissage en profondeur / d'apprentissage automatique, mais augmentent les techniques existantes en tant que hacks
Il ne fait aucun doute que l'avenir ultime de l'IA est d'atteindre et de dépasser l'intelligence humaine. Mais c'est un exploit farfelu à réaliser. Même les plus optimistes d'entre nous parient que l'IA au niveau humain (AGI ou ASI) sera d'ici 10 à 15 ans, les sceptiques étant même prêts à parier que cela prendra des siècles, si possible. Eh bien, ce n'est pas le sujet du message.
Ici, nous allons parler d'un avenir plus tangible et plus proche et discuter des algorithmes et techniques d'IA émergents et puissants qui, à notre avis, vont façonner l'avenir proche de l'IA.
L'IA a commencé à améliorer les humains dans quelques tâches sélectionnées et spécifiques. Par exemple, battre des médecins pour diagnostiquer un cancer de la peau et vaincre des joueurs de go au championnat du monde. Mais les mêmes systèmes et modèles échoueront dans l'exécution des tâches différentes de celles pour lesquelles ils ont été formés. C'est pourquoi, à long terme, un système généralement intelligent qui exécute efficacement un ensemble de tâches sans avoir besoin de réévaluation est qualifié d'avenir de l'IA.
Mais, dans le futur proche de l'IA, bien avant que l'AGI n'apparaisse, comment les scientifiques feront-ils pour que les algorithmes alimentés par l'IA surmontent les problèmes auxquels ils sont confrontés aujourd'hui pour sortir des laboratoires et devenir des objets d'usage quotidien ?
Quand vous regardez autour de vous, l'IA gagne un château à la fois (lisez nos articles sur la façon dont l'IA dépasse les humains, première et deuxième parties). Qu'est-ce qui pourrait mal tourner dans un tel jeu gagnant-gagnant ? Les humains produisent de plus en plus de données (qui sont le fourrage consommé par l'IA) avec le temps et nos capacités matérielles s'améliorent également. Après tout, les données et un meilleur calcul sont les raisons pour lesquelles la révolution du Deep Learning a commencé en 2012, n'est-ce pas ? La vérité est que la croissance des attentes humaines est plus rapide que la croissance des données et du calcul. Les scientifiques des données devraient penser à des solutions au-delà de ce qui existe actuellement pour résoudre les problèmes du monde réel. Par exemple, la classification des images, comme la plupart des gens le penseraient, est un problème scientifiquement résolu (si nous résistons à l'envie de dire 100 % de précision ou GTFO).
Nous pouvons classer les images (disons en images de chat ou en images de chien) correspondant à la capacité humaine à l'aide de l'IA. Mais cela peut-il déjà être utilisé pour des cas d'utilisation réels ? L'IA peut-elle apporter une solution à des problèmes plus pratiques auxquels les humains sont confrontés ? Dans certains cas, oui, mais dans beaucoup de cas, nous n'en sommes pas encore là.
Nous vous guiderons à travers les défis qui sont les principaux obstacles au développement d'une solution réelle utilisant l'IA. Supposons que vous souhaitiez classer des images de chats et de chiens. Nous utiliserons cet exemple tout au long de l'article.

Notre exemple d'algorithme : Classer les images de chats et de chiens
Le graphique ci-dessous résume les défis :

Défis liés au développement d'une IA du monde réel
Discutons de ces défis en détail :
Apprendre avec moins de données
- Les données de formation que les algorithmes d'apprentissage en profondeur les plus performants consomment nécessitent qu'elles soient étiquetées en fonction du contenu/de la fonctionnalité qu'elles contiennent. Ce processus est appelé annotation.
- Les algorithmes ne peuvent pas utiliser les données trouvées naturellement autour de vous. L'annotation de quelques centaines (ou quelques milliers de points de données) est facile, mais notre algorithme de classification d'images au niveau humain a pris un million d'images annotées pour bien apprendre.
- La question est donc de savoir si annoter un million d'images est possible ? Si ce n'est pas le cas, comment l'IA peut-elle évoluer avec une quantité moindre de données annotées ?
Résoudre divers problèmes du monde réel
- Alors que les ensembles de données sont fixes, l'utilisation dans le monde réel est plus diversifiée (par exemple, un algorithme formé sur des images colorées peut échouer gravement sur des images en niveaux de gris contrairement aux humains).
- Alors que nous avons amélioré les algorithmes de vision par ordinateur pour détecter les objets pour correspondre aux humains. Mais comme mentionné précédemment, ces algorithmes résolvent un problème très spécifique par rapport à l'intelligence humaine qui est beaucoup plus générique à bien des égards.
- Notre exemple d'algorithme d'IA, qui classe les chats et les chiens, ne sera pas en mesure d'identifier une espèce de chien rare s'il n'est pas alimenté avec des images de cette espèce.
Ajustement des données incrémentielles
- Un autre défi majeur concerne les données incrémentielles. Dans notre exemple, si nous essayons de reconnaître les chats et les chiens, nous pourrions former notre IA pour un certain nombre d'images de chats et de chiens de différentes espèces lors de notre premier déploiement. Mais lors de la découverte d'une nouvelle espèce, nous devons entraîner l'algorithme à reconnaître les "Kotpies" avec les espèces précédentes.
- Bien que la nouvelle espèce puisse être plus similaire aux autres que nous ne le pensons et puisse être facilement entraînée pour adapter l'algorithme, il y a des points où cela est plus difficile et nécessite une nouvelle formation et une réévaluation complètes.
- La question est de savoir si nous pouvons rendre l'IA au moins adaptable à ces petits changements ?
Pour rendre l'IA immédiatement utilisable, l'idée est de résoudre les défis susmentionnés par un ensemble d'approches appelées Effective Learning (veuillez noter que ce n'est pas un terme officiel, je l'invente juste pour éviter d'écrire Meta-Learning, Transfer Learning, Few Apprentissage par tir, apprentissage contradictoire et apprentissage multitâche à chaque fois). Chez ParallelDots, nous utilisons maintenant ces approches pour résoudre des problèmes étroits avec l'IA, remportant de petites batailles tout en nous préparant à une IA plus complète pour conquérir de plus grandes guerres. Laissez-nous vous présenter ces techniques une à la fois.
Remarquablement, la plupart de ces techniques d'Apprentissage Efficace ne sont pas quelque chose de nouveau. Ils voient juste une résurgence maintenant. Les chercheurs SVM (Support Vector Machines) utilisent ces techniques depuis longtemps. L'apprentissage contradictoire, en revanche, est issu des travaux récents de Goodfellow sur les GAN et le raisonnement neuronal est un nouvel ensemble de techniques pour lesquelles des ensembles de données sont devenus disponibles très récemment. Voyons en profondeur comment ces techniques vont contribuer à façonner l'avenir de l'IA.
Apprentissage par transfert
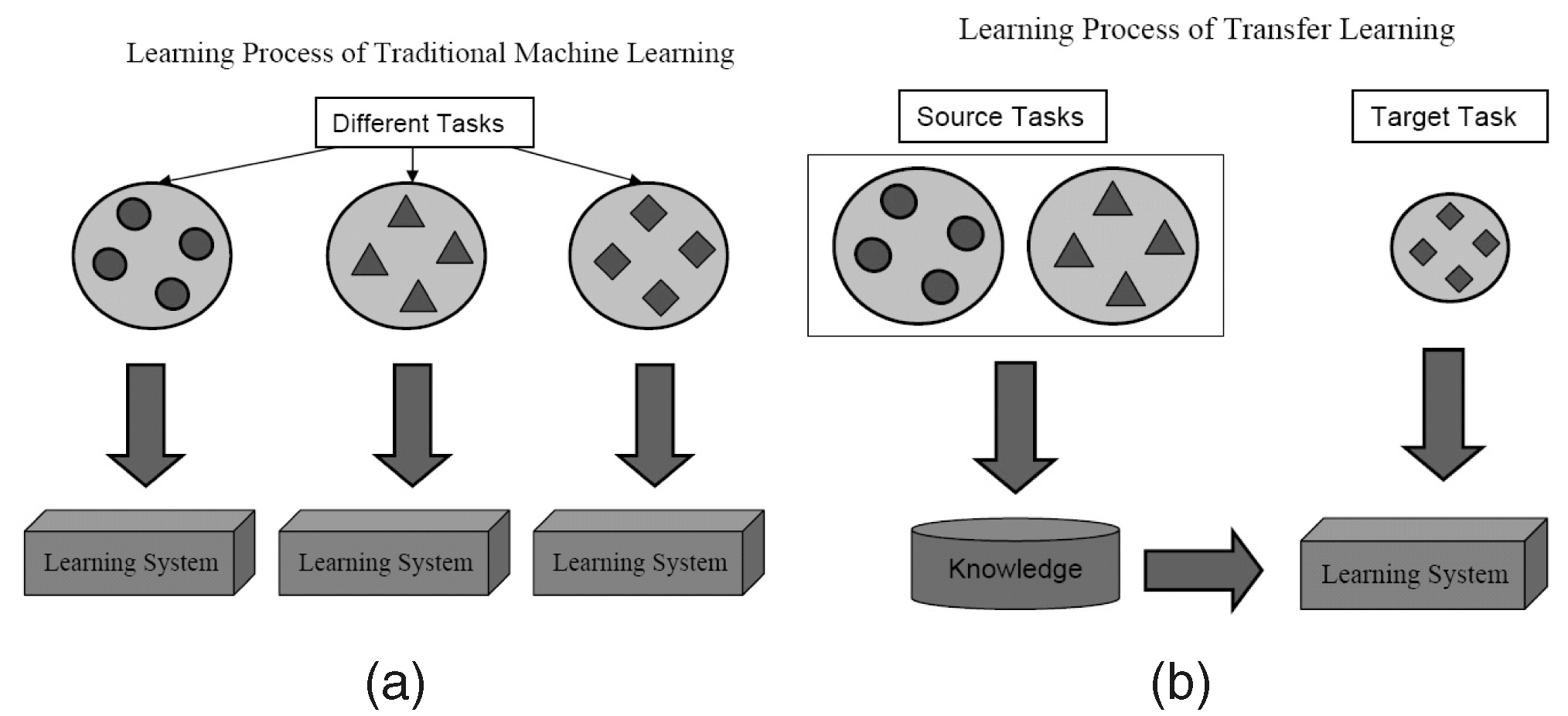
Qu'est-ce que c'est?
Comme son nom l'indique, l'apprentissage est transféré d'une tâche à l'autre au sein du même algorithme dans Transfer Learning. Les algorithmes formés sur une tâche (tâche source) avec un ensemble de données plus grand peuvent être transférés avec ou sans modification dans le cadre d'un algorithme essayant d'apprendre une tâche différente (tâche cible) sur un ensemble de données (relativement) plus petit.
Quelques exemples
L'utilisation des paramètres d'un algorithme de classification d'images comme extracteur de caractéristiques dans différentes tâches telles que la détection d'objets est une application simple de l'apprentissage par transfert. En revanche, il peut également être utilisé pour effectuer des tâches complexes. L'algorithme développé par Google pour classer la rétinopathie diabétique mieux que les médecins il y a quelque temps a été créé à l'aide de l'apprentissage par transfert. Étonnamment, le détecteur de rétinopathie diabétique était en fait un classificateur d'images du monde réel (classificateur d'images chien/chat) Transfer Learning pour classer les scans oculaires.
Dis m'en plus!
Vous trouverez des scientifiques des données appelant ces parties transférées de réseaux de neurones de la source à la tâche cible en tant que réseaux préformés dans la littérature sur le Deep Learning. Le réglage fin se produit lorsque les erreurs de la tâche cible sont légèrement rétropropagées dans le réseau pré-entraîné au lieu d'utiliser le réseau pré-entraîné non modifié. Une bonne introduction technique à l'apprentissage par transfert en vision par ordinateur peut être vue ici. Ce concept simple d'apprentissage par transfert est très important dans notre ensemble de méthodologies d'apprentissage efficace.
Recommandé pour vous:

Comment Metaverse va transformer l'industrie automobile indienne

Que signifie la disposition anti-profit pour les startups indiennes ?

Comment les startups Edtech aident la main-d'œuvre indienne à se perfectionner et à se préparer pour l'avenir...

Stocks technologiques de la nouvelle ère cette semaine : les problèmes de Zomato continuent, EaseMyTrip publie des...

Les startups indiennes prennent des raccourcis à la recherche de financement

La plate-forme de marketing numérique Logicserve met en sac un financement INR 80 Cr et se rebaptise LS Dig ...
Apprentissage multitâche
Qu'est-ce que c'est?
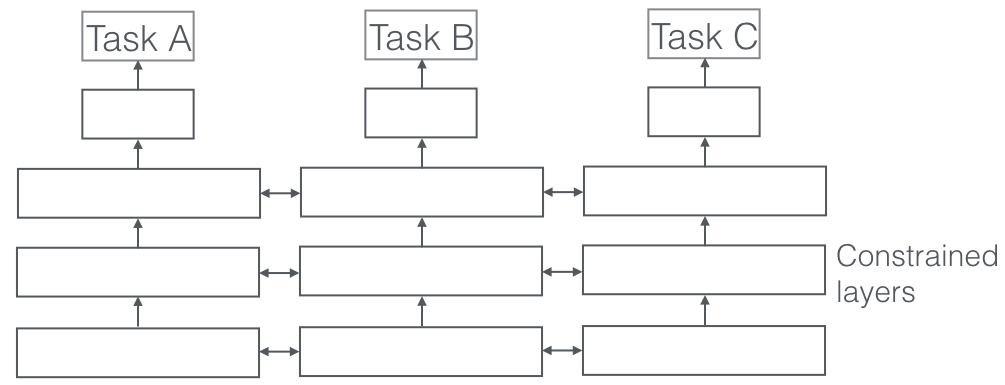

Dans l'apprentissage multitâche, plusieurs tâches d'apprentissage sont résolues en même temps, tout en exploitant les points communs et les différences entre les tâches. C'est surprenant, mais parfois, apprendre ensemble deux ou plusieurs tâches (également appelées tâche principale et tâches auxiliaires) peut améliorer les résultats des tâches. Veuillez noter que toutes les paires, triplets ou quatuors de tâches ne peuvent pas être considérées comme auxiliaires. Mais quand cela fonctionne, c'est un incrément gratuit de précision.
Quelques exemples
Par exemple, chez ParallelDots, nos classificateurs Sentiment, Intent et Emotion Detection ont été formés en tant qu'apprentissage multi-tâches, ce qui a augmenté leur précision par rapport à si nous les avions formés séparément. Le meilleur système d'étiquetage sémantique des rôles et d'étiquetage POS en NLP que nous connaissons est un système d'apprentissage multitâche, c'est donc l'un des meilleurs systèmes de segmentation sémantique et d'instance en vision par ordinateur. Google a proposé des apprenants multitâches multimodaux (un modèle pour les gouverner tous) qui peuvent apprendre à la fois des ensembles de données visuelles et textuelles dans le même plan.
Dis m'en plus!
Un aspect très important de l'apprentissage multitâche que l'on voit dans les applications du monde réel est que la formation de n'importe quelle tâche pour devenir à l'épreuve des balles, nous devons respecter de nombreux domaines d'où proviennent les données (également appelée adaptation de domaine). Un exemple dans nos cas d'utilisation de chat et de chien sera un algorithme qui peut reconnaître des images de différentes sources (par exemple des caméras VGA et des caméras HD ou même des caméras infrarouges). Dans de tels cas, une perte auxiliaire de classification de domaine (d'où proviennent les images) peut être ajoutée à n'importe quelle tâche, puis la machine apprend de telle sorte que l'algorithme continue de s'améliorer dans la tâche principale (classification des images en images de chat ou de chien), mais s'aggrave délibérément à la tâche auxiliaire (ceci est fait en rétropropageant le gradient d'erreur inverse à partir de la tâche de classification de domaine). L'idée est que l'algorithme apprend les caractéristiques discriminantes pour la tâche principale, mais oublie les caractéristiques qui différencient les domaines et cela le rendrait meilleur. L'apprentissage multitâche et ses cousins d'adaptation de domaine sont l'une des techniques d'apprentissage efficace les plus réussies que nous connaissions et ont un rôle important à jouer pour façonner l'avenir de l'IA.
Apprentissage contradictoire
Qu'est-ce que c'est?
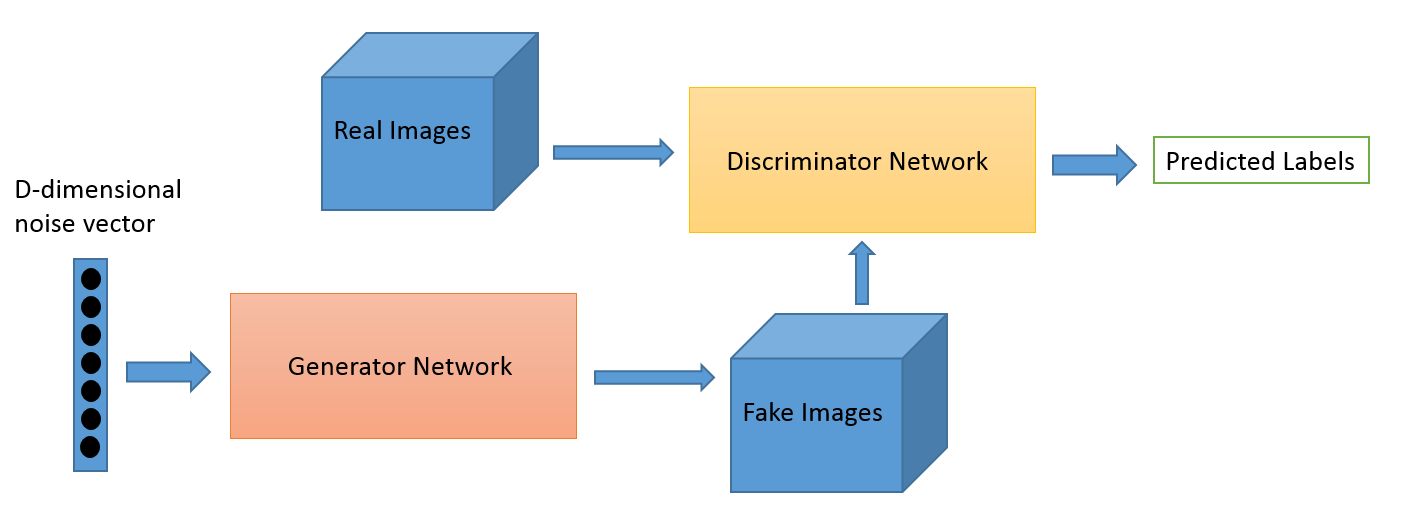
L'apprentissage contradictoire en tant que domaine a évolué à partir des travaux de recherche de Ian Goodfellow. Bien que les applications les plus populaires de l'apprentissage contradictoire soient sans aucun doute les réseaux antagonistes génératifs (GAN) qui peuvent être utilisés pour générer des images époustouflantes, il existe de nombreuses autres façons d'utiliser cet ensemble de techniques. Typiquement, cette technique inspirée de la théorie des jeux a deux algorithmes, un générateur et un discriminateur, dont le but est de se tromper pendant qu'ils s'entraînent. Le générateur peut être utilisé pour générer de nouvelles images nouvelles comme nous en avons discuté, mais peut également générer des représentations de toute autre donnée pour masquer les détails du discriminateur. C'est pourquoi ce concept nous intéresse tant.
Quelques exemples
Il s'agit d'un nouveau domaine et la capacité de génération d'images est probablement ce sur quoi se concentrent la plupart des personnes intéressées comme les astronomes. Mais nous pensons que cela fera également évoluer de nouveaux cas d'utilisation, comme nous le dirons plus tard.
Dis m'en plus!
Le jeu d'adaptation de domaine peut être amélioré en utilisant la perte GAN. La perte auxiliaire ici est un système GAN au lieu d'une classification de domaine pur, où un discriminateur essaie de classer de quel domaine proviennent les données et un composant générateur essaie de le tromper en présentant le bruit aléatoire comme des données. D'après notre expérience, cela fonctionne mieux que l'adaptation de domaine simple (qui est également plus erratique à coder).
Quelques coups d'apprentissage
Qu'est-ce que c'est?
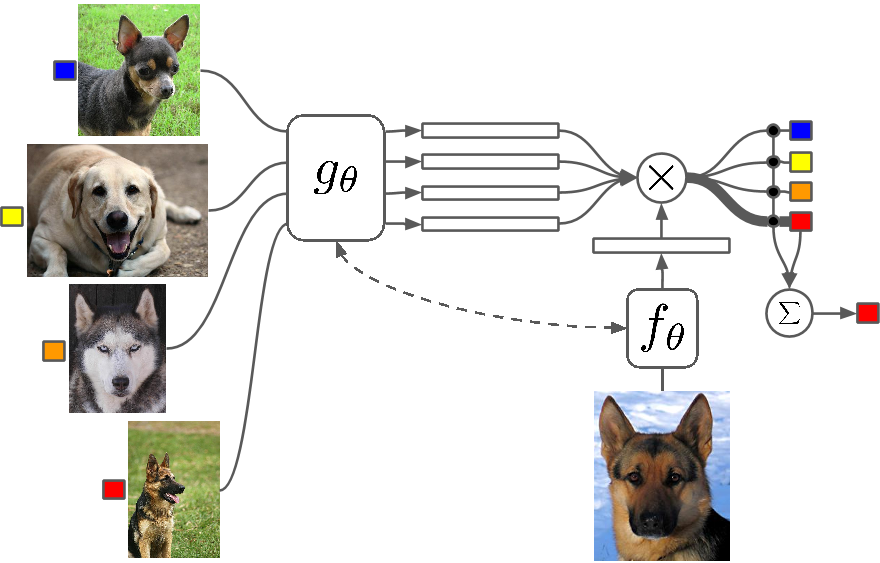
Few Shot Learning est une étude des techniques qui permettent aux algorithmes d'apprentissage en profondeur (ou à tout algorithme d'apprentissage automatique) d'apprendre avec moins d'exemples par rapport à ce qu'un algorithme traditionnel ferait. One Shot Learning consiste essentiellement à apprendre avec un exemple d'une catégorie, l'apprentissage inductif k-shot signifie apprendre avec k exemples de chaque catégorie.
Quelques exemples
Peu de Shot Learning en tant que domaine voit un afflux d'articles dans toutes les grandes conférences sur l'apprentissage en profondeur et il existe désormais des ensembles de données spécifiques sur lesquels comparer les résultats, tout comme le MNIST et le CIFAR pour l'apprentissage automatique normal. L'apprentissage ponctuel voit un certain nombre d'applications dans certaines tâches de classification d'images telles que la détection et la représentation de caractéristiques.
Dis m'en plus!
Plusieurs méthodes sont utilisées pour l'apprentissage Few Shot, notamment l'apprentissage par transfert, l'apprentissage multitâche ainsi que le méta-apprentissage en tant que tout ou partie de l'algorithme. Il existe d'autres moyens comme avoir une fonction de perte intelligente, utiliser des architectures dynamiques ou utiliser des hacks d'optimisation. Zero Shot Learning, une classe d'algorithmes qui prétendent prédire les réponses pour des catégories que l'algorithme n'a même pas vues, sont essentiellement des algorithmes qui peuvent évoluer avec un nouveau type de données.
Méta-apprentissage
Qu'est-ce que c'est?

Le méta-apprentissage est exactement ce à quoi il ressemble, un algorithme qui s'entraîne de telle sorte que, en voyant un ensemble de données, il donne un nouveau prédicteur d'apprentissage automatique pour cet ensemble de données particulier. La définition est très futuriste si vous lui donnez un premier coup d'œil. Vous vous sentez « whoa ! c'est ce que fait un Data Scientist » et il automatise « le travail le plus sexy du 21e siècle », et dans un certain sens, les Meta-Learners ont commencé à le faire.
Quelques exemples
Le méta-apprentissage est récemment devenu un sujet brûlant dans l'apprentissage en profondeur, avec la publication de nombreux articles de recherche, utilisant le plus souvent la technique d'optimisation des hyperparamètres et des réseaux de neurones, la recherche de bonnes architectures de réseau, la reconnaissance d'images Few-Shot et l'apprentissage par renforcement rapide.
Dis m'en plus!
Certaines personnes se réfèrent à cette automatisation complète pour décider à la fois des paramètres et des hyperparamètres comme l'architecture de réseau comme autoML et vous pourriez trouver des gens faisant référence à Meta Learning et AutoML comme des champs différents. Malgré tout le battage médiatique qui les entoure, la vérité est que les Meta Learners sont toujours des algorithmes et des voies pour faire évoluer l'apprentissage automatique avec la complexité et la variété des données qui augmentent.
La plupart des articles de Meta-Learning sont des hacks intelligents, qui selon Wikipedia ont les propriétés suivantes :
- Le système doit inclure un sous-système d'apprentissage, qui s'adapte avec l'expérience.
- L'expérience est acquise en exploitant les méta-connaissances extraites soit lors d'un épisode d'apprentissage précédent sur un seul ensemble de données, soit à partir de différents domaines ou problèmes.
- Le biais d'apprentissage doit être choisi dynamiquement.
Le sous-système est essentiellement une configuration qui s'adapte lorsque les métadonnées d'un domaine (ou d'un domaine entièrement nouveau) y sont introduites. Ces métadonnées peuvent indiquer le nombre croissant de classes, la complexité, les changements de couleurs et de textures et d'objets (dans les images), les styles, les modèles de langage (langage naturel) et d'autres caractéristiques similaires. Découvrez quelques articles super sympas ici : Meta-Learning Shared Hierarchies et Meta-Learning Using Temporal Convolutions. Vous pouvez également créer des algorithmes Few Shot ou Zero Shot à l'aide d'architectures Meta-Learning. Le méta-apprentissage est l'une des techniques les plus prometteuses qui contribuera à façonner l'avenir de l'IA.
Raisonnement neuronal
Qu'est-ce que c'est?

Le raisonnement neuronal est la prochaine grande chose dans les problèmes de classification d'images. Le raisonnement neuronal est une étape au-dessus de la reconnaissance de formes où les algorithmes vont au-delà de l'idée de simplement identifier et classer du texte ou des images. Le raisonnement neuronal résout des questions plus génériques dans l'analyse de texte ou l'analyse visuelle. Par exemple, l'image ci-dessous représente un ensemble de questions auxquelles Neural Reasoning peut répondre à partir d'une image.
Dis m'en plus!
Ce nouvel ensemble de techniques apparaît après la publication de l'ensemble de données bAbi de Facebook ou du récent ensemble de données CLEVR. Les techniques à venir pour déchiffrer les relations et pas seulement les modèles ont un immense potentiel pour résoudre non seulement le raisonnement neuronal, mais également de nombreux autres problèmes difficiles, notamment les problèmes d'apprentissage de Few Shot.
Retourner
Maintenant que nous savons quelles sont les techniques, revenons en arrière et voyons comment elles résolvent les problèmes de base avec lesquels nous avons commencé. Le tableau ci-dessous donne un aperçu des capacités des techniques d'apprentissage efficace pour relever les défis :
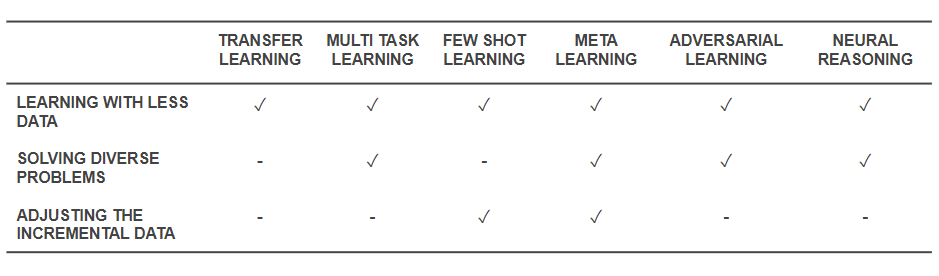
Capacités des techniques d'apprentissage efficaces
- Toutes les techniques mentionnées ci-dessus aident à résoudre la formation avec une quantité moindre de données d'une manière ou d'une autre. Alors que le méta-apprentissage donnerait des architectures qui se mouleraient simplement avec les données, l'apprentissage par transfert rend les connaissances d'un autre domaine utiles pour compenser moins de données. Few Shot Learning est dédié au problème en tant que discipline scientifique. L'apprentissage contradictoire peut aider à améliorer les ensembles de données.
- Les architectures d'adaptation de domaine (un type d'apprentissage multitâche), d'apprentissage contradictoire et (parfois) de méta-apprentissage aident à résoudre les problèmes résultant de la diversité des données.
- Le méta-apprentissage et le Few Shot Learning aident à résoudre les problèmes de données incrémentales.
- Les algorithmes de raisonnement neuronal ont un immense potentiel pour résoudre des problèmes du monde réel lorsqu'ils sont incorporés en tant que méta-apprenants ou apprenants peu de coups.
Veuillez noter que ces techniques d'apprentissage efficace ne sont pas de nouvelles techniques d'apprentissage en profondeur / d'apprentissage automatique, mais complètent les techniques existantes en tant que hacks , ce qui les rend plus rentables. Par conséquent, vous verrez toujours nos outils habituels tels que les réseaux de neurones convolutifs et les LSTM en action, mais avec les épices supplémentaires. Ces techniques d'apprentissage efficace qui fonctionnent avec moins de données et effectuent de nombreuses tâches à la fois peuvent faciliter la production et la commercialisation de produits et services alimentés par l'IA. Chez ParallelDots, nous reconnaissons la puissance de l'apprentissage efficace et l'incorporons comme l'une des principales caractéristiques de notre philosophie de recherche.
Ce billet de Parth Shrivastava est apparu pour la première fois sur le blog ParallelDots et a été reproduit avec permission.