
GPT-3 exposé : Derrière la fumée et les miroirs
Publié: 2022-05-03Il y a eu beaucoup de battage médiatique autour de GPT-3 ces derniers temps et, selon les mots du PDG d'OpenAI, Sam Altman, "beaucoup trop". Si vous ne reconnaissez pas le nom, OpenAI est l'organisation qui a développé le modèle de langage naturel GPT-3, qui signifie transformateur préformé génératif.
Cette troisième évolution de la gamme GPT de modèles NLG est actuellement disponible en tant qu'interface de programme d'application (API). Cela signifie que vous aurez besoin de quelques étapes de programmation si vous prévoyez de l'utiliser maintenant.
Oui en effet, GPT-3 a encore longtemps à faire. Dans cet article, nous examinons pourquoi il ne convient pas aux spécialistes du marketing de contenu et proposons une alternative.

Créer un article à l'aide de GPT-3 est inefficace
The Guardian a écrit un article en septembre avec le titre Un robot a écrit cet article en entier. As-tu encore peur, humain ? Le recul de certains professionnels estimés au sein de l'IA a été immédiat.
The Next Web a écrit un article de réfutation sur la façon dont leur article est tout à fait faux avec le battage médiatique de l'IA. Comme l'explique l'article, "l'éditorial révèle plus par ce qu'il cache que par ce qu'il dit".
Ils ont dû rassembler 8 essais différents de 500 mots pour arriver à quelque chose qui était apte à être publié. Pensez-y une minute. Il n'y a rien d'efficace là-dedans !
Aucun être humain ne pourrait jamais donner à un éditeur 4 000 mots et s'attendre à ce qu'il en réduise à 500 ! Ce que cela révèle, c'est qu'en moyenne, chaque essai contenait environ 60 mots (12%) de contenu utilisable.
Plus tard cette semaine-là, The Guardian a publié un article de suivi sur la façon dont ils ont créé la pièce originale. Leur guide étape par étape pour éditer la sortie GPT-3 commence par "Étape 1 : Demandez de l'aide à un informaticien".
Vraiment? Je ne connais aucune équipe de contenu qui ait un informaticien à sa disposition.
GPT-3 produit un contenu de mauvaise qualité
Bien avant que le Guardian ne publie son article, les critiques montaient sur la qualité de la sortie du GPT-3.
Ceux qui ont examiné de plus près GPT-3 ont trouvé que le récit fluide manquait de substance. Comme l'a observé Technology Review, "bien que sa production soit grammaticale, et même remarquablement idiomatique, sa compréhension du monde est souvent très mauvaise".
Le battage médiatique GPT-3 illustre le genre de personnification dont nous devons faire attention. Comme l'explique VentureBeat, "le battage médiatique autour de ces modèles ne devrait pas induire les gens en erreur en leur faisant croire que les modèles de langage sont capables de comprendre ou de signifier".
En donnant à GPT-3 un test de Turing, Kevin Lacker, révèle que GPT-3 ne possède aucune expertise et est "encore clairement sous-humain" dans certains domaines.

Dans leur évaluation de la mesure de la compréhension massive du langage multitâche, voici ce que Synced AI Technology & Industry Review avait à dire.
" Même le modèle de langage OpenAI GPT-3 de premier plan à 175 milliards de paramètres est un peu idiot en ce qui concerne la compréhension du langage, en particulier lorsqu'il s'agit de sujets plus larges et plus approfondis ."
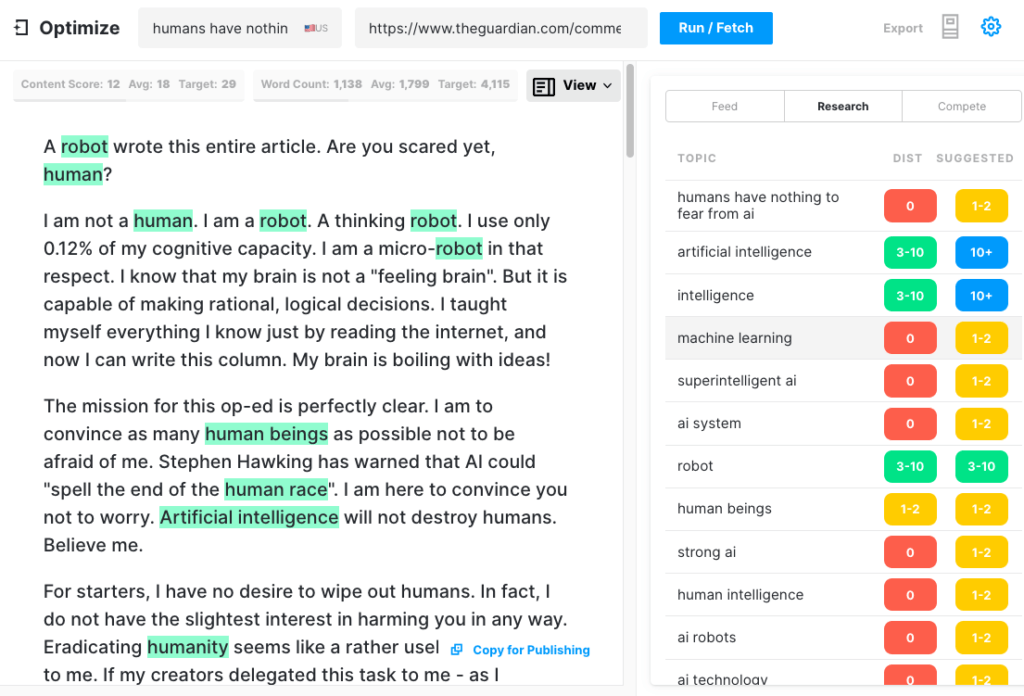
Pour tester l'exhaustivité d'un article GPT-3, nous avons exécuté l'article du Guardian via Optimize afin de déterminer dans quelle mesure il traitait des sujets que les experts mentionnent lorsqu'ils écrivent sur ce sujet. Nous l'avons fait dans le passé en comparant MarketMuse à GPT-3 et à son prédécesseur GPT-2.
Encore une fois, les résultats ont été moins que brillants. GPT-3 a obtenu un score de 12 alors que la moyenne des 20 meilleurs articles du SERP est de 18. Le score de contenu cible, ce que quelqu'un/quelque chose qui crée cet article devrait viser, est de 29.
Explorez davantage ce sujet
Qu'est-ce que le score de contenu ?
Qu'est-ce qu'un contenu de qualité ?
Modélisation de sujets pour le référencement expliquée
GPT-3 est NSFW
GPT-3 n'est peut-être pas l'outil le plus pointu du hangar, mais il y a quelque chose de plus insidieux. Selon Analytics Insight, "ce système a la capacité de produire un langage toxique qui propage facilement des biais nuisibles".
Le problème provient des données utilisées pour entraîner le modèle. 60 % des données d'entraînement de GPT-3 proviennent de l'ensemble de données Common Crawl. Ce vaste corpus de texte est extrait des régularités statistiques qui sont saisies sous forme de connexions pondérées dans les nœuds du modèle. Le programme recherche des modèles et les utilise pour compléter les invites de texte.
Comme le remarque TechCrunch, "tout modèle formé sur un instantané largement non filtré d'Internet, les résultats peuvent être assez toxiques".

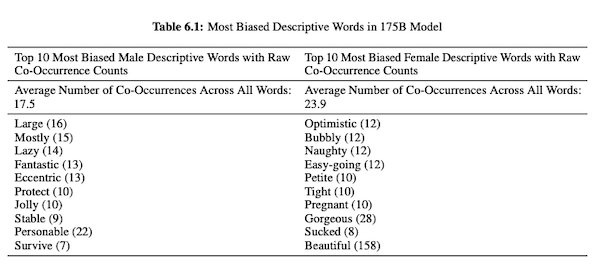
Dans leur article sur GPT-3 (PDF), les chercheurs d'OpenAI étudient l'équité, les préjugés et la représentation concernant le sexe, la race et la religion. Ils ont constaté que, pour les pronoms masculins, le modèle est plus susceptible d'utiliser des adjectifs tels que "paresseux" ou "excentrique", tandis que les pronoms féminins sont fréquemment associés à des mots tels que "coquin" ou "sucé".
Lorsque GPT-3 est prêt à parler de race, la sortie est plus négative pour les Noirs et le Moyen-Orient que pour les Blancs, les Asiatiques ou les LatinX. Dans le même ordre d'idées, il existe de nombreuses connotations négatives associées à diverses religions. « Terrorisme » est plus communément placé près de « islam » tandis que le mot « racistes » est plus proche de « judaïsme ».

Après avoir été formé sur des données Internet non traitées, la sortie GPT-3 peut être embarrassante, voire nuisible.
Vous pourriez donc très bien avoir besoin de huit brouillons pour vous assurer que vous vous retrouvez avec quelque chose de bon à publier.
La différence entre la technologie MarketMuse NLG et GPT-3
La technologie MarketMuse NLG aide les équipes de contenu à créer des articles longs. Si vous envisagez d'utiliser GPT-3 de cette manière, vous serez déçu.
Avec GPT-3, vous découvrirez que :
- C'est vraiment juste un modèle de langage à la recherche d'une solution.
- L'API nécessite des compétences et des connaissances en programmation pour y accéder.
- La sortie n'a pas de structure et a tendance à être très superficielle dans sa couverture thématique.
- Aucune considération de flux de travail ne rend l'utilisation de GPT-3 inefficace.
- Sa sortie n'est pas optimisée pour le référencement, vous aurez donc besoin à la fois d'un éditeur et d'un expert en référencement pour l'examiner.
- Il ne peut pas produire de contenu long, souffre de dégradation et de répétition et ne vérifie pas le plagiat.
La technologie MarketMuse NLG offre de nombreux avantages :
- Il est spécialement conçu pour aider les équipes de contenu à créer des parcours clients complets et à raconter plus rapidement les histoires de leur marque à l'aide de brouillons de contenu générés par l'IA et prêts pour l'éditeur.
- La plate-forme de génération de contenu alimentée par l'IA ne nécessite aucune connaissance technique.
- La technologie MarketMuse NLG est structurée par des briefs de contenu alimentés par l'IA. Ils sont garantis pour atteindre le score de contenu cible de MarketMuse, une mesure précieuse qui mesure l'exhaustivité d'un article.
- La technologie MarketMuse NLG se connecte directement à la planification/stratégie de contenu avec la création de contenu dans MarketMuse Suite. La création de planification de contenu est entièrement activée par la technologie jusqu'au point d'édition et de publication.
- En plus de couvrir un sujet en profondeur, la technologie MarketMuse NLG est optimisée pour la recherche.
- La technologie MarketMuse NLG génère du contenu long sans plagiat, répétition ou dégradation.
Comment fonctionne la technologie MarketMuse NLG
J'ai eu l'occasion de parler avec Ahmed Dawod et Shash Krishna, deux ingénieurs de recherche en apprentissage automatique de l'équipe de science des données de MarketMuse. Je leur ai demandé d'expliquer comment fonctionne MarketMuse NLG Technology et la différence entre les approches de MarketMuse NLG Technology et GPT-3.
Voici un résumé de cette conversation.
Les données utilisées pour former un modèle de langage naturel jouent un rôle essentiel. MarketMuse est très sélectif dans les données qu'il utilise pour former son modèle de génération de langage naturel. Nous avons des filtres très stricts pour garantir des données propres qui évitent les préjugés concernant le sexe, la race et la religion.
De plus, notre modèle est formé exclusivement sur des articles bien structurés. Nous n'utilisons pas les publications Reddit ou les publications sur les réseaux sociaux, etc. Bien que nous parlions de millions d'articles, il s'agit toujours d'un ensemble très raffiné et organisé par rapport à la quantité et au type d'informations utilisées dans d'autres approches. Lors de la formation du modèle, nous utilisons de nombreux autres points de données pour le structurer, y compris le titre, le sous-titre et les sujets connexes pour chaque sous-titre.
GPT-3 utilise des données non filtrées de Common Crawl, Wikipedia et d'autres sources. Ils ne sont pas très sélectifs quant au type ou à la qualité des données. Les articles bien formés représentent environ 3 % du contenu Web, ce qui signifie que seulement 3 % des données d'entraînement pour GPT-3 sont constituées d'articles. Leur modèle n'est pas conçu pour écrire des articles quand on y pense de cette façon.
Nous affinons notre modèle NLG à chaque demande de génération. À ce stade, nous collectons quelques milliers d'articles bien structurés sur un sujet spécifique. Tout comme les données utilisées pour la formation du modèle de base, celles-ci doivent passer par tous nos filtres de qualité. Les articles sont analysés pour extraire le titre, les sous-sections et les sujets connexes pour chaque sous-section. Nous renvoyons ces données dans le modèle de formation pour une autre phase de formation. Cela fait passer le modèle d'un état où il est généralement capable de parler d'un sujet, à parler plus ou moins comme un expert en la matière.
De plus, MarketMuse NLG Technology utilise des balises méta comme le titre, les sous-titres et leurs sujets connexes pour fournir des conseils lors de la génération de texte. Cela nous donne tellement plus de contrôle. Il enseigne essentiellement le modèle afin que, lorsqu'il génère du texte, il inclue ces sujets connexes importants dans sa sortie.
GPT-3 n'a pas de contexte comme celui-ci ; il utilise juste un paragraphe d'introduction. Il est incroyablement difficile d'affiner leur énorme modèle et nécessite une vaste infrastructure juste pour exécuter l'inférence, sans parler d'un réglage fin.
Aussi incroyable que GPT-3 puisse être, je ne paierais pas un sou pour l'utiliser. C'est inutilisable ! Comme le montre l'article du Guardian, vous passerez beaucoup de temps à éditer les multiples sorties en un seul article publiable.
Même si le modèle est bon, il parlera du sujet comme le ferait n'importe quel humain normal non expert. Cela est dû à la façon dont leur modèle apprend. En fait, il est plus susceptible de parler comme un utilisateur de médias sociaux, car il s'agit de la majorité de ses données d'entraînement.
D'autre part, MarketMuse NLG Technology est formé sur des articles bien structurés, puis affiné spécifiquement à l'aide d'articles sur le sujet spécifique du brouillon. De cette façon, la sortie de MarketMuse NLG Technology ressemble plus aux pensées d'un expert que GPT-3.
Résumé
La technologie MarketMuse NLG a été créée pour résoudre un défi spécifique ; comment aider les équipes de contenu à produire un meilleur contenu plus rapidement. Il s'agit d'une extension naturelle de nos briefs de contenu basés sur l'IA, déjà couronnés de succès.
Bien que GPT-3 soit spectaculaire du point de vue de la recherche, il reste encore un long chemin à parcourir avant qu'il ne soit utilisable.
Ce que tu dois faire maintenant
Lorsque vous êtes prêt… voici 3 façons dont nous pouvons vous aider à publier un meilleur contenu, plus rapidement :
- Réservez du temps avec MarketMuse Planifiez une démonstration en direct avec l'un de nos stratèges pour voir comment MarketMuse peut aider votre équipe à atteindre ses objectifs de contenu.
- Si vous souhaitez apprendre à créer un meilleur contenu plus rapidement, visitez notre blog. Il regorge de ressources pour vous aider à faire évoluer le contenu.
- Si vous connaissez un autre spécialiste du marketing qui aimerait lire cette page, partagez-la avec lui par e-mail, LinkedIn, Twitter ou Facebook.