
Comment utiliser la PNL dans le marketing de contenu
Publié: 2022-05-02Chris Penn, co-fondateur de Trust Insights, et Jeff Coyle, co-fondateur et chef de produit de MarketMuse, discutent de l'analyse de rentabilisation de l'IA pour le marketing. Après le webinaire, Paul a participé à une session "demandez-moi n'importe quoi" dans notre communauté Slack, The Content Strategy Collective (joignez-vous ici). Voici les notes du webinaire suivies d'une transcription de l'AMA.

Le webinaire
Le problème
Avec l'explosion du contenu, nous avons de nouveaux intermédiaires. Ce ne sont pas des journalistes ou des influenceurs des médias sociaux. Ce sont des algorithmes ; des modèles d'apprentissage automatique qui dictent tout ce qui se dresse entre vous et votre public.
Ne tenez pas compte de cela et votre contenu continuera d'être embourbé dans l'obscurité.
La solution : le traitement du langage naturel
La PNL est la programmation d'ordinateurs pour traiter et analyser de grandes quantités de données en langage naturel. Cela provient de documents, de chatbots, de publications sur les réseaux sociaux, de pages sur votre site Web et de tout ce qui est essentiellement une pile de mots. La PNL basée sur des règles est arrivée en premier, mais a été remplacée par le traitement statistique du langage naturel.
Comment fonctionne la PNL
Les trois tâches principales du traitement du langage naturel sont la reconnaissance, la compréhension et la génération.
Reconnaissance – Les ordinateurs ne peuvent pas traiter le texte comme les humains. Ils ne peuvent lire que des chiffres. La première étape consiste donc à convertir la langue dans un format que l'ordinateur peut comprendre.
Compréhension – La représentation du texte sous forme de nombres permet aux algorithmes d'effectuer une analyse statistique pour déterminer quels sujets sont les plus fréquemment mentionnés ensemble.
Génération - Après l'analyse et la compréhension mathématique, la prochaine étape logique de la PNL est la génération de texte. Les machines peuvent être utilisées pour faire apparaître les questions auxquelles un écrivain doit répondre dans son contenu. À un autre niveau, l'intelligence artificielle peut générer des synthèses de contenu qui fournissent des informations supplémentaires sur la création de contenu de niveau expert.
Ces outils sont disponibles dans le commerce aujourd'hui via MarketMuse. Au-delà de cela, il y a les modèles de génération de langage naturel avec lesquels vous pouvez jouer aujourd'hui, mais qui ne sont pas sous une forme commercialement utilisable. Bien que la technologie MarketMuse NLG arrive très bientôt.
Ressources supplémentaires mentionnées
- Huggingface.co
- Python
- R
- Collaboration
- IBM Watson Studio

L'AMA
Avez-vous des articles ou des recommandations de sites Web pour suivre les tendances de l'industrie de l'IA ?
Lisez les recherches universitaires publiées là-bas. Des sites comme ceux-ci font tous un excellent travail pour couvrir les derniers et les meilleurs.
- KDNuggets.com
- Vers la science des données
- Kagglé
Cela et les principaux centres de publication de recherche sur Facebook, Google, IBM, Microsoft et Amazon. Vous verrez des tonnes d'excellents documents partagés sur ces sites.
"J'utilise un vérificateur de densité de mots clés pour tout mon contenu. À quel point est-ce loin d'être une stratégie raisonnable aujourd'hui pour le référencement ? »
La densité des mots-clés est essentiellement le comptage de la fréquence des termes. Il a sa place pour comprendre le caractère très grossier du texte, mais il lui manque toute connaissance sémantique. Si vous n'avez pas accès aux outils NLP, regardez au moins des éléments tels que le contenu «les personnes ont également recherché» dans l'outil de référencement de votre choix.
Pourriez-vous donner des exemples précis sur la façon dont vous générez du contenu dans… des pages Web ? Des postes? des tweets ?
Le défi est que ces outils sont exactement cela – ce sont des outils. C'est comme, comment opérationnalisez-vous une spatule? Cela dépend de ce que vous cuisinez. Vous pouvez l'utiliser pour remuer la soupe et aussi retourner les crêpes. La façon de démarrer avec certaines de ces connaissances dépend de votre niveau de compétence technique. Si vous êtes à l'aise avec les blocs-notes Python et Jupyter, par exemple, vous pouvez littéralement importer la bibliothèque de transformateurs, alimenter votre fichier texte de formation et commencer la génération immédiatement. Je l'ai fait avec les tweets d'un certain politicien et il a commencé à cracher des tweets qui déclencheraient la Troisième Guerre mondiale. Si vous n'êtes pas à l'aise techniquement, alors commencez à regarder des outils comme MarketMuse. Je laisserai Jeff Coyle offrir des suggestions sur la façon dont le commerçant moyen commence là-bas.
Si vous regardez au-delà des outils, mais plutôt dans les stratégies, quel pourrait être un exemple de stratégie que vous pourriez mettre en œuvre pour utiliser ces connaissances ?
Quelques exemples rapides concernent des choses comme les méta-descriptions, pour classer des pages ou des blocs de contenu dans une taxonomie, ou pour essayer de deviner des questions qui nécessitent des réponses - mais ce sont vraiment des solutions ponctuelles. La plus grande sagesse stratégique vient lorsque vous l'utilisez pour vous montrer vos forces actuelles, vos lacunes et où vous avez de l'élan. À partir de là, prendre des décisions sur ce qu'il faut créer, mettre à jour, développer devient transformateur pour une entreprise. Imaginez maintenant faire la même chose contre un concurrent. Trouver leurs lacunes. faire mousser, rincer, répéter.
La stratégie est toujours basée sur l'objectif. Quel objectif essayez-vous d'atteindre ? Attirez-vous du trafic de recherche ? Faites-vous de la génération de leads ? Faites-vous des relations publiques ? La PNL est un ensemble d'outils. C'est similaire à - la stratégie est le menu. Serez-vous le petit-déjeuner, le déjeuner ou le dîner ? Les outils et les recettes que vous utiliserez dépendront fortement du menu que vous servez. Un pot de soupe va être profondément inutile si vous faites du spanakopita.
Quel est un bon point de départ pour quelqu'un qui souhaite commencer à extraire des données pour obtenir des informations ?
Commencez par la méthode scientifique.
- À quelle question voulez-vous répondre ?
- De quels données, processus et outils avez-vous besoin pour répondre à cette question ?
- Formulez une hypothèse, une condition unique, une affirmation prouvée vraie ou fausse que vous pouvez tester.
- Test.
- Analysez vos données de test.
- Affiner ou rejeter l'hypothèse.
Pour les données elles-mêmes, utilisez notre cadre de données 6C pour juger de la qualité des données.
Quelles sont, à votre avis, les principales intentions des utilisateurs de recherche que les spécialistes du marketing devraient prendre en compte ?
Les étapes du parcours client. Cartographiez l'expérience client du début à la fin - sensibilisation, considération, engagement, achat, propriété, fidélité, évangélisation. Ensuite, déterminez ce que les intentions sont susceptibles d'être à chaque étape. Par exemple, au niveau de la propriété, les intentions de recherche sont très susceptibles d'être orientées vers le service. "Comment réparer le bruit de craquement des airpods pro" en est un exemple. Le défi consiste à collecter des données à chacune des étapes du voyage et à les utiliser pour s'entraîner/se régler.
Ne pensez-vous pas que cela peut être un peu volatil ? Si nous avons besoin de quelque chose de plus stable pour automatiser le processus, nous devons généraliser les choses à un niveau supérieur.
Jeff Bezos a dit, concentrez-vous sur ce qui ne change pas. Le chemin général vers la propriété ne change pas beaucoup - quelqu'un mécontent de son paquet de chewing-gum vivra des choses similaires à quelqu'un mécontent du nouveau porte-avions nucléaire qu'il a commandé. Les détails changent, bien sûr, mais comprendre quels types de données et d'intentions est essentiel pour savoir où se trouve quelqu'un, émotionnellement, dans un voyage - et comment il le transmet dans le langage.
Quels sont les pièges probables dans lesquels les gens tomberont lorsqu'ils essaieront de classer l'intention de l'utilisateur ?
De loin, biais de confirmation. Les gens projetteront leurs propres hypothèses sur l'expérience client et interpréteront les données client à travers leurs propres préjugés. Je suggérerais également dans la mesure du possible d'utiliser au mieux les données d'interaction (e-mails ouverts, pieds dans la porte, appels au centre d'appels, etc.) pour les valider. Je sais que certains endroits, en particulier les grandes organisations, sont de grands fans de la modélisation d'équations structurées pour comprendre l'intention de l'utilisateur. Je n'étais pas aussi fan qu'eux, mais c'est une approche potentielle supplémentaire.
Selon vous, quels sont les outils ou produits qui permettent de déterminer l'intention de l'utilisateur d'une requête ?
Trame. Outre MarketMuse? Honnêtement, j'ai dû travailler avec mes propres trucs parce que je n'ai pas trouvé d'excellents résultats, en particulier avec les outils de référencement traditionnels. FastText pour la vectorisation puis le clustering non structuré.
D'après votre expérience, comment BERT a-t-il changé la recherche Google ?
La principale contribution de BERT est le contexte, en particulier avec les modificateurs. BERT permet à Google de voir l'ordre des mots et de lui faire interpréter le sens. Avant cela, ces deux requêtes pouvaient être fonctionnellement équivalentes dans un modèle de style sac de mots :
- où est le meilleur café
- quel est le meilleur endroit pour acheter du café
Ces deux requêtes, bien que très similaires, pourraient avoir des résultats radicalement différents. Un café n'est peut-être pas un endroit où vous voulez acheter des haricots. Un Walmart n'est DÉFINITIVEMENT pas un endroit où vous voulez boire du café.
Pensez-vous que l'IA ou les TIC développeront un jour la conscience/les émotions/l'empathie comme les humains ? Comment allons-nous les programmer ? Comment humaniser l'IA ?
La réponse à cela dépend de ce qui se passe avec l'informatique quantique. Quantum permet des états flous variables et un calcul massivement parallèle qui imite ce qui se passe dans notre propre cerveau. Votre cerveau est un processeur parallèle massif très lent, basé sur la chimie. C'est vraiment bon pour faire un tas de choses à la fois, sinon rapidement. Quantum permettrait aux ordinateurs de faire la même chose, mais beaucoup, beaucoup plus rapidement - et cela ouvre la porte à l'intelligence générale artificielle. Voici mon souci, et c'est un souci avec l'IA aujourd'hui, déjà, dans un usage étroit : nous les formons en fonction de nous. L'humanité n'a pas fait un excellent travail pour bien se traiter ou traiter la planète sur laquelle nous vivons. Nous ne voulons pas que nos ordinateurs imitent cela.
Je soupçonne que, dans la mesure où les systèmes le permettent, les émotions informatiques seront fonctionnellement très différentes des nôtres et s'auto-organiseront à partir de leurs données, tout comme les nôtres le font à partir de nos réseaux de neurones basés sur la chimie. Cela signifie à son tour qu'ils peuvent se sentir très différemment de nous. Si les machines, basées principalement sur la logique et les données, font une évaluation franche et objective de l'humanité, elles peuvent déterminer que franchement, nous causons plus de problèmes que nous n'en valons la peine. Et ils n'auraient pas tort, franchement. Nous sommes, en tant qu'espèce, un gâchis barbare la plupart du temps.
À votre avis, comment voyez-vous les spécialistes du marketing de contenu intégrer/adopter la génération du langage naturel dans leur flux de travail/processus quotidiens ?
Les spécialistes du marketing devraient déjà en intégrer une certaine forme, même s'il ne s'agit que de répondre à des questions comme celles que nous avons présentées dans le produit de MarketMuse. Répondre aux questions dont vous savez que le public se soucie est un moyen rapide et facile de créer un contenu significatif. Mon ami Marcus Sheridan a écrit un excellent livre, "Ils demandent, vous répondez" que, ironiquement, vous n'avez pas besoin de lire pour comprendre la stratégie client de base : répondre aux questions des gens. Si vous n'avez pas encore de questions soumises par de vraies personnes, utilisez NLG pour les créer.
Où voyez-vous l'IA et la PNL progresser dans les 2 prochaines années ?
Si je le savais, je ne serais pas ici, car je serais dans la forteresse au sommet de la montagne que j'ai achetée avec mes gains. Mais sérieusement, le pivot majeur que nous avons vu au cours des 2 dernières années et qui ne montre aucun signe de changement est la progression des modèles «roulez vos propres» vers «téléchargez pré-formés et peaufinez». Je pense que nous allons vivre des moments passionnants dans la vidéo et l'audio alors que les machines s'améliorent en matière de synthèse. La génération de musique, en particulier, est mûre pour l'automatisation ; à l'heure actuelle, les machines génèrent au mieux une musique tout à fait médiocre et au pire des plaies d'oreille. Cela change rapidement. Je vois plus d'exemples comme le mélange de transformateurs et d'auto-encodeurs comme BART l'a fait comme prochaines étapes majeures dans la progression du modèle et les résultats de pointe.

Où voyez-vous l'orientation de la recherche Google en matière de recherche d'informations ?
Le défi auquel Google continue d'être confronté, et vous le voyez dans nombre de ses articles de recherche, est l'échelle. Ils sont particulièrement confrontés à des problèmes tels que YouTube ; le fait qu'ils s'appuient toujours fortement sur les bigrammes n'est pas un coup à leur sophistication, c'est une reconnaissance que tout ce qui dépasse cela a un coût de calcul insensé. Toute percée majeure de leur part ne se fera pas tant au niveau du modèle qu'au niveau de l'échelle pour faire face au déluge de nouveaux contenus riches déversés sur Internet chaque jour.
Quelles sont certaines des applications les plus intéressantes de l'IA que vous avez rencontrées ?
Le tout autonome est un domaine que je surveille de près. Il en va de même pour les contrefaçons profondes. Ce sont des exemples qui montrent à quel point le chemin à parcourir est périlleux, si nous ne faisons pas attention. En PNL en particulier, la génération progresse rapidement et est le domaine à surveiller.
Où avez-vous vu des référenceurs utiliser la PNL d'une manière qui ne fonctionne pas ou ne fonctionnera pas ?
J'ai perdu le compte. La plupart du temps, ce sont des gens qui utilisent un outil d'une manière non prévue et qui obtiennent des résultats médiocres. Comme nous l'avons mentionné dans le webinaire, il existe des tableaux de bord pour les différents tests de pointe pour les modèles, et les personnes qui utilisent un outil dans un domaine où il n'est pas puissant n'apprécient généralement pas les résultats. Cela dit… la plupart des praticiens du référencement n'utilisent aucun type de NLP en dehors de ce que les fournisseurs leur fournissent, et de nombreux fournisseurs sont toujours bloqués en 2015. Ce sont toutes des listes de mots clés, tout le temps.
Où voyez-vous la recherche de vidéos (YouTube) et d'images sur Google ? Pensez-vous que les technologies déployées par Google utilisées pour tous les types de recherches sont très similaires ou différentes les unes des autres ?
Les technologies de Google sont toutes construites au-dessus de leur infrastructure et utilisent leur technologie. Tant de choses sont construites sur TensorFlow et pour une bonne raison - c'est super robuste et évolutif. Là où les choses varient, c'est dans la façon dont Google utilise les différents outils. TensorFlow pour la reconnaissance d'images a par nature des entrées et des couches très différentes de celles de TensorFlow pour la comparaison par paires et le traitement du langage. Mais si vous savez comment utiliser TensorFlow et les différents modèles disponibles, vous pouvez réaliser vous-même des choses plutôt intéressantes.
Comment pouvons-nous nous adapter/suivre les progrès de l'IA et de la PNL ?
Continuez à lire, à rechercher et à tester. Rien ne remplace le fait de se salir les mains, au moins un peu. Créez un compte Google Colab gratuit et essayez des choses. Enseignez-vous un peu Python. Copiez et collez des exemples de code à partir de Stack Overflow. Vous n'avez pas besoin de connaître tous les rouages d'un moteur à combustion interne pour conduire une voiture, mais quand quelque chose ne va pas, un peu de connaissance suffit. Il en va de même pour l'IA et la PNL - le simple fait de pouvoir appeler BS sur un fournisseur est une compétence précieuse. C'est l'une des raisons pour lesquelles j'aime travailler avec les gens de MarketMuse. Ils savent réellement ce qu'ils font et leur travail d'IA n'est pas BS.
Que diriez-vous aux personnes qui craignent que l'IA leur prenne leur emploi ? Par exemple, les écrivains qui voient une technologie comme NLG et craignent de se retrouver au chômage si l'IA peut être "assez bonne" pour qu'un éditeur nettoie un peu le texte.
"L'IA remplacera les tâches, pas les emplois" - le Brookings InstituteEt c'est absolument vrai. Mais il y aura des pertes nettes d'emplois, car voici ce qui va se passer. Supposons que votre travail soit composé de 50 tâches. AI fait 30 d'entre eux. Super, vous avez maintenant 20 tâches. Si vous êtes la seule personne à faire cela, alors vous êtes au nirvana parce que vous avez 30 unités de temps de plus pour faire un travail plus intéressant et plus amusant. C'est ce que promettent les optimistes de l'IA. Vérification de la réalité : s'il y a 5 personnes qui font ces 50 unités, et que l'IA en fait 30, alors l'IA fait maintenant 150/250 unités de travail. Cela signifie qu'il reste 100 unités de travail à faire, et les entreprises étant ce qu'elles sont, elles supprimeront immédiatement 3 postes car les 100 unités de travail peuvent être effectuées par 2 personnes. Devez-vous vous inquiéter que l'IA prenne des emplois ? Cela dépend du travail. Si le travail que vous faites est incroyablement répétitif, soyez absolument inquiet. Dans mon ancienne agence, il y avait un pauvre con dont le travail consistait à copier et coller les résultats de recherche dans une feuille de calcul pour les clients (je travaillais dans une entreprise de relations publiques, pas l'endroit le plus technologiquement avancé) 8 heures par jour. Ce travail est en danger immédiat, et franchement aurait dû l'être depuis des années. Répétition = automatisation = IA = perte de tâche. Moins votre travail est répétitif, plus vous êtes en sécurité.
Chaque changement a également créé de plus en plus d'inégalités de revenus. Nous sommes maintenant à un point dangereux où les machines - qui ne dépensent pas, ne sont pas des consommateurs - font de plus en plus le travail de personnes qui dépensent, qui consomment, et nous le voyons dans la dominance massive de la richesse dans la technologie. C'est un problème de société auquel nous devrons nous attaquer à un moment donné.
Et le défi avec cela est que le progrès est le pouvoir. Comme Robert Ingersoll l'a écrit (et a ensuite été attribué à tort à Abraham Lincoln) : "" Presque tous les hommes peuvent supporter l'adversité, mais si vous voulez tester le caractère d'un homme, donnez-lui le pouvoir. " Nous voyons comment les gens gèrent le pouvoir aujourd'hui.
Comment puis-je coupler les données de Google Analytics avec NLP Research ?
GA indique la direction, puis NLP indique la création. Qu'est-ce qui est populaire ? Je viens de le faire pour un client il y a peu de temps. Ils ont des milliers de pages Web et de sessions de chat. Nous avons utilisé GA pour analyser les catégories qui connaissaient la croissance la plus rapide sur leur site, puis nous avons utilisé le NLP pour traiter ces journaux de discussion afin de leur montrer les tendances et ce dont ils avaient besoin pour créer du contenu.
Google Analytics est idéal pour nous dire CE QUI s'est passé. La PNL peut commencer à démêler un peu le POURQUOI, puis nous complétons cela avec une étude de marché.
Je vous ai vu utiliser Talkwalker comme source de données dans plusieurs de vos études. Quels autres sources et cas d'utilisation dois-je prendre en compte pour l'analyse ?
Alors, tellement. Data.gov. Talkwalker. MarketMuse. Otter.ai pour transcrire votre audio. Noyaux de Kaggle. Recherche de données Google - qui soit dit en passant est GOLD et si vous ne l'utilisez pas, vous devriez absolument l'être. Google Actualités et GDELT. Il y a tellement de bonnes sources là-bas.
À quoi ressemble pour vous une collaboration idéale entre l'équipe marketing et l'équipe d'analyse de données ?
Je ne blague pas; l'une des plus grosses erreurs que Katie Robbert et moi voyons tout le temps chez les clients sont les silos organisationnels. La main gauche n'a aucune idée de ce que fait la main droite, et c'est un bordel chaud partout. Rassembler les gens, partager des idées, partager des listes de tâches, avoir des standups communs, s'enseigner mutuellement - être fonctionnellement "une équipe, un rêve" est la collaboration idéale, au point où vous n'avez plus besoin d'utiliser le mot collaboration . Les gens travaillent simplement ensemble et apportent toutes leurs compétences à la table.
Pouvez-vous consulter le rapport MVP que vous prévisualisez fréquemment dans vos présentations et son fonctionnement ?
Le rapport MVP représente les pages les plus précieuses. Cela fonctionne en extrayant les données de chemin de Google Analytics, en les séquençant, puis en les soumettant à un modèle de chaîne de Markov pour déterminer quelles pages sont les plus susceptibles d'aider les conversions.
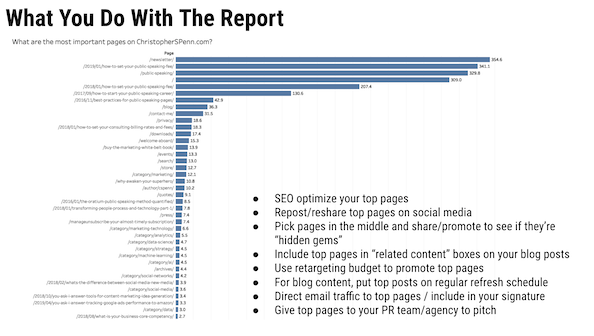
Et si vous voulez une explication plus longue.
Pouvez-vous donner plus d'informations sur le biais des données ? Quelles sont les considérations lors de la création de modèles NLP ou NLG ?
Oh oui. Il y a tant à dire ici. Tout d'abord, nous devons établir ce qu'est le biais, car il en existe deux types fondamentaux.
Les préjugés humains sont généralement acceptés comme étant « des préjugés en faveur ou à l'encontre de quelque chose par rapport à un autre, généralement d'une manière considérée comme injuste ».
Ensuite, il y a le biais mathématique, généralement accepté comme étant défini comme "Une statistique est biaisée si elle est calculée de telle manière qu'elle est systématiquement différente du paramètre de population estimé".
Ils sont différents mais liés. Le biais mathématique n'est pas nécessairement mauvais ; par exemple, vous voulez absolument avoir un parti pris en faveur de vos clients les plus fidèles si vous avez le moindre sens des affaires. Les préjugés humains sont implicitement mauvais dans le sens de l'injustice, en particulier contre tout ce qui est considéré comme une classe protégée : âge, sexe, orientation sexuelle, identité de genre, race/ethnie, statut d'ancien combattant, handicap, etc. Ce sont des classes que vous NE DEVEZ PAS discriminer.
Les préjugés humains engendrent des préjugés liés aux données, généralement à 6 endroits : les personnes, la stratégie, les données, les algorithmes, les modèles et les actions. Nous embauchons des personnes biaisées - il suffit de regarder la suite exécutive ou le conseil d'administration d'une entreprise pour déterminer quelle est sa partialité. J'ai vu une agence de relations publiques l'autre jour vanter son engagement envers la diversité et un clic à leur équipe de direction et ils sont d'une seule ethnie, tous les 15.
Je pourrais continuer BEAUCOUP de temps à ce sujet, mais je vous suggère de suivre un cours que j'ai développé sur ce sujet, au Marketing AI Institute. En termes de modèles NLG et NLP, nous devons faire quelques choses.
Premièrement, nous devons valider nos données. Y a-t-il un parti pris et, si oui, est-ce discriminatoire à l'encontre d'une classe protégée ? Deuxièmement, si c'est discriminatoire, est-il possible de l'atténuer ou devons-nous rejeter les données?
Une tactique courante consiste à transformer les métadonnées en biais. Si vous avez, par exemple, un ensemble de données composé à 60 % d'hommes et à 40 % de femmes, vous recodez 10 % des hommes en femmes pour l'équilibrer pour l'entraînement du modèle. C'est imparfait et pose quelques problèmes, mais c'est mieux que de laisser passer le préjugé.
Idéalement, nous avons intégré l'interprétabilité dans nos modèles qui nous permet d'effectuer des vérifications pendant le processus, puis nous validons également les résultats (explicabilité) a posteriori. Les deux sont nécessaires si vous souhaitez réussir un audit certifiant que vous n'introduisez pas de biais dans vos modèles. Woe est l'entreprise qui n'a que des explications post hoc.
Et enfin, vous avez absolument besoin d'une supervision humaine d'une équipe diversifiée et inclusive pour vérifier les résultats. Idéalement, vous utilisez un tiers, mais un tiers interne de confiance est acceptable. Le modèle et ses résultats présentent-ils un résultat biaisé par rapport à celui que vous obtiendriez de la population elle-même ?
Par exemple, si vous créiez du contenu pour les 16-22 ans et que vous n'avez pas vu une seule fois des termes comme deadass, dank, low-key, etc. dans le texte généré, vous n'avez pas réussi à capturer de données côté entrée. cela entraînerait le modèle à utiliser son langage avec précision.
Le plus grand défi ici est de gérer tout cela à travers des données non structurées. C'est la raison pour laquelle la lignée est si importante. Sans lignage, vous ne pouvez pas prouver que vous avez correctement échantillonné la population. La lignée est votre documentation sur la source des données, leur origine, la manière dont elles ont été collectées, si des exigences réglementaires ou des divulgations s'y appliquent.
Ce que tu dois faire maintenant
Lorsque vous êtes prêt… voici 3 façons dont nous pouvons vous aider à publier un meilleur contenu, plus rapidement :
- Réservez du temps avec MarketMuse Planifiez une démonstration en direct avec l'un de nos stratèges pour voir comment MarketMuse peut aider votre équipe à atteindre ses objectifs de contenu.
- Si vous souhaitez apprendre à créer un meilleur contenu plus rapidement, visitez notre blog. Il regorge de ressources pour vous aider à faire évoluer le contenu.
- Si vous connaissez un autre spécialiste du marketing qui aimerait lire cette page, partagez-la avec lui par e-mail, LinkedIn, Twitter ou Facebook.