
Identification des attributs subjectifs des entités
Publié: 2022-05-13Identification des attributs subjectifs UGC des entités
Ce brevet récemment accordé concerne l'identification des attributs subjectifs des entités.
Je n'ai pas vu de brevet sur les attributs subjectifs des entités ou les réponses à ces entités.
Un aspect essentiel de celui-ci est qu'il s'agit de contenu généré par l'utilisateur.
On nous dit que le contenu généré par les utilisateurs (UGC) est de plus en plus courant sur le Web en raison de la popularité croissante des réseaux sociaux, des blogs, des sites Web d'avis, etc.
Nous voyons souvent du contenu généré par les utilisateurs sous la forme de commentaires, tels que :
- Un commentaire d'un premier utilisateur sur un contenu partagé par un deuxième utilisateur au sein d'un réseau social
- Commentaires d'utilisateurs en réponse à un article du blog d'un chroniqueur
- Un commentaire d'un clip vidéo posté sur un site d'hébergement de contenu
- Avis (tels que des produits, des films)
- Actions (telles que J'aime !, Je n'aime pas !, +1, partage, mise en signet, liste de lecture, etc.)
- Ainsi de suite
Dans le cadre de ce brevet, un moyen d'identifier et de prédire les attributs subjectifs des entités (tels que des clips multimédias, des images, des articles de journaux, des entrées de blog, des personnes, des organisations, des entreprises commerciales, etc.) est fourni.
Cela commence par :
- Identifier un premier ensemble d'attributs subjectifs pour une première entité sur la base d'une réaction à la première entité (comme des commentaires sur un site Web, une démonstration d'approbation de la première entité (comme "J'aime !, etc.)
- Partage de la première entité
- Mettre en signet la première entité
- Ajouter la première entité à une liste de lecture
- Formation d'un classificateur (tel qu'une machine à vecteurs de support, AdaBoost, un réseau de neurones, un arbre de décision sur un ensemble de mappages d'entrée-sortie, où l'ensemble de mappages d'entrée-sortie comprend un mappage d'entrée-sortie dont l'entrée est Fournir un vecteur de caractéristiques pour la première entité, dont la sortie est basée sur le premier ensemble d'attributs subjectifs
- Fournir un vecteur de caractéristiques pour une deuxième entité au classificateur formé pour obtenir un deuxième ensemble d'attributs subjectifs pour la deuxième entité
Une mémoire et un processeur sont fournis pour identifier et prédire des attributs subjectifs pour des entités.
Un support de stockage lisible par ordinateur contient des instructions qui amènent un système informatique à effectuer des opérations comprenant :
- Identification d'un premier ensemble d'attributs subjectifs pour une première entité sur la base d'une réaction à la première entité
- Obtention d'un premier vecteur de caractéristiques pour la première entité
- Apprentissage d'un classificateur sur un ensemble de mappages d'entrée-sortie, l'ensemble de mappages d'entrée-sortie comprenant un mappage d'entrée-sortie dont l'entrée est basée sur le premier vecteur de caractéristiques et dont la sortie est basée sur le premier ensemble d'attributs subjectifs
- Obtention d'un deuxième vecteur de caractéristiques pour une deuxième entité
- Fournir au classificateur, après l'apprentissage, le deuxième vecteur de caractéristiques pour obtenir un deuxième ensemble d'attributs subjectifs pour la deuxième entité
Ce brevet sur l'identification des attributs subjectifs des entités = se trouve à :
Identifier les attributs subjectifs par l'analyse des signaux de curation
Inventeurs : Hrishikesh Aradhye et Sanketh Shetty
Cessionnaire : Google LLC
Brevet américain : 11 328 218
Attribué : 10 mai 2022
Date de dépôt : 6 novembre 2017
Abstrait:
L'invention concerne un système et un procédé d'identification et de prédiction d'attributs subjectifs pour des entités (telles que des clips multimédias, des films, des émissions de télévision, des images, des articles de journaux, des entrées de blog, des personnes, des organisations, des entreprises commerciales, etc.).
Dans un aspect, des attributs subjectifs pour un premier élément multimédia sont identifiés sur la base d'une réaction au premier élément multimédia, et des scores de pertinence pour les qualités personnelles concernant le premier élément multimédia sont déterminés.
Un classificateur est entraîné en utilisant (i) une entrée d'entraînement comprenant un ensemble de caractéristiques pour le premier élément multimédia et une sortie cible pour l'entrée d'entraînement, la sortie cible comprenant les scores de pertinence respectifs pour les attributs subjectifs du premier élément multimédia.
Identifier et prédire les attributs subjectifs des entités
Moyens d'identifier et de prédire les attributs subjectifs des entités (tels que des clips multimédias, des images, des articles de journaux, des entrées de blog, des personnes, des organisations, des entreprises commerciales, etc.).
Les attributs subjectifs (tels que "mignon", "drôle", "génial", etc.) sont définis, et les attributs subjectifs d'une entité particulière sont identifiés en fonction de la réaction de l'utilisateur à l'entité, tels que :
- Commentaires sur un site web
- Aimer!
- Partager la première entité avec d'autres utilisateurs
- Marquer la première entité
- Ajouter la première entité à une liste de lecture
- Etc
Les scores de pertinence pour les attributs subjectifs sont déterminés à propos de l'entité
Si l'attribut subjectif "mignon" apparaît dans une proportion importante de commentaires pour un clip vidéo, alors "mignon" peut se voir attribuer un score de pertinence élevé.
L'entité est ensuite associée aux attributs subjectifs et aux scores de pertinence identifiés (tels que via des balises appliquées à l'entité, via des entrées dans une table d'une base de données relationnelle, etc.).
La procédure ci-dessus est effectuée pour chaque entité dans un ensemble d'entités donné (comme des clips vidéo dans un référentiel de clips vidéo, etc.), et un mappage inverse des attributs subjectifs aux entités du groupe est généré en fonction des qualités personnelles et des scores de pertinence. .
Le mappage inverse peut alors être utilisé pour identifier toutes les entités de l'ensemble qui correspondent à un attribut subjectif donné (comme toutes les entités qui ont été associées à l'attribut subjectif "drôle", etc.), permettant ainsi :
- Récupération rapide des entités pertinentes pour le traitement des recherches par mots-clés
- Remplir des listes de lecture
- Diffuser des publicités
- Génération d'ensembles d'entraînement pour le classifieur
- Ainsi de suite
Un classificateur (tel qu'une machine à vecteurs de support [SVM], AdaBoost, un réseau de neurones, un arbre de décision, etc.) est formé en fournissant un ensemble d'exemples de formation, où l'entrée d'un exemple de formation comprend un vecteur de caractéristiques obtenu à partir d'un entité particulière (telle qu'un vecteur de caractéristiques pour un clip vidéo.
Il peut contenir des valeurs numériques concernant :
- Couleur
- Texture
- Intensité
- Balises de métadonnées associées au clip vidéo
- Etc
La sortie a des scores de pertinence pour chaque attribut subjectif dans le vocabulaire de l'entité particulière.
Le classificateur entraîné peut alors prédire les attributs subjectifs des entités qui ne figurent pas dans l'ensemble d'entraînement (comme un clip vidéo récemment téléchargé, un article d'actualité qui n'a pas encore reçu de commentaires, etc.).
Ce brevet peut classer les entités selon des attributs subjectifs tels que "drôle", "mignon", etc. en fonction de la réaction de l'utilisateur aux entités.
Ce brevet peut améliorer la qualité des descriptions d'entités, telles que les balises d'un clip vidéo, améliorer la qualité des recherches et le ciblage des publicités.
Une architecture système pour identifier les attributs subjectifs
L'architecture du système comprend :
- Ordinateur serveur
- Magasin d'entités
- Les machines clientes sont connectées à un réseau
Le réseau peut être public (tel qu'Internet), un réseau privé (tel qu'un réseau local (LAN) ou un réseau étendu (WAN)), ou une combinaison de ceux-ci.
Les machines clientes peuvent être des terminaux sans fil (smartphones, etc.), des ordinateurs personnels (PC), des ordinateurs portables, des tablettes ou tout autre dispositif informatique ou de communication.
Les machines clientes peuvent exécuter un système d'exploitation (OS) qui gère le matériel et les logiciels des machines clientes.
Un navigateur (non représenté) peut s'exécuter sur les machines clientes (comme sur le système d'exploitation des machines clientes).
Le navigateur peut être un navigateur Web qui peut accéder à des pages Web et à du contenu servi par un serveur Web.
Les machines clientes peuvent également télécharger :
- les pages Web
- Extraits média
- Entrées de blog
- liens vers des articles
- Ainsi de suite
La machine serveur comprend un serveur Web et un gestionnaire d'attributs subjectifs. Le serveur Web et le gestionnaire d'attributs émotionnels peuvent s'exécuter sur différents appareils.
Le magasin d'entités est un stockage persistant capable de stocker des entités telles que des clips multimédias (tels que des clips vidéo, des clips audio, des clips contenant à la fois de la vidéo et de l'audio, des images, etc.) et d'autres types d'éléments de contenu (tels que des pages Web, des documents basés, critiques de restaurants, critiques de films, etc.), ainsi que des structures de données pour étiqueter, organiser et indexer les entités.
Le magasin d'entités peut être hébergé par des périphériques de stockage, tels que la mémoire principale, des disques magnétiques ou optiques, des bandes ou des disques durs, NAS, SAN, etc.
Le magasin d'entités peut être hébergé par un serveur de fichiers connecté au réseau. En revanche, dans d'autres implémentations, le magasin d'entités peut être hébergé par un autre type de stockage persistant tel que celui de la machine serveur ou différentes machines couplées à la machine serveur via le réseau.
Les entités stockées dans le magasin d'entités peuvent inclure du contenu généré par l'utilisateur qui est téléchargé par les machines clientes et peut inclure du contenu fourni par des fournisseurs de services tels que :
- Organismes de presse
- Éditeurs
- Bibliothèques
- Bientôt
Le serveur peut servir des pages Web et du contenu des magasins d'entités aux clients.
Le gestionnaire d'attributs subjectifs :
- Identifie les attributs subjectifs des entités en fonction de la réaction de l'utilisateur (comme les commentaires, J'aime !, le partage, la mise en signet, la liste de lecture, etc.)
- Détermine les scores de pertinence pour les attributs subjectifs sur les entités
- Associe des attributs subjectifs et des scores de pertinence aux entités
- Extrait des caractéristiques telles que des caractéristiques d'image telles que la couleur, la texture et l'intensité ; caractéristiques audio telles que l'amplitude, les rapports de coefficients spectraux ; les caractéristiques textuelles telles que la fréquence des mots, la longueur moyenne des phrases, les paramètres de formatage ; les métadonnées associées à l'entité ; etc.) à partir d'entités pour générer des vecteurs de caractéristiques
- Entraîne un classificateur basé sur les vecteurs de caractéristiques et les scores de pertinence des attributs subjectifs
- Utilise le classificateur formé pour prédire les attributs subjectifs des nouvelles entités en fonction des vecteurs de caractéristiques des nouvelles entités
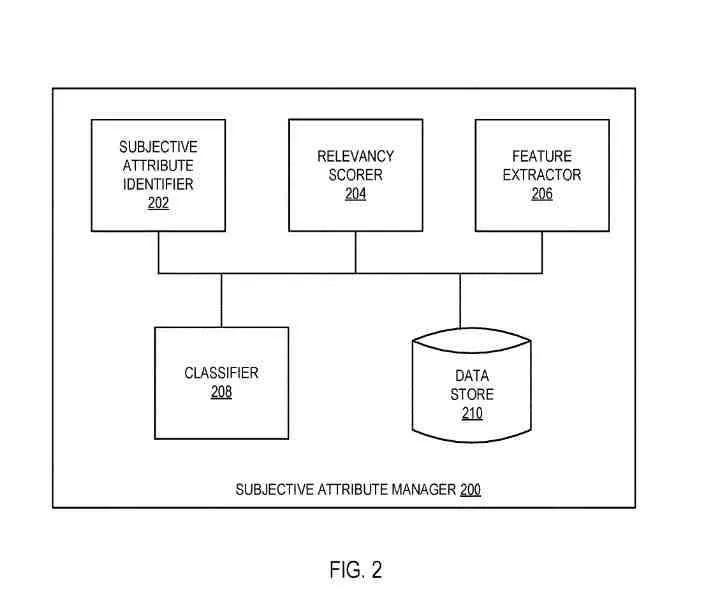
Un gestionnaire d'attributs subjectif
Le gestionnaire d'attributs subjectifs peut être le même que le gestionnaire d'attributs subjectifs et peut comprendre :
- Identificateur d'attribut subjectif
- Scoreur de pertinence
- Extracteur de fonctionnalités
- Classificateur
- Magasin de données
.
Les composants peuvent être combinés ou séparés dans d'autres détails.
Le magasin de données peut être le même que le magasin d'entités ou un magasin de données différent (tel qu'un tampon temporaire ou un magasin de données permanent) pour contenir un vocabulaire d'attributs personnels, des entités à traiter, des vecteurs de caractéristiques associés à des entités, des attributs personnels et les scores de pertinence liés aux entités, ou une combinaison de ces données.
La banque de données peut être hébergée par des périphériques de stockage, tels que la mémoire principale, des disques magnétiques ou optiques, des bandes ou des disques durs, etc.
Le gestionnaire d'attributs subjectifs informe les utilisateurs des types d'informations stockées dans le magasin de données et le magasin d'entités et permet aux utilisateurs de choisir de ne pas collecter et partager ces informations avec le gestionnaire d'attributs subjectifs.
L'identifiant d'attribut subjectif
L'identificateur d'attribut personnel identifie des attributs subjectifs pour des entités sur la base de la réaction de l'utilisateur aux entités.
L'identifiant d'attribut personnel peut identifier des attributs subjectifs par traitement de texte de commentaires d'utilisateurs à une entité publiée par un utilisateur sur un site Web de réseautage social.
L'identifiant d'attribut subjectif peut identifier les attributs subjectifs des entités en fonction d'autres types de réactions des utilisateurs aux entités, telles que :
- 'Aimer!' ou "Je n'aime pas !"
- Partage de l'entité
- Ajouter l'entité aux signets
- Ajouter l'entité à une liste de lecture
- Ainsi de suite
L'identifiant d'attribut personnel peut appliquer des seuils pour déterminer quels attributs sont associés à une entité (tel qu'un attribut subjectif doit apparaître dans au moins N commentaires, etc.).
Le marqueur de pertinence détermine des scores de pertinence pour des attributs subjectifs concernant des entités.
Par exemple, lorsque l'identifiant d'attribut subjectif a identifié les attributs subjectifs « mignon », « drôle » et « génial » sur la base des commentaires d'un clip multimédia publié sur un site Web de réseau social, le marqueur de pertinence peut déterminer les scores de pertinence pour chacun de ces trois éléments subjectifs. attributs basés sur :
- La fréquence à laquelle ces attributs subjectifs apparaissent dans les commentaires
- Les utilisateurs particuliers qui ont fourni les attributs subjectifs
- Ainsi de suite
Par exemple, s'il y a 40 commentaires et que « mignon » apparaît dans 20 mots et « génial » apparaît dans 8 commentaires, alors « mignon » peut se voir attribuer un score de pertinence supérieur à « génial ».
Les scores de pertinence peuvent être attribués en fonction de la proportion de commentaires dans lesquels un attribut subjectif apparaît (comme un score de 0,5 pour « mignon » et un score de 0,2 pour « génial », etc.).
Le marqueur de pertinence peut ne conserver que les k attributs subjectifs les plus pertinents et écarter les autres attributs personnels.
Par exemple, supposons que l'identifiant d'attribut personnel identifie sept attributs émotionnels qui apparaissent dans les commentaires des utilisateurs au moins trois fois. Dans ce cas, le marqueur de pertinence peut, par exemple, ne retenir que les cinq attributs subjectifs avec les scores de pertinence les plus élevés et écarter les deux autres attributs émotionnels (par exemple en mettant leurs scores de pertinence à zéro, etc.).
Un score de pertinence est un nombre naturel compris entre 0,0 et 1,0 inclus.
L'extracteur de caractéristiques obtient un vecteur de caractéristiques pour une entité à l'aide de techniques telles que :
- Analyse en composantes principales
- Plongements semi-définis
- Isocartes
- Moindres carrés partiels
- Ainsi de suite
Les calculs associés à l'extraction des caractéristiques d'une entité sont effectués par l'extracteur de caractéristiques lui-même.

Dans certains autres aspects, ces calculs sont effectués par une autre entité, telle qu'une bibliothèque exécutable de :
- Routines de traitement d'image hébergées par la machine serveur [non représentées dans les figures]
- Routines de traitement audio
- Routines de traitement de texte
- Etc
Les résultats sont fournis à l'extracteur de caractéristiques.
Le classificateur est une machine d'apprentissage (comme les machines à vecteurs de support [SVM], AdaBoost, les réseaux de neurones, les arbres de décision, etc.) qui accepte en entrée un vecteur de caractéristiques associé à une entité et génère des scores de pertinence (comme un nombre réel entre 0 et 1 inclus, etc.) pour chaque attribut subjectif du vocabulaire des attributs personnels.
Le classificateur se compose d'un seul classificateur.
Le classificateur peut comprendre plusieurs classificateurs (tels qu'un classificateur pour chaque attribut subjectif dans le vocabulaire des attributs personnels, etc.).
Un ensemble d'exemples positifs et de critères négatifs sont rassemblés pour chaque attribut subjectif dans le vocabulaire des attributs personnels.
L'ensemble d'exemples positifs pour un attribut subjectif peut comprendre des vecteurs de caractéristiques pour des entités associées à cet attribut personnel particulier.
L'ensemble d'exemples négatifs pour un attribut subjectif peut comprendre des vecteurs de caractéristiques pour des entités qui n'ont pas été associées à cet attribut personnel particulier.
Lorsque l'ensemble d'exemples positifs et l'ensemble de critères négatifs sont de taille inégale, l'ensemble le plus étendu peut être échantillonné pour correspondre à la taille du plus petit groupe.
Après l'apprentissage, le classificateur peut prédire des attributs subjectifs pour d'autres entités ne faisant pas partie de l'ensemble d'apprentissage en fournissant des vecteurs de caractéristiques pour ces entités en entrée du classificateur.
Un ensemble d'attributs subjectifs peut être obtenu à partir de la sortie du classificateur en incluant tous les attributs émotionnels avec des scores de pertinence non nuls. Un groupe de points subjectifs peut être obtenu en appliquant le seuil le plus mineur aux scores numériques (en considérant tous les attributs personnels qui ont un score d'au moins, disons, 0,2 comme faisant partie de l'ensemble).
Identification des attributs subjectifs des entités
Le procédé est exécuté en traitant une logique qui peut comprendre du matériel (circuits, logique dédiée, etc.), un logiciel (tel qu'exécuté sur un système informatique à usage général ou une machine dédiée), ou les deux.
La méthode est exécutée par la machine serveur, tandis que d'autres implémentations peuvent être exécutées par un autre appareil.
Divers composants des gestionnaires d'attributs subjectifs peuvent s'exécuter sur des machines distinctes (comme l'identifiant d'attribut personnel et le scoreur de pertinence peuvent s'exécuter sur un appareil tandis que l'extracteur de caractéristiques et le classificateur s'exécutent sur un autre appareil, etc.).
Pour simplifier l'explication, la méthode est représentée et décrite comme une série d'actes.
Mais des actes peuvent se produire dans divers ordres et et avec d'autres actes non présentés et décrits ici.
En outre, tous les actes illustrés peuvent ne pas être requis pour installer les procédés par l'objet divulgué.
De plus, l'homme du métier comprendra et appréciera que le procédé pourrait être représenté comme une série d'états interdépendants via un diagramme d'états ou des événements.
De plus, il convient de noter que les procédés décrits dans cette spécification peuvent être stockés sur un article de fabrication pour faciliter le transport et le transfert de telles méthodologies vers des dispositifs informatiques.
Le terme article de fabrication, tel qu'il est utilisé ici, est destiné à englober un programme informatique accessible à partir de tout dispositif lisible par ordinateur ou support de stockage.
Un vocabulaire d'attributs subjectifs est généré.
Dans certains aspects, le vocabulaire des attributs subjectifs peut être défini. En revanche, dans certains autres facteurs, le vocabulaire des attributs personnels peut être généré de manière automatisée en collectant des termes et des phrases qui sont utilisés dans les réactions des utilisateurs aux entités. En revanche, dans d'autres aspects encore, le vocabulaire peut être généré par une combinaison de techniques manuelles et automatisées.
Le vocabulaire est ensemencé avec un petit nombre d'attributs subjectifs censés s'appliquer aux entités. Le vocabulaire s'élargit au fil du temps à mesure que davantage de termes ou d'expressions apparaissant dans les réactions des utilisateurs sont identifiés via le traitement automatisé des réponses.
Le vocabulaire des attributs subjectifs peut être organisé hiérarchiquement, éventuellement sur la base de « méta-attributs » associés aux attributs personnels (comme l'attribut personnel « drôle » peut avoir un méta-attribut « positif », tandis que le point subjectif « dégoûtant » peut avoir un méta-attribut « négatif », etc.).
Un ensemble S d'entités (comme toutes les entités du magasin d'entités, un sous-ensemble d'entités du magasin d'entités, etc.) est prétraité.
Sous un aspect, le prétraitement des entités comprend l'identification des réactions des utilisateurs aux entités, puis l'apprentissage d'un classificateur sur la base des réponses.
Lorsqu'une entité est une entité physique réelle
Il convient de noter que lorsqu'une entité est une entité physique réelle (telle qu'une personne, un restaurant, etc.), le prétraitement de l'entité est effectué via un "cyber proxy" associé à l'entité physique (telle qu'un fan page d'un acteur sur un site de réseau social, avis de restaurant sur un site internet, etc.) ; mais, les attributs subjectifs sont considérés comme étant associés à l'entité elle-même (comme l'acteur ou le restaurant, pas la page fan de l'acteur ou la critique du restaurant).
Un exemple d'une méthode pour effectuer get décrit en détail.
L'entité Atn E qui n'est pas dans l'ensemble S est reçue (comme un clip vidéo récemment téléchargé, un article de presse qui n'a pas encore reçu de commentaires, une entité dans le magasin d'entités qui n'était pas incluse dans l'ensemble de formation, etc.).
Les attributs de sujet et les scores de pertinence pour l'entité E sont obtenus.
Une mise en œuvre d'un premier exemple de procédé est décrite en détail ci-dessous, et les performances d'un second exemple de procédé sont décrites.
Les attributs subjectifs et les scores de pertinence obtenus sont associés à l'entité E (par exemple en appliquant des balises correspondantes à l'entité, en ajoutant un enregistrement dans une table de base de données relationnelle, etc.).
L'exécution continue en arrière.
Il convient de noter que le classifieur peut être ré-entraîné (par exemple toutes les 100 itérations de la boucle, tous les N jours, etc.) par un processus de ré-apprentissage qui peut s'exécuter simultanément.
Pré-traitement d'un ensemble d'entités
Le procédé est exécuté en traitant une logique qui peut comprendre du matériel (circuits, logique dédiée, etc.), un logiciel (tel qu'exécuté sur un système informatique à usage général ou une machine dédiée), ou les deux.
La méthode est exécutée, tandis que dans certaines autres implémentations, elle peut être exécutée par une autre machine.
L'ensemble d'apprentissage est initialisé sur l'ensemble vide. Une entité E est sélectionnée et supprimée de l'ensemble S d'entités.
Les attributs subjectifs de l'entité E sont identifiés en fonction des réactions des utilisateurs à l'entité E (comme les commentaires des utilisateurs, J'aime !, la mise en signet, le partage, l'ajout à une liste de lecture, etc.).
L'identification des attributs subjectifs comprend le traitement des commentaires des utilisateurs, par exemple :
- Faire correspondre les mots dans les commentaires des utilisateurs avec les attributs subjectifs du vocabulaire
- Combiner la correspondance des mots et d'autres techniques de traitement du langage naturel telles que l'analyse syntaxique et sémantique
- Etc
Entités qui se produisent à proximité d'emplacements
Les réactions des utilisateurs peuvent être agrégées pour des entités qui se produisent dans de nombreux endroits, telles que :
- Entités qui apparaissent dans les listes de lecture de nombreux utilisateurs
- Entités qui ont été partagées et qui apparaissent dans les "flux d'actualités" d'une pluralité d'utilisateurs sur un site Web de réseau social
- Etc
Les différents emplacements peuvent être pondérés dans leur contribution aux scores de pertinence en fonction de divers facteurs, tels que :
L'utilisateur particulier associé à l'emplacement (par exemple, un utilisateur spécifique peut être une autorité en matière de musique classique et, par conséquent, les commentaires sur une entité dans son fil d'actualité peuvent être plus pondérés que les commentaires dans un autre fil d'actualité, etc.), les réactions non textuelles de l'utilisateur (telles que comme "J'aime !", "Je n'aime pas !", "+1", etc.).
De plus, le nombre d'emplacements où l'entité apparaît peut également être utilisé pour déterminer les attributs subjectifs et les scores de pertinence (tels que les scores de pertinence pour un clip vidéo peuvent être augmentés lorsque le clip vidéo se trouve dans des centaines de listes de lecture d'utilisateurs, etc.).
Le bloc est exécuté par l'identifiant d'attribut subjectif.
Les scores de pertinence pour les attributs subjectifs sont déterminés par l'entité E.
Un score de pertinence est déterminé pour un attribut subjectif particulier en fonction de la fréquence à laquelle l'attribut personnel apparaît dans les commentaires des utilisateurs, les utilisateurs spécifiques qui ont fourni les détails subjectifs dans leurs mots (par exemple, certains utilisateurs peuvent être connus par expérience pour être plus précis dans leurs commentaires que les autres utilisateurs, etc.).
Par exemple, s'il y a 40 commentaires et que « mignon » apparaît dans 20 mots et « génial » apparaît dans 8 commentaires, alors « mignon » peut se voir attribuer un score de pertinence supérieur à « génial ».
Les notes de pertinence peuvent être attribuées en fonction de la proportion de commentaires dans lesquels un attribut subjectif apparaît (comme une note de 0,5 pour « mignon » et une note de 0,2 pour « génial », etc.).
Sous un aspect, les scores de pertinence sont normalisés pour tomber par intervalles [0, 1].
Selon certains aspects, les attributs subjectifs identifiés peuvent être rejetés en fonction de leurs scores de pertinence (comme conserver les k attributs émotionnels avec les scores de pertinence les plus élevés, rejeter tout attribut personnel dont le score de pertinence est inférieur à un seuil, etc.).
Il convient de noter qu'un attribut subjectif peut être écarté en fixant son score de pertinence à zéro dans certains aspects.
Des attributs subjectifs et des scores de pertinence sont associés aux entités
Les attributs subjectifs et les scores de pertinence sont associés aux entités (comme par exemple via un balisage, des entrées dans une table d'une base de données relationnelle, etc.).
Un vecteur de caractéristiques pour l'entité E est obtenu.
Dans un aspect, le vecteur caractéristique pour un clip vidéo ou une image fixe peut contenir des valeurs numériques concernant la couleur, la texture, l'intensité, etc., tandis que le vecteur caractéristique pour un clip audio (ou un clip vidéo avec son) peut inclure des valeurs numériques concernant l'amplitude , coefficients spectraux, etc., tandis que le vecteur de caractéristiques d'un document texte peut inclure :
- Valeurs numériques sur les fréquences de mots
- Durée moyenne des peines
- Paramètres de formatage
- Ainsi de suite
Cela peut être effectué par l'extracteur de fonctionnalités.
Le vecteur de caractéristiques et les scores de pertinence obtenus sont ajoutés à l'ensemble d'apprentissage.
Le bloc vérifie si l'ensemble S d'entités est vide ; si S n'est pas vide, l'exécution continue, sinon l'exécution continue.
Le classificateur est formé sur tous les exemples de l'ensemble d'apprentissage, de sorte que le vecteur de caractéristiques d'un exemple d'apprentissage est fourni en entrée au classificateur, et les scores de pertinence des attributs subjectifs sont fournis en sortie.
Obtention d'attributs subjectifs et de scores de pertinence pour une entité
Un vecteur de caractéristiques pour l'entité E est généré.
Comme décrit ci-dessus, le vecteur caractéristique d'un clip vidéo ou d'une image fixe peut contenir des valeurs numériques concernant la couleur, la texture, l'intensité, etc. En revanche, le vecteur caractéristique d'un clip audio (ou d'un clip vidéo avec son) peut inclure des valeurs numériques sur l'amplitude, les coefficients spectraux, etc. En revanche, le vecteur de caractéristiques d'un document texte peut inclure des valeurs numériques sur la fréquence des mots, la longueur moyenne des phrases, les paramètres de formatage, etc.
Le classificateur formé fournit le vecteur de caractéristiques pour obtenir les attributs subjectifs prédits et les scores de pertinence pour l'entité E.
Les attributs subjectifs prédits et les scores de pertinence sont associés à l'entité E (par exemple via des balises appliquées à l'entité E, via des entrées dans une table d'une base de données relationnelle, etc.).
Une deuxième méthode pour obtenir des attributs subjectifs et des scores de pertinence pour une entité
Le procédé est exécuté en traitant une logique qui peut comprendre du matériel (circuit, logique dédiée, etc.), un logiciel ou une combinaison des deux.
La méthode est exécutée par la machine serveur, tandis que d'autres peuvent être exécutées par un autre appareil.
Un vecteur de caractéristiques pour l'entité E est généré. Le classificateur formé fournit le vecteur de caractéristiques pour obtenir les attributs subjectifs prédits et les scores de pertinence pour l'entité E.
Les attributs subjectifs prédits obtenus sont suggérés à un utilisateur (tel que l'utilisateur qui a téléchargé l'entité). Un ensemble affiné d'attributs personnels est obtenu de l'utilisateur, par exemple via une page Web dans laquelle l'utilisateur sélectionne parmi les attributs suggérés et éventuellement ajoute de nouveaux attributs, etc.).
Un score de pertinence par défaut pour les entités
Un score de pertinence par défaut est attribué à tous les nouveaux attributs subjectifs ajoutés par l'utilisateur.
Le score de pertinence par défaut peut être de 1,0 sur une échelle de 0,0 à 1,0, le score de pertinence par défaut peut être basé sur l'utilisateur particulier (par exemple, un score de 1,0 lorsque l'utilisateur est connu par le passé pour être très bon pour suggérer des attributs, un score de 0,8 lorsque l'utilisateur est connu pour être assez doué pour suggérer des attributs, etc.).
Les branches de blocage sont basées sur le fait que l'utilisateur a supprimé l'un des attributs subjectifs suggérés (par exemple en ne sélectionnant pas l'attribut).
L'entité E est stockée en tant qu'exemple négatif du ou des attributs supprimés pour un futur réapprentissage du classificateur. L'ensemble raffiné d'attributs subjectifs et les scores de pertinence correspondants sont associés à l'entité E (par exemple via des balises appliquées à l'entité E, via des entrées dans une table d'une base de données relationnelle, etc.).