
Noindex Nofollow et Disallow : directives du robot de recherche
Publié: 2022-12-01Il existe trois directives (commandes) que vous pouvez utiliser pour dicter la manière dont les moteurs de recherche découvrent, stockent et diffusent les informations de votre site en tant que résultats de recherche :
- NoIndex : ne pas ajouter ma page aux résultats de la recherche.
- NoFollow : Ne regardez pas les liens sur cette page.
- Interdire : ne pas consulter cette page du tout.
Ces directives vous permettent de contrôler quelles pages de votre site peuvent être explorées par les moteurs de recherche et apparaître dans la recherche.
Que signifie Pas d'index ?
La directive noindex indique aux robots de recherche, comme googlebot, de ne pas inclure une page Web dans ses résultats de recherche.

Comment marquez-vous une page sans index ?
Il existe deux manières d'émettre une directive noindex :
- Ajouter une balise meta noindex au code HTML de la page
- Renvoyer un en-tête noindex dans la requête HTTP
En utilisant la balise méta "pas d'index" pour une page, ou comme en-tête de réponse HTTP, vous masquez essentiellement la page de la recherche.
La directive noindex peut également être utilisée pour bloquer uniquement des moteurs de recherche spécifiques. Par exemple, vous pouvez empêcher Google d'indexer une page tout en autorisant Bing :
Exemple : Blocage de la plupart des moteurs de recherche*
<meta name=”robots” content=”noindex”>
Exemple : Blocage de Google uniquement
<meta name=”googlebot” content=”noindex”>
Remarque : depuis septembre 2019, Google ne respecte plus les directives noindex dans le fichier robots.txt . Noindex DOIT maintenant être émis via une balise méta HTML ou un en-tête de réponse HTTP. Pour les utilisateurs plus avancés, l' interdiction fonctionne toujours pour le moment, mais pas pour tous les cas d'utilisation.
Quelle est la différence entre noindex et nofollow ?
C'est une différence entre stocker du contenu et découvrir du contenu :
noindex est appliqué au niveau de la page et indique à un robot d'indexation de moteur de recherche de ne pas indexer et servir une page dans les résultats de la recherche.
nofollow est appliqué au niveau de la page ou du lien et indique à un robot d'exploration du moteur de recherche de ne pas suivre (découvrir) les liens.
Essentiellement, la balise noindex supprime une page de l'index de recherche et un attribut nofollow supprime un lien du graphique de liens du moteur de recherche.
NoFollow comme attribut de page
L'utilisation du nofollow au niveau de la page signifie que les robots ne suivront aucun des liens de cette page pour découvrir du contenu supplémentaire, et les robots n'utiliseront pas les liens comme signaux de classement pour les sites cibles.
<meta name=”robots” content=”nofollow”>
NoFollow en tant qu'attribut de lien
L'utilisation du nofollow au niveau du lien empêche les robots d'exploration d'explorer un lien spécifique à l'annonce et empêche que ce lien soit utilisé comme signal de classement.
La directive nofollow est appliquée au niveau du lien à l'aide d'un attribut rel dans la balise a href :
<a href="https://domain.com" rel="nofollow">
Pour Google en particulier, l'utilisation de l'attribut de lien nofollow empêchera votre site de transmettre le PageRank aux URL de destination.
Pourquoi devriez-vous marquer une page comme NoFollow ?
Pour la majorité des cas d'utilisation, vous ne devez pas marquer une page entière comme nofollow - marquer des liens individuels comme nofollow suffira.
Vous marqueriez une page entière comme nofollow si vous ne vouliez pas que Google affiche les liens sur la page, ou si vous pensiez que les liens sur la page pourraient nuire à votre site.
Dans la plupart des cas, des directives générales de non- suivi au niveau de la page sont utilisées lorsque vous n'avez pas le contrôle sur le contenu publié sur une page Certains éditeurs haut de gamme ont également appliqué de manière générale la directive nofollow à leurs pages pour dissuader leurs rédacteurs de placer des liens sponsorisés dans leur contenu.
Comment utiliser les pages NoIndex ?
Marquez les pages comme noindex qui sont peu susceptibles de fournir de la valeur aux utilisateurs et ne doivent pas apparaître dans les résultats de recherche. Par exemple, il est peu probable que les pages qui existent pour la pagination aient le même contenu affiché dessus au fil du temps.
Il est peu probable que Domain.com/category/resultspage=2 montre à un utilisateur de meilleurs résultats que domain.com/category/resultspage=1 et les deux pages ne seraient en concurrence que dans la recherche. Il est préférable de ne pas indexer les pages dont le seul but est la pagination.
Voici les types de pages que vous devriez envisager de ne pas indexer :
- Pages utilisées pour la pagination
- Pages de recherche internes
- Pages de destination optimisées pour les annonces
- Ex : affiche uniquement un argumentaire et un formulaire d'inscription, pas de navigation principale
- Ex : variantes en double du même contenu, utilisées uniquement pour les annonces
- Pages d'auteur archivées
- Pages dans les flux de paiement
- Pages de confirmation
- Ex : pages de remerciement
- Ex : Commander des pages complètes
- Ex : Succès ! pages
- Certaines pages générées par des plug-ins qui ne sont pas pertinentes pour votre site (par exemple : si vous utilisez un plug-in de commerce mais n'utilisez pas leurs pages de produits habituelles)
- Pages d'administration et pages de connexion d'administrateur
Marquer une page Noindex et Nofollow
Une page marquée à la fois noindex et nofollow empêchera un crawler d'indexer cette page et empêchera un crawler d'explorer les liens sur la page.
Essentiellement, l'image ci-dessous montre ce qu'un moteur de recherche verra sur une page Web en fonction de la façon dont vous avez utilisé les directives noindex et nofollow :

Marquage d'une page déjà indexée comme NoIndex
Si un moteur de recherche a déjà indexé une page et que vous la marquez comme noindex , la prochaine fois que la page sera explorée, elle sera supprimée des résultats de la recherche Pour que cette méthode de suppression d'une page de l'index fonctionne, vous ne devez pas bloquer (interdire) le robot avec votre fichier robots.txt.
Si vous dites à un crawler de ne pas lire la page, il ne verra jamais le marqueur noindex et la page restera indexée bien que son contenu ne soit pas actualisé.
Comment empêcher les moteurs de recherche d'indexer mon site ?
Si vous souhaitez supprimer une page de l'index de recherche, une fois qu'elle a déjà été indexée, vous pouvez effectuer les étapes suivantes :
- Appliquer la directive noindex Ajouter l'attribut noindex à la balise meta ou à l'en-tête de réponse HTTP
- Demander au moteur de recherche d'explorer la page Pour Google, vous pouvez le faire dans la console de recherche, demander à Google de réindexer la page. Cela déclenchera l'exploration de la page par Googlebot, où Googlebot découvrira la directive noindex. Vous devrez le faire pour chaque moteur de recherche dont vous souhaitez supprimer la page.
- Confirmer que la page a été supprimée de la recherche Une fois que vous avez demandé au robot d'exploration de revisiter votre page Web, laissez-lui un peu de temps, puis confirmez que votre page a été supprimée des résultats de recherche. Vous pouvez le faire en accédant à n'importe quel moteur de recherche et en saisissant l'URL cible du site, comme dans l'image ci-dessous.
Si votre recherche ne renvoie aucun résultat, votre page a été supprimée de cet index de recherche. - Si la page n'a pas été supprimée Vérifiez que vous n'avez pas de directive "disallow" dans votre fichier robots.txt. Google et les autres moteurs de recherche ne peuvent pas lire la directive noindex s'ils ne sont pas autorisés à explorer la page. Si vous le faites, supprimez la directive d'interdiction pour la page cible, puis demandez à nouveau l'exploration.
- Définissez une directive d'interdiction pour la page cible dans votre fichier robots.txt Disallow : /page$
Vous devrez placer le signe dollar à la fin de l'URL dans votre fichier robots.txt ou vous risquez d'interdire accidentellement toutes les pages sous cette page, ainsi que toutes les pages commençant par la même chaîne. Ex : Disallow : /sweater désactivera également /sweater-weather et /sweater/green, mais Disallow : /sweater$ n'autorisera que la page exacte /sweater.
Comment pour supprimer une page de la recherche Google
Si la page que vous souhaitez supprimer de la recherche se trouve sur un site que vous possédez ou gérez, la plupart des sites peuvent utiliser l'outil de suppression d'URL pour les webmasters.
L'outil de suppression d'URL Webmaster ne supprime le contenu de la recherche que pendant environ 90 jours. Si vous souhaitez une solution plus permanente, vous devrez utiliser une directive noindex, interdire l'exploration de votre fichier robots.txt ou supprimer la page de votre site. Google fournit des instructions supplémentaires pour la suppression permanente d'URL ici.

Si vous essayez de supprimer une page de la recherche pour un site qui ne vous appartient pas, vous pouvez demander à Google de supprimer la page de la recherche si elle répond aux critères suivants :
- Affiche des informations personnelles telles que votre carte de crédit ou votre numéro de sécurité sociale
- La page fait partie d'un programme malveillant ou d'hameçonnage
- La page enfreint la loi
- La page viole un droit d'auteur
Si la page ne répond pas à l'un des critères ci-dessus, vous pouvez contacter une société de référencement ou une société de relations publiques pour obtenir de l'aide dans la gestion de la réputation en ligne.
Devriez-vous ne pas indexer les pages de catégories ?
Il n'est généralement pas recommandé de ne pas indexer les pages de catégorie, sauf si vous êtes une organisation au niveau de l'entreprise qui crée des pages de catégorie par programme en fonction de recherches ou de balises générées par l'utilisateur et que le contenu dupliqué devient difficile à manier.
Dans la plupart des cas, si vous balisez votre contenu intelligemment, de manière à aider les utilisateurs à mieux naviguer sur votre site et à trouver ce dont ils ont besoin, tout ira bien.
En fait, les pages de catégorie peuvent être des mines d'or pour le référencement car elles affichent généralement une profondeur de contenu sous les sujets de catégorie.
Jetez un œil à cette analyse que nous avons effectuée en décembre 2018 pour quantifier la valeur des pages de catégorie pour une poignée de publications en ligne.
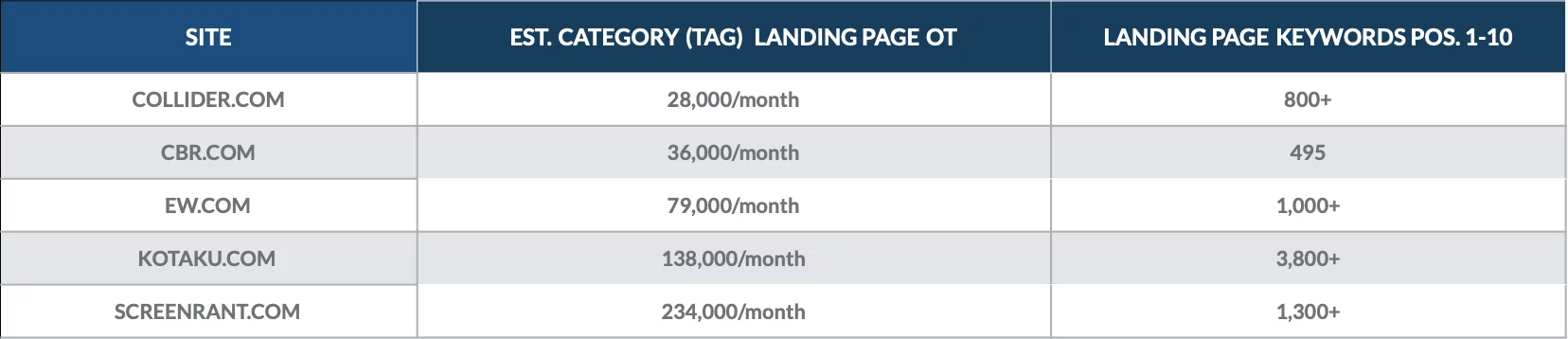
Nous avons constaté que les pages de destination de la catégorie étaient classées pour des centaines de mots-clés de la page 1 et attiraient des milliers de visiteurs organiques chaque mois.
Les pages de catégorie les plus précieuses pour chaque site ont souvent attiré chacune des milliers de visiteurs organiques.
Jetez un œil à EW.com ci-dessous, nous avons mesuré le trafic vers chaque page (représenté par la taille du cercle) et la valeur du trafic vers chaque page (représentée par la couleur du cercle).
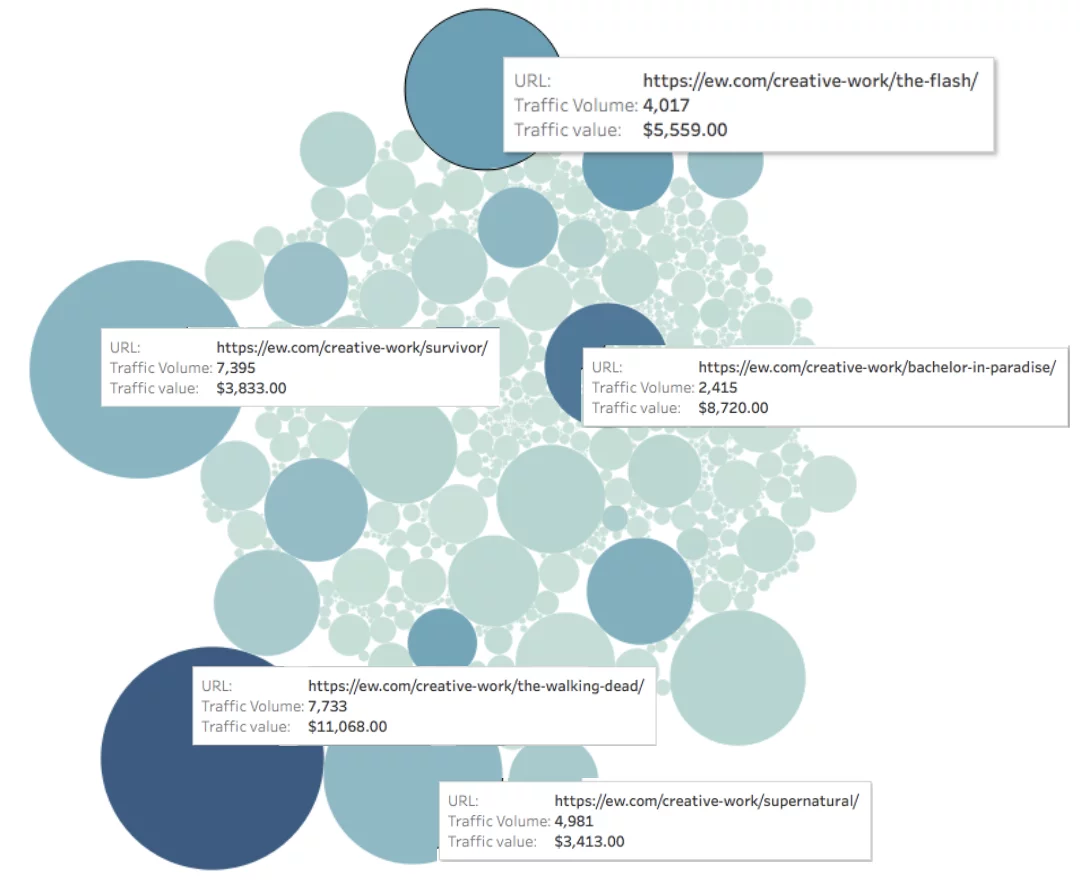
Valeur organique mensuelle de la page = profondeur de couleur
Imaginez maintenant les mêmes graphiques, mais pour des sites basés sur des produits où les visiteurs sont susceptibles de faire des achats actifs.
Cela étant dit, si vos catégories sont suffisamment similaires pour semer la confusion chez les utilisateurs ou se faire concurrence dans la recherche, vous devrez peut-être apporter une modification :
- Si vous définissez vous-même les catégories, nous vous recommandons de migrer le contenu d'une catégorie à l'autre et de réduire le nombre total de catégories que vous avez dans l'ensemble.
- Si vous autorisez les utilisateurs à créer des catégories, vous souhaiterez peut-être ne pas indexer les pages de catégories générées par les utilisateurs, au moins jusqu'à ce que les nouvelles catégories aient subi un processus de révision.
Comment puis-je empêcher Google d'indexer les sous-domaines ?
Il existe quelques options pour empêcher Google d'indexer les sous-domaines :
- Vous pouvez ajouter un mot de passe en utilisant un fichier .htpasswd
- Vous pouvez interdire les crawlers avec un fichier robots.txt
- Vous pouvez ajouter une directive noindex à chaque page du sous-domaine
- Vous pouvez 404 toutes les pages de sous-domaine
Ajout d'un mot de passe pour bloquer l'indexation
Si vos sous-domaines sont à des fins de développement, ajouter un fichier .htpasswd au répertoire racine de votre sous-domaine est l'option idéale. Le mur de connexion empêchera les crawlers d'indexer le contenu sur le sous-domaine et empêchera l'accès des utilisateurs non autorisés.
Exemples de cas d'utilisation :
- Dev.domain.com
- Staging.domain.com
- Testing.domain.com
- QA.domaine.com
- UAT.domaine.com
Utilisation de robots.txt pour bloquer l'indexation
Si vos sous-domaines servent à d'autres fins, vous pouvez ajouter un fichier robots.txt au répertoire racine de votre sous-domaine. Il devrait alors être accessible comme suit :
https://subdomain.domain.com/robots.txt
Vous devrez ajouter un fichier robots.txt à chaque sous-domaine que vous essayez de bloquer de la recherche. Exemple:
https://help.domain.com/robots.txt
https://domainepublic.com/robots.txt
Dans chaque cas, le fichier robots.txt doit interdire les crawlers. Pour bloquer la plupart des crawlers avec une seule commande, utilisez le code suivant :
Agent utilisateur: *
Interdire : /
L'astérisque * après user-agent : est appelé un caractère générique, il correspondra à n'importe quelle séquence de caractères. L'utilisation d'un caractère générique enverra la directive d'interdiction suivante à tous les agents utilisateurs, quel que soit leur nom, de googlebot à yandex.
La barre oblique inverse indique au robot d'exploration que toutes les pages hors du sous-domaine sont incluses dans la directive d'interdiction.
Comment bloquer sélectivement l'indexation des pages de sous-domaine
Si vous souhaitez que certaines pages d'un sous-domaine apparaissent dans la recherche, mais pas d'autres, vous avez deux options :
- Utiliser les directives noindex au niveau de la page
- Utiliser les directives d'interdiction au niveau du dossier ou du répertoire
Les directives noindex au niveau de la page seront plus lourdes à mettre en œuvre, car la directive doit être ajoutée au code HTML ou à l'en-tête de chaque page. Cependant, les directives noindex empêcheront Google d'indexer un sous-domaine, que le sous-domaine ait déjà été indexé ou non.
Les directives d'interdiction au niveau du répertoire sont plus faciles à mettre en œuvre, mais ne fonctionneront que si les pages de sous-domaine ne figurent pas déjà dans l'index de recherche. Mettez simplement à jour le fichier robots.txt du sous-domaine pour interdire l'exploration des répertoires ou sous-dossiers applicables.
Comment savoir si mes pages ne sont pas indexées ?
L'ajout accidentel de pages de directive sans index sur votre site peut avoir des conséquences dramatiques pour votre classement de recherche et votre visibilité de recherche.
Si vous trouvez qu'une page ne voit pas de trafic organique malgré un bon contenu et des backlinks, vérifiez d'abord que vous n'avez pas accidentellement interdit les robots d'exploration de votre fichier robots.txt. Si cela ne résout pas votre problème, vous devrez vérifier les pages individuelles pour les directives noindex.
Vérification de NoIndex sur les pages WordPress
WordPress facilite l'ajout ou la suppression de cette balise sur vos pages. La première étape de la vérification du nofollow sur vos pages consiste simplement à basculer le paramètre Visibilité du moteur de recherche dans l'onglet "Lecture" du menu "Paramètres".
Cela résoudra probablement le problème, mais ce paramètre fonctionne comme une "suggestion" plutôt qu'une règle, et une partie de votre contenu peut finir par être indexée de toute façon.
Afin d'assurer une confidentialité absolue pour vos fichiers et votre contenu, vous devrez franchir une dernière étape soit en protégeant votre site par mot de passe en utilisant soit les outils de gestion cPanel, si disponibles, soit via un simple plugin.
De même, la suppression de cette balise de votre contenu peut être effectuée en supprimant la protection par mot de passe et en décochant le paramètre de visibilité.
Vérifier NoIndex sur Squarespace
Les pages Squarespace sont également facilement NoIndexées grâce à la capacité d'injection de code de la plateforme. Comme WordPress, Squarespace peut facilement être bloqué des recherches de routine à l'aide d'une protection par mot de passe, mais la plate-forme déconseille également de prendre cette mesure pour protéger l'intégrité de votre contenu.
En ajoutant la ligne de code NoIndex dans chaque page que vous souhaitez masquer des moteurs de recherche Internet et à chaque sous-page en dessous, vous pouvez garantir la sécurité du contenu sécurisé qui doit être interdit d'accès au public. Comme d'autres plates-formes, la suppression de cette balise est également assez simple : il vous suffit d'utiliser la fonction d'injection de code pour retirer le code.
Squarespace est unique en ce sens que ses concurrents proposent cette option principalement dans le cadre de la suite de paramètres des outils de gestion de pages. Squarespace part ici, permettant une manipulation personnelle du code. Ceci est intéressant car vous pouvez voir le changement que vous apportez au contenu de votre page, contrairement aux autres dans cet espace.
Vérifier NoIndex sur Wix
Wix permet également une solution simple et rapide aux problèmes de NoIndexing. Dans les paramètres "Menus & Pages", vous pouvez simplement désactiver l'option "Afficher cette page dans les résultats de recherche" si vous souhaitez NoIndexer une seule page de votre site.
Comme avec ses concurrents, Wix suggère également un mot de passe protégeant vos pages ou l'ensemble du site pour plus de confidentialité. Cependant, Wix se démarque des autres en ce que l'équipe de support ne prescrit pas d'action parallèle sur les deux fronts afin de sécuriser le contenu du crawler. Wix fait une remarque particulière sur la différence entre masquer une page de votre menu et la masquer des critères de recherche.
Il s'agit d'un conseil particulièrement utile pour les créateurs de sites Web moins expérimentés qui ne comprennent peut-être pas initialement la différence étant donné que la suppression du menu de votre site rend la page inaccessible à partir du site, mais pas à partir d'un terme de recherche Google prudent.