
Modélisation de sujets avec Word2Vec
Publié: 2022-05-02Un mot est défini par la compagnie qu'il garde. C'est la prémisse derrière Word2Vec, une méthode de conversion des mots en nombres et de les représenter dans un espace multidimensionnel. Des mots fréquemment retrouvés rapprochés dans un ensemble de documents (corpus) apparaîtront également rapprochés dans cet espace. On dit qu'ils sont liés contextuellement.
Word2Vec est une méthode de machine learning qui nécessite un corpus et une formation adéquate. La qualité des deux affecte sa capacité à modéliser un sujet avec précision. Toute lacune devient évidente lors de l'examen des résultats pour des sujets très spécifiques et compliqués, car ce sont les plus difficiles à modéliser avec précision. Word2Vec peut être utilisé seul, bien qu'il soit fréquemment combiné avec d'autres techniques de modélisation pour pallier ses limites.
Le reste de cet article fournit des informations supplémentaires sur Word2Vec, son fonctionnement, son utilisation dans la modélisation de sujets et certains des défis qu'il présente.
Qu'est-ce que Word2Vec ?
En septembre 2013, les chercheurs de Google, Tomas Mikolov, Kai Chen, Greg Corrado et Jeffrey Dean, ont publié l'article «Efficient Estimation of Word Representations in Vector Space» (pdf). C'est ce que nous appelons maintenant Word2Vec. L'objectif de l'article était "d'introduire des techniques qui peuvent être utilisées pour apprendre des vecteurs de mots de haute qualité à partir d'énormes ensembles de données avec des milliards de mots et avec des millions de mots dans le vocabulaire".
Auparavant, toutes les techniques de traitement du langage naturel traitaient les mots comme des unités singulières. Ils n'ont tenu compte d'aucune similitude entre les mots. Bien qu'il y ait eu des raisons valables pour cette approche, elle avait ses limites. Il y avait des situations dans lesquelles la mise à l'échelle de ces techniques de base ne pouvait pas offrir d'amélioration significative. D'où la nécessité de développer des technologies avancées.
L'article a montré que des modèles simples, avec leurs exigences de calcul moindres, pouvaient former des vecteurs de mots de haute qualité. Comme le conclut l'article, il est "possible de calculer des vecteurs de mots de grande dimension très précis à partir d'un ensemble de données beaucoup plus vaste". Ils parlent de collections de documents (corpus) avec un trillion de mots fournissant une taille pratiquement illimitée du vocabulaire.
Word2Vec est un moyen de convertir des mots en nombres, dans ce cas des vecteurs, afin que des similitudes puissent être découvertes mathématiquement. L'idée est que les vecteurs de mots similaires sont regroupés dans l'espace vectoriel.
Pensez aux coordonnées latitudinales et longitudinales sur une carte. À l'aide de ce vecteur bidimensionnel, vous pouvez déterminer rapidement si deux emplacements sont relativement proches l'un de l'autre. Pour que les mots soient convenablement représentés dans un espace vectoriel, deux dimensions ne suffisent pas. Ainsi, les vecteurs doivent incorporer de nombreuses dimensions.
Comment fonctionne Word2Vec ?
Word2Vec prend en entrée un grand corpus de texte et le vectorise à l'aide d'un réseau neuronal peu profond. La sortie est une liste de mots (vocabulaire), chacun avec un vecteur correspondant. Des mots ayant une signification similaire apparaissent dans l'espace à proximité. Mathématiquement, cela est mesuré par la similarité cosinus, où la similarité totale est exprimée sous la forme d'un angle de 0 degré alors qu'aucune similarité n'est exprimée sous la forme d'un angle de 90 degrés.
Les mots peuvent être encodés sous forme de vecteurs à l'aide de différents types de modèles. Dans leur article, Mikolov et al. a examiné deux modèles existants, le modèle de langage de réseau neuronal à action directe (NNLM) et le modèle de langage de réseau neuronal récurrent (RNNLM). De plus, ils proposent deux nouveaux modèles log-linéaires, le sac de mots continu (CBOW) et le Skip-gram continu.
Dans leurs comparaisons, CBOW et Skip-gram ont obtenu de meilleurs résultats, examinons donc ces deux modèles.
CBOW est similaire à NNLM et s'appuie sur le contexte pour déterminer un mot cible. Il détermine le mot cible en fonction des mots qui le précèdent et le suivent. Mikolov a trouvé que la meilleure performance s'est produite avec quatre mots futurs et quatre mots historiques. C'est ce qu'on appelle 'sac de mots' parce que l'ordre des mots dans l'histoire n'influence pas la sortie. «Continu» dans le terme CBOW fait référence à son utilisation de «représentation distribuée continue du contexte».
Skip-gram est l'inverse de CBOW. Étant donné un mot, il prédit les mots environnants dans une plage spécifique. Une plus grande plage fournit des vecteurs de mots de meilleure qualité mais augmente la complexité de calcul. Moins de poids est donné aux termes éloignés car ils sont généralement moins liés au mot courant.
En comparant CBOW à Skip-gram, ce dernier s'est avéré offrir des résultats de meilleure qualité sur de grands ensembles de données. Bien que CBOW soit plus rapide, Skip-gram gère mieux les mots rarement utilisés.
Lors de l'apprentissage, un vecteur est attribué à chaque mot. Les composants de ce vecteur sont ajustés de sorte que des mots similaires (en fonction de leur contexte) soient plus proches les uns des autres. Considérez cela comme un bras de fer, où les mots sont poussés et tirés dans ce vecteur multidimensionnel chaque fois qu'un autre terme est ajouté à l'espace.
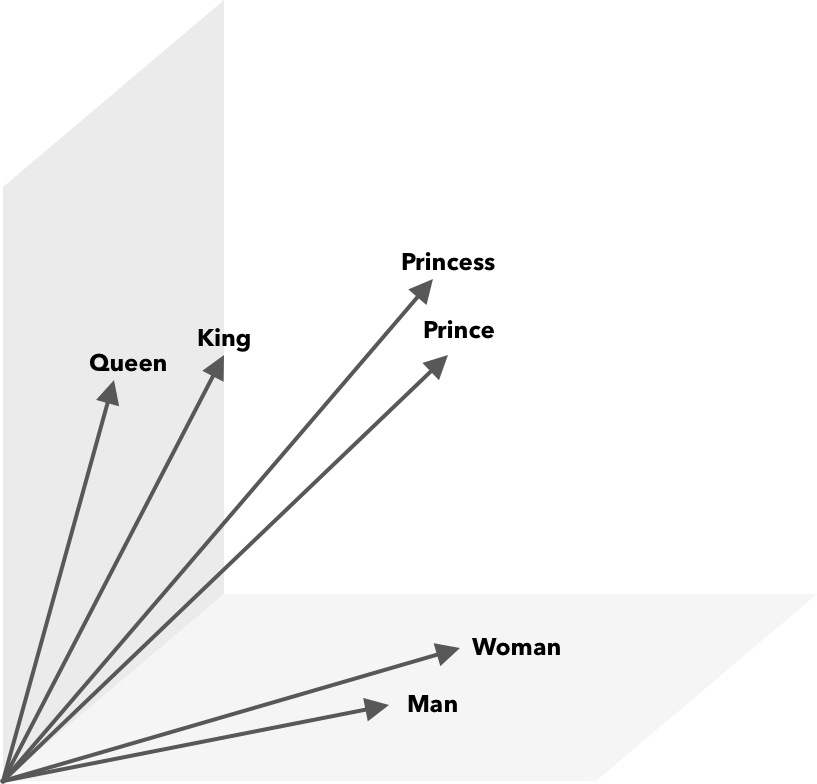
Des opérations mathématiques, en plus de la similarité cosinus, peuvent être effectuées sur des vecteurs de mots. Par exemple, le vecteur ("Roi") - vecteur ("Homme") + vecteur ("Femme") donne un vecteur le plus proche de celui représentant le mot Reine.

Word2Vec pour la modélisation de sujet
Le vocabulaire créé par Word2Vec peut être interrogé directement pour détecter les relations entre les mots ou alimenté dans un réseau neuronal d'apprentissage en profondeur. Un problème avec les algorithmes Word2Vec comme CBOW et Skip-gram est qu'ils pondèrent chaque mot de manière égale. Le problème qui se pose lorsque l'on travaille avec des documents est que les mots ne représentent pas de la même manière le sens d'une phrase.
Certains mots sont plus importants que d'autres. Ainsi, différentes stratégies de pondération, telles que TF-IDF, sont souvent utilisées pour faire face à la situation. Cela aide également à résoudre le problème de hubness mentionné dans la section suivante. Searchmetrics ContentExperience utilise une combinaison de TF-IDF et Word2Vec, que vous pouvez lire ici dans notre comparaison avec MarketMuse.
Alors que les incorporations de mots comme Word2Vec capturent des informations morphologiques, sémantiques et syntaxiques, la modélisation de sujets vise à découvrir des structures sémantiques latentes ou des sujets dans un corpus.
Selon Budhkar et Rudzicz (PDF), la combinaison de l'allocation Dirichlet latente (LDA) avec Word2Vec peut produire des caractéristiques discriminantes pour "résoudre le problème causé par l'absence d'informations contextuelles intégrées dans ces modèles". Une lecture plus facile sur LDA2vec peut être trouvée dans ce tutoriel DataCamp.
Défis de Word2Vec
Il existe plusieurs problèmes avec les incorporations de mots en général, y compris Word2Vec. Nous aborderons certains d'entre eux, pour une analyse plus détaillée, reportez-vous à 'A Survey of Word Embedding Evaluation Methods' (pdf) par Amir Bakarov. Le corpus et sa taille, ainsi que la formation elle-même, auront un impact significatif sur la qualité de la sortie.
Comment évaluez-vous la sortie ?
Comme Bakarov l'explique dans son article, un ingénieur NLP évaluera généralement les performances des intégrations différemment d'un linguiste informatique ou d'un spécialiste du marketing de contenu. Voici quelques problèmes supplémentaires cités dans le document.
- La sémantique est une idée vague. Une « bonne » incorporation de mots reflète notre notion de sémantique. Cependant, nous pouvons ne pas savoir si notre compréhension est correcte. De plus, les mots ont différents types de relations comme la relation sémantique et la similitude sémantique. Quel type de relation le mot incorporation doit-il refléter ?
- Manque de données de formation appropriées. Lors de la formation des incorporations de mots, les chercheurs augmentent fréquemment leur qualité en les ajustant aux données. C'est ce que nous appelons l'ajustement de courbe. Au lieu de faire correspondre le résultat aux données, les chercheurs devraient essayer de saisir les relations entre les mots.
- L'absence de corrélation entre les méthodes intrinsèques et extrinsèques signifie qu'il n'est pas clair quelle classe de méthode est préférée. L'évaluation extrinsèque détermine la qualité de sortie à utiliser plus en aval dans d'autres tâches de traitement du langage naturel. L'évaluation intrinsèque repose sur le jugement humain des relations entre les mots.
- Le problème du hubness. Les hubs, vecteurs de mots représentant des mots courants, sont proches d'un nombre excessif d'autres vecteurs de mots. Ce bruit peut biaiser l'évaluation.
De plus, il y a deux défis importants avec Word2Vec en particulier.
- Il ne peut pas très bien gérer les ambiguïtés. De ce fait, le vecteur d'un mot à sens multiples reflète la moyenne, ce qui est loin d'être idéal.
- Word2Vec ne peut pas gérer les mots hors vocabulaire (OOV) et les mots morphologiquement similaires. Lorsque le modèle rencontre un nouveau concept, il recourt à l'utilisation d'un vecteur aléatoire, qui n'est pas une représentation précise.
Résumé
L'utilisation de Word2Vec ou de tout autre intégration de mots n'est pas une garantie de succès. Une production de qualité repose sur une formation appropriée utilisant un corpus approprié et suffisamment large.
Bien que l'évaluation de la qualité de la sortie puisse être fastidieuse, voici une solution simple pour les spécialistes du marketing de contenu. La prochaine fois que vous évaluerez un optimiseur de contenu, essayez d'utiliser un sujet très spécifique. Les modèles de sujet de mauvaise qualité échouent lorsqu'il s'agit de tester de cette manière. Ils sont acceptables pour les termes généraux, mais se décomposent lorsque la demande devient trop spécifique.
Donc, si vous utilisez le sujet "comment faire pousser des avocats", assurez-vous que les suggestions ont quelque chose à voir avec la culture de la plante et non avec les avocats en général.
La génération de langage naturel MarketMuse NLG Technology a aidé à créer cet article.
Ce que tu dois faire maintenant
Lorsque vous êtes prêt… voici 3 façons dont nous pouvons vous aider à publier un meilleur contenu, plus rapidement :
- Réservez du temps avec MarketMuse Planifiez une démonstration en direct avec l'un de nos stratèges pour voir comment MarketMuse peut aider votre équipe à atteindre ses objectifs de contenu.
- Si vous souhaitez apprendre à créer un meilleur contenu plus rapidement, visitez notre blog. Il regorge de ressources pour vous aider à faire évoluer le contenu.
- Si vous connaissez un autre spécialiste du marketing qui aimerait lire cette page, partagez-la avec lui par e-mail, LinkedIn, Twitter ou Facebook.