
Quels sont les types de Big Data : caractéristiques et définition
Publié: 2023-10-06Résumé : Les mégadonnées comprennent quatre types nommés données structurées, non structurées, semi-structurées et quasi-structurées. Découvrons chaque type de Big Data en détail ci-dessous !
La plupart des organisations s'appuient sur des ensembles de données pour obtenir des informations et en savoir plus sur leurs clients, leur secteur et leur entreprise. Cependant, lorsque la taille des données augmente, il devient difficile de les gérer et de les traiter.
Ces ensembles de données sont appelés ensembles de données volumineuses qui contiennent une plus grande variété de données et sont de nature énorme. Le Big Data peut se présenter sous plusieurs formes : structurées, non structurées, semi-structurées et quasi-structurées.
Apprenons-en davantage sur les différents types d'ensembles de Big Data dans l'article ci-dessous.
Table des matières
Quels sont les types populaires de Big Data ?
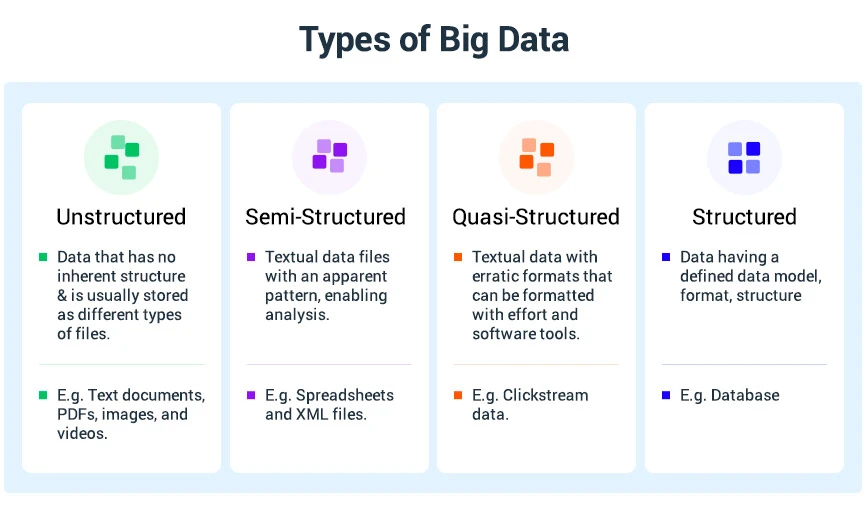
Le Big Data est classé selon les quatre types principaux énumérés ci-dessous :
Données structurées
Les données structurées sont un type de données qui ont un format standardisé et facilement accessible par le logiciel et les personnes. Il se présente généralement sous forme de tableau avec diverses lignes et colonnes qui mettent en évidence les attributs des données.
Les données structurées comprennent des données quantitatives telles que l'âge, le numéro de téléphone, les numéros de carte de crédit, etc. Comme il est de nature quantitative, le logiciel peut facilement le traiter pour obtenir des informations précieuses.
Pour traiter les données de structure, vous n'avez pas besoin de placer les données dans des métriques pertinentes. De plus, les données structurelles n’ont pas besoin d’être converties et interprétées en profondeur pour obtenir des informations précieuses.
Où utiliser le type de données structurées ?
- Gestion des données clients
- Gestion des détails des factures
- Stockage des bases de données de produits
- Enregistrement de la liste de contacts
Avantages et inconvénients des données structurées
- Cela facilite le traitement des données car elles sont stockées dans un format défini.
- Les données sont traitées rapidement par rapport aux données non structurées
- Il se peut qu’il ne soit pas adapté à tous les types d’informations car les données sont stockées dans un format spécifique.
Données non structurées : XML, JSON, YAML

Les données non structurées sont un type de données qui ne se limitent pas à un modèle de données spécifique ni à une structure identifiable pouvant être lue par un programme informatique. Ce type de données n'est pas organisé de manière correctement définie et ne dispose d'aucune séquence ou format pour traiter les données.
Contrairement aux données structurées, ce type de données ne peut pas être stocké sous forme de lignes et de colonnes. Un exemple courant de données non structurées est une base de données hétérogène contenant une combinaison d’images, de vidéos, de fichiers texte, etc.
Où utiliser le type de données non structurées ?
- Gestion des données audio et vidéo
- Gérer les réponses aux enquêtes ouvertes
- Gérer les publications sur les réseaux sociaux
- Gestion des documents commerciaux
Avantages et inconvénients des données non structurées
- Puisqu’il n’y a pas de structure définie, les données peuvent être collectées rapidement.
- Il peut être utilisé pour traiter des sources de données hétérogènes.
- En raison de l’absence de structure ou de schéma, il est plus difficile à gérer.
Données semi-structurées
Les données semi-structurées sont un type de données qui ne sont pas correctement structurées mais en même temps pas entièrement non structurées. Ces données ne respectent pas le schéma rigide et le modèle de données. De plus, il peut également contenir des composants qui ne peuvent pas être facilement catégorisés ou classés.
Les données semi-structurées sont caractérisées par des métadonnées et des balises qui fournissent des informations supplémentaires sur tous les éléments de données. Par exemple, un fichier XML peut contenir des balises indiquant la structure du document et inclure des balises supplémentaires qui fournissent des métadonnées sur le contenu comme la date ou des mots-clés.
Où utiliser le type de données semi-structuré ?
- Analyser des pages Web via HTML
- Utiliser les données des e-mails pour obtenir des informations sur les clients
- Catégoriser et analyser des vidéos et des images
Avantages et inconvénients du type de données semi-structuré
- Le schéma des données peut être modifié.
- Ce type de données peut accueillir des données qui peuvent ne pas correspondre à un schéma prédéfini.
- Les requêtes de données sont moins efficaces que les données structurées.
Données quasi-structurées
Les données quasi-structurées sont un type de données textuelles accompagnées de formats de données erratiques. Ce type de données peut être formaté avec différents outils d'analyse de données. Il inclut des données telles que les données de parcours Web.

Où utiliser le type de données quasi-structurées ?
- Il peut être utilisé pour analyser les données des pages Web
Avantages et inconvénients du type de données quasi-structuré
- Les données peuvent être traitées rapidement.
- Ce type de données peut être rapidement formaté grâce à des outils d’analyse de données.
- Le chargement des données peut prendre du temps.
Quels sont les sous-types de données ?
Il existe plusieurs sous-types de données qui ne sont pas considérés comme du Big Data mais qui sont importants pour l'analyse. L’origine de ces données peut provenir des médias sociaux, de la journalisation opérationnelle, déclenchée par un événement ou géospatiale. Cela peut également provenir de systèmes open source, de données transmises via API et d'appareils perdus ou volés.
Caractéristiques du Big Data
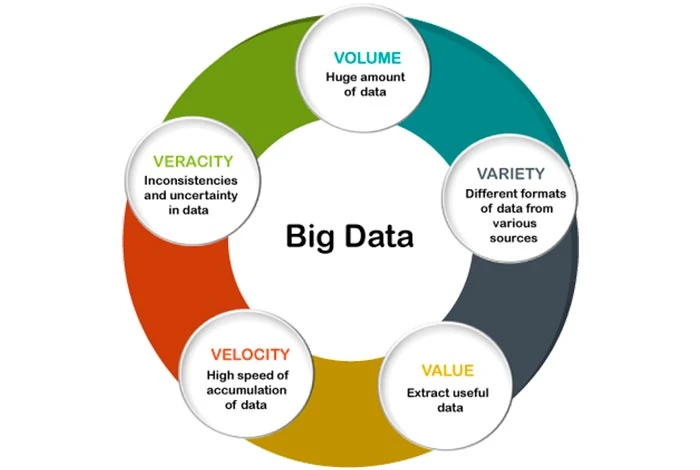
Il existe cinq V qui définissent les caractéristiques du Big Data. Ces caractéristiques sont énumérées ci-dessous :
- Volume : La première caractéristique du big data est le volume. Le Big Data est un vaste « volume » de données collectées à partir de plusieurs sources. Les sources peuvent inclure des procédures commerciales, des plateformes de médias sociaux, des machines, des interactions humaines, etc.
- Véracité : La véracité peut être définie comme la qualité et l’exactitude des données fournies. Les données extraites peuvent contenir certains éléments manquants ou ne pas être en mesure de fournir des informations précieuses. Par conséquent, cette caractéristique est utile pour identifier la qualité des données et obtenir des informations.
- Variété : la variété peut être définie comme la diversité de différents types de données. Les données peuvent être obtenues à partir de plusieurs sources de données dont la valeur peut varier. Les données collectées peuvent être structurées, non structurées ou semi-structurées. La variété des données peut prendre la forme de PDF, d'e-mails, de photos, d'audios, etc.
- Valeur : elle peut être définie comme la valeur que le Big Data peut apporter. Il est important de tirer de la valeur des données collectées pour en tirer des informations précieuses. Les organisations peuvent utiliser les mêmes outils d’analyse Big Data grâce auxquels elles ont collecté des données pour les analyser.
- Vélocité : la vélocité fait référence à la vitesse à laquelle les données sont générées et déplacées. Il s'agit d'un élément important pour les entreprises qui souhaitent que leurs données circulent rapidement afin qu'elles soient disponibles au bon moment pour obtenir des informations. Les données peuvent provenir de diverses sources comme des machines, des smartphones, des réseaux, etc. Une fois les données collectées, elles peuvent être analysées rapidement.
Secteurs utilisant le Big Data au quotidien
Le Big Data peut être utilisé dans de nombreux secteurs, notamment la santé, l’agriculture, l’éducation, la finance, etc. Découvrons en détail ci-dessous l'application du Big Data dans les secteurs suivants :
- Éducation : dans le secteur de l'éducation, les enseignants peuvent analyser les performances des élèves et les taux d'abandon scolaire afin d'optimiser le programme. De plus, cela peut également aider à identifier les domaines d'amélioration en analysant les performances d'un élève.
- Commerce électronique : le secteur du commerce électronique peut utiliser l’analyse du Big Data pour comprendre quelles procédures de votre entreprise fonctionnent bien ou lesquelles doivent être améliorées. De plus, vous pouvez également identifier le type de contenu qui génère l’engagement et quels canaux génèrent le trafic le plus élevé.
- Soins de santé : dans le domaine de la santé, les mégadonnées peuvent être utilisées pour tirer des enseignements de la recherche biomédicale et fournir des recommandations médicales personnalisées aux patients après avoir analysé leurs données. De plus, en surveillant l'état d'un patient en temps réel, ils peuvent envoyer des alertes au personnel médical.
- Gouvernement : le gouvernement peut utiliser le Big Data pour analyser en masse les données des citoyens selon plusieurs paramètres. Par exemple, les mégadonnées du recensement sont analysées pour connaître le nombre de jeunes dans le pays ou la population de chômeurs. Les résultats peuvent les aider à développer des programmes et des plans pour cibler le bon groupe de citoyens.
Lecture suggérée : Les meilleurs outils de Business Intelligence (BI)
Conclusion
Le Big Data a permis aux entreprises de traiter plus facilement des ensembles de données en masse. Lorsque les données sont triées, organisées et analysées en masse, elles peuvent aider les entreprises à obtenir des informations précieuses. De plus en plus d’industries s’appuient sur l’analyse du Big Data pour traiter des données complexes et exploiter l’inférence pour leur avantage concurrentiel.
FAQ relatives aux types de Big Data
Qu’est-ce que le Big Data et quel type de Big Data ?
Le Big Data est un type de données plus variées, plus volumineuses et plus rapides. Les types de Big Data comprennent les données structurées, non structurées et semi-structurées.
Quels sont les trois types de classification Big Data ?
Les trois types de classification Big Data sont les données structurées, non structurées et semi-structurées.
Quelles sont les 4 composantes du Big Data ?
Les quatre composantes principales du Big Data sont le volume, la vélocité, la variété et la véracité.
Quelles sont les 6 caractéristiques du Big Data ?
Le Big Data présente les caractéristiques suivantes qui aident à analyser les données : volume, variété, véracité, variabilité, vitesse et valeur.
Quelles sont les sources du big data ?
Les principales sources de Big Data pourraient être regroupées en réseaux sociaux, machines et transactionnels. Les sources sociales sont les sources de Big Data les plus utilisées par l’organisation. Il comprend les publications sur les réseaux sociaux, les vidéos publiées, etc.