
Qu'est-ce que le crawl budget et comment l'optimiser intelligemment ?
Publié: 2021-08-19Table des matières
L'analyse du budget de crawl fait partie des tâches de tout expert en référencement (en particulier s'il s'agit de grands sites Web). Une tâche importante, convenablement couverte dans les documents fournis par Google. Pourtant, comme vous pouvez le voir sur Twitter, même les employés de Google minimisent le rôle du budget de crawl dans l'amélioration du trafic et des classements :

Ont-ils raison sur celui-ci ?
Comment Google fonctionne-t-il et collecte-t-il des données ?
En abordant le sujet, rappelons comment le moteur de recherche collecte, indexe et organise les informations. Garder ces trois étapes dans un coin de votre esprit est essentiel lors de vos travaux ultérieurs sur le site Web :
Étape 1 : Explorer . Parcourir les ressources en ligne dans le but de découvrir – et de parcourir – tous les liens, fichiers et données existants. En règle générale, Google commence par les endroits les plus populaires sur le Web, puis procède à l'analyse d'autres ressources moins tendance.
Étape 2 : Indexation . Google essaie de déterminer de quoi traite la page et si le contenu/document analysé constitue un élément unique ou en double. A ce stade, Google regroupe les contenus et établit un ordre d'importance (en lisant les suggestions dans les balises rel=”canonical” ou rel=”alternate” ou autre).
Étape 3 : Servir . Une fois segmentées et indexées, les données sont affichées en réponse aux requêtes des utilisateurs. C'est également à ce moment que Google trie les données de manière appropriée, en tenant compte de facteurs tels que l'emplacement de l'utilisateur.
Important : de nombreux matériaux disponibles négligent l'étape 4 : rendu du contenu . Par défaut, Googlebot indexe le contenu textuel. Cependant, à mesure que les technologies Web continuent d'évoluer, Google a dû concevoir de nouvelles solutions pour cesser de simplement « lire » et commencer à « voir » également. C'est de cela qu'il s'agit. Il sert à Google à améliorer considérablement sa portée parmi les sites Web nouvellement lancés et à élargir l'index.
Remarque : des problèmes de rendu de contenu peuvent être à l'origine d'un budget de crawl défaillant.
Quel est le budget de crawl ?
Le budget de crawl n'est rien d'autre que la fréquence à laquelle les robots et les robots des moteurs de recherche peuvent indexer votre site Web, ainsi que le nombre total d'URL auxquelles ils peuvent accéder en un seul crawl. Imaginez votre budget de crawl comme des crédits que vous pouvez dépenser dans un service ou une application. Si vous ne pensez pas à « facturer » votre budget de crawl, le robot ralentira et vous rendra moins de visites.
Dans le référencement, la "facturation" fait référence au travail effectué pour acquérir des backlinks ou améliorer la popularité globale d'un site Web. Par conséquent, le budget de crawl fait partie intégrante de tout l'écosystème du Web. Lorsque vous faites du bon travail sur le contenu et les backlinks, vous augmentez la limite de votre budget de crawl disponible.
Dans ses ressources, Google ne s'aventure pas à définir explicitement le budget de crawl. Au lieu de cela, il pointe vers deux composants fondamentaux de l'exploration qui affectent la minutie de Googlebot et la fréquence de ses visites :
- limite de vitesse d'exploration ;
- demande d'exploration.
Quelle est la limite de vitesse de crawl et comment la vérifier ?
En termes simples, la limite de vitesse d'exploration correspond au nombre de connexions simultanées que Googlebot peut établir lors de l'exploration de votre site. Parce que Google ne veut pas nuire à l'expérience utilisateur, il limite le nombre de connexions pour maintenir des performances fluides de votre site Web/serveur. En bref, plus votre site Web est lent, plus votre limite de vitesse de crawl est petite.
Important : la limite d'exploration dépend également de la santé globale du référencement de votre site Web - si votre site déclenche de nombreuses redirections, des erreurs 404/410 ou si le serveur renvoie souvent un code d'état 500, le nombre de connexions diminuera également.
Vous pouvez analyser les données de limite de vitesse d'exploration avec les informations disponibles dans Google Search Console, dans le rapport Crawl Stats .
Demande de crawl ou popularité du site Web
Alors que la limite de vitesse de crawl vous oblige à peaufiner les détails techniques de votre site Web, la demande de crawl vous récompense pour la popularité de votre site Web. En gros, plus le buzz autour de votre site Web (et sur celui-ci) est important, plus sa demande de crawl est importante.
Dans ce cas, Google fait le point sur deux problèmes :
- Popularité globale - Google est plus désireux d'exécuter des analyses fréquentes des URL qui sont généralement populaires sur Internet (pas nécessairement celles avec des backlinks du plus grand nombre d'URL).
- Fraîcheur des données d'index – Google s'efforce de ne présenter que les informations les plus récentes. Important : Créer de plus en plus de nouveaux contenus ne signifie pas que votre limite de budget d'exploration globale augmente.
Facteurs affectant le budget de crawl
Dans la section précédente, nous avons défini le budget de crawl comme une combinaison de la limite de taux de crawl et de la demande de crawl. Gardez à l'esprit que vous devez vous occuper des deux, simultanément, pour assurer une bonne exploration (et donc une indexation) de votre site Web.
Vous trouverez ci-dessous une liste simple de points à prendre en compte lors de l'optimisation du budget de crawl
- Serveur - le principal problème est la performance. Plus votre vitesse est faible, plus le risque que Google affecte moins de ressources à l'indexation de votre nouveau contenu est élevé.
- Codes de réponse du serveur - plus le nombre de redirections 301 et d'erreurs 404/410 sur votre site Web est élevé, plus les résultats d'indexation que vous obtiendrez seront mauvais. Important : Soyez à l'affût des boucles de redirection – chaque « saut » réduit la limite de vitesse d'exploration de votre site Web pour la prochaine visite du bot.
- Blocages dans robots.txt - si vous basez vos directives robots.txt sur l'intuition, vous risquez de créer des goulots d'étranglement d'indexation. Le résultat : vous nettoyerez l'index, mais au détriment de l'efficacité de votre indexation pour les nouvelles pages (lorsque les URL bloquées étaient fermement intégrées dans la structure de l'ensemble du site Web).
- Navigation à facettes / identifiants de session / tous les paramètres dans les URL - surtout, faites attention aux situations où une adresse avec un paramètre peut être paramétrée davantage, sans aucune restriction en place. Si cela devait se produire, Google atteindrait un nombre infini d'adresses, dépensant toutes les ressources disponibles sur les parties les moins importantes de notre site Web.
- Contenu dupliqué - le contenu copié (en dehors de la cannibalisation) nuit considérablement à l'efficacité de l'indexation du nouveau contenu.
- Contenu fin - qui se produit lorsqu'une page a un rapport texte/HTML très faible. En conséquence, Google peut identifier la page comme une soi-disant Soft 404 et restreindre l'indexation de son contenu (même lorsque le contenu est significatif, ce qui peut être le cas, par exemple, sur la page d'un fabricant présentant un seul produit et aucun produit unique contenu du texte).
- Mauvaise liaison interne ou absence de celle-ci .
Outils utiles pour l'analyse du budget de crawl
Puisqu'il n'y a pas de référence pour le budget de crawl (ce qui signifie qu'il est difficile de comparer les limites entre les sites Web), équipez-vous d'un ensemble d'outils conçus pour faciliter la collecte et l'analyse des données.
Console de recherche Google
GSC a bien grandi au fil des ans. Lors d'une analyse du budget de crawl, il y a deux rapports principaux que nous devrions examiner : la couverture de l'index et les statistiques de crawl.
Couverture de l'indice dans GSC
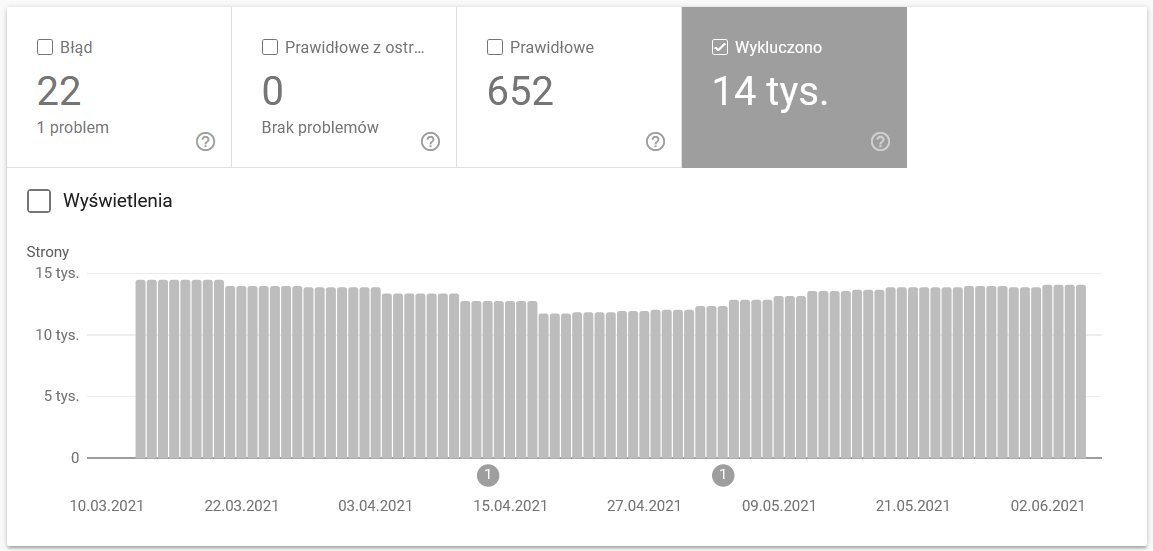
Le rapport est une source de données massive. Vérifions les informations sur les URL exclues de l'indexation. C'est un excellent moyen de comprendre l'ampleur du problème auquel vous êtes confronté.
L'ensemble des rapports mérite un article séparé, donc pour l'instant, concentrons-nous sur les informations suivantes :
- Exclus par la balise 'noindex' - En général, plus de pages sans index signifient moins de trafic. Ce qui soulève la question - quel est l'intérêt de les garder sur le site Web ? Comment restreindre l'accès à ces pages ?
- Crawled - actuellement non indexé - si vous voyez cela, vérifiez si le contenu s'affiche correctement aux yeux de Googlebot. N'oubliez pas que chaque URL avec ce statut gaspille votre budget de crawl car elle ne génère pas de trafic organique.
- Découvert - actuellement non indexé - l'un des problèmes les plus alarmants qui mérite d'être placé en tête de votre liste de priorités.
- Dupliquer sans canonique sélectionné par l'utilisateur - toutes les pages en double sont extrêmement dangereuses car elles nuisent non seulement à votre budget de crawl, mais augmentent également le risque de cannibalisation.
- En double, Google a choisi un canonique différent de celui de l'utilisateur - théoriquement, il n'y a pas lieu de s'inquiéter. Après tout, Google devrait être assez intelligent pour prendre une décision éclairée à notre place. Eh bien, en réalité, Google sélectionne ses canoniques de manière assez aléatoire - coupant souvent des pages précieuses avec un canonique pointant vers la page d'accueil.
- Soft 404 - toutes les erreurs "soft" sont très dangereuses car elles peuvent entraîner la suppression de pages critiques de l'index.
- URL soumise en double non sélectionnée comme canonique - similaire au rapport d'état sur le manque de canoniques sélectionnés par l'utilisateur.
Statistiques d'exploration
Le rapport n'est pas parfait et en ce qui concerne les recommandations, je suggère fortement de jouer également avec les bons vieux journaux de serveur, qui donnent un aperçu plus approfondi des données (et plus d'options de modélisation).
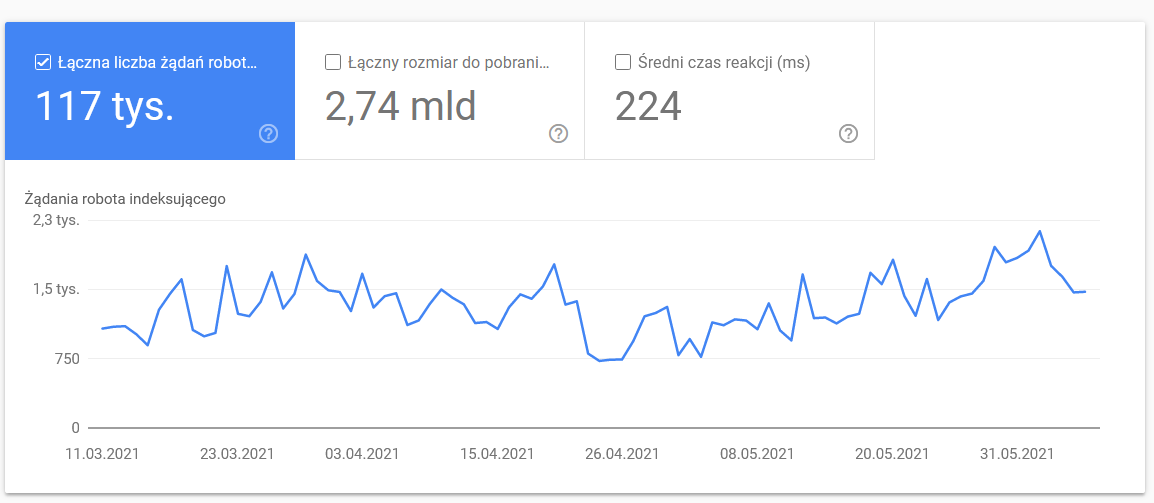
Comme je l'ai déjà dit, vous aurez du mal à chercher des repères pour les chiffres ci-dessus. Cependant, c'est un bon appel à regarder de plus près:
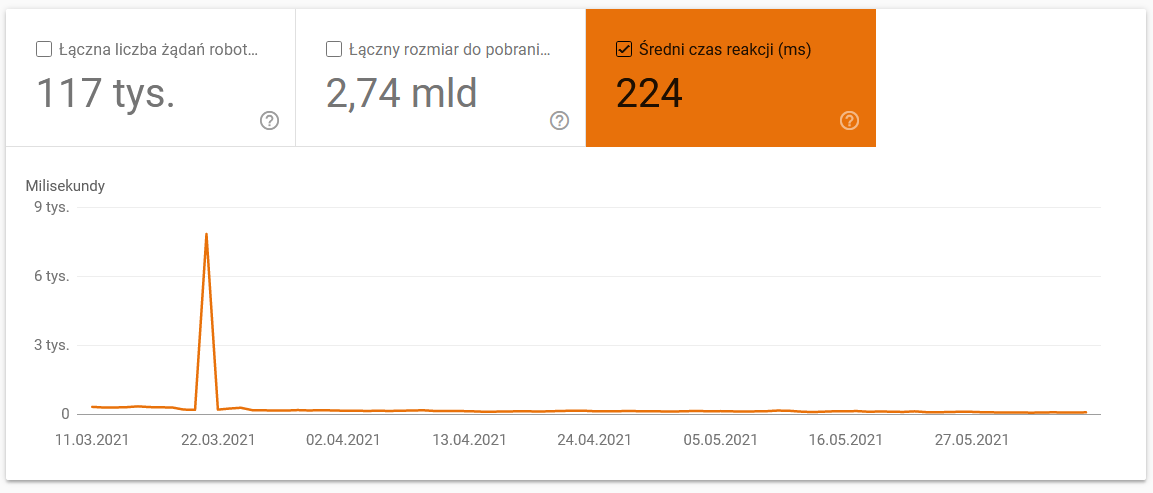
- Temps de téléchargement moyen. La capture d'écran ci-dessous montre que le temps de réponse moyen a pris un coup dramatique, en raison de problèmes liés au serveur :
- Analysez les réponses. Regardez le rapport pour voir, en général, si vous avez un problème avec votre site Web ou non. Portez une attention particulière aux codes d'état de serveur atypiques, comme les 304 ci-dessous. Ces URL ne servent à rien, mais Google gaspille ses ressources à parcourir leur contenu.

- Objectif d'exploration. En général, ces données dépendent largement du volume de nouveaux contenus sur le site Web. Les différences entre les informations recueillies par Google et l'utilisateur peuvent être assez fascinantes :
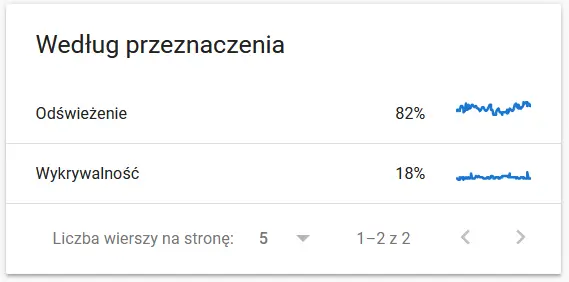
Contenu d'une URL recrawlée aux yeux de Google :
En attendant, voici ce que l'utilisateur voit dans le navigateur :
Certainement une cause de réflexion et d'analyse : )
- Type Googlebot . Ici, vous avez les robots qui visitent votre site Web sur un plateau d'argent, ainsi que leurs motivations pour analyser votre contenu. La capture d'écran ci-dessous montre que 22 % des requêtes font référence à la charge des ressources de la page.
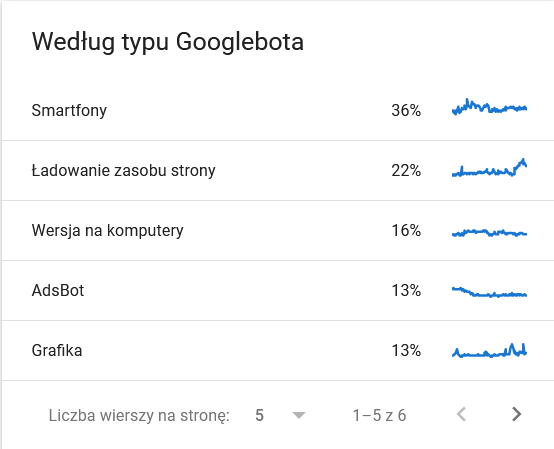
Le total a gonflé dans les derniers jours de la période :
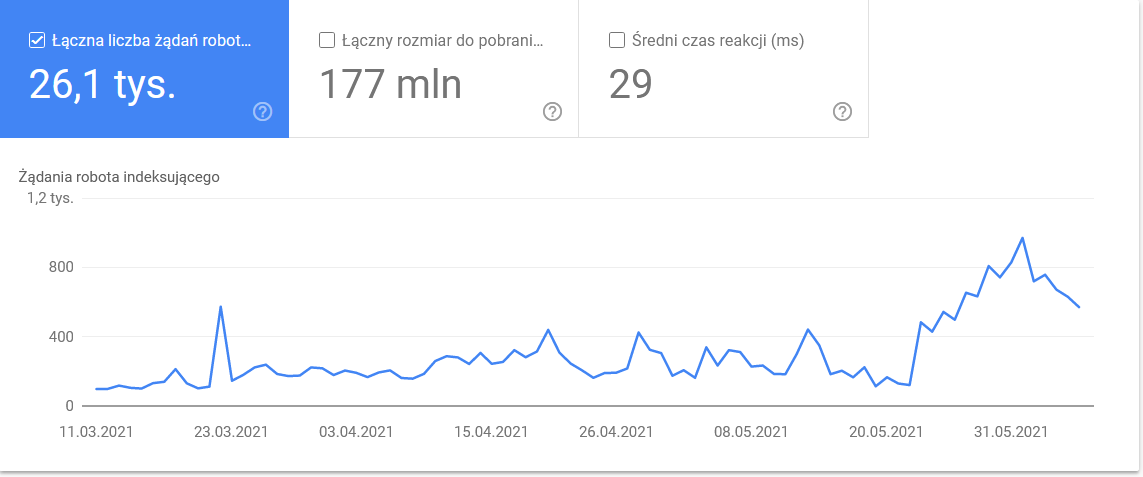
Un coup d'œil aux détails révèle les URL qui nécessitent une attention particulière :
Robots d'exploration externes (avec des exemples de Screaming Frog SEO Spider)
Les robots d'exploration sont parmi les outils les plus importants pour analyser le budget de crawl de votre site Web. Leur objectif principal est d'imiter les mouvements des robots rampants sur le site Web. La simulation vous montre en un coup d'œil si tout se passe bien.
Si vous êtes un apprenant visuel, sachez que la plupart des solutions disponibles sur le marché proposent des visualisations de données.
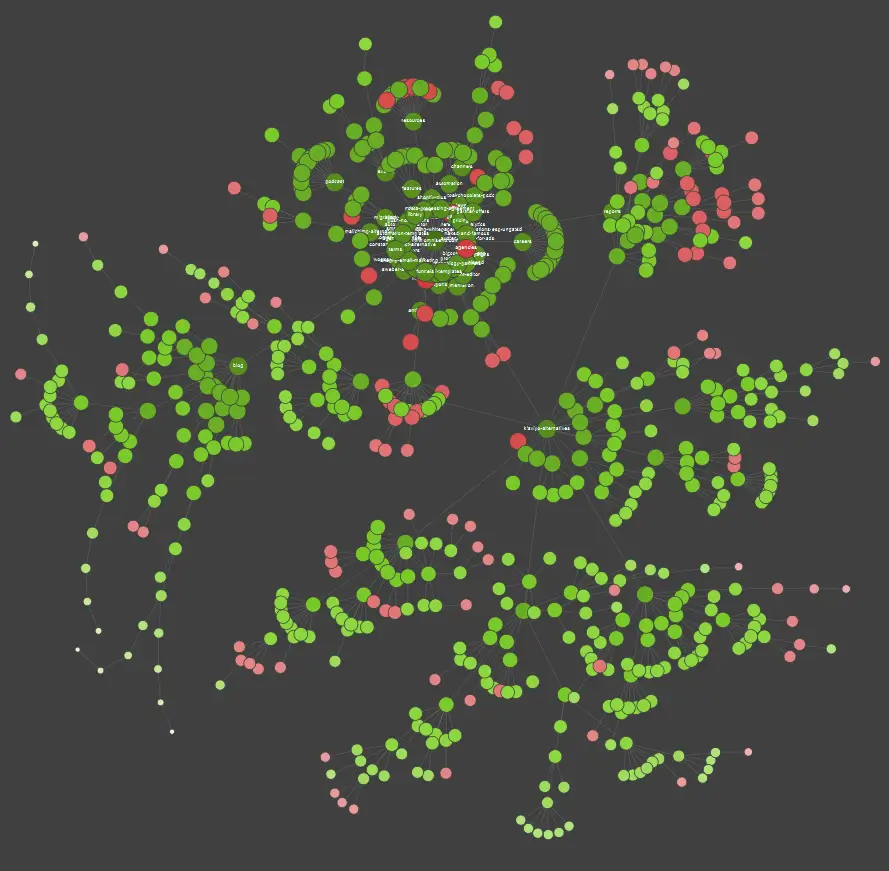
Dans l'exemple ci-dessus, les points rouges représentent les pages non indexées. Prenez le temps de réfléchir à leur utilité et à leur impact sur le fonctionnement du site. Si les journaux du serveur révèlent que ces pages font perdre beaucoup de temps à Google sans ajouter de valeur, il est temps de revoir sérieusement l'intérêt de les conserver sur le site Web.
Important : Si on veut recréer le comportement d'un Googlebot le plus fidèlement possible, les bons réglages sont indispensables. Ici vous pouvez voir des exemples de paramètres de mon ordinateur :
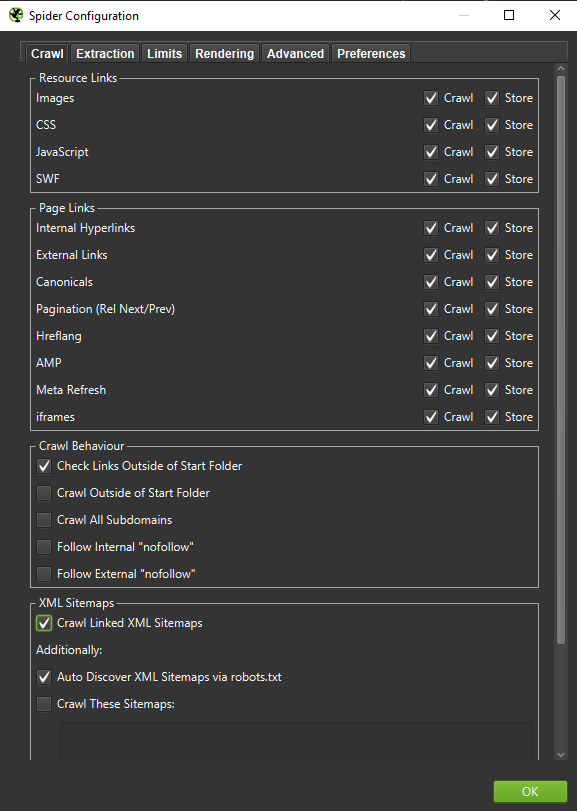
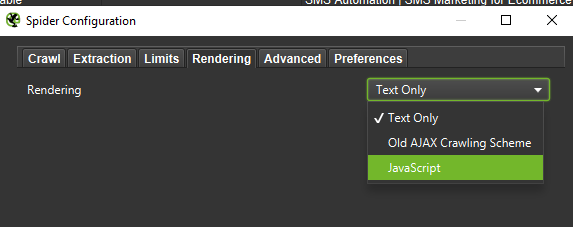
Lors d'une analyse approfondie, il est judicieux de tester deux modes - Texte uniquement, mais aussi JavaScript - pour comparer les différences (le cas échéant).

Enfin, cela ne fait jamais de mal de tester la configuration présentée ci-dessus sur deux agents utilisateurs différents :
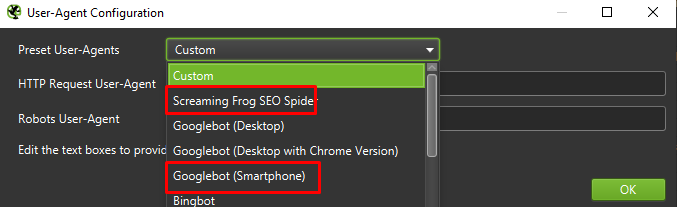
Dans la plupart des cas, vous n'aurez qu'à vous concentrer sur les résultats explorés/rendus par l'agent mobile.
Important : Je suggère également d'utiliser l'opportunité offerte par Screaming Frog et d'alimenter votre robot d'exploration avec les données de GA et de Google Search Console. L'intégration est un moyen rapide d'identifier le gaspillage du budget d'exploration, tel qu'un ensemble substantiel d'URL potentiellement redondantes qui ne reçoivent aucun trafic.
Outils d'analyse de journaux (Screaming Frog Logfile et autres)
Le choix d'un analyseur de journaux de serveur est une question de préférence personnelle. Mon outil de prédilection est l'analyseur de fichiers journaux Screaming Frog. Ce n'est peut-être pas la solution la plus efficace (charger un énorme paquet de journaux = suspendre l'application), mais j'aime l'interface. L'important est de commander au système d'afficher uniquement les Googlebots vérifiés.
Outils de suivi de la visibilité
Une aide utile, car ils vous permettent d'identifier vos pages principales. Si une page est bien classée pour de nombreux mots-clés dans Google (= reçoit beaucoup de trafic), elle peut potentiellement avoir une plus grande demande de crawl (vérifiez-la dans les logs – Google génère-t-il vraiment plus de visites pour cette page particulière ?).
Pour nos besoins, nous aurons besoin de rapports généraux dans Senuto - Chemins et URL - pour un examen continu à l'avenir. Les deux rapports sont disponibles dans l'analyse de visibilité, l'onglet Sections. Regarde:
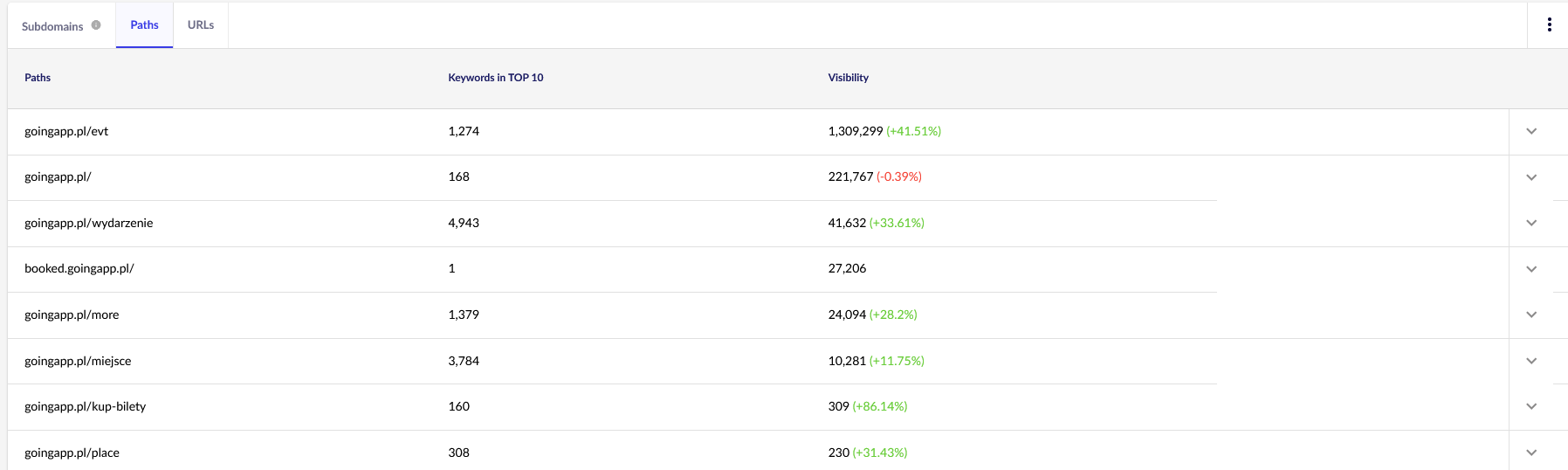
Notre principal point d'intérêt est le deuxième rapport. Trions-le pour examiner la visibilité de nos mots clés (la liste et le nombre total de mots clés pour lesquels notre site Web se classe dans le TOP 10). Les résultats nous serviront à identifier l'axe principal pour la stimulation (et l'allocation efficace) de notre budget de crawl.
Outils d'analyse de backlinks (Ahrefs, Majestic)
Si l'une de vos pages contient une grande quantité de liens entrants, utilisez-la comme pilier de votre stratégie d'optimisation du budget de crawl. Les pages populaires peuvent jouer le rôle de hubs qui transfèrent le jus plus loin. De plus, une page populaire avec un pool décent de liens précieux a de meilleures chances d'attirer des crawls fréquents.
Dans Ahrefs, nous avons besoin du rapport Pages, et pour être exact, de sa partie intitulée : « Best by links » :
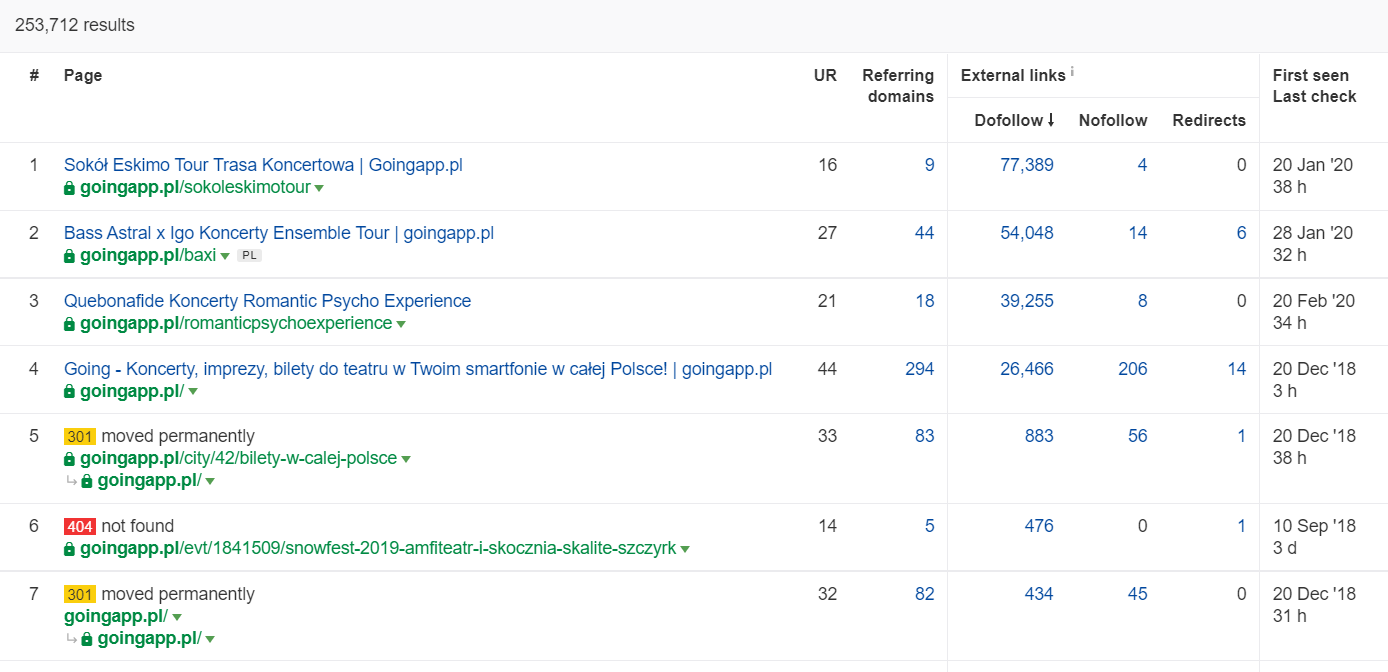
L'exemple ci-dessus montre que certains LP liés aux concerts ont continué à générer des statistiques solides pour les backlinks. Même avec tous les concerts annulés à cause de la pandémie, il est toujours payant d'utiliser des pages historiquement puissantes pour piquer la curiosité des robots rampants et répandre le jus dans les coins les plus profonds de votre site Web.
Quels sont les signes révélateurs d'un problème de budget de crawl ?
Il n'est pas facile de se rendre compte que vous avez affaire à un budget de crawl problématique (trop bas). Pourquoi? Principalement parce que le SEO est une entreprise extrêmement complexe. De faibles classements ou des problèmes d'indexation peuvent tout aussi bien être la conséquence d'un profil de lien médiocre ou du manque de contenu adéquat sur le site Web.
Généralement, un diagnostic de budget de crawl consiste à vérifier :
- Combien de temps s'écoule entre la publication et l'indexation de nouvelles pages (articles de blog / produits), en supposant que vous ne demandez pas l'indexation via Google Search Console ?
- Combien de temps Google conserve-t-il les URL non valides dans son index ? Important : les adresses redirigées sont une exception – Google les stocke exprès.
- Avez-vous des pages qui entrent dans l'index pour être supprimées plus tard ?
- Combien de temps Google passe-t-il sur des pages qui ne génèrent pas de valeur (trafic) ? Accédez à l'analyse des journaux pour le savoir.
Comment analyser et optimiser le budget de crawl ?
La décision de se lancer dans l'optimisation du budget de crawl est principalement dictée par la taille de votre site web. Google suggère qu'en général, les sites Web de moins de 1000 pages ne devraient pas se soucier de tirer le meilleur parti de leurs limites d'exploration disponibles. Dans mon livre, vous devriez commencer à vous battre pour une exploration plus efficace si votre site Web comprend plus de 300 pages et que votre contenu change de manière dynamique (par exemple, vous continuez à ajouter de nouvelles pages/articles de blog).
Pourquoi? C'est une question d'hygiène SEO. Mettez en place de bonnes habitudes d'optimisation et une bonne gestion du budget de crawl dès les premiers jours, et vous aurez moins à rectifier et à reconcevoir à l'avenir.
Optimisation du budget de crawl. Une procédure standard
En général, le travail d'analyse et d'optimisation du budget de craw comprend trois étapes :
- La collecte de données, qui est le processus de compilation de tout ce que nous savons sur le site Web - à la fois des webmasters et des outils externes.
- Analyse de visibilité et identification des fruits à portée de main. Qu'est-ce qui tourne comme une horloge ? Qu'est-ce qui pourrait être mieux? Quels domaines ont le plus fort potentiel de croissance ?
- Recommandations pour le budget de crawl.
Collecte de données pour un audit de budget de crawl
1. Une exploration complète du site Web effectuée avec l'un des outils disponibles dans le commerce. L'objectif est d'effectuer au moins deux explorations : la première simule Googlebot, tandis que l'autre récupère le site Web en tant qu'agent utilisateur par défaut (l'agent utilisateur d'un navigateur fera l'affaire). À ce stade, vous êtes uniquement intéressé par le téléchargement de 100 % du contenu . Si vous remarquez que le crawler est entré dans une boucle (alors qu'après une journée de crawling, nous n'avons encore que 10 % du site Web sur notre disque dur), faites savoir qu'il y a un problème et vous pouvez arrêter le crawling. Un nombre raisonnable d'URL pour l'analyse, dans le cas de grands sites Web, est d'environ 250 à 300 000 pages.
a) Ce que nous recherchons, ce sont principalement les redirections 301 internes, les erreurs 404, mais aussi les situations où vos textes peuvent être classés comme contenu léger. Screaming Frog a la possibilité de détecter le contenu presque dupliqué :
2. Journaux du serveur . La période idéale devrait couvrir le dernier mois, cependant, dans le cas de grands sites Web, deux dernières semaines peuvent s'avérer suffisantes. Dans le meilleur des cas, nous devrions avoir accès aux journaux historiques du serveur pour comparer les mouvements de Googlebot au moment où tout allait bien.
3. Exportations de données depuis Google Search Console . En combinaison avec les points 1 et 2 ci-dessus, les données de la couverture de l'index et des statistiques d'exploration devraient vous donner un compte rendu assez complet de tous les événements survenus sur votre site Web.
4. Données de trafic organique . Les meilleures pages telles que déterminées par Google Search Console, Google Analytics, ainsi que Senuto et Ahrefs. Nous voulons identifier toutes les pages qui se démarquent parmi la foule avec leurs statistiques de haute visibilité, leur volume de trafic ou leur nombre de backlinks. Ces pages doivent devenir l'épine dorsale de votre travail sur le budget de crawl. Nous les utiliserons pour améliorer le crawl des pages les plus importantes.
5. Examen manuel de l'index . Dans certains cas, le meilleur ami d'un expert SEO est une solution simple. Dans ce cas : une revue des données issues directement de l'index ! C'est un bon appel pour vérifier votre site Web avec la combinaison des opérateurs inurl: + site :.Enfin, nous devons fusionner toutes les données collectées. En règle générale, nous utiliserons un robot d'exploration externe avec des fonctionnalités permettant l'importation de données externes (données GSC, journaux de serveur et données de trafic organique).
Analyse de visibilité et fruits à portée de main
Le processus mérite un article séparé, mais notre objectif aujourd'hui est d'avoir une vue d'ensemble de nos objectifs pour le site Web et des progrès réalisés. Nous nous intéressons à tout ce qui sort de l'ordinaire : les baisses de trafic soudaines (qui ne peuvent être expliquées par des tendances saisonnières) et les changements simultanés de visibilité organique. Nous vérifions quels groupes de pages sont les plus puissants, car ils deviendront nos HUBS pour pousser Googlebot plus profondément dans notre site Web.
Dans le monde parfait, une telle vérification devrait couvrir toute l'histoire de notre site Web depuis son lancement. Cependant, comme le volume de données ne cesse de croître chaque mois, concentrons-nous sur l'analyse de la visibilité et du trafic organique de la dernière période de 12 mois.
Budget de crawl – nos recommandations
Les activités énumérées ci-dessus différeront en fonction de la taille du site Web optimisé. Cependant, ce sont les éléments les plus importants que je prends toujours en compte lors de l'analyse d'un budget de crawl. L'objectif primordial est d'éliminer les goulots d'étranglement sur votre site Web. En d'autres termes, garantir une capacité d'exploration maximale pour les Googlebots (ou autres agents d'indexation).
1. Commençons par les bases - l'élimination de toutes sortes d'erreurs 404/410, l'analyse des redirections internes et leur suppression du maillage interne . Nous devrions conclure notre travail par une dernière analyse. Cette fois, tous les liens doivent renvoyer un code de réponse 200, sans redirections internes ni erreurs 404.
- A ce stade, il est judicieux de rectifier toutes les chaînes de redirection détectées dans le rapport de backlink.
2. Après l'exploration, assurez-vous que la structure de notre site Web est exempte de doublons flagrants .
- Vérifiez également la cannibalisation potentielle - outre les problèmes liés au ciblage du même mot-clé avec plusieurs pages (en bref, vous arrêtez de contrôler quelle page sera affichée par Google), la cannibalisation affecte négativement l'ensemble de votre budget de crawl.
- Consolidez les doublons identifiés en une seule URL (généralement celle qui se classe le plus haut).
3. Vérifiez combien d'URL ont la balise noindex . Comme nous le savons, Google peut toujours naviguer sur ces pages. Ils n'apparaissent tout simplement pas dans les résultats de recherche. Nous essayons de minimiser la part des balises noindex dans la structure de notre site Web.
- Exemple concret - un blog organise sa structure avec des balises ; les auteurs affirment que la solution est dictée par la commodité de l'utilisateur. Chaque article est étiqueté avec 3 à 5 balises, attribuées de manière incohérente et non indexées. L'analyse des journaux révèle qu'il s'agit de la troisième structure la plus explorée sur le site Web.
4. Vérifiez robots.txt . N'oubliez pas que la mise en œuvre de robots.txt ne signifie pas que Google n'affichera pas l'adresse dans l'index.
- Vérifiez lesquelles des structures d'adresses bloquées sont encore explorées. Peut-être que les couper crée un goulot d'étranglement ?
- Supprimez les directives obsolètes/inutiles.
5. Analysez le volume d'URL non canoniques sur votre site Web. Google a cessé de considérer rel="canonical" comme une directive dure. Dans de nombreux cas, l'attribut est carrément ignoré par le moteur de recherche (paramètres de tri dans l'index – encore un cauchemar).
6. Analysez les filtres et leur mécanisme sous-jacent . Le filtrage des listes est le plus gros casse-tête de l'optimisation du budget de crawl. Les propriétaires d'entreprises de commerce électronique insistent pour mettre en place des filtres applicables dans n'importe quelle combinaison (par exemple, filtrer par couleur + matériau + taille + disponibilité… jusqu'à la énième fois). La solution n'est pas optimale et doit être limitée au minimum.
7. Architecture de l'information sur le site Web - une architecture qui tient compte des objectifs commerciaux, du potentiel de trafic et du profil de lien actuel. Partons du principe qu'un lien vers le contenu essentiel à nos objectifs commerciaux doit être visible sur l'ensemble du site (sur toutes les pages) ou sur la page d'accueil. Nous simplifions ici, bien sûr, mais la page d'accueil et le menu supérieur / les liens sur l'ensemble du site sont les indicateurs les plus puissants pour créer de la valeur à partir des liens internes. Dans le même temps, nous essayons d'atteindre la répartition optimale du domaine : notre objectif est la situation dans laquelle nous pouvons démarrer le crawl à partir de n'importe quelle page et toujours atteindre le même nombre de pages (chaque URL doit avoir un lien entrant AU MINIMUM) .
- Travailler vers une architecture d'information robuste est l'un des éléments clés de l'optimisation du budget de crawl. Cela nous permet de libérer certaines des ressources du bot d'un emplacement et de les rediriger vers un autre. C'est aussi l'un des plus grands défis, car il nécessite la coopération des parties prenantes de l'entreprise – ce qui conduit souvent à d'énormes batailles et à des critiques sapant les recommandations SEO.
8. Rendu du contenu. Critique dans le cas des sites Web visant à fonder leur maillage interne sur des systèmes de recommandation capturant le comportement des utilisateurs. Surtout, la plupart de ces outils reposent sur des fichiers cookies. Google ne stocke pas de cookies, il n'obtient donc pas de résultats personnalisés. Le résultat : Google voit toujours le même contenu ou pas de contenu du tout.
- C'est une erreur courante d'empêcher Googlebot d'accéder au contenu JS/CSS critique. Cette décision peut entraîner des problèmes d'indexation des pages (et faire perdre du temps à Google pour rendre le contenu indisponible).
9. Performances du site Web - Core Web Vitals . Bien que je sois sceptique quant à l'impact de CWV sur le classement des sites (pour de nombreuses raisons, y compris la diversité des appareils disponibles dans le commerce et les vitesses variables de la connexion Internet), c'est l'un des paramètres qui mérite le plus d'être discuté avec un codeur.
10. Sitemap.xml - vérifiez s'il fonctionne et contient tous les éléments clés (rien que des URL canoniques renvoyant un code d'état 200).
- Ma première recommandation pour optimiser sitemap.xml est de diviser vos pages par type ou, si possible, par catégorie. La division vous donnera un contrôle total sur les mouvements de Google et l'indexation du contenu.