
Mencapai Ketahanan Dengan Antrean: Membangun Sistem yang Tidak Pernah Mengalahkan Satu Miliar
Diterbitkan: 2018-12-21Braze memproses miliaran dan miliaran acara per hari atas nama pelanggannya, menghasilkan miliaran pesan pribadi yang sangat terfokus yang dikirim ke pengguna akhir mereka. Gagal mengirim salah satu pesan tersebut memiliki konsekuensi, apakah itu tanda terima yang terlewat atau—lebih buruk lagi—pemberitahuan yang terlewat yang memberi tahu pengguna bahwa makanan mereka sudah siap. Untuk memastikan pesan-pesan kunci tersebut selalu benar dan selalu tepat waktu, Braze mengambil pendekatan strategis untuk memanfaatkan antrian pekerjaan.
Apa itu Antrian Pekerjaan?
Antrian pekerjaan tipikal adalah pola arsitektur di mana proses mengirimkan pekerjaan komputasi ke antrian dan proses lain benar-benar mengeksekusi pekerjaan. Ini biasanya merupakan hal yang baik—bila digunakan dengan benar, ini memberi Anda derajat konkurensi, skalabilitas, dan redundansi yang tidak dapat Anda peroleh dengan paradigma permintaan-respons tradisional. Banyak pekerja dapat menjalankan pekerjaan yang berbeda secara bersamaan dalam beberapa proses, beberapa mesin, atau bahkan beberapa pusat data untuk konkurensi puncak. Anda dapat menetapkan node pekerja tertentu untuk bekerja pada antrean tertentu dan mengirim pekerjaan tertentu ke antrean tertentu, memungkinkan Anda untuk menskalakan sumber daya sesuai kebutuhan. Jika proses pekerja macet atau pusat data offline, pekerja lain dapat menjalankan pekerjaan yang tersisa.
Meskipun Anda pasti dapat menerapkan prinsip-prinsip ini dan menjalankan sistem antrian pekerjaan dengan mudah dalam skala kecil, jahitannya mulai terlihat (dan bahkan pecah) saat Anda memproses miliaran dan miliaran pekerjaan. Mari kita lihat beberapa masalah yang dihadapi Braze saat kami berkembang dari memproses ribuan, menjadi jutaan, dan sekarang miliaran pekerjaan per hari.
Kurangnya Konsistensi Adalah Kelemahan
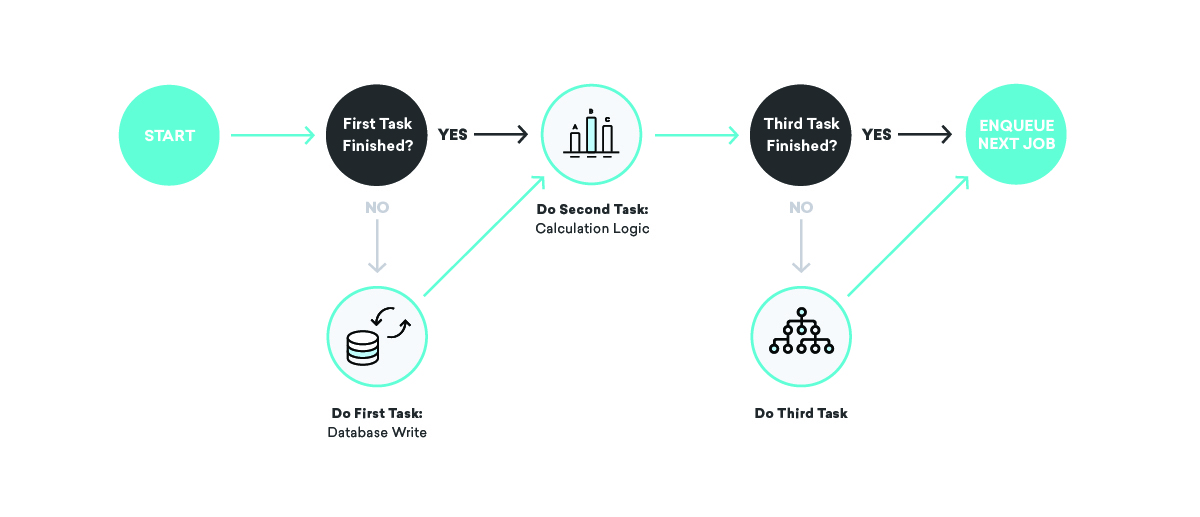
Apa yang terjadi jika kami mengirim pesan, tetapi kami mogok sebelum merekam fakta bahwa kami baru saja mengirim pesan itu?
Beberapa hasil buruk yang berbeda mungkin terjadi di sini. Pertama, Anda mungkin menjadwal ulang pekerjaan yang gagal dan mengirim pesan lagi. Itu…tidak ideal: tidak ada yang mau menerima hal yang sama dua kali. Sebaliknya, pertimbangkan untuk tidak menjadwal ulang sama sekali. Dalam hal ini, akuntansi internal kami akan salah, jadi atribusi, konversi, dan segala macam hal lainnya tidak akan benar di masa mendatang.
Bagaimana kita memperbaikinya? Saat menulis definisi pekerjaan kami, kami berpikir sangat keras tentang idempotensi dan perilaku coba lagi.
Ketika Anda berbicara tentang antrian, idempotensi berarti bahwa satu pekerjaan dapat dihentikan pada titik yang sewenang-wenang, pekerjaan yang diantrekan ulang diputar ulang secara keseluruhan, dan hasil akhirnya akan sama seperti jika kita telah berhasil menjalankan pekerjaan tepat satu waktu. Ini terkait erat dengan perilaku pilihan percobaan ulang kami—setidaknya pengiriman sekali. Dengan mengingat bahwa semua pekerjaan kami akan dijalankan setidaknya sekali, dan mungkin beberapa kali, kami dapat menulis definisi pekerjaan idempoten yang memastikan konsistensi bahkan dalam menghadapi kegagalan acak.
Kembali ke contoh pengiriman pesan kita, bagaimana kita bisa menggunakan konsep-konsep ini untuk memastikan konsistensi? Dalam hal ini, kita mungkin memecah pekerjaan menjadi dua bagian, dengan yang pertama mengirim pesan dan mengantrekan yang kedua, dan yang kedua menulis ke database. Dalam skenario itu, kita dapat mencoba kembali salah satu pekerjaan sebanyak yang kita inginkan—jika penyedia pengirim pesan sedang down, atau database akuntansi internal sedang down, kita akan mencoba lagi dengan tepat sampai kita berhasil!
Pagar yang Baik Menjadi Tetangga yang Baik
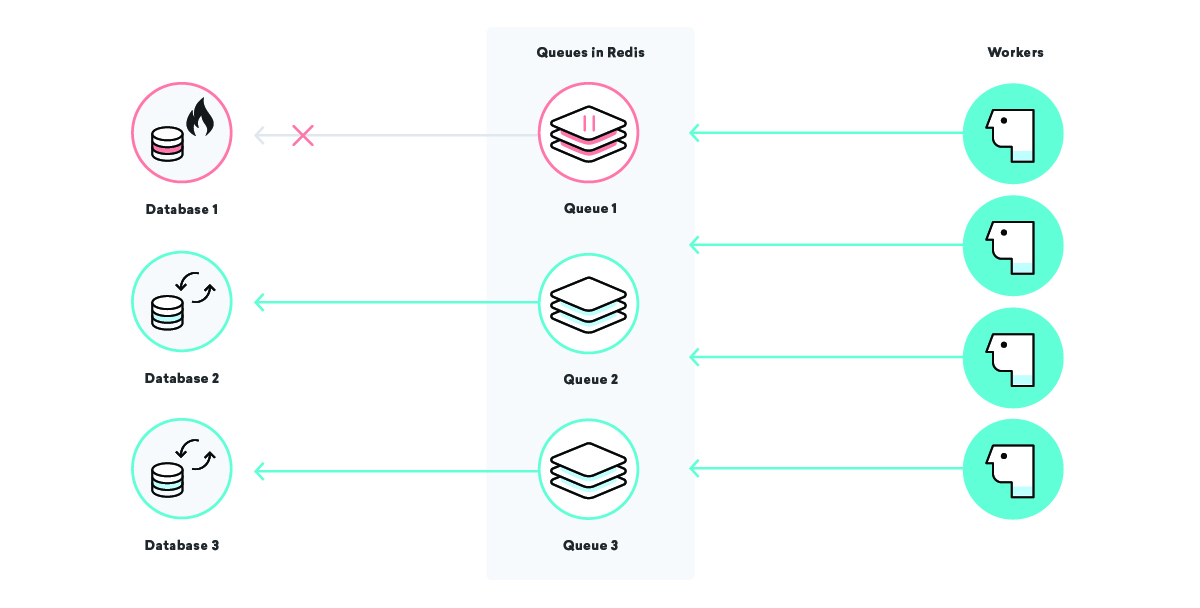
Apa yang terjadi pada pemrosesan data Consolidated Widgets perusahaan contoh kami ketika database untuk Global Gizmos sedang down?
Dalam skenario ini, jika strategi pengiriman setidaknya satu kali kami dimainkan, kami akan mengharapkan semua pekerjaan pemrosesan data untuk Global Gizmos untuk mencoba lagi dan lagi sampai mereka berhasil. Ini bagus—kami tidak akan kehilangan data apa pun meskipun database mereka sedang tidak aktif. Namun, untuk Widget Konsolidasi, ini mungkin tidak terlalu bagus: jika pekerja terus mencoba dan gagal, mereka mungkin terlalu sibuk untuk memproses pekerjaan Widget Konsolidasi secara tepat waktu.
Kami dapat memperbaikinya dengan menggunakan nama antrian yang dipilih dengan baik dan menjeda antrian tertentu sesuai kebutuhan. Dengan ini di sabuk alat kami, kami dapat meredakan ketegangan pada infrastruktur dengan cara pembedahan. Dalam skenario kami di atas, setelah kami mengetahui bahwa basis data Global Gizmos sedang tidak aktif, kami dapat menjeda antrean pemrosesan data mereka hingga kami mengetahui bahwa itu telah dicadangkan, memastikan bahwa satu pemadaman tertentu tidak memengaruhi pelanggan lain!

Menunggu Itu Menyakitkan
Bagaimana jika Widget Konsolidasi dan Gizmos Global mengirim kampanye email ke masing-masing 50 juta pengguna, dengan selang waktu 5 menit? Siapa yang pergi duluan?
Sistem antrian pekerjaan sederhana memiliki antrian "pekerjaan" sederhana yang digunakan pekerja untuk menarik pekerjaan. Setelah Anda memiliki berbagai macam pekerjaan dan jenis pekerjaan yang berbeda, Anda mungkin beralih ke memiliki beberapa jenis antrian, masing-masing memiliki prioritas atau jenis pekerja yang berbeda yang menarik dari antrian tersebut. Dalam nada itu, kami memiliki berbagai antrian sederhana untuk pemrosesan data, pengiriman pesan, dan berbagai tugas pemeliharaan.
Maju cepat ke saat Anda mengirim miliaran pesan yang dipersonalisasi per hari, satu antrean "pesan" tidak akan memotongnya—apa yang terjadi ketika antrean itu tumbuh sangat besar, seperti dalam contoh kami di atas? Apakah kita memprioritaskan pekerjaan yang datang lebih dulu?
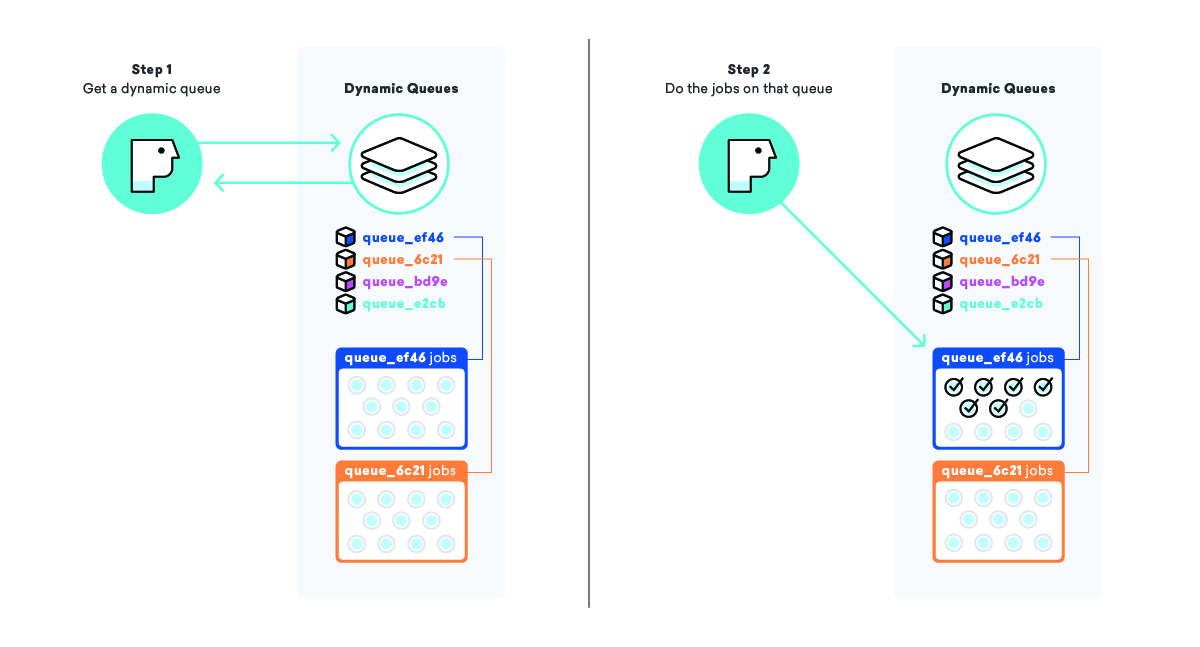
Sistem antrian dinamis kami berusaha untuk mengatasi fenomena yang disebut kelaparan pekerjaan, di mana pekerjaan yang siap dieksekusi menunggu lama sebelum dieksekusi, biasanya karena semacam prioritas. Dalam antrian "pesan" sederhana, prioritasnya hanyalah waktu pekerjaan memasuki antrian, yang berarti bahwa pekerjaan yang ditambahkan ke akhir antrian besar dapat berakhir menunggu untuk waktu yang sangat lama.
Saat kami mengantrekan kampanye dan semua pesannya, alih-alih menambahkan pekerjaan ke antrean "pesan" yang besar, kami membuat antrean yang sama sekali baru hanya untuk kampanye ini, lengkap dengan nama khusus sehingga kami tahu apa itu dan bagaimana menemukannya. Setelah menambahkan pekerjaan ke antrian, kami mengambil daftar "antrian dinamis" kami dan menambahkan nama antrian baru ini ke akhir.
Dengan menggunakan strategi ini, kita dapat menginstruksikan pekerja untuk mengambil nama antrian dinamis dari daftar "antrian dinamis", kemudian memproses semua pekerjaan pada antrian tertentu. Ini memungkinkan kami memastikan bahwa pesan dikirim secepat mungkin DAN bahwa semua pelanggan kami diperlakukan dengan prioritas yang sama.
Akibatnya, ini memiliki manfaat lain, seperti tingkat hit cache yang lebih tinggi dan koneksi database yang lebih sedikit, karena peningkatan lokasi kerja untuk pekerja tertentu. Semua orang menang!
Selalu Miliki Rencana Cadangan
Apa yang terjadi ketika database sedang down, beberapa antrian dijeda, dan antrian pekerjaan mulai terisi?
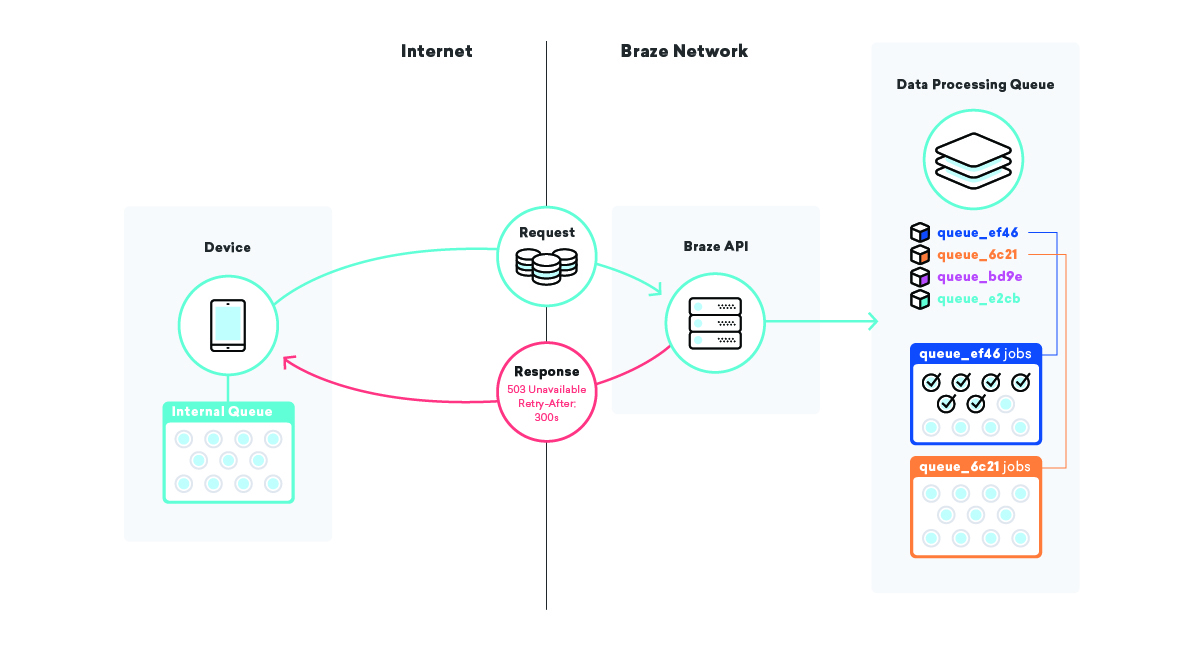
Terkadang bagian penting dari infrastruktur mati begitu saja pada Anda. Kami memiliki sekunder dan cadangan, tetapi waktu yang dibutuhkan untuk mempromosikan infrastruktur cadangan hampir tidak pernah nol. Memiliki beberapa lapisan antrian di seluruh infrastruktur aplikasi dapat sangat membantu dalam mengurangi dampak dari jenis kejadian ini.
Salah satu strategi yang kami terapkan adalah mengantri di perangkat itu sendiri. Jutaan dan jutaan perangkat memiliki aplikasi berbeda menggunakan Braze SDK, dan dalam aplikasi tersebut, kami menggunakan antrean untuk mengirim data ke API kami.
Saat SDK kami mengirimkan data tersebut dan gagal, karena alasan apa pun, SDK mengantre percobaan ulang menggunakan algoritme backoff eksponensial hingga berhasil. Strategi ini meminimalkan dampak kegagalan infrastruktur atau kode, karena perangkat hanya akan mengantri data mereka sendiri dan mengirimkannya ke Braze saat semuanya kembali online.
Bergerak Cepat dan Tidak Melanggar Barang
Pada akhirnya, tujuan kami adalah mengirim pesan yang sangat fokus dan dipersonalisasi lebih baik daripada orang lain, dan itu melibatkan bergerak cepat, menjadi tangguh, dan menyelesaikan semuanya dengan benar. Antrean pekerjaan adalah inti dari infrastruktur Braze, jadi kami selalu mengawasi kinerja kami, menerapkan praktik terbaik, dan bereksperimen dengan strategi baru dan teknik canggih untuk menjadi yang terbaik dalam permainan.
Jika jenis rekayasa sistem berperforma tinggi dan latensi rendah di ruang otomatisasi pemasaran ini menggairahkan Anda, maka Anda pasti harus memeriksa papan pekerjaan kami!