
Pembelajaran Efektif: Masa Depan AI yang Dekat
Diterbitkan: 2017-11-09Teknik Pembelajaran Efektif Ini Bukanlah Teknik Deep Learning/Machine Learning Baru, Tapi Menambah Teknik Yang Sudah Ada Sebagai Peretasan
Tidak diragukan lagi bahwa masa depan utama AI adalah mencapai dan melampaui kecerdasan manusia. Tapi ini adalah prestasi yang terlalu mengada-ada untuk dicapai. Bahkan yang paling optimis di antara kita bertaruh bahwa AI tingkat manusia (AGI atau ASI) sejauh 10-15 tahun dari sekarang dengan skeptis bahkan berani bertaruh bahwa itu akan memakan waktu berabad-abad, bahkan mungkin. Nah, ini bukan tentang postingannya.
Di sini kita akan berbicara tentang masa depan yang lebih nyata, lebih dekat dan membahas algoritma dan teknik AI yang muncul dan kuat yang, menurut pendapat kami, akan membentuk AI dalam waktu dekat.
AI telah mulai memperbaiki manusia dalam beberapa tugas yang dipilih dan spesifik. Misalnya, mengalahkan dokter dalam mendiagnosis kanker kulit dan mengalahkan pemain Go di kejuaraan dunia. Tetapi sistem dan model yang sama akan gagal dalam melakukan tugas yang berbeda dari yang mereka dilatih untuk dipecahkan. Inilah sebabnya, dalam jangka panjang, sistem yang umumnya cerdas yang melakukan serangkaian tugas secara efisien tanpa perlu penilaian ulang disebut sebagai masa depan AI.
Tapi, dalam waktu dekat AI, jauh sebelum AGI muncul, bagaimana mungkin para ilmuwan membuat algoritma bertenaga AI mengatasi masalah yang mereka hadapi saat ini untuk keluar dari lab dan menjadi objek penggunaan sehari-hari?
Ketika Anda melihat-lihat, AI memenangkan satu kastil pada satu waktu (baca posting kami tentang bagaimana AI melampaui manusia, bagian satu dan bagian dua). Apa yang mungkin salah dalam permainan menang-menang seperti itu? Manusia menghasilkan lebih banyak data (yang merupakan makanan yang dikonsumsi AI) seiring waktu dan kemampuan perangkat keras kami juga semakin baik. Bagaimanapun, data dan komputasi yang lebih baik adalah alasan mengapa revolusi Deep Learning dimulai pada tahun 2012 bukan? Yang benar adalah bahwa lebih cepat dari pertumbuhan data dan komputasi adalah pertumbuhan harapan manusia. Ilmuwan Data harus memikirkan solusi di luar apa yang ada saat ini untuk memecahkan masalah dunia nyata. Misalnya, klasifikasi gambar seperti yang kebanyakan orang pikirkan secara ilmiah adalah masalah yang terpecahkan (jika kita menolak keinginan untuk mengatakan akurasi 100% atau GTFO).
Kita dapat mengklasifikasikan gambar (misalkan menjadi gambar kucing atau gambar anjing) yang sesuai dengan kapasitas manusia menggunakan AI. Tetapi apakah ini sudah bisa digunakan untuk kasus penggunaan dunia nyata? Bisakah AI memberikan solusi untuk masalah yang lebih praktis yang dihadapi manusia? Dalam beberapa kasus, ya, tetapi dalam banyak kasus, kami belum sampai di sana.
Kami akan memandu Anda melalui tantangan yang merupakan hambatan utama untuk mengembangkan solusi dunia nyata menggunakan AI. Katakanlah Anda ingin mengklasifikasikan gambar kucing dan anjing. Kami akan menggunakan contoh ini di seluruh posting.

Contoh algoritma kami: Mengklasifikasikan gambar kucing dan anjing
Grafik di bawah ini merangkum tantangan:

Tantangan yang terlibat dalam mengembangkan AI dunia nyata
Mari kita bahas tantangan ini secara rinci:
Belajar Dengan Data Lebih Sedikit
- Data pelatihan yang paling banyak digunakan oleh algoritma Deep Learning mengharuskannya untuk diberi label sesuai dengan konten/fitur yang dikandungnya. Proses ini disebut anotasi.
- Algoritme tidak dapat menggunakan data yang ditemukan secara alami di sekitar Anda. Anotasi beberapa ratus (atau beberapa ribu titik data) itu mudah, tetapi algoritme klasifikasi gambar tingkat manusia kami membutuhkan satu juta gambar beranotasi untuk dipelajari dengan baik.
- Jadi pertanyaannya adalah, apakah mungkin membuat anotasi sejuta gambar? Jika tidak, lalu bagaimana AI dapat menskalakan dengan jumlah data beranotasi yang lebih sedikit?
Memecahkan Beragam Masalah Dunia Nyata
- Sementara kumpulan data diperbaiki, penggunaan di dunia nyata lebih beragam (misalnya, algoritme yang dilatih pada gambar berwarna mungkin gagal parah pada gambar skala abu-abu tidak seperti manusia).
- Sementara kami telah meningkatkan algoritma Computer Vision untuk mendeteksi objek yang cocok dengan manusia. Tetapi seperti yang disebutkan sebelumnya, algoritma ini memecahkan masalah yang sangat spesifik dibandingkan dengan kecerdasan manusia yang jauh lebih umum dalam banyak hal.
- Contoh algoritme AI kami, yang mengklasifikasikan kucing dan anjing, tidak akan dapat mengidentifikasi spesies anjing langka jika tidak diberi makan dengan gambar spesies tersebut.
Menyesuaikan Data Tambahan
- Tantangan besar lainnya adalah data tambahan. Dalam contoh kami, jika kami mencoba mengenali kucing dan anjing, kami mungkin melatih AI kami untuk sejumlah gambar kucing dan anjing dari spesies yang berbeda saat kami pertama kali menerapkannya. Namun pada penemuan spesies baru secara keseluruhan, kita perlu melatih algoritma untuk mengenali “Kotpies” bersama dengan spesies sebelumnya.
- Sementara spesies baru mungkin lebih mirip dengan yang lain daripada yang kita pikirkan dan dapat dengan mudah dilatih untuk mengadaptasi algoritme, ada titik di mana ini lebih sulit dan membutuhkan pelatihan ulang dan penilaian ulang yang lengkap.
- Pertanyaannya adalah bisakah kita membuat AI setidaknya beradaptasi dengan perubahan kecil ini?
Untuk membuat AI segera dapat digunakan, idenya adalah untuk memecahkan tantangan yang disebutkan di atas dengan serangkaian pendekatan yang disebut Pembelajaran Efektif (harap dicatat bahwa ini bukan istilah resmi, saya hanya mengada-ada untuk menghindari penulisan Meta-Learning, Transfer Learning, Sedikit Shot Learning, Adversarial Learning dan Multi-Task Learning setiap saat). Kami, di ParallelDots, sekarang menggunakan pendekatan ini untuk menyelesaikan masalah sempit dengan AI, memenangkan pertempuran kecil sambil bersiap untuk AI yang lebih komprehensif untuk menaklukkan perang yang lebih besar. Biarkan kami memperkenalkan Anda pada teknik ini satu per satu.
Terlihat, sebagian besar teknik Pembelajaran Efektif ini bukanlah sesuatu yang baru. Mereka baru saja melihat kebangkitan sekarang. Peneliti SVM (Support Vector Machines) telah menggunakan teknik ini sejak lama. Adversarial Learning, di sisi lain, adalah sesuatu yang keluar dari karya terbaru Goodfellow di GANs dan Neural Reasoning adalah seperangkat teknik baru yang kumpulan datanya telah tersedia baru-baru ini. Mari selami lebih dalam bagaimana teknik ini akan membantu membentuk masa depan AI.
Pindah Belajar
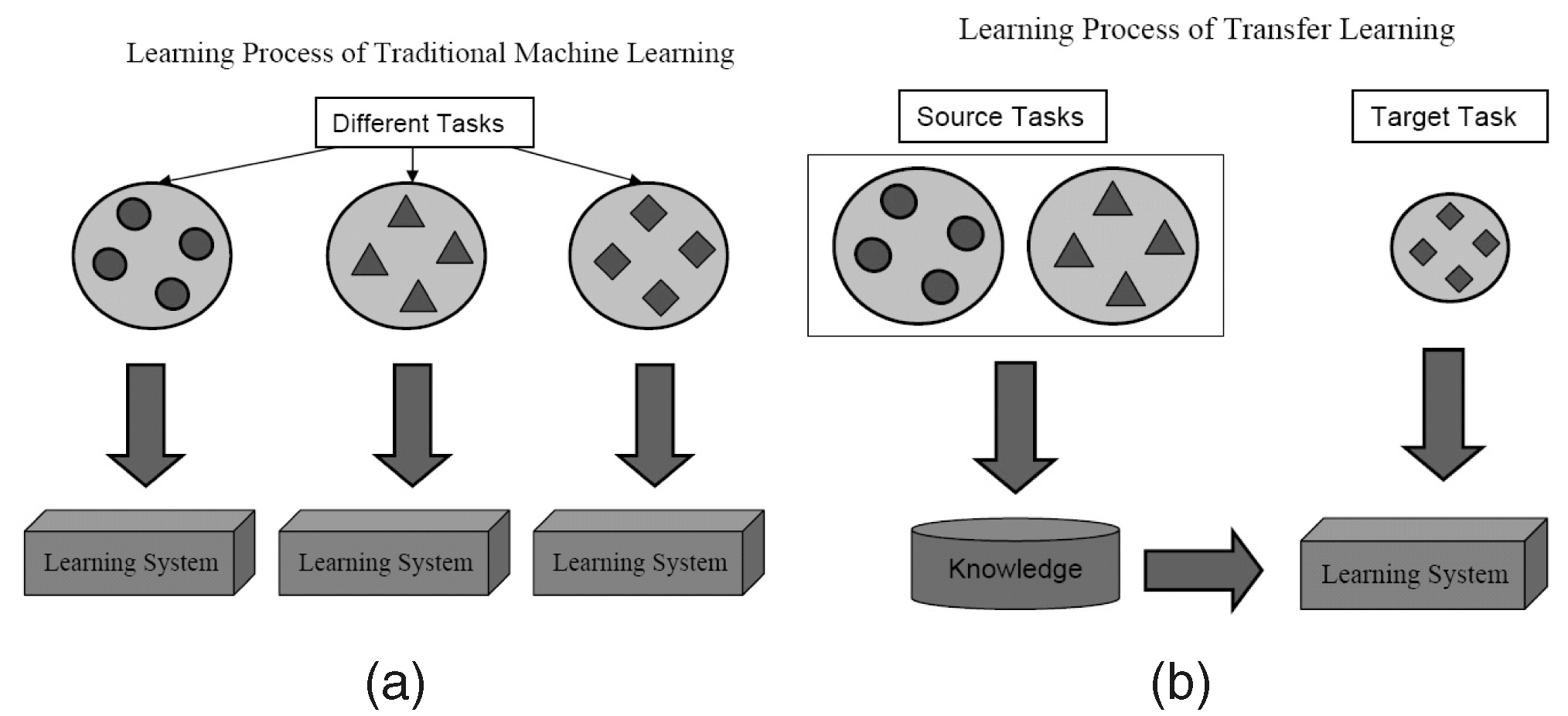
Apa itu?
Seperti namanya, pembelajaran ditransfer dari satu tugas ke tugas lainnya dalam algoritma yang sama dalam Transfer Learning. Algoritma yang dilatih pada satu tugas (tugas sumber) dengan kumpulan data yang lebih besar dapat ditransfer dengan atau tanpa modifikasi sebagai bagian dari algoritma yang mencoba mempelajari tugas yang berbeda (tugas target) pada kumpulan data (yang relatif) lebih kecil.
Beberapa contoh
Menggunakan parameter dari algoritma klasifikasi gambar sebagai ekstraktor fitur dalam tugas yang berbeda seperti deteksi objek adalah aplikasi sederhana dari Transfer Learning. Sebaliknya, itu juga dapat digunakan untuk melakukan tugas-tugas kompleks. Algoritme yang dikembangkan Google untuk mengklasifikasikan Retinopati Diabetik lebih baik daripada dokter beberapa waktu lalu dibuat menggunakan Transfer Learning. Anehnya, detektor Retinopati Diabetik sebenarnya adalah pengklasifikasi gambar dunia nyata (pengklasifikasi gambar anjing/kucing) Transfer Learning untuk mengklasifikasikan pemindaian mata.
Beritahu Saya Lebih Banyak!
Anda akan menemukan Ilmuwan Data menyebut bagian jaringan saraf yang ditransfer dari sumber ke tugas target sebagai jaringan yang telah dilatih sebelumnya dalam literatur Pembelajaran Mendalam. Fine Tuning adalah ketika kesalahan tugas target sedikit dipropagasi kembali ke jaringan yang telah dilatih alih-alih menggunakan jaringan yang telah dilatih sebelumnya tanpa dimodifikasi. Pengantar teknis yang baik untuk Transfer Learning dalam Computer Vision dapat dilihat di sini. Konsep sederhana tentang Pembelajaran Transfer ini sangat penting dalam rangkaian metodologi Pembelajaran Efektif kami.
Direkomendasikan untukmu:

Bagaimana Metaverse Akan Mengubah Industri Otomotif India

Apa Arti Ketentuan Anti-Profiteering Bagi Startup India?

Bagaimana Startup Edtech Membantu Tenaga Kerja India Meningkatkan Keterampilan & Menjadi Siap Masa Depan...

Saham Teknologi Zaman Baru Minggu Ini: Masalah Zomato Berlanjut, EaseMyTrip Posting Stro...

Startup India Mengambil Jalan Pintas Dalam Mengejar Pendanaan

Platform Pemasaran Digital Logicserve Bags Pendanaan INR 80 Cr, Berganti Nama Sebagai LS Dig...
Pembelajaran Multi-Tugas
Apa itu?
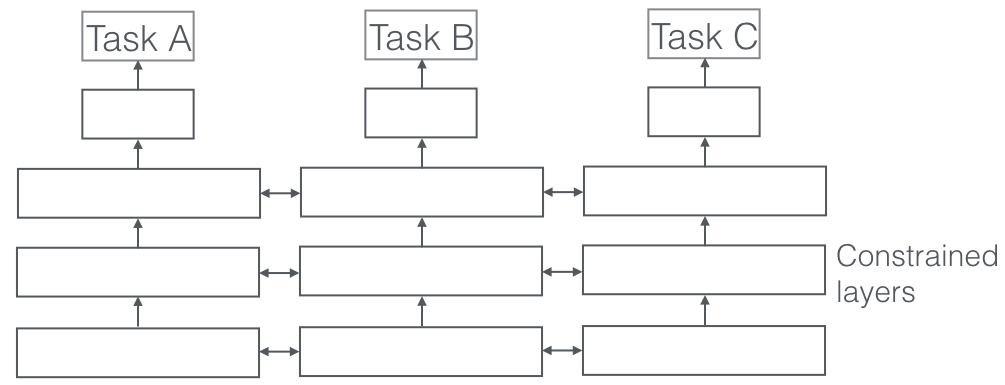

Dalam Pembelajaran Multi-Tugas, beberapa tugas pembelajaran diselesaikan pada saat yang sama, sambil memanfaatkan kesamaan dan perbedaan di seluruh tugas. Ini mengejutkan, tetapi terkadang mempelajari dua atau lebih tugas bersama-sama (juga disebut tugas utama dan tugas tambahan) dapat memberikan hasil yang lebih baik untuk tugas tersebut. Harap dicatat bahwa tidak setiap pasangan atau triplet atau kuartet tugas dapat dianggap sebagai tugas tambahan. Tetapi ketika berhasil, ini adalah peningkatan gratis dalam akurasi.
Beberapa contoh
Misalnya, di ParallelDots, pengklasifikasi Sentimen, Niat, dan Deteksi Emosi kami dilatih sebagai Pembelajaran Multi-Tugas yang meningkatkan akurasinya dibandingkan jika kami melatihnya secara terpisah. Sistem Pelabelan Peran Semantik dan penandaan POS terbaik di NLP yang kami tahu adalah Sistem Pembelajaran Multi-Tugas, jadi merupakan salah satu sistem terbaik untuk segmentasi semantik dan instans di Computer Vision. Google datang dengan Pembelajar Multi-Tugas multimodal (Satu model untuk mengatur semuanya) yang dapat belajar dari kumpulan data visi dan teks dalam bidikan yang sama.
Beritahu Saya Lebih Banyak!
Aspek yang sangat penting dari Pembelajaran Multi-Tugas yang terlihat dalam aplikasi dunia nyata adalah di mana melatih tugas apa pun untuk menjadi antipeluru, kita perlu menghormati banyak data domain yang berasal (juga disebut adaptasi domain). Contoh dalam kasus penggunaan kucing dan anjing kami adalah algoritme yang dapat mengenali gambar dari sumber yang berbeda (misalnya kamera VGA dan kamera HD atau bahkan kamera inframerah). Dalam kasus seperti itu, hilangnya klasifikasi domain tambahan (dari mana gambar berasal) dapat ditambahkan ke tugas apa pun dan kemudian mesin belajar sedemikian rupa sehingga algoritme terus menjadi lebih baik pada tugas utama (mengklasifikasikan gambar menjadi gambar kucing atau anjing), tetapi sengaja menjadi lebih buruk pada tugas tambahan (ini dilakukan dengan mempropagasi mundur gradien kesalahan terbalik dari tugas klasifikasi domain). Idenya adalah bahwa algoritme mempelajari fitur diskriminatif untuk tugas utama, tetapi melupakan fitur yang membedakan domain dan ini akan membuatnya lebih baik. Pembelajaran Multi-Tugas dan sepupu Adaptasi Domainnya adalah salah satu teknik Pembelajaran Efektif paling sukses yang kami ketahui dan memiliki peran besar dalam membentuk masa depan AI.
Pembelajaran Bermusuhan
Apa itu?
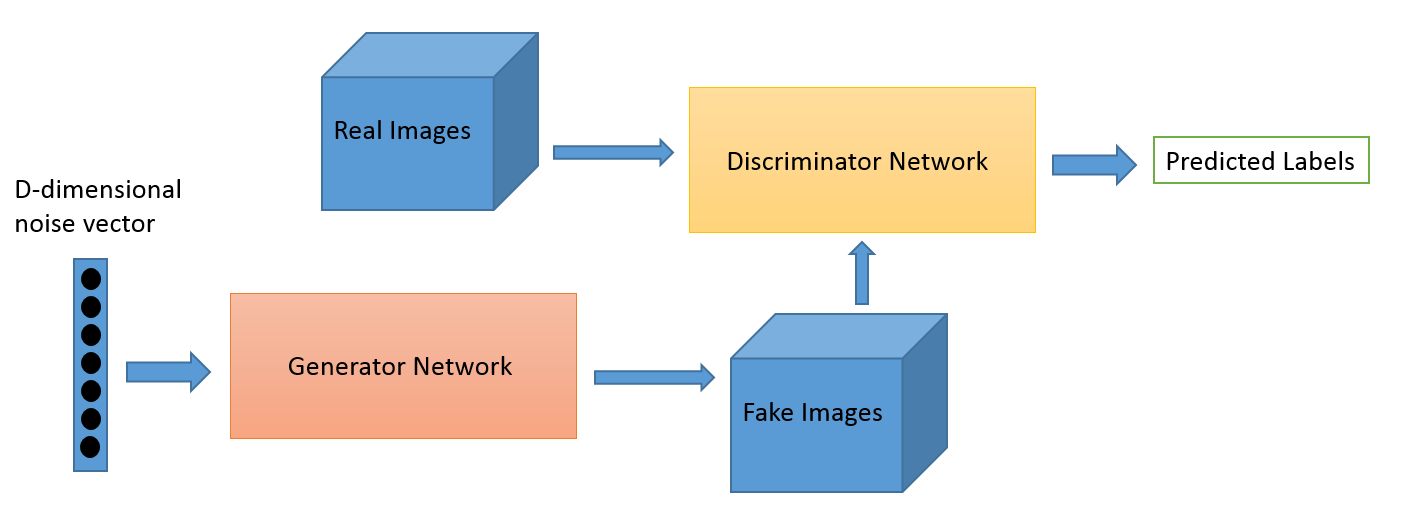
Adversarial Learning sebagai bidang berkembang dari karya penelitian Ian Goodfellow. Sementara aplikasi Adversarial Learning yang paling populer tidak diragukan lagi Generative Adversarial Networks (GANs) yang dapat digunakan untuk menghasilkan gambar yang menakjubkan, ada beberapa cara lain dari kumpulan teknik ini. Biasanya teknik yang diilhami teori permainan ini memiliki dua algoritme generator dan diskriminator, yang tujuannya adalah untuk saling membodohi saat mereka berlatih. Generator dapat digunakan untuk menghasilkan gambar baru seperti yang kita diskusikan, tetapi juga dapat menghasilkan representasi data lain untuk menyembunyikan detail dari diskriminator. Yang terakhir adalah mengapa konsep ini sangat menarik bagi kami.
Beberapa contoh
Ini adalah bidang baru dan kapasitas generasi gambar mungkin menjadi fokus sebagian besar orang yang tertarik seperti astronom. Namun kami yakin ini akan mengembangkan kasus penggunaan yang lebih baru juga seperti yang akan kami sampaikan nanti.
Beritahu Saya Lebih Banyak!
Game adaptasi domain dapat ditingkatkan menggunakan GAN loss. Kerugian tambahan di sini adalah sistem GAN alih-alih klasifikasi domain murni, di mana seorang diskriminator mencoba mengklasifikasikan dari domain mana data itu berasal dan komponen generator mencoba membodohinya dengan menghadirkan noise acak sebagai data. Dalam pengalaman kami, ini bekerja lebih baik daripada adaptasi domain biasa (yang juga lebih tidak menentu untuk kode).
Sedikit Belajar Tembakan
Apa itu?
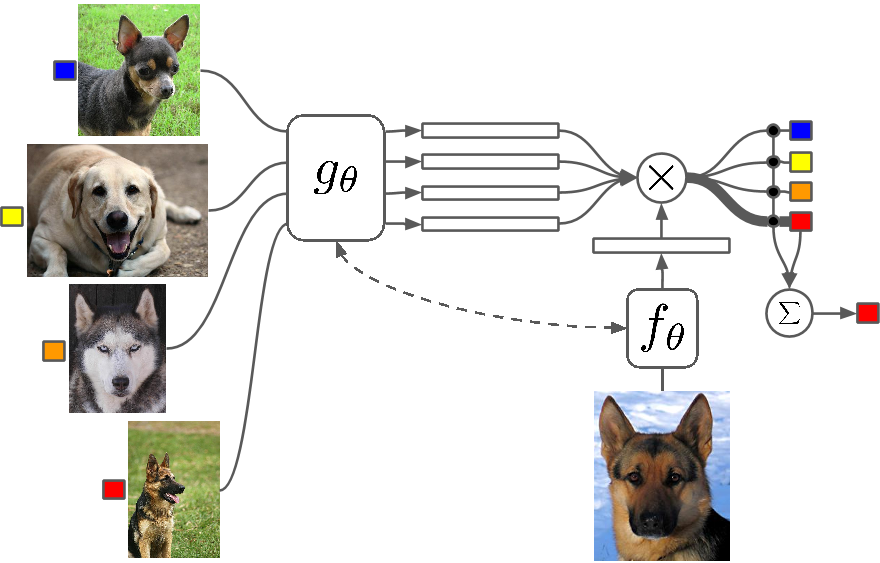
Beberapa Shot Learning adalah studi tentang teknik yang membuat algoritma Deep Learning (atau algoritma Machine Learning apa pun) belajar dengan jumlah contoh yang lebih sedikit dibandingkan dengan apa yang akan dilakukan oleh algoritma tradisional. Pembelajaran One Shot pada dasarnya adalah pembelajaran dengan satu contoh kategori, secara induktif pembelajaran k-shot berarti pembelajaran dengan k contoh setiap kategori.
Beberapa contoh
Beberapa Shot Learning sebagai bidang melihat masuknya makalah di semua konferensi Deep Learning utama dan sekarang ada kumpulan data khusus untuk membandingkan hasil, seperti MNIST dan CIFAR untuk pembelajaran mesin normal. One-shot Learning adalah melihat sejumlah aplikasi dalam tugas klasifikasi gambar tertentu seperti deteksi fitur dan representasi.
Beritahu Saya Lebih Banyak!
Ada beberapa metode yang digunakan untuk pembelajaran Few Shot, termasuk Transfer Learning, Multi-Task Learning serta Meta-Learning sebagai semua atau sebagian dari algoritme. Ada cara lain seperti memiliki fungsi kehilangan yang cerdas, menggunakan arsitektur dinamis atau menggunakan peretasan pengoptimalan. Zero Shot Learning, kelas algoritme yang mengklaim dapat memprediksi jawaban untuk kategori yang bahkan belum pernah dilihat algoritme, pada dasarnya adalah algoritme yang dapat diskalakan dengan tipe data baru.
Meta-Belajar
Apa itu?

Meta-Learning persis seperti apa kedengarannya, sebuah algoritme yang melatih sedemikian rupa sehingga, saat melihat set data, ia menghasilkan prediktor pembelajaran mesin baru untuk set data tertentu. Definisinya sangat futuristik jika Anda melihatnya sekilas. Anda merasa “wah! itulah yang dilakukan seorang Data Scientist” dan ini mengotomatiskan “pekerjaan paling seksi abad ke-21”, dan dalam beberapa hal, Meta-Learners telah mulai melakukan itu.
Beberapa contoh
Meta-Learning telah menjadi topik hangat di Deep Learning baru-baru ini, dengan banyak makalah penelitian keluar, paling sering menggunakan teknik untuk hyperparameter dan optimasi jaringan saraf, menemukan arsitektur jaringan yang baik, pengenalan gambar Sedikit-Shot, dan pembelajaran penguatan cepat.
Beritahu Saya Lebih Banyak!
Beberapa orang merujuk pada otomatisasi penuh untuk memutuskan parameter dan hyperparameter seperti arsitektur jaringan sebagai autoML dan Anda mungkin menemukan orang yang merujuk pada Meta Learning dan AutoML sebagai bidang yang berbeda. Terlepas dari semua hype di sekitar mereka, kenyataannya adalah bahwa Meta Learners masih merupakan algoritma dan jalur untuk menskalakan Machine Learning dengan kompleksitas dan variasi data yang meningkat.
Sebagian besar makalah Meta-Learning adalah peretasan yang cerdas, yang menurut Wikipedia memiliki properti berikut:
- Sistem harus mencakup subsistem pembelajaran, yang beradaptasi dengan pengalaman.
- Pengalaman diperoleh dengan memanfaatkan meta-pengetahuan yang diekstraksi baik dalam episode pembelajaran sebelumnya pada dataset tunggal atau dari domain atau masalah yang berbeda.
- Bias belajar harus dipilih secara dinamis.
Subsistem pada dasarnya adalah pengaturan yang beradaptasi ketika meta-data domain (atau domain yang sama sekali baru) diperkenalkan padanya. Metadata ini dapat memberi tahu tentang peningkatan jumlah kelas, kompleksitas, perubahan warna dan tekstur dan objek (dalam gambar), gaya, pola bahasa (bahasa alami) dan fitur serupa lainnya. Lihat beberapa makalah yang sangat keren di sini: Hirarki Bersama Meta-Learning dan Meta-Learning Menggunakan Konvolusi Temporal. Anda juga dapat membuat algoritma Sedikit Pemotretan atau Nol Pemotretan menggunakan arsitektur Meta-Learning. Meta-Learning adalah salah satu teknik paling menjanjikan yang akan membantu membentuk masa depan AI.
Penalaran Saraf
Apa itu?

Neural Reasoning adalah hal besar berikutnya dalam masalah klasifikasi citra. Penalaran Neural adalah langkah di atas pengenalan pola di mana algoritma bergerak di luar gagasan hanya mengidentifikasi dan mengklasifikasikan teks atau gambar. Neural Reasoning memecahkan pertanyaan yang lebih umum dalam analisis teks atau analisis visual. Misalnya, gambar di bawah ini mewakili serangkaian pertanyaan yang dapat dijawab oleh Neural Reasoning dari sebuah gambar.
Beritahu Saya Lebih Banyak!
Kumpulan teknik baru ini akan muncul setelah rilis dataset bAbi Facebook atau dataset CLEVR baru-baru ini. Teknik-teknik yang muncul untuk menguraikan hubungan dan bukan hanya pola memiliki potensi besar untuk memecahkan tidak hanya Penalaran Saraf tetapi juga beberapa masalah sulit lainnya termasuk masalah pembelajaran Beberapa Pemotretan.
Akan kembali
Sekarang setelah kita mengetahui apa saja tekniknya, mari kita kembali dan melihat bagaimana teknik tersebut memecahkan masalah dasar yang kita mulai. Tabel di bawah ini memberikan gambaran tentang kemampuan teknik Pembelajaran Efektif untuk mengatasi tantangan:
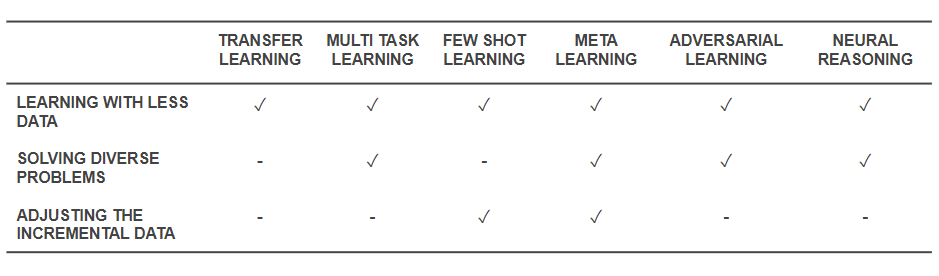
Kemampuan Teknik Belajar Efektif
- Semua teknik yang disebutkan di atas membantu menyelesaikan pelatihan dengan jumlah data yang lebih sedikit dalam beberapa cara atau yang lain. Sementara Meta-Learning akan memberikan arsitektur yang hanya akan dibentuk dengan data, Transfer Learning membuat pengetahuan dari beberapa domain lain berguna untuk mengimbangi lebih sedikit data. Beberapa Shot Learning didedikasikan untuk masalah sebagai disiplin ilmu. Pembelajaran Bermusuhan dapat membantu meningkatkan kumpulan data.
- Adaptasi Domain (sejenis Pembelajaran Multi-Tugas), Pembelajaran Bermusuhan dan (terkadang) arsitektur Meta-Learning membantu memecahkan masalah yang timbul dari keragaman data.
- Meta-Learning dan Beberapa Shot Learning membantu memecahkan masalah data tambahan.
- Algoritma Neural Reasoning memiliki potensi besar untuk memecahkan masalah dunia nyata ketika digabungkan sebagai Meta-Learners atau Few Shot Learners.
Harap dicatat bahwa teknik Pembelajaran Efektif ini bukanlah teknik Pembelajaran Mendalam/Pembelajaran Mesin yang baru, tetapi menambah teknik yang ada sebagai peretasan sehingga membuatnya lebih bermanfaat. Oleh karena itu, Anda masih akan melihat alat reguler kami seperti Convolutional Neural Networks dan LSTM beraksi, tetapi dengan bumbu tambahan. Teknik Pembelajaran Efektif yang bekerja dengan lebih sedikit data dan melakukan banyak tugas sekaligus dapat membantu dalam produksi dan komersialisasi produk dan layanan yang didukung AI dengan lebih mudah. Di ParallelDots, kami mengakui kekuatan Pembelajaran yang Efisien dan menggabungkannya sebagai salah satu fitur utama filosofi Penelitian kami.
Postingan oleh Parth Shrivastava ini pertama kali muncul di blog ParallelDots dan telah direproduksi dengan izin.