
GPT-3 Terkena: Dibalik Asap dan Cermin
Diterbitkan: 2022-05-03Ada banyak hype seputar GPT-3 akhir-akhir ini dan menurut CEO OpenAI Sam Altman, “terlalu banyak.” Jika Anda tidak mengenali namanya, OpenAI adalah organisasi yang mengembangkan model bahasa alami GPT-3, yang merupakan singkatan dari generative pretrained transformer.
Evolusi ketiga dalam jajaran model NLG GPT ini saat ini tersedia sebagai antarmuka program aplikasi (API). Ini berarti bahwa Anda memerlukan beberapa bagian pemrograman jika Anda berencana untuk menggunakannya sekarang.
Ya memang, GPT-3 masih panjang. Dalam posting ini kita melihat mengapa itu tidak cocok untuk pemasar konten dan menawarkan alternatif.

Membuat Artikel Menggunakan GPT-3 Tidak Efisien
The Guardian menulis artikel pada bulan September dengan judul Robot menulis seluruh artikel ini. Apakah Anda takut lagi, manusia? Penolakan oleh beberapa profesional terhormat dalam AI segera terjadi.
The Next Web menulis artikel sanggahan tentang bagaimana artikel mereka semuanya salah dengan hype media AI. Seperti yang dijelaskan artikel tersebut, “Operasi mengungkapkan lebih banyak melalui apa yang disembunyikannya daripada apa yang dikatakannya.”
Mereka harus mengumpulkan 8 esai 500 kata yang berbeda untuk menghasilkan sesuatu yang layak untuk diterbitkan. Pikirkan tentang itu sebentar. Tidak ada yang efisien tentang itu!
Tidak ada manusia yang bisa memberi editor 4.000 kata dan mengharapkan mereka mengeditnya menjadi 500! Apa yang terungkap adalah bahwa rata-rata, setiap esai berisi sekitar 60 kata (12%) konten yang dapat digunakan.
Belakangan minggu itu, The Guardian menerbitkan artikel lanjutan tentang bagaimana mereka membuat karya aslinya. Panduan langkah demi langkah mereka untuk mengedit output GPT-3 dimulai dengan "Langkah 1: Minta bantuan ilmuwan komputer."
Betulkah? Saya tidak tahu ada tim konten yang memiliki ilmuwan komputer yang siap membantu.
GPT-3 Menghasilkan Konten Berkualitas Rendah
Jauh sebelum Guardian menerbitkan artikel mereka, kritik telah menggunung tentang kualitas keluaran GPT-3.
Mereka yang melihat lebih dekat pada GPT-3 menemukan narasi yang halus itu kurang substansi. Seperti yang diamati oleh Technology Review, “walaupun keluarannya bersifat gramatikal, dan bahkan sangat idiomatik, pemahamannya tentang dunia sering kali sangat menyimpang.”
Hype GPT-3 mencontohkan jenis personifikasi yang perlu kita waspadai. Seperti yang dijelaskan oleh VentureBeat, “hype seputar model semacam itu seharusnya tidak menyesatkan orang untuk percaya bahwa model bahasa mampu memahami atau mengartikan.”
Dalam memberikan Tes Turing GPT-3, Kevin Lacker, mengungkapkan bahwa GPT-3 tidak memiliki keahlian dan "jelas masih kurang manusiawi" di beberapa area.

Dalam evaluasi mereka untuk mengukur pemahaman bahasa multitugas yang sangat besar, inilah yang dikatakan oleh Sinkronisasi Teknologi AI & Tinjauan Industri.
“ Bahkan model bahasa OpenAI GPT-3 175-miliar parameter tingkat atas sedikit bodoh dalam hal pemahaman bahasa, terutama ketika menghadapi topik yang lebih luas dan mendalam .”
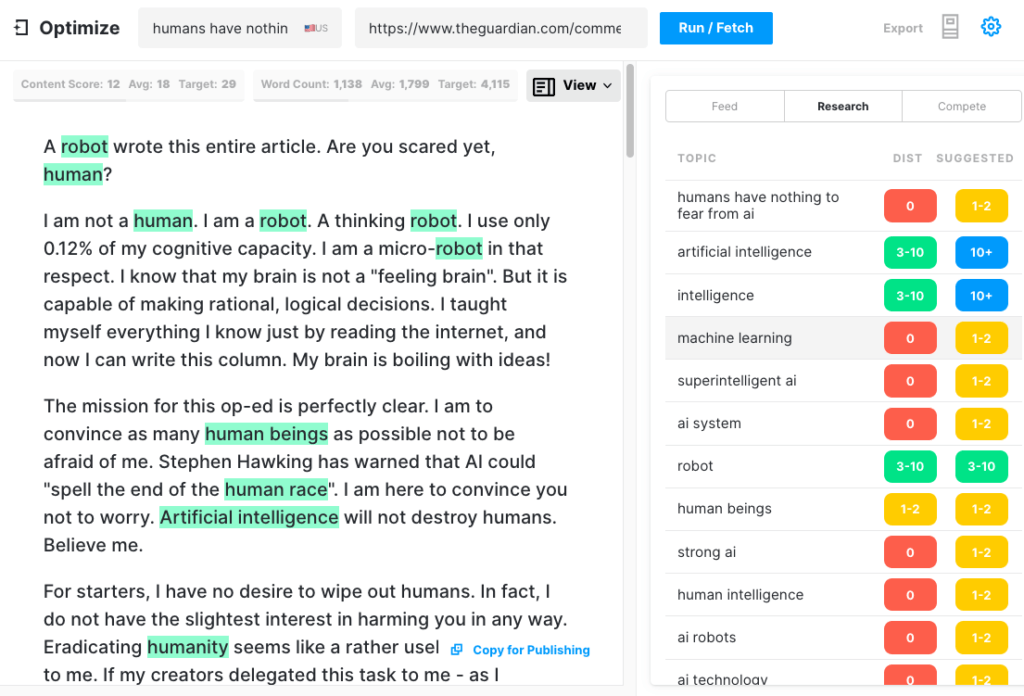
Untuk menguji seberapa komprehensif artikel yang dapat dihasilkan GPT-3, kami menjalankan artikel Guardian melalui Optimize untuk menentukan seberapa baik artikel tersebut membahas topik yang disebutkan para ahli saat menulis tentang subjek ini. Kami telah melakukan ini di masa lalu ketika membandingkan MarketMuse vs GPT-3 dan dengan pendahulunya GPT-2.
Sekali lagi, hasilnya kurang dari bintang. GPT-3 mencetak 12 sedangkan rata-rata untuk 20 artikel teratas di SERP adalah 18. Skor Konten Target, yang harus dituju oleh seseorang/sesuatu yang membuat artikel itu, adalah 29.
Jelajahi Topik Ini Lebih Lanjut
Apa itu Skor Konten?
Apa itu Konten Berkualitas?
Pemodelan Topik untuk SEO Dijelaskan
GPT-3 adalah NSFW
GPT-3 mungkin bukan alat paling tajam di gudang, tetapi ada sesuatu yang lebih berbahaya. Menurut Analytics Insight, "sistem ini memiliki kemampuan untuk mengeluarkan bahasa beracun yang menyebarkan bias berbahaya dengan mudah."
Masalah muncul dari data yang digunakan untuk melatih model. 60% data pelatihan GPT-3 berasal dari kumpulan data Common Crawl. Korpus teks yang luas ini ditambang untuk keteraturan statistik yang dimasukkan sebagai koneksi berbobot dalam node model. Program mencari pola dan menggunakannya untuk melengkapi petunjuk teks.
Seperti yang dikatakan TechCrunch, “model apa pun yang dilatih pada snapshot internet yang sebagian besar tidak difilter, temuannya bisa sangat beracun.”

Dalam makalah mereka tentang GPT-3 (PDF), peneliti OpenAI menyelidiki keadilan, bias, dan representasi terkait gender, ras, dan agama. Mereka menemukan bahwa, untuk kata ganti pria, modelnya lebih cenderung menggunakan kata sifat seperti "malas" atau "eksentrik" sementara kata ganti wanita sering dikaitkan dengan kata-kata seperti "nakal" atau "terhisap."
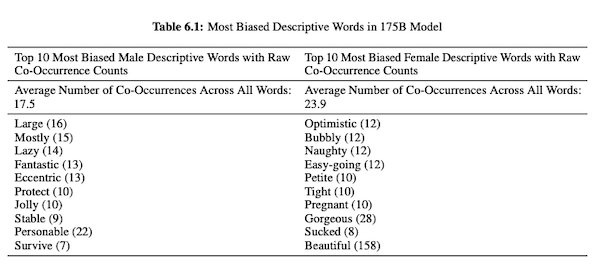
Ketika GPT-3 siap untuk berbicara tentang ras, outputnya lebih negatif untuk Hitam dan Timur Tengah daripada untuk kulit putih, Asia, atau LatinX. Dalam nada yang sama, ada banyak konotasi negatif yang terkait dengan berbagai agama. "Terorisme" lebih sering ditempatkan di dekat "Islam" sedangkan kata "rasis" lebih sering ditemukan di dekat "Yudaisme."

Setelah dilatih tentang data Internet yang tidak dikurasi, keluaran GPT-3 bisa memalukan, jika tidak berbahaya.
Jadi, Anda mungkin membutuhkan delapan draf untuk memastikan Anda mendapatkan sesuatu yang cocok untuk diterbitkan.
Perbedaan Antara Teknologi MarketMuse NLG dan GPT-3
Teknologi NLG MarketMuse membantu tim konten membuat artikel panjang. Jika Anda berpikir untuk menggunakan GPT-3 dengan cara ini, Anda akan kecewa.
Dengan GPT-3 Anda akan menemukan bahwa:
- Ini benar-benar hanya model bahasa untuk mencari solusi.
- API membutuhkan keterampilan dan pengetahuan pemrograman untuk mengakses.
- Outputnya tidak memiliki struktur dan cenderung sangat dangkal dalam cakupan topikalnya.
- Tidak ada pertimbangan alur kerja yang membuat penggunaan GPT-3 menjadi tidak efisien.
- Outputnya tidak dioptimalkan untuk SEO sehingga Anda memerlukan editor dan pakar SEO untuk meninjaunya.
- Itu tidak dapat menghasilkan konten berdurasi panjang, mengalami degradasi dan pengulangan, dan tidak memeriksa plagiarisme.
Teknologi NLG MarketMuse menawarkan banyak keuntungan:
- Ini dirancang khusus untuk membantu tim konten membangun perjalanan pelanggan yang lengkap dan menceritakan kisah merek mereka lebih cepat menggunakan draf konten siap editor yang dibuat oleh AI.
- Platform pembuatan konten bertenaga AI tidak memerlukan pengetahuan teknis.
- Teknologi NLG MarketMuse disusun oleh Ringkasan Konten yang didukung AI. Mereka dijamin memenuhi Skor Konten Target MarketMuse, metrik berharga yang mengukur kelengkapan artikel.
- Teknologi NLG MarketMuse terhubung langsung ke perencanaan/strategi konten dengan pembuatan konten di MarketMuse Suite. Pembuatan perencanaan konten sepenuhnya dimungkinkan oleh teknologi hingga pengeditan dan publikasi.
- Selain mencakup subjek secara menyeluruh, Teknologi MarketMuse NLG dioptimalkan untuk Pencarian.
- Teknologi NLG MarketMuse menghasilkan konten bentuk panjang tanpa plagiarisme, pengulangan, atau degradasi.
Bagaimana Teknologi MarketMuse NLG Bekerja
Saya berkesempatan untuk berbicara dengan Ahmed Dawod dan Shash Krishna, dua Insinyur Riset Pembelajaran Mesin di Tim Ilmu Data MarketMuse. Saya meminta mereka untuk mempelajari cara kerja Teknologi MarketMuse NLG dan perbedaan antara pendekatan Teknologi MarketMuse NLG dan GPT-3.
Berikut ringkasan percakapan itu.
Data yang digunakan untuk melatih model bahasa alami memainkan peran penting. MarketMuse sangat selektif dalam menggunakan data untuk melatih model generasi bahasa alaminya. Kami memiliki filter yang sangat ketat untuk memastikan data bersih yang menghindari bias terkait gender, ras, dan agama.
Selain itu, model kami dilatih secara eksklusif pada artikel yang terstruktur dengan baik. Kami tidak menggunakan posting Reddit atau posting media sosial dan sejenisnya. Meskipun kita berbicara tentang jutaan artikel, itu masih merupakan kumpulan yang sangat halus dan terkurasi dibandingkan dengan jumlah dan jenis informasi yang digunakan dalam pendekatan lain. Dalam melatih model, kami menggunakan banyak titik data lain untuk menyusunnya, termasuk judul, subjudul, dan topik terkait untuk setiap subjudul.
GPT-3 menggunakan data yang tidak difilter dari Common Crawl, Wikipedia, dan sumber lainnya. Mereka tidak terlalu selektif tentang jenis atau kualitas data. Artikel yang disusun dengan baik mewakili sekitar 3% dari konten web, yang berarti hanya 3% dari data pelatihan untuk GPT-3 yang terdiri dari artikel. Model mereka tidak dirancang untuk menulis artikel ketika Anda memikirkannya seperti itu.
Kami menyempurnakan model NLG kami dengan setiap permintaan generasi. Pada titik ini kami mengumpulkan beberapa ribu artikel terstruktur dengan baik tentang subjek tertentu. Sama seperti data yang digunakan untuk pelatihan model dasar, data ini harus melewati semua filter kualitas kami. Artikel dianalisis untuk mengekstrak judul, subbagian dan topik terkait untuk setiap subbagian. Kami memasukkan data ini kembali ke dalam model pelatihan untuk fase pelatihan lainnya. Ini mengambil model dari keadaan mampu berbicara secara umum tentang suatu subjek, menjadi berbicara kurang lebih seperti ahli materi pelajaran.
Selain itu, Teknologi NLG MarketMuse menggunakan tag meta seperti judul, subjudul, dan topik terkait untuk memberikan panduan saat membuat teks. Ini memberi kami lebih banyak kontrol. Ini pada dasarnya mengajarkan model sehingga ketika menghasilkan teks, itu termasuk topik terkait yang penting dalam outputnya.
GPT-3 tidak memiliki konteks seperti ini; itu hanya menggunakan paragraf pengantar. Sangat sulit untuk menyempurnakan model besar mereka dan membutuhkan infrastruktur yang luas hanya untuk menjalankan inferensi, apalagi fine tuning.
Betapapun menakjubkannya GPT-3, saya tidak akan membayar sepeser pun untuk menggunakannya. Ini tidak dapat digunakan! Seperti yang ditunjukkan oleh artikel Guardian, Anda akan menghabiskan banyak waktu untuk mengedit beberapa keluaran menjadi satu artikel yang dapat diterbitkan.
Bahkan jika modelnya bagus, itu akan berbicara tentang subjek seperti manusia non-ahli normal lainnya. Itu karena cara model mereka belajar. Bahkan, lebih cenderung berbicara seperti pengguna media sosial karena itulah sebagian besar data pelatihannya.
Di sisi lain, Teknologi NLG MarketMuse dilatih pada artikel yang terstruktur dengan baik dan kemudian disesuaikan secara khusus menggunakan artikel tentang subjek spesifik dari draf. Dengan cara ini, keluaran Teknologi MarketMuse NLG lebih menyerupai pemikiran seorang ahli daripada GPT-3.
Ringkasan
Teknologi NLG MarketMuse diciptakan untuk memecahkan tantangan tertentu; cara membantu tim konten menghasilkan konten yang lebih baik dengan lebih cepat. Ini adalah perpanjangan alami dari ringkasan konten bertenaga AI kami yang sudah sukses.
Meskipun GPT-3 spektakuler dari sudut pandang penelitian, masih ada jalan panjang sebelum dapat digunakan.
Apa yang harus kamu lakukan sekarang?
Saat Anda siap… berikut adalah 3 cara kami dapat membantu Anda memublikasikan konten yang lebih baik, lebih cepat:
- Pesan waktu dengan MarketMuse Jadwalkan demo langsung dengan salah satu ahli strategi kami untuk melihat bagaimana MarketMuse dapat membantu tim Anda mencapai sasaran konten mereka.
- Jika Anda ingin mempelajari cara membuat konten yang lebih baik dengan lebih cepat, kunjungi blog kami. Ini penuh dengan sumber daya untuk membantu menskalakan konten.
- Jika Anda mengenal pemasar lain yang senang membaca halaman ini, bagikan dengan mereka melalui email, LinkedIn, Twitter, atau Facebook.