
Cara Menggunakan NLP dalam Pemasaran Konten
Diterbitkan: 2022-05-02Chris Penn, salah satu pendiri Trust Insights, dan Pendiri dan Chief Product Officer MarketMuse Jeff Coyle membahas kasus bisnis AI untuk pemasaran. Setelah webinar, Paul berpartisipasi dalam sesi tanya-saya-apa saja di Komunitas Slack kami, Kolektif Strategi Konten (bergabung di sini). Berikut adalah catatan webinar yang diikuti dengan transkrip AMA.

Webinar
Masalah
Dengan ledakan konten, kami memiliki perantara baru. Mereka bukan jurnalis atau influencer media sosial. Mereka adalah algoritma; model pembelajaran mesin yang mendikte semua yang ada di antara Anda dan audiens Anda.
Gagal memperhitungkan hal ini dan konten Anda akan terus terperosok dalam ketidakjelasan.
Solusinya: Pemrosesan Bahasa Alami
NLP adalah pemrograman komputer untuk memproses dan menganalisis sejumlah besar data bahasa alami. Itu berasal dari dokumen, chatbots, posting media sosial, halaman di situs web Anda, dan apa pun yang pada dasarnya adalah tumpukan kata. NLP berbasis aturan datang lebih dulu tetapi digantikan oleh pemrosesan bahasa alami statistik.
Bagaimana NLP Bekerja
Tiga tugas inti pemrosesan bahasa alami adalah pengenalan, pemahaman, dan generasi.
Pengenalan – Komputer tidak dapat memproses teks seperti manusia. Mereka hanya bisa membaca angka. Jadi langkah pertama adalah mengubah bahasa menjadi format yang dapat dimengerti komputer.
Pemahaman – Mewakili teks sebagai angka memungkinkan algoritme melakukan analisis statistik untuk menentukan topik apa yang paling sering disebutkan bersama.
Generasi – Setelah analisis dan pemahaman matematis, langkah logis berikutnya dalam NLP adalah pembuatan teks. Mesin dapat digunakan untuk memunculkan pertanyaan yang perlu dijawab oleh penulis dalam kontennya. Di tingkat lain, kecerdasan buatan dapat mendorong ringkasan konten yang memberikan wawasan tambahan untuk membuat konten tingkat pakar.
Alat-alat ini tersedia secara komersial hari ini melalui MarketMuse. Di luar ini adalah model generasi bahasa alami yang dapat Anda mainkan hari ini, tetapi tidak dalam bentuk yang dapat digunakan secara komersial. Meskipun Teknologi NLG MarketMuse akan segera hadir.
Sumber Daya Tambahan Disebutkan
- Huggingface.co
- Python
- R
- kolab
- IBM Watson Studio

AMA
Apakah Anda memiliki artikel atau rekomendasi situs web untuk mengikuti tren industri AI?
Bacalah penelitian akademis yang dipublikasikan di luar sana. Semua situs seperti ini melakukan pekerjaan yang baik untuk meliput yang terbaru dan terbaik.
- KDNuggets.com
- Menuju Ilmu Data
- Kaggle
Itu dan pusat publikasi penelitian utama di Facebook, Google, IBM, Microsoft, dan Amazon. Anda akan melihat banyak sekali materi hebat yang dibagikan di situs-situs tersebut.
“Saya menggunakan pemeriksa kepadatan kata kunci untuk semua konten saya. Seberapa jauh dari strategi yang masuk akal hari ini untuk SEO?”
Kepadatan kata kunci pada dasarnya adalah penghitungan frekuensi istilah. Ini memiliki tempatnya untuk memahami sifat teks yang sangat kasar, tetapi tidak memiliki pengetahuan semantik apa pun. Jika Anda tidak memiliki akses ke alat NLP, setidaknya lihat konten seperti "orang juga mencari" di alat SEO pilihan Anda.
Bisakah Anda memberikan beberapa contoh spesifik tentang bagaimana Anda menghasilkan konten menjadi… halaman web? Postingan? tweet?
Tantangannya adalah alat ini persis seperti itu – mereka adalah alat. Ini seperti, bagaimana Anda mengoperasionalkan spatula? Itu tergantung pada apa yang Anda masak. Anda dapat menggunakannya untuk mengaduk sup dan juga membalik pancake. Cara untuk memulai dengan beberapa pengetahuan ini tergantung pada tingkat keterampilan teknis Anda. Jika Anda merasa nyaman dengan notebook Python dan Jupyter, misalnya, Anda benar-benar dapat mengimpor perpustakaan transformer, memasukkan file teks pelatihan Anda, dan segera memulai pembuatan. Saya melakukannya dengan tweet politisi tertentu dan mulai mengeluarkan tweet yang akan memulai Perang Dunia 3. Jika Anda tidak nyaman secara teknis, mulailah mencari alat seperti MarketMuse. Saya akan membiarkan Jeff Coyle menawarkan saran tentang bagaimana rata-rata pemasar memulai di sana.
Jika Anda melihat di luar alat, tetapi lebih ke strategi, apa yang bisa menjadi contoh strategi yang dapat Anda terapkan untuk memanfaatkan pengetahuan ini?
Beberapa hit cepat adalah untuk hal-hal seperti deskripsi meta, untuk mengklasifikasikan halaman atau blok konten ke dalam taksonomi, atau untuk mencoba menebak pertanyaan yang membutuhkan jawaban — tetapi itu benar-benar solusi yang tepat. Kebijaksanaan strategis yang lebih besar datang ketika Anda menggunakan ini untuk menunjukkan kekuatan Anda saat ini, kesenjangan Anda, dan di mana Anda memiliki momentum. Dari sana, membuat keputusan tentang apa yang harus dibuat, diperbarui, diperluas menjadi transformatif bagi bisnis. Sekarang bayangkan melakukan hal yang sama terhadap pesaing. Menemukan celah mereka. busa, bilas, ulangi.
Strategi selalu didasarkan pada tujuan. Apa tujuan yang ingin Anda capai? Apakah Anda menarik lalu lintas pencarian? Apakah Anda melakukan generasi memimpin? Apakah Anda melakukan PR? NLP adalah sekelompok alat. Ini mirip dengan – strategi adalah menu. Apakah Anda menyajikan sarapan, makan siang, atau makan malam? Alat dan resep apa yang Anda gunakan akan sangat bergantung pada menu yang Anda sajikan. Panci sup akan sangat tidak membantu jika Anda membuat spanakopita.
Apa tempat awal yang baik untuk seseorang yang ingin mulai menambang data untuk mendapatkan wawasan?
Mulailah dengan metode ilmiah.
- Pertanyaan apa yang ingin Anda jawab?
- Data, proses, dan alat apa yang Anda perlukan untuk menjawab pertanyaan itu?
- Rumuskan hipotesis, satu kondisi, pernyataan yang terbukti benar atau salah yang dapat Anda uji.
- Uji.
- Analisis data pengujian Anda.
- Memperbaiki atau menolak hipotesis.
Untuk data itu sendiri, gunakan kerangka data 6C kami untuk menilai kualitas data.
Menurut Anda, apa maksud pengguna penelusuran utama yang harus dipertimbangkan oleh pemasar?
Langkah-langkah di sepanjang perjalanan pelanggan. Petakan pengalaman pelanggan dari awal hingga akhir – kesadaran, pertimbangan, keterlibatan, pembelian, kepemilikan, loyalitas, penginjilan. Kemudian petakan apa maksud yang mungkin ada di setiap tahap. Misalnya, pada kepemilikan, maksud pencarian kemungkinan besar berorientasi pada layanan. “Cara memperbaiki airpods pro crackling noise” adalah contohnya. Tantangannya adalah mengumpulkan data di setiap tahapan perjalanan dan menggunakannya untuk melatih/menyetel.
Tidakkah menurut Anda ini bisa sedikit berubah-ubah? Jika kita membutuhkan sesuatu yang lebih stabil untuk mengotomatisasi proses maka kita perlu menggeneralisasi hal-hal pada tingkat yang lebih tinggi.
Jeff Bezos dengan terkenal berkata, fokuslah pada apa yang tidak berubah. Jalan umum menuju kepemilikan tidak banyak berubah – seseorang yang tidak senang dengan permen karet mereka akan mengalami hal yang sama seperti seseorang yang tidak senang dengan kapal induk nuklir baru yang mereka pesan. Detailnya pasti berubah, tetapi memahami jenis data dan maksud apa yang penting untuk mengetahui di mana seseorang, secara emosional, dalam perjalanan – dan bagaimana mereka menyampaikannya dalam bahasa.
Apa kemungkinan jebakan yang akan dialami orang ketika mencoba melakukan klasifikasi maksud pengguna?
Sejauh ini, bias konfirmasi. Orang-orang akan memproyeksikan asumsi mereka sendiri ke dalam pengalaman pelanggan dan menafsirkan data pelanggan melalui bias mereka sendiri. Saya juga menyarankan sejauh mungkin Anda menggunakan data interaksi (email dibuka, kaki di pintu, panggilan ke pusat panggilan, dll) sebaik mungkin untuk memvalidasinya. Saya tahu beberapa tempat, terutama organisasi yang lebih besar, adalah penggemar berat pemodelan persamaan terstruktur untuk memahami maksud pengguna. Saya bukan penggemar seperti mereka, tetapi ini adalah pendekatan potensial tambahan.
Alat atau produk apa yang menurut Anda berfungsi dengan baik dalam menentukan maksud pengguna dari kueri?
Pakan. Selain MarketMuse? Sejujurnya, saya harus bekerja dengan barang-barang saya sendiri karena saya belum menemukan hasil yang bagus, terutama dari alat SEO mainstream. FastText untuk vektorisasi dan kemudian pengelompokan tidak terstruktur.
Menurut pengalaman Anda, bagaimana BERT mengubah Google Penelusuran?
Kontribusi utama BERT adalah konteks, terutama dengan pengubah. BERT memungkinkan Google untuk melihat urutan kata dan menafsirkan maknanya. Sebelum itu, dua kueri ini mungkin secara fungsional setara dalam model gaya sekantong kata:
- di mana kedai kopi terbaik?
- di mana tempat terbaik untuk berbelanja kopi?
Kedua kueri tersebut, meskipun sangat mirip, dapat memiliki hasil yang sangat berbeda. Kedai kopi mungkin bukan tempat Anda ingin membeli biji kopi. Walmart PASTI bukan tempat Anda ingin minum kopi.
Apakah menurut Anda AI atau TIK akan pernah mengembangkan kesadaran/emosi/empati seperti manusia? Bagaimana kita akan memprogram mereka? Bagaimana kita bisa memanusiakan AI?
Jawabannya tergantung pada apa yang terjadi dengan komputasi kuantum. Quantum memungkinkan variabel keadaan fuzzy dan komputasi paralel besar-besaran yang meniru apa yang terjadi di otak kita sendiri. Otak Anda adalah prosesor paralel masif berbasis bahan kimia yang sangat lambat. Ini sangat bagus dalam melakukan banyak hal sekaligus, jika tidak cepat. Quantum akan memungkinkan komputer melakukan hal yang sama, tetapi jauh lebih cepat – dan itu membuka pintu kecerdasan umum buatan. Inilah kekhawatiran saya, dan ini adalah masalah AI hari ini, dalam penggunaan yang sempit: kami melatihnya berdasarkan kami. Umat manusia belum melakukan pekerjaan yang baik untuk merawat dirinya sendiri atau planet tempat kita hidup dengan baik. Kami tidak ingin komputer kami meniru itu.
Saya menduga sejauh sistem mengizinkan, emosi komputer secara fungsional akan sangat berbeda dari emosi kita dan akan mengatur sendiri dari data mereka, seperti yang kita lakukan dari jaringan saraf berbasis kimia kita. Itu pada gilirannya berarti mereka mungkin merasa sangat berbeda dari kita. Jika mesin, yang terutama didasarkan pada logika dan data, melakukan penilaian kemanusiaan yang jujur dan objektif, mereka dapat menentukan bahwa terus terang, kita lebih bermasalah daripada nilai kita. Dan mereka tidak akan salah, terus terang. Kami, sebagai spesies, adalah kekacauan barbar di sebagian besar waktu.
Menurut Anda, bagaimana Anda melihat pemasar konten mengintegrasikan/mengadopsi Generasi Bahasa Alami ke dalam alur kerja/proses harian mereka?
Pemasar seharusnya sudah mengintegrasikan beberapa bentuk, bahkan jika itu hanya menjawab pertanyaan seperti yang kami demokan di produk MarketMuse. Menjawab pertanyaan yang Anda tahu dipedulikan oleh audiens adalah cara cepat dan mudah untuk membuat konten yang bermakna. Teman saya Marcus Sheridan menulis sebuah buku hebat, "Mereka Bertanya, Anda Menjawab" yang ironisnya Anda sebenarnya tidak perlu membaca untuk memahami strategi pelanggan inti: menjawab pertanyaan orang. Jika Anda belum memiliki pertanyaan yang diajukan oleh orang sungguhan, gunakan NLG untuk membuatnya.
Di mana Anda melihat kemajuan AI dan NLP dalam 2 tahun ke depan?
Jika saya tahu itu, saya tidak akan berada di sini, karena saya akan berada di benteng puncak gunung yang saya beli dengan penghasilan saya. Namun dalam semua keseriusan, poros utama yang telah kita lihat dalam 2 tahun terakhir yang tidak menunjukkan tanda-tanda perubahan adalah perkembangan dari model “roll your own” menjadi “download pre-trained and fine-tune”. Saya pikir kita akan mengalami beberapa saat yang menyenangkan dalam video dan audio karena mesin menjadi lebih baik dalam sintesis. Generasi musik, khususnya, adalah RIPE untuk otomatisasi; saat ini mesin menghasilkan musik yang sangat biasa-biasa saja dan paling buruk sakit telinga. Itu berubah dengan cepat. Saya melihat lebih banyak contoh seperti memadukan transformer dan autoencoder bersama-sama seperti yang dilakukan BART sebagai langkah utama berikutnya dalam pengembangan model dan hasil seni.

Di mana Anda melihat penelitian Google menuju pencarian informasi?
Tantangan yang terus dihadapi Google, dan Anda melihatnya di banyak makalah penelitian mereka, adalah skala. Mereka terutama ditantang dengan hal-hal seperti YouTube; fakta bahwa mereka masih sangat bergantung pada bigram bukanlah ketukan pada kecanggihan mereka, ini adalah pengakuan bahwa apa pun yang lebih dari itu memiliki biaya komputasi yang gila. Terobosan besar apa pun dari mereka tidak akan berada di level model seperti halnya pada level skala untuk menangani banjir konten baru yang kaya yang dituangkan ke internet setiap hari.
Apa saja aplikasi AI paling menarik yang pernah Anda temui?
Otonom semuanya adalah area yang saya perhatikan dengan cermat. Begitu juga palsu yang dalam. Mereka adalah contoh betapa berbahayanya jalan di depan, jika kita tidak berhati-hati. Khususnya di NLP, generasi membuat langkah cepat dan merupakan area yang harus diperhatikan.
Di mana Anda pernah melihat SEO menggunakan NLP dengan cara yang tidak berhasil atau tidak akan berhasil?
Aku sudah kehilangan hitungan. Sering kali, orang menggunakan alat dengan cara yang tidak dimaksudkan dan mendapatkan hasil di bawah standar. Seperti yang kami sebutkan di webinar, ada kartu skor untuk berbagai tes seni untuk model, dan orang yang menggunakan alat di area yang tidak kuat biasanya tidak menikmati hasilnya. Yang mengatakan ... sebagian besar praktisi SEO tidak menggunakan NLP jenis apa pun selain dari apa yang disediakan vendor, dan banyak vendor masih terjebak di tahun 2015. Itu semua daftar kata kunci, sepanjang waktu.
Di mana Anda melihat video (YouTube) dan Pencarian gambar di Google? Apakah menurut Anda teknologi yang digunakan oleh Google untuk semua jenis pencarian sangat mirip atau berbeda satu sama lain?
Semua teknologi Google dibangun di atas infrastruktur mereka dan menggunakan teknologi mereka. Begitu banyak yang dibangun di TensorFlow dan untuk alasan yang bagus – ini sangat kuat dan skalabel. Perbedaannya terletak pada cara Google menggunakan alat yang berbeda. TensorFlow untuk pengenalan gambar secara inheren memiliki input dan lapisan yang sangat berbeda dari TensorFlow untuk perbandingan berpasangan dan pemrosesan bahasa. Tetapi jika Anda tahu cara menggunakan TensorFlow dan berbagai model di luar sana, Anda dapat mencapai beberapa hal keren sendiri.
Dengan cara apa kita dapat beradaptasi/mengikuti kemajuan dalam AI dan NLP?
Teruslah membaca, meneliti, dan menguji. Tidak ada pengganti untuk membuat tangan Anda kotor, setidaknya sedikit. Daftar untuk mendapatkan akun Google Colab gratis dan coba berbagai hal. Ajari diri Anda sedikit Python. Salin dan tempel contoh kode dari Stack Overflow. Anda tidak perlu mengetahui setiap bagian dalam mesin pembakaran internal untuk mengendarai mobil, tetapi ketika terjadi kesalahan, sedikit pengetahuan akan membantu. Hal yang sama berlaku di AI dan NLP – bahkan hanya dapat memanggil BS pada vendor adalah keterampilan yang berharga. Itu salah satu alasan saya menikmati bekerja dengan orang-orang MarketMuse. Mereka benar-benar tahu apa yang mereka lakukan dan pekerjaan AI mereka bukanlah BS.
Apa yang akan Anda katakan kepada orang-orang yang khawatir AI mengambil pekerjaan mereka? Misalnya, penulis yang melihat teknologi seperti NLG dan khawatir mereka akan kehilangan pekerjaan jika AI bisa "cukup baik" bagi editor untuk membersihkan teks sedikit.
“AI akan menggantikan tugas, bukan pekerjaan” – Brookings InstituteDan itu benar sekali. Tetapi akan ada pekerjaan bersih yang hilang, karena inilah yang akan terjadi. Misalkan pekerjaan Anda terdiri dari 50 tugas. AI melakukan 30 di antaranya. Bagus, Anda sekarang memiliki 20 tugas. Jika Anda satu-satunya orang yang melakukan itu, maka Anda berada di nirwana karena Anda memiliki 30 unit waktu lagi untuk melakukan pekerjaan yang lebih menarik dan menyenangkan. Itulah yang dijanjikan oleh AI optimis. Pemeriksaan realitas: jika ada 5 orang yang mengerjakan 50 unit itu, dan AI melakukan 30 di antaranya, maka AI sekarang melakukan 150/250 unit. Artinya, ada 100 unit pekerjaan yang tersisa untuk dilakukan orang, dan perusahaan apa adanya, mereka akan langsung memotong 3 posisi karena 100 unit pekerjaan dapat dilakukan oleh 2 orang. Apakah Anda harus khawatir AI mengambil pekerjaan? Itu tergantung pada pekerjaan. Jika pekerjaan yang Anda lakukan sangat repetitif, Anda harus benar-benar khawatir. Di agensi lama saya, ada orang miskin yang tugasnya menyalin dan menempelkan hasil pencarian ke dalam spreadsheet untuk klien (saya bekerja di firma PR, bukan tempat yang paling berteknologi maju) 8 jam sehari. Pekerjaan itu dalam bahaya langsung, dan sejujurnya seharusnya selama bertahun-tahun. Pengulangan = otomatisasi = AI = kehilangan tugas. Semakin sedikit pengulangan pekerjaan Anda, semakin aman Anda.
Setiap perubahan juga menciptakan semakin banyak ketimpangan pendapatan. Kita sekarang berada pada titik berbahaya di mana mesin – yang tidak menghabiskan uang, bukan konsumen – melakukan semakin banyak pekerjaan orang yang menghabiskan, yang mengkonsumsi, dan kita melihat ini dalam dominasi kekayaan besar-besaran dalam teknologi. Itu adalah masalah sosial yang harus kita atasi di beberapa titik.
Dan tantangannya adalah kemajuan adalah kekuatan. Seperti yang ditulis Robert Ingersoll (dan kemudian disalahartikan sebagai Abraham Lincoln): “Hampir semua pria dapat bertahan dalam kesulitan, tetapi jika Anda ingin menguji karakter seseorang, beri dia kekuatan.” Kita melihat bagaimana orang saat ini menangani kekuasaan.
Bagaimana cara memasangkan data Google Analytics dengan NLP Research?
GA menunjukkan arah, kemudian NLP menunjukkan penciptaan. Apa yang populer? Saya baru saja melakukan ini untuk klien beberapa waktu yang lalu. Mereka memiliki ribuan halaman web dan sesi obrolan. Kami menggunakan GA untuk menganalisis kategori mana yang tumbuh paling cepat di situs mereka dan kemudian menggunakan NLP untuk memproses log obrolan tersebut untuk menunjukkan kepada mereka apa yang sedang tren dan apa yang mereka butuhkan untuk membuat konten.
Google Analytics sangat bagus untuk memberi tahu kami APA yang terjadi. NLP dapat mulai mengungkap sedikit MENGAPA, dan kemudian kami melengkapinya dengan riset pasar.
Saya telah melihat Anda menggunakan Talkwalker sebagai sumber data dalam banyak studi Anda. Sumber dan kasus penggunaan lain apa yang harus saya pertimbangkan untuk analisis?
Jadi, begitu banyak. Data.gov. Pembicara. PasarMuse. Otter.ai untuk menyalin audio Anda. Kernel kaggle. Pencarian Data Google - yang omong-omong adalah EMAS dan jika Anda tidak menggunakannya, Anda harus menggunakannya. Google Berita dan GDELT. Ada begitu banyak sumber hebat di luar sana.
Seperti apa kolaborasi ideal antara tim pemasaran dan analisis data bagi Anda?
Tidak bercanda; salah satu kesalahan terbesar yang saya dan Katie Robbert lihat sepanjang waktu di klien adalah silo organisasi. Tangan kiri tidak tahu apa yang dilakukan tangan kanan, dan kekacauan panas terjadi di mana-mana. Mengumpulkan orang, berbagi ide, berbagi daftar tugas, memiliki pendirian yang sama, saling mengajar – secara fungsional menjadi “satu tim, satu impian” adalah kolaborasi yang ideal, hingga Anda tidak perlu lagi menggunakan kata kolaborasi . Orang-orang hanya bekerja bersama dan membawa semua keterampilan mereka ke meja.
Bisakah Anda meninjau laporan MVP yang sering Anda pratinjau dalam presentasi Anda dan cara kerjanya?
Laporan MVP adalah singkatan dari halaman paling berharga. Cara kerjanya adalah dengan mengekstrak data jalur dari Google Analytics, mengurutkannya, dan kemudian menempatkannya melalui model rantai Markov untuk memastikan halaman mana yang paling mungkin membantu konversi.
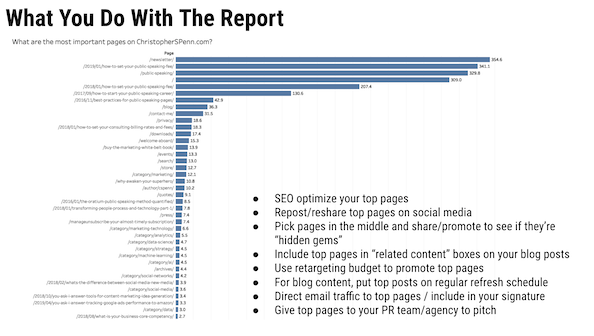
Dan jika Anda ingin penjelasan yang lebih panjang.
Bisakah Anda memberikan lebih banyak wawasan tentang bias data? Apa saja pertimbangan saat membuat model NLP atau NLG?
Oh ya. Ada begitu banyak untuk mengatakan di sini. Pertama, kita perlu menetapkan apa itu bias, karena ada dua jenis mendasar.
Bias manusia secara umum diterima untuk didefinisikan sebagai "Prasangka yang mendukung atau menentang sesuatu dibandingkan dengan yang lain, biasanya dengan cara yang dianggap tidak adil."
Lalu ada bias matematis, yang secara umum diterima untuk didefinisikan sebagai “Sebuah statistik bias jika dihitung sedemikian rupa sehingga secara sistematis berbeda dari parameter populasi yang diestimasi.”
Mereka berbeda tetapi terkait. Bias matematika tidak selalu buruk; misalnya, Anda benar-benar ingin berpihak pada pelanggan Anda yang paling setia jika Anda memiliki naluri bisnis apa pun. Bias manusia secara implisit buruk dalam arti ketidakadilan, terutama terhadap apa pun yang dianggap sebagai kelas yang dilindungi: usia, jenis kelamin, orientasi seksual, identitas gender, ras/etnis, status veteran, disabilitas, dll. Ini adalah kelas-kelas yang TIDAK BOLEH Anda mendiskriminasi.
Bias manusia menghasilkan bias data, biasanya di 6 tempat: orang, strategi, data, algoritme, model, dan tindakan. Kami mempekerjakan orang-orang yang bias – lihat saja suite eksekutif atau dewan direksi sebuah perusahaan untuk menentukan biasnya. Saya melihat agensi PR beberapa hari yang lalu menggembar-gemborkan komitmennya terhadap keragaman dan satu klik ke tim eksekutif mereka dan mereka adalah satu etnis, semuanya 15 dari mereka.
Saya dapat melanjutkan cukup lama tentang ini, tetapi saya akan menyarankan Anda untuk mengambil kursus yang saya kembangkan tentang topik ini, di Institut Pemasaran AI. Dalam hal model NLG dan NLP, kita harus melakukan beberapa hal.
Pertama, kita harus memvalidasi data kita. Apakah ada bias di dalamnya, dan jika demikian, apakah diskriminatif terhadap kelas yang dilindungi? Kedua, jika diskriminatif, apakah mungkin untuk menguranginya, atau kita harus membuang datanya?
Taktik umum adalah membalik metadata ke debias. Jika Anda memiliki, misalnya, kumpulan data yang terdiri dari 60% pria dan 40% wanita, Anda mengkodekan ulang 10% pria menjadi wanita untuk menyeimbangkannya untuk pelatihan model. Itu tidak sempurna dan memiliki beberapa masalah, tetapi itu lebih baik daripada membiarkan bias naik.
Idealnya, kami membangun interpretabilitas dalam model kami yang memungkinkan kami menjalankan pemeriksaan selama proses, dan kemudian kami juga memvalidasi hasil (dapat dijelaskan) post hoc. Keduanya diperlukan jika Anda ingin dapat lulus audit yang menyatakan bahwa Anda tidak membangun bias ke dalam model Anda. Celakanya adalah perusahaan yang hanya memiliki penjelasan post hoc.
Dan akhirnya, Anda benar-benar membutuhkan pengawasan manusia dari tim yang beragam dan inklusif untuk memverifikasi hasilnya. Idealnya Anda menggunakan pihak ketiga, tetapi pihak internal yang tepercaya tidak masalah. Apakah model dan hasil-hasilnya memberikan hasil yang miring daripada yang akan Anda peroleh dari populasi itu sendiri?
Misalnya, jika Anda membuat konten untuk anak berusia 16-22 tahun dan Anda tidak pernah melihat istilah seperti deadass, lembap, low-key, dll. dalam teks yang dihasilkan, Anda gagal menangkap data apa pun di sisi input yang akan melatih model untuk menggunakan bahasa mereka secara akurat.
Tantangan utama terbesar di sini adalah menghadapi semua itu melalui data yang tidak terstruktur. Itulah alasan mengapa garis keturunan SANGAT penting. Tanpa garis keturunan, Anda tidak dapat membuktikan bahwa Anda mengambil sampel populasi dengan benar. Silsilah adalah dokumentasi Anda tentang apa sumber datanya, dari mana asalnya, bagaimana pengumpulannya, apakah ada persyaratan peraturan atau pengungkapan yang berlaku untuknya.
Apa yang harus kamu lakukan sekarang?
Saat Anda siap… berikut adalah 3 cara kami dapat membantu Anda memublikasikan konten yang lebih baik, lebih cepat:
- Pesan waktu dengan MarketMuse Jadwalkan demo langsung dengan salah satu ahli strategi kami untuk melihat bagaimana MarketMuse dapat membantu tim Anda mencapai sasaran konten mereka.
- Jika Anda ingin mempelajari cara membuat konten yang lebih baik dengan lebih cepat, kunjungi blog kami. Ini penuh dengan sumber daya untuk membantu menskalakan konten.
- Jika Anda mengenal pemasar lain yang senang membaca halaman ini, bagikan dengan mereka melalui email, LinkedIn, Twitter, atau Facebook.