
Mengidentifikasi Atribut Subyektif Entitas
Diterbitkan: 2022-05-13Mengidentifikasi Atribut Subyektif UGC Entitas
Paten yang diberikan baru-baru ini adalah tentang mengidentifikasi atribut subjektif entitas.
Saya belum melihat paten tentang atribut subjektif entitas atau tanggapan terhadap entitas tersebut.
Aspek penting dari itu adalah bahwa itu adalah konten yang dibuat pengguna.
Kami diberitahu bahwa konten yang dibuat pengguna (UGC) menjadi lebih umum di Web karena meningkatnya popularitas jejaring sosial, blog, situs web ulasan, dll.
Kami sering melihat konten yang dibuat pengguna dalam bentuk komentar, seperti:
- Komentar oleh pengguna pertama tentang konten yang dibagikan oleh pengguna kedua dalam jejaring sosial
- Komentar pengguna sebagai tanggapan atas artikel di blog kolumnis
- Komentar dari klip video yang diposting di situs web hosting konten
- Ulasan (seperti produk, film)
- Tindakan (seperti Suka!, Tidak Suka!, +1, berbagi, mem-bookmark, membuat daftar putar, dll.)
- Begitu seterusnya
Di bawah paten ini, cara untuk mengidentifikasi dan memprediksi atribut subjektif untuk entitas (seperti klip media, gambar, artikel surat kabar, entri blog, orang, organisasi, bisnis komersial, dll.) disediakan.
Ini dimulai dengan:
- Mengidentifikasi set pertama atribut subjektif untuk entitas pertama berdasarkan reaksi terhadap entitas pertama (seperti komentar di situs web, demonstrasi persetujuan entitas pertama (seperti “Suka!, dll.)
- Berbagi entitas pertama
- Menandai entitas pertama
- Menambahkan entitas pertama ke daftar putar
- Melatih pengklasifikasi (seperti mesin vektor pendukung, AdaBoost, jaringan saraf, pohon keputusan pada satu set pemetaan input-output, di mana set pemetaan input-output terdiri dari pemetaan input-output yang inputnya Menyediakan vektor fitur untuk entitas pertama, yang outputnya didasarkan pada set pertama atribut subjektif
- Memberikan vektor fitur untuk entitas kedua ke pengklasifikasi terlatih untuk mendapatkan set kedua atribut subjektif untuk entitas kedua
Memori dan prosesor disediakan untuk mengidentifikasi dan memprediksi atribut subjektif untuk entitas.
Media penyimpanan yang dapat dibaca komputer memiliki instruksi yang menyebabkan sistem komputer melakukan operasi termasuk:
- Mengidentifikasi set pertama atribut subjektif untuk entitas pertama berdasarkan reaksi terhadap entitas pertama
- Memperoleh vektor fitur pertama untuk entitas pertama
- Melatih pengklasifikasi pada satu set pemetaan input-output, di mana set pemetaan input-output terdiri dari pemetaan input-output yang inputnya didasarkan pada vektor fitur pertama dan outputnya didasarkan pada set pertama atribut subjektif
- Memperoleh vektor fitur kedua untuk entitas kedua
- Memberikan kepada pengklasifikasi, setelah pelatihan, vektor fitur kedua untuk mendapatkan set kedua atribut subjektif untuk entitas kedua
Paten untuk mengidentifikasi atribut subjektif untuk entitas ini = ditemukan di:
Mengidentifikasi atribut subjektif dengan analisis sinyal kurasi
Penemu: Hrishikesh Aradhye dan Sanketh Shetty
Penerima tugas: Google LLC
Paten AS: 11.328.218
Diberikan: 10 Mei 2022
Diarsipkan: 6 November 2017
Abstrak:
Sistem dan metode untuk mengidentifikasi dan memprediksi atribut subjektif untuk entitas (seperti klip media, film, acara televisi, gambar, artikel surat kabar, entri blog, orang, organisasi, bisnis komersial, dll.) diungkapkan.
Dalam satu aspek, atribut subjektif untuk item media pertama diidentifikasi berdasarkan reaksi terhadap item media pertama, dan skor relevansi untuk kualitas pribadi dengan tentang item media pertama ditentukan.
Pengklasifikasi dilatih menggunakan (i) input pelatihan yang terdiri dari serangkaian fitur untuk item media pertama dan output target untuk input pelatihan, output target yang terdiri dari skor relevansi masing-masing untuk atribut subjektif dari item media pertama.
Mengidentifikasi Dan Memprediksi Atribut Subyektif Untuk Entitas
Cara untuk mengidentifikasi dan memprediksi atribut subjektif untuk entitas (seperti klip media, gambar, artikel surat kabar, entri blog, orang, organisasi, bisnis komersial, dll.).
Atribut subjektif (seperti "imut", "lucu", "mengagumkan", dll.) ditentukan, dan atribut subjektif untuk entitas tertentu diidentifikasi berdasarkan reaksi pengguna terhadap entitas tersebut, seperti:
- Komentar di situs web
- Suka!
- Berbagi entitas pertama dengan pengguna lain
- Mem-boomark entitas pertama
- Menambahkan entitas pertama ke daftar putar
- Dll
Skor Relevansi Untuk Atribut Subyektif Ditentukan Tentang Entitas
Jika atribut subjektif "imut" muncul dalam proporsi komentar yang signifikan untuk klip video, maka "imut" dapat diberi skor relevansi tinggi.
Entitas tersebut kemudian dikaitkan dengan atribut subjektif yang diidentifikasi dan skor relevansi (seperti melalui tag yang diterapkan ke entitas, melalui entri dalam tabel database relasional, dll.).
Prosedur di atas dilakukan untuk setiap entitas dalam kumpulan entitas tertentu (seperti klip video dalam repositori klip video, dll.), dan pemetaan terbalik dari atribut subjektif ke entitas dalam grup dihasilkan berdasarkan kualitas pribadi dan skor relevansi .
Pemetaan terbalik kemudian dapat digunakan untuk mengidentifikasi semua entitas dalam himpunan yang cocok dengan atribut subjektif tertentu (seperti semua entitas yang telah dikaitkan dengan atribut subjektif "lucu", dll.), sehingga memungkinkan:
- Pengambilan cepat entitas yang relevan untuk memproses pencarian kata kunci
- Mengisi daftar putar
- Menyampaikan iklan
- Menghasilkan set pelatihan untuk pengklasifikasi
- Begitu seterusnya
Pengklasifikasi (seperti mesin vektor dukungan [SVM], AdaBoost, jaringan saraf, pohon keputusan, dll.) dilatih dengan memberikan satu set contoh pelatihan, di mana input untuk contoh pelatihan terdiri dari vektor fitur yang diperoleh dari entitas tertentu (seperti vektor fitur untuk klip video.
Ini mungkin berisi nilai numerik tentang:
- Warna
- Tekstur
- Intensitas
- Tag metadata yang terkait dengan klip video
- Dll
Outputnya memiliki skor relevansi untuk setiap atribut subjektif dalam kosakata untuk entitas tertentu.
Pengklasifikasi terlatih kemudian dapat memprediksi atribut subjektif untuk entitas yang tidak ada dalam set pelatihan (seperti klip video yang baru diunggah, artikel berita yang belum menerima komentar, dll.).
Paten ini dapat mengklasifikasikan entitas menurut atribut subjektif seperti "lucu", "imut", dll. berdasarkan reaksi pengguna terhadap entitas tersebut.
Paten ini dapat meningkatkan kualitas deskripsi entitas, seperti tag untuk klip video, meningkatkan kualitas pencarian, dan penargetan iklan.
Arsitektur Sistem Untuk Mengidentifikasi Atribut Subyektif
Arsitektur sistem meliputi:
- Mesin server
- Toko entitas
- Mesin klien terhubung ke jaringan
Jaringan tersebut dapat bersifat publik (seperti Internet), jaringan pribadi (seperti jaringan area lokal (LAN) atau jaringan area luas (WAN)), atau kombinasinya.
Mesin klien mungkin terminal nirkabel (smartphone, dll), komputer pribadi (PC), laptop, komputer tablet, atau perangkat komputasi atau komunikasi lainnya.
Mesin klien dapat menjalankan sistem operasi (OS) yang mengelola perangkat keras dan perangkat lunak dari mesin klien.
Peramban (tidak ditampilkan) dapat berjalan pada mesin klien (seperti pada OS mesin klien).
Browser mungkin merupakan browser web yang dapat mengakses halaman web dan konten yang disajikan oleh server web.
Mesin klien juga dapat mengunggah:
- Halaman web
- Klip media
- entri blog
- tautan ke artikel
- Begitu seterusnya
Mesin server termasuk server web dan manajer atribut subjektif. Server web dan manajer atribut emosional dapat berjalan di perangkat yang berbeda.
Penyimpanan entitas adalah penyimpanan persisten yang mampu menyimpan entitas seperti klip media (seperti klip video, klip audio, klip yang berisi video dan audio, gambar, dll.) dan jenis item konten lainnya (seperti halaman web, teks- dokumen berbasis, ulasan restoran, ulasan film, dll.), serta struktur data untuk menandai, mengatur, dan mengindeks entitas.
Penyimpanan entitas dapat di-host oleh perangkat penyimpanan, seperti memori utama, disk berbasis penyimpanan magnetik atau optik, kaset atau hard drive, NAS, SAN, dll.
Penyimpanan entitas mungkin di-host oleh server file yang terhubung ke jaringan. Sebaliknya, dalam implementasi lain, penyimpanan entitas dapat di-host oleh beberapa jenis penyimpanan persisten lainnya seperti mesin server atau mesin berbeda yang digabungkan ke mesin server melalui jaringan.
Entitas yang disimpan di penyimpanan entitas dapat menyertakan konten buatan pengguna yang diunggah oleh mesin klien dan dapat mencakup konten yang disediakan oleh penyedia layanan seperti:
- Organisasi berita
- penerbit
- Perpustakaan
- Segera
Server dapat menyajikan halaman web dan konten dari toko entitas ke klien.
Manajer atribut subjektif:
- Mengidentifikasi atribut subjektif untuk entitas berdasarkan reaksi pengguna (seperti komentar, Suka!, berbagi, bookmark, daftar putar, dll.)
- Menentukan skor relevansi untuk atribut subjektif tentang entitas
- Mengaitkan atribut subjektif dan skor relevansi dengan entitas
- Ekstrak fitur seperti fitur gambar seperti warna, tekstur, dan intensitas; fitur audio seperti amplitudo, rasio koefisien spektral; fitur tekstual seperti frekuensi kata, panjang kalimat rata-rata, parameter pemformatan; metadata yang terkait dengan entitas; dll.) dari entitas untuk menghasilkan vektor fitur
- Melatih pengklasifikasi berdasarkan vektor fitur dan skor relevansi atribut subjektif
- Menggunakan pengklasifikasi terlatih untuk memprediksi atribut subjektif untuk entitas baru berdasarkan vektor fitur dari entitas baru
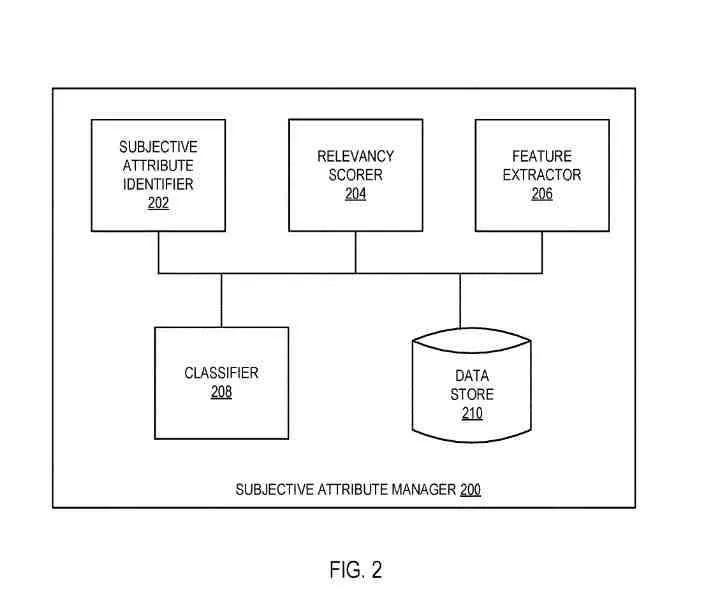
Manajer Atribut Subyektif
Manajer atribut subjektif mungkin sama dengan manajer atribut subjektif dan dapat mencakup:
- Pengidentifikasi atribut subjektif
- Pencetak relevansi
- Ekstraktor fitur
- Penggolong
- Penyimpanan data
.
Komponen dapat digabungkan atau dipisahkan menjadi detail lebih lanjut.
Penyimpanan data mungkin sama dengan penyimpanan entitas atau penyimpanan data yang berbeda (seperti buffer sementara atau penyimpanan data permanen) untuk menampung kosakata atribut pribadi, entitas yang akan diproses, vektor fitur yang terkait dengan entitas, atribut pribadi dan skor relevansi yang terkait dengan entitas, atau beberapa kombinasi dari data ini.
Datastore dapat di-host oleh perangkat penyimpanan, seperti memori utama, disk berbasis penyimpanan magnetik atau optik, kaset atau hard drive, dll.
Manajer atribut subjektif memberi tahu pengguna tentang jenis informasi yang disimpan di penyimpanan data dan penyimpanan entitas dan memungkinkan pengguna untuk memilih agar informasi tersebut tidak dikumpulkan dan dibagikan dengan manajer atribut subjektif.
Pengidentifikasi Atribut Subyektif
Pengidentifikasi atribut pribadi mengidentifikasi atribut subjektif untuk entitas berdasarkan reaksi pengguna terhadap entitas.
Pengidentifikasi atribut pribadi dapat mengidentifikasi atribut subjektif melalui pemrosesan teks komentar pengguna ke entitas yang diposting oleh pengguna di situs web jejaring sosial.
Pengidentifikasi atribut subjektif dapat mengidentifikasi atribut subjektif untuk entitas berdasarkan jenis reaksi pengguna lainnya terhadap entitas, seperti:
- 'Suka!' atau 'Tidak suka!'
- Berbagi entitas
- Menandai entitas
- Menambahkan entitas ke daftar putar
- Begitu seterusnya
Pengidentifikasi atribut pribadi dapat menerapkan ambang batas untuk menentukan atribut mana yang terkait dengan entitas (seperti atribut subjektif harus muncul setidaknya dalam N komentar, dll.).
Pencetak relevansi menentukan skor relevansi untuk atribut subjektif tentang entitas.
Misalnya, ketika pengidentifikasi atribut subjektif telah mengidentifikasi atribut subjektif "imut", "lucu", dan "mengagumkan" berdasarkan komentar ke klip media yang diposting di situs jejaring sosial, pencetak relevansi dapat menentukan skor relevansi untuk masing-masing dari tiga subjektif ini. atribut berdasarkan:
- Frekuensi atribut subjektif ini muncul dalam komentar
- Pengguna tertentu yang memberikan atribut subjektif
- Begitu seterusnya
Misalnya, jika ada 40 komentar dan "imut" muncul dalam 20 kata dan "mengagumkan" muncul dalam 8 komentar, maka "imut" dapat diberi skor relevansi yang lebih tinggi dari "mengagumkan".
Skor relevansi dapat diberikan berdasarkan proporsi komentar yang menampilkan atribut subjektif (seperti skor 0,5 untuk "imut" dan skor 0,2 untuk "mengagumkan", dll.).
Pencetak skor relevansi hanya dapat menyimpan k atribut subjektif yang paling relevan dan membuang atribut pribadi lainnya.
Misalnya, pengidentifikasi atribut pribadi mengidentifikasi tujuh atribut emosional yang muncul dalam komentar pengguna setidaknya tiga kali. Dalam hal ini, skor relevansi dapat, misalnya, hanya mempertahankan lima atribut subjektif dengan skor relevansi tertinggi dan membuang dua atribut emosional lainnya (seperti dengan menetapkan skor relevansinya ke nol, dll.).
Skor relevansi adalah bilangan asli antara 0,0 dan 1,0 inklusif.
Ekstraktor fitur memperoleh vektor fitur untuk entitas menggunakan teknik seperti:
- Analisis komponen utama
- Penyematan setengah pasti
- isomaps
- Kuadrat terkecil parsial
- Begitu seterusnya
Perhitungan yang terkait dengan mengekstraksi fitur suatu entitas dilakukan oleh ekstraktor fitur itu sendiri.

Dalam beberapa aspek lain, perhitungan ini dilakukan oleh entitas lain, seperti perpustakaan yang dapat dieksekusi dari:
- Rutinitas pemrosesan gambar yang dihosting oleh mesin server [tidak digambarkan dalam Gambar]
- Rutinitas pemrosesan audio
- Rutinitas pemrosesan teks
- Dll
Hasilnya diberikan ke ekstraktor fitur.
Pengklasifikasi adalah mesin pembelajaran (seperti mesin vektor pendukung [SVM], AdaBoost, jaringan saraf, pohon keputusan, dll.) yang menerima sebagai input vektor fitur yang terkait dengan entitas dan menghasilkan skor relevansi (seperti angka aktual antara 0 dan 1 inklusif, dll.) untuk setiap atribut subjektif dari kosakata atribut pribadi.
Classifier terdiri dari satu classifier.
Pengklasifikasi dapat mencakup beberapa pengklasifikasi (seperti pengklasifikasi untuk setiap atribut subjektif dalam kosakata atribut pribadi, dll.).
Serangkaian contoh positif dan kriteria negatif dikumpulkan untuk setiap atribut subjektif dalam kosakata atribut pribadi.
Kumpulan contoh positif untuk atribut subjektif dapat mencakup vektor fitur untuk entitas yang terkait dengan atribut pribadi tertentu.
Kumpulan contoh negatif untuk atribut subjektif dapat mencakup vektor fitur untuk entitas yang belum dikaitkan dengan atribut pribadi tertentu.
Ketika kumpulan contoh positif dan kumpulan kriteria negatif tidak sama ukurannya, kumpulan yang lebih luas dapat diambil sampelnya agar sesuai dengan ukuran kelompok yang lebih kecil.
Setelah pelatihan, pengklasifikasi dapat memprediksi atribut subjektif untuk entitas lain yang tidak ada dalam set pelatihan dengan menyediakan vektor fitur untuk entitas ini sebagai input ke pengklasifikasi.
Seperangkat atribut subjektif dapat diperoleh dari keluaran pengklasifikasi dengan memasukkan semua atribut emosional dengan skor relevansi bukan nol. Sekelompok poin subjektif dapat diperoleh dengan menerapkan ambang batas paling kecil untuk skor numerik (dengan mempertimbangkan semua atribut pribadi yang memiliki skor setidaknya, katakanlah, 0,2 sebagai anggota himpunan).
Mengidentifikasi Atribut Subyektif Entitas
Metode ini dilakukan dengan memproses logika yang dapat terdiri dari perangkat keras (sirkuit, logika khusus, dll.), Perangkat lunak (seperti dijalankan pada sistem komputer tujuan umum atau mesin khusus), atau keduanya.
Metode ini dilakukan oleh mesin server, sementara beberapa implementasi lain mungkin dilakukan oleh perangkat lain.
Berbagai komponen manajer atribut subjektif dapat berjalan pada mesin terpisah (seperti pengenal atribut pribadi dan pencetak relevansi dapat berjalan di satu perangkat sementara pengekstrak fitur dan pengklasifikasi berjalan di perangkat lain, dll.).
Untuk kesederhanaan penjelasan, metode digambarkan dan digambarkan sebagai serangkaian tindakan.
Tetapi tindakan dapat terjadi dalam berbagai urutan dan dan dengan tindakan lain yang tidak disajikan dan dijelaskan di sini.
Selain itu, tidak semua tindakan yang diilustrasikan mungkin diperlukan untuk menginstal metode dengan materi pelajaran yang diungkapkan.
Selain itu, mereka yang ahli dalam bidang ini akan memahami dan menghargai bahwa metode tersebut dapat direpresentasikan sebagai serangkaian keadaan yang saling terkait melalui diagram keadaan atau peristiwa.
Selain itu, harus dihargai bahwa metode yang diungkapkan dalam spesifikasi ini mampu disimpan pada artikel manufaktur untuk memudahkan pengangkutan dan pemindahan metodologi tersebut ke perangkat komputasi.
Istilah barang manufaktur, seperti yang digunakan di sini, dimaksudkan untuk mencakup program komputer yang dapat diakses dari perangkat atau media penyimpanan yang dapat dibaca komputer.
Sebuah kosakata atribut subjektif akan dihasilkan.
Dalam beberapa aspek, kosakata atribut subjektif dapat didefinisikan. Sebaliknya, dalam beberapa faktor lain, kosakata atribut pribadi dapat dihasilkan secara otomatis dengan mengumpulkan istilah dan frasa yang digunakan dalam reaksi pengguna terhadap entitas. Sebaliknya, dalam aspek lain, kosakata dapat dihasilkan oleh kombinasi teknik manual dan otomatis.
Kosakata diunggulkan dengan sejumlah kecil atribut subjektif yang diharapkan berlaku untuk entitas. Kosakata akan diperluas dari waktu ke waktu karena lebih banyak istilah atau frasa yang muncul dalam reaksi pengguna diidentifikasi melalui pemrosesan respons otomatis.
Kosakata atribut subjektif dapat diatur secara hierarkis, mungkin berdasarkan "meta-atribut" yang terkait dengan atribut pribadi (seperti atribut pribadi "lucu" mungkin memiliki meta-atribut "positif", sedangkan poin subjektif "menjijikkan" mungkin memiliki sebuah meta-atribut "negatif," dll).
Satu set S entitas (seperti semua entitas di penyimpanan entitas, subset entitas di penyimpanan entitas, dll.) telah diproses sebelumnya.
Di bawah satu aspek, pra-pemrosesan entitas terdiri dari mengidentifikasi reaksi pengguna terhadap entitas dan kemudian melatih pengklasifikasi berdasarkan respons.
Ketika Suatu Entitas Adalah Entitas Fisik Yang Sebenarnya
Perlu dicatat bahwa ketika suatu entitas adalah entitas fisik yang sebenarnya (seperti orang, restoran, dll.), pra-pemrosesan entitas dilakukan melalui "proxy cyber" yang terkait dengan entitas fisik (seperti halaman penggemar untuk aktor di situs jejaring sosial, ulasan restoran di situs web, dll.); tetapi, atribut subjektif dianggap terkait dengan entitas itu sendiri (seperti aktor atau restoran, bukan halaman penggemar aktor atau ulasan restoran).
Contoh metode untuk melakukan dijelaskan secara rinci.
Atn entitas E yang tidak ada di set S diterima (seperti klip video yang baru diunggah, artikel berita yang belum menerima komentar apa pun, entitas di penyimpanan entitas yang tidak disertakan dalam set pelatihan, dll.).
Atribut subjek dan skor relevansi untuk entitas E diperoleh.
Implementasi metode contoh pertama dijelaskan secara rinci di bawah ini, dan kinerja metode contoh kedua dijelaskan.
Atribut subjektif dan skor relevansi yang diperoleh terkait dengan entitas E (seperti dengan menerapkan tag yang sesuai ke entitas, menambahkan catatan dalam tabel database relasional, dll.).
Eksekusi dilanjutkan kembali.
Perlu diperhatikan bahwa pengklasifikasi dapat dilatih ulang (seperti setelah setiap 100 iterasi perulangan, setiap N hari, dll.) dengan proses pelatihan ulang yang dapat dijalankan secara bersamaan.
Pra-Pemrosesan Satu Set Entitas
Metode ini dilakukan dengan memproses logika yang dapat terdiri dari perangkat keras (sirkuit, logika khusus, dll.), Perangkat lunak (seperti dijalankan pada sistem komputer tujuan umum atau mesin khusus), atau keduanya.
Metode akan dilakukan, sementara di beberapa implementasi lain mungkin dilakukan oleh mesin lain.
Set pelatihan diinisialisasi ke set kosong. Entitas E dipilih dan dihapus dari himpunan S entitas.
Atribut subjektif untuk entitas E diidentifikasi berdasarkan reaksi pengguna terhadap entitas E (seperti komentar pengguna, Suka!, bookmark, berbagi, menambah daftar putar, dll.).
Identifikasi atribut subjektif termasuk melakukan pemrosesan komentar pengguna, seperti dengan:
- Mencocokkan kata dalam komentar pengguna dengan atribut subjektif dalam kosa kata
- Menggabungkan pencocokan kata dan teknik pemrosesan bahasa alami lainnya seperti analisis sintaksis dan semantik
- Dll
Entitas yang Terjadi di Dekat Lokasi
Reaksi pengguna mungkin dikumpulkan untuk entitas yang terjadi di banyak lokasi, seperti:
- Entitas yang muncul di daftar putar banyak pengguna
- Entitas yang telah dibagikan dan muncul dalam sejumlah "umpan berita" pengguna di situs web jejaring sosial
- Dll
Lokasi yang berbeda mungkin mendapat bobot dalam kontribusinya terhadap skor relevansi berdasarkan berbagai faktor, seperti:
Pengguna tertentu yang terkait dengan lokasi (seperti pengguna tertentu mungkin memiliki otoritas pada musik klasik dan dengan demikian komentar tentang entitas di umpan berita mereka mungkin lebih berbobot daripada komentar di umpan berita lain, dll.), reaksi pengguna non-tekstual (seperti sebagai "Suka!", "Tidak suka!", "+1", dll.).
Selain itu, jumlah lokasi tempat entitas muncul juga dapat digunakan dalam menentukan atribut subjektif dan skor relevansi (seperti skor relevansi untuk klip video dapat ditingkatkan saat klip video ada di ratusan daftar putar pengguna, dll.).
Blok dilakukan oleh pengidentifikasi atribut subjektif.
Skor relevansi untuk atribut subjektif ditentukan oleh entitas E.
Skor relevansi ditentukan untuk atribut subjektif tertentu berdasarkan frekuensi kemunculan atribut pribadi dalam komentar pengguna, pengguna tertentu yang memberikan detail subjektif dalam kata-kata mereka (seperti beberapa pengguna mungkin diketahui dari pengalaman untuk lebih akurat dalam komentar mereka daripada pengguna lain, dll.).
Misalnya, jika ada 40 komentar dan "imut" muncul dalam 20 kata dan "mengagumkan" muncul dalam 8 komentar, maka "imut" dapat diberi skor relevansi yang lebih tinggi dari "mengagumkan".
Skor relevansi dapat diberikan berdasarkan proporsi komentar di mana atribut subjektif muncul (seperti skor 0,5 untuk "imut" dan skor 0,2 untuk "mengagumkan", dll.).
Di bawah satu aspek, skor relevansi dinormalisasi untuk jatuh dalam interval [0, 1].
Dengan beberapa aspek, atribut subjektif yang diidentifikasi dapat dibuang berdasarkan skor relevansinya (seperti mempertahankan k atribut emosional dengan skor relevansi tertinggi, membuang atribut pribadi yang skor relevansinya di bawah ambang batas, dll.).
Perlu dicatat bahwa atribut subjektif dapat dibuang dengan menetapkan skor relevansinya menjadi nol dalam beberapa aspek.
Atribut Subyektif Dan Skor Relevansi Terkait Dengan Entitas
Atribut subjektif dan skor relevansi dikaitkan dengan entitas (seperti melalui penandaan, entri dalam tabel dalam database relasional, dll.).
Vektor fitur untuk entitas E diperoleh.
Dalam satu aspek, vektor fitur untuk klip video atau gambar diam dapat berisi nilai numerik tentang warna, tekstur, intensitas, dll., sedangkan vektor fitur untuk klip audio (atau klip video dengan suara) dapat menyertakan nilai numerik tentang amplitudo , koefisien spektral, dll., sedangkan vektor fitur untuk dokumen teks dapat mencakup:
- Nilai numerik tentang frekuensi kata
- Panjang kalimat rata-rata
- Parameter pemformatan
- Begitu seterusnya
Ini mungkin dilakukan oleh ekstraktor fitur.
Vektor fitur dan skor relevansi yang diperoleh ditambahkan ke set pelatihan.
Bock memeriksa apakah himpunan entitas S kosong; jika S tidak kosong, eksekusi dilanjutkan, jika tidak, eksekusi dilanjutkan.
Pengklasifikasi dilatih pada semua contoh set pelatihan, sehingga vektor fitur dari contoh pelatihan diberikan sebagai input ke pengklasifikasi, dan skor relevansi atribut subjektif diberikan sebagai output.
Memperoleh Atribut Subyektif Dan Skor Relevansi Untuk Suatu Entitas
Vektor fitur untuk entitas E dihasilkan.
Seperti dijelaskan di atas, vektor fitur untuk klip video atau gambar diam mungkin berisi nilai numerik tentang warna, tekstur, intensitas, dll. Sebaliknya, vektor fitur untuk klip audio (atau klip video dengan suara) dapat menyertakan nilai numerik tentang amplitudo, koefisien spektral, dll. Sebaliknya, vektor fitur untuk dokumen teks dapat mencakup nilai numerik tentang frekuensi kata, panjang kalimat rata-rata, parameter pemformatan, dan sebagainya.
Pengklasifikasi terlatih menyediakan vektor fitur untuk mendapatkan atribut subjektif yang diprediksi dan skor relevansi untuk entitas E.
Atribut subjektif yang diprediksi dan skor relevansi diasosiasikan dengan entitas E (seperti melalui tag yang diterapkan ke entitas E, melalui entri dalam tabel database relasional, dll.).
Metode Kedua Untuk Mendapatkan Atribut Subyektif Dan Skor Relevansi Untuk Suatu Entitas
Metode ini dilakukan dengan memproses logika yang dapat terdiri dari perangkat keras (sirkuit, logika khusus, dll.), Perangkat lunak, atau kombinasi keduanya.
Metode ini dilakukan oleh mesin server, sementara beberapa lainnya mungkin dilakukan oleh perangkat lain.
Vektor fitur untuk entitas E dihasilkan. Pengklasifikasi terlatih menyediakan vektor fitur untuk mendapatkan atribut subjektif yang diprediksi dan skor relevansi untuk entitas E.
Atribut subjektif yang diprediksi diperoleh disarankan kepada pengguna (seperti pengguna yang mengunggah entitas. Seperangkat atribut pribadi yang disempurnakan diperoleh dari pengguna, seperti melalui halaman web di mana pengguna memilih dari antara atribut yang disarankan dan mungkin menambahkan atribut baru, dll.).
Skor Relevansi Default Untuk Entitas
Skor relevansi default diberikan ke atribut subjektif baru yang ditambahkan oleh pengguna.
Skor relevansi default mungkin 1,0 pada skala 0,0 hingga 1,0, skor relevansi default mungkin didasarkan pada pengguna tertentu (seperti skor 1,0 ketika pengguna diketahui dari riwayat masa lalu sangat baik dalam menyarankan atribut, skor dari 0,8 ketika pengguna diketahui cukup baik dalam menyarankan atribut, dll.).
Cabang Blok mendapatkan berdasarkan apakah pengguna menghapus salah satu atribut subjektif yang disarankan (seperti dengan tidak memilih atribut).
Entitas E disimpan sebagai contoh negatif dari atribut yang dihapus untuk pelatihan ulang pengklasifikasi di masa mendatang. Kumpulan atribut subjektif yang disempurnakan dan skor relevansi terkait dikaitkan dengan entitas E (seperti melalui tag yang diterapkan ke entitas E, melalui entri dalam tabel database relasional, dll.).