
Pemodelan Topik Dengan Word2Vec
Diterbitkan: 2022-05-02Sebuah kata ditentukan oleh perusahaan yang dipegangnya. Itulah premis di balik Word2Vec, sebuah metode untuk mengubah kata menjadi angka dan merepresentasikannya dalam ruang multidimensi. Kata-kata yang sering ditemukan berdekatan dalam kumpulan dokumen (korpus) juga akan muncul berdekatan di ruang ini. Mereka dikatakan terkait secara kontekstual.
Word2Vec adalah metode pembelajaran mesin yang membutuhkan korpus dan pelatihan yang tepat. Kualitas keduanya mempengaruhi kemampuannya untuk memodelkan suatu topik secara akurat. Setiap kekurangan menjadi mudah terlihat ketika memeriksa keluaran untuk topik yang sangat spesifik dan rumit karena ini adalah yang paling sulit untuk dimodelkan secara tepat. Word2Vec dapat digunakan dengan sendirinya, meskipun sering dikombinasikan dengan teknik pemodelan lain untuk mengatasi keterbatasannya.
Sisa artikel ini memberikan latar belakang tambahan tentang Word2Vec, cara kerjanya, cara menggunakannya dalam pemodelan topik, dan beberapa tantangan yang dihadirkannya.
Apa itu Word2Vec?
Pada September 2013, peneliti Google, Tomas Mikolov, Kai Chen, Greg Corrado, dan Jeffrey Dean, menerbitkan makalah 'Efficient Estimation of Word Representations in Vector Space' (pdf). Inilah yang sekarang kita sebut sebagai Word2Vec. Tujuan makalah ini adalah untuk “memperkenalkan teknik yang dapat digunakan untuk mempelajari vektor kata berkualitas tinggi dari kumpulan data besar dengan miliaran kata, dan dengan jutaan kata dalam kosakata.”
Sebelum titik ini, setiap teknik pemrosesan bahasa alami memperlakukan kata-kata sebagai unit tunggal. Mereka tidak memperhitungkan kesamaan antara kata-kata. Meskipun ada alasan yang sah untuk pendekatan ini, itu memang memiliki keterbatasan. Ada situasi di mana penskalaan teknik dasar ini tidak dapat menawarkan peningkatan yang signifikan. Oleh karena itu, perlu dikembangkan teknologi canggih.
Makalah tersebut menunjukkan bahwa model sederhana, dengan persyaratan komputasi yang lebih rendah, dapat melatih vektor kata berkualitas tinggi. Saat makalah ini menyimpulkan, "mungkin untuk menghitung vektor kata berdimensi tinggi yang sangat akurat dari kumpulan data yang jauh lebih besar." Mereka berbicara tentang kumpulan dokumen (corpora) dengan satu triliun kata yang memberikan ukuran kosakata yang hampir tidak terbatas.
Word2Vec adalah cara mengubah kata menjadi angka, dalam hal ini vektor, sehingga persamaan dapat ditemukan secara matematis. Idenya adalah bahwa vektor dari kata-kata yang mirip dikelompokkan dalam ruang vektor.
Pikirkan koordinat lintang dan bujur pada peta. Dengan menggunakan vektor dua dimensi ini, Anda dapat dengan cepat menentukan apakah dua lokasi relatif berdekatan. Agar kata-kata direpresentasikan dengan tepat dalam ruang vektor, dua dimensi tidak cukup. Jadi, vektor perlu menggabungkan banyak dimensi.
Bagaimana Cara Kerja Word2Vec?
Word2Vec mengambil inputnya berupa korpus teks besar dan membuat vektor menggunakan jaring saraf dangkal. Outputnya adalah daftar kata (kosa kata), masing-masing dengan vektor yang sesuai. Kata-kata dengan makna yang mirip secara spasial muncul dalam jarak yang berdekatan. Secara matematis ini diukur dengan kesamaan kosinus, di mana kesamaan total dinyatakan sebagai sudut 0 derajat sedangkan tidak ada kesamaan dinyatakan sebagai sudut 90 derajat.
Kata-kata dapat dikodekan sebagai vektor menggunakan berbagai jenis model. Dalam makalah mereka, Mikolov et al. melihat dua model yang ada, model bahasa jaringan saraf maju (NNLM) dan model bahasa jaringan saraf berulang (RNNLM). Selain itu, mereka mengusulkan dua model log-linear baru, continuous bag of words (CBOW), dan Skip-gram berkelanjutan.
Dalam perbandingan mereka, CBOW dan Skip-gram berkinerja lebih baik, jadi mari kita periksa kedua model ini.
CBOW mirip dengan NNLM dan bergantung pada konteks untuk menentukan kata target. Ini menentukan kata target berdasarkan kata-kata yang datang sebelum dan sesudahnya. Mikolov menemukan kinerja terbaik terjadi dengan empat masa depan dan empat kata sejarah. Disebut 'kantong kata-kata' karena urutan kata-kata dalam sejarah tidak mempengaruhi output. 'Berkelanjutan' dalam istilah CBOW mengacu pada penggunaan "representasi konteks yang terdistribusi secara terus menerus."
Skip-gram adalah kebalikan dari CBOW. Diberikan sebuah kata, itu memprediksi kata-kata di sekitarnya dalam rentang tertentu. Rentang yang lebih besar memberikan kualitas vektor kata yang lebih baik tetapi meningkatkan kompleksitas komputasi. Lebih sedikit bobot diberikan pada istilah yang jauh karena biasanya kurang terkait dengan kata saat ini.
Dalam membandingkan CBOW dengan Skip-gram, yang terakhir ditemukan menawarkan hasil kualitas yang lebih baik pada kumpulan data yang besar. Meskipun CBOW lebih cepat, Skip-gram menangani kata-kata yang jarang digunakan dengan lebih baik.
Selama pelatihan, sebuah vektor ditugaskan untuk setiap kata. Komponen-komponen dari vektor tersebut disesuaikan sehingga kata-kata yang mirip (berdasarkan konteksnya) lebih dekat satu sama lain. Anggap ini sebagai tarik ulur, di mana kata-kata didorong dan ditarik dalam vektor multi-dimensi ini setiap kali istilah lain ditambahkan ke ruang.
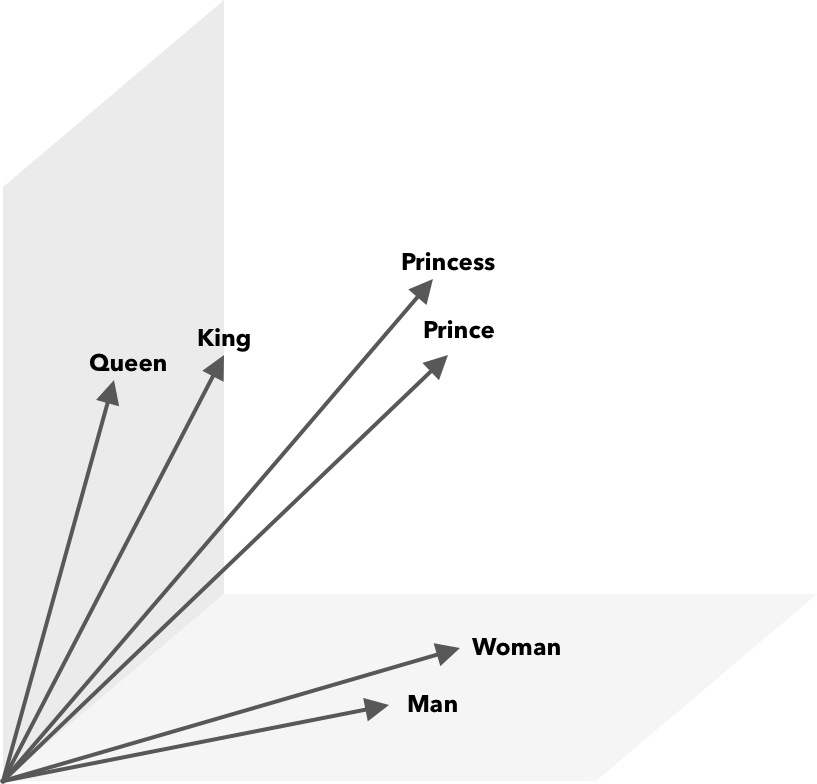
Operasi matematika, selain kesamaan cosinus, dapat dilakukan pada vektor kata. Misalnya, vektor("Raja") – vektor("Pria") + vektor("Wanita") menghasilkan vektor yang paling dekat dengan yang mewakili kata Ratu.

Word2Vec untuk Pemodelan Topik
Kosakata yang dibuat oleh Word2Vec dapat ditanyakan secara langsung untuk mendeteksi hubungan antar kata atau dimasukkan ke dalam jaringan saraf pembelajaran mendalam. Satu masalah dengan algoritma Word2Vec seperti CBOW dan Skip-gram adalah bahwa mereka menimbang setiap kata secara merata. Masalah yang muncul ketika bekerja dengan dokumen adalah bahwa kata-kata tidak sama mewakili arti dari sebuah kalimat.
Beberapa kata lebih penting daripada yang lain. Dengan demikian, strategi pembobotan yang berbeda, seperti TF-IDF, sering digunakan untuk menghadapi situasi tersebut. Ini juga membantu mengatasi masalah hubness yang disebutkan di bagian berikutnya. Searchmetrics ContentExperience menggunakan kombinasi TF-IDF dan Word2Vec, yang dapat Anda baca di sini dalam perbandingan kami dengan MarketMuse.
Sementara penyisipan kata seperti Word2Vec menangkap informasi morfologis, semantik, dan sintaksis, pemodelan topik bertujuan untuk menemukan struktur semantik laten atau topik dalam korpus.
Menurut Budhkar dan Rudzicz (PDF), menggabungkan alokasi Dirichlet laten (LDA) dengan Word2Vec dapat menghasilkan fitur diskriminatif untuk "mengatasi masalah yang disebabkan oleh tidak adanya informasi kontekstual yang tertanam dalam model ini." Membaca lebih mudah di LDA2vec dapat ditemukan di tutorial DataCamp ini.
Tantangan Word2Vec
Ada beberapa masalah dengan penyisipan kata secara umum, termasuk Word2Vec. Kami akan menyentuh beberapa di antaranya, untuk analisis yang lebih rinci, lihat 'A Survey of Word Embedding Evaluation Methods' (pdf) oleh Amir Bakarov. Korpus dan ukurannya, serta pelatihan itu sendiri, akan sangat mempengaruhi kualitas output.
Bagaimana Anda mengevaluasi output?
Seperti yang dijelaskan Bakarov dalam makalahnya, seorang insinyur NLP biasanya akan mengevaluasi kinerja embeddings secara berbeda dari ahli bahasa komputasi, atau pemasar konten dalam hal ini. Berikut adalah beberapa masalah tambahan yang dikutip dalam makalah.
- Semantik adalah ide yang kabur. Penyematan kata yang "baik" mencerminkan gagasan kami tentang semantik. Namun, kita mungkin tidak menyadari apakah pemahaman kita benar. Juga, kata-kata memiliki berbagai jenis hubungan seperti keterkaitan semantik dan kesamaan semantik. Jenis hubungan apa yang harus dicerminkan oleh kata embedding?
- Kurangnya data pelatihan yang tepat. Saat melatih penyisipan kata, peneliti sering kali meningkatkan kualitasnya dengan menyesuaikannya dengan data. Inilah yang kami sebut sebagai pemasangan kurva. Alih-alih membuat hasilnya sesuai dengan data, peneliti harus mencoba menangkap hubungan antar kata.
- Tidak adanya korelasi antara metode intrinsik dan ekstrinsik berarti tidak jelas kelas metode mana yang lebih disukai. Evaluasi ekstrinsik menentukan kualitas keluaran untuk digunakan lebih jauh di hilir dalam tugas pemrosesan bahasa alami lainnya. Evaluasi intrinsik bergantung pada penilaian manusia tentang hubungan kata.
- Masalah hub. Hub, vektor kata yang mewakili kata umum, mendekati jumlah vektor kata lain yang berlebihan. Kebisingan ini dapat membiaskan evaluasi.
Selain itu, ada dua tantangan signifikan dengan Word2Vec pada khususnya.
- Itu tidak bisa menangani ambiguitas dengan baik. Akibatnya, vektor sebuah kata dengan makna ganda mencerminkan rata-rata, yang jauh dari ideal.
- Word2Vec tidak dapat menangani kata-kata out-of-vocabulary (OOV) dan kata-kata yang mirip secara morfologis. Ketika model menemukan konsep baru, ia menggunakan vektor acak, yang bukan merupakan representasi akurat.
Ringkasan
Menggunakan Word2Vec atau penyisipan kata lainnya bukanlah jaminan keberhasilan. Output yang berkualitas didasarkan pada pelatihan yang tepat menggunakan corpus yang sesuai dan cukup besar.
Meskipun mengevaluasi kualitas keluaran bisa jadi rumit, berikut adalah solusi sederhana untuk pemasar konten. Lain kali Anda mengevaluasi pengoptimal konten, coba gunakan topik yang sangat spesifik. Model topik berkualitas buruk gagal dalam pengujian dengan cara ini. Mereka baik-baik saja untuk istilah umum tetapi rusak ketika permintaan menjadi terlalu spesifik.
Jadi, jika Anda menggunakan topik 'cara menanam alpukat', pastikan sarannya ada hubungannya dengan menanam tanaman dan bukan alpukat pada umumnya.
Teknologi NLG MarketMuse generasi bahasa alami membantu membuat artikel ini.
Apa yang harus kamu lakukan sekarang?
Saat Anda siap… berikut adalah 3 cara kami dapat membantu Anda memublikasikan konten yang lebih baik, lebih cepat:
- Pesan waktu dengan MarketMuse Jadwalkan demo langsung dengan salah satu ahli strategi kami untuk melihat bagaimana MarketMuse dapat membantu tim Anda mencapai sasaran konten mereka.
- Jika Anda ingin mempelajari cara membuat konten yang lebih baik dengan lebih cepat, kunjungi blog kami. Ini penuh dengan sumber daya untuk membantu menskalakan konten.
- Jika Anda mengenal pemasar lain yang senang membaca halaman ini, bagikan dengan mereka melalui email, LinkedIn, Twitter, atau Facebook.