
Raggiungere la resilienza con le code: costruire un sistema che non salta mai un battito in un miliardo
Pubblicato: 2018-12-21Braze elabora miliardi e miliardi di eventi al giorno per conto dei suoi clienti, generando miliardi di messaggi iper-focalizzati e personalizzati inviati ai loro utenti finali. Il mancato invio di uno di questi messaggi ha delle conseguenze, sia che si tratti di una ricevuta mancata o, peggio ancora, di una mancata notifica che consente all'utente di sapere che il suo cibo è pronto. Per assicurarsi che quei messaggi chiave siano sempre corretti e sempre puntuali, Braze adotta un approccio strategico per sfruttare le code di lavoro.
Che cos'è una coda di lavoro?
Una tipica coda di lavoro è un modello architettonico in cui i processi inviano lavori di calcolo a una coda e altri processi effettivamente eseguono i lavori. Di solito è una buona cosa: se usato correttamente, offre livelli di concorrenza, scalabilità e ridondanza che non puoi ottenere con un paradigma di richiesta-risposta tradizionale. Molti lavoratori possono eseguire diversi lavori contemporaneamente in più processi, più macchine o persino più data center per la massima simultaneità. Puoi assegnare determinati nodi di lavoro per lavorare su determinate code e inviare lavori particolari a code specifiche, consentendoti di ridimensionare le risorse secondo necessità. Se un processo di lavoro si arresta in modo anomalo o un data center va offline, altri lavoratori possono eseguire i lavori rimanenti.
Sebbene tu possa certamente applicare questi principi ed eseguire facilmente un sistema di accodamento lavori su piccola scala, le cuciture iniziano a mostrarsi (e persino a scoppiare) quando stai elaborando miliardi e miliardi di lavori. Diamo un'occhiata ad alcuni problemi che Braze ha dovuto affrontare quando siamo passati dall'elaborazione di migliaia, a milioni e ora miliardi di lavori al giorno.
La mancanza di coerenza è una debolezza
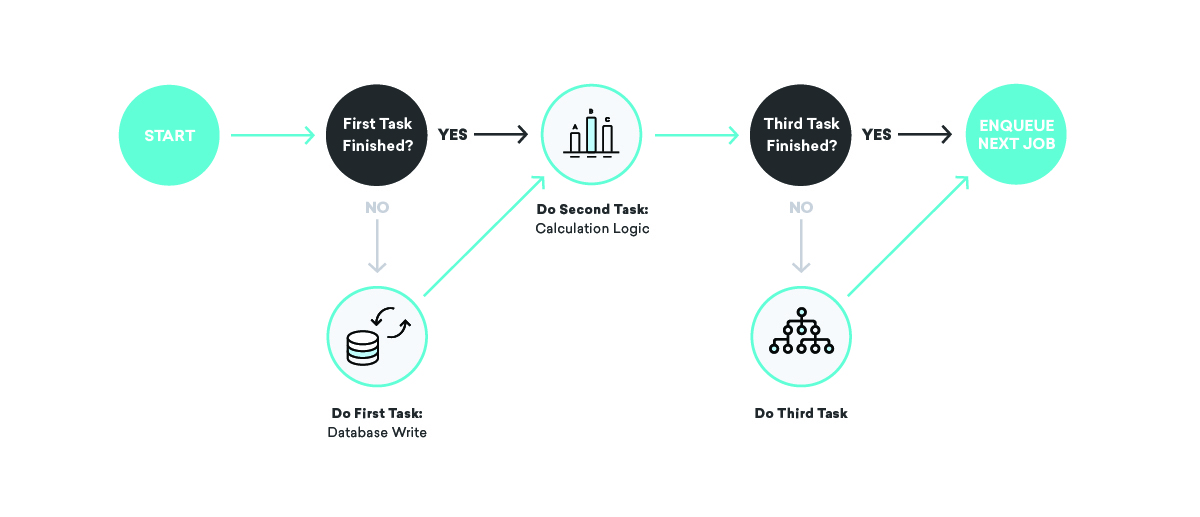
Cosa succede se inviamo un messaggio, ma andiamo in crash prima di registrare il fatto che abbiamo appena inviato quel messaggio?
Qui sono possibili un paio di esiti negativi diversi. Innanzitutto, potresti riprogrammare il lavoro non riuscito e inviare nuovamente il messaggio. Questo... non è l'ideale: nessuno vuole ricevere la stessa cosa due volte. Invece, considera di non riprogrammarlo affatto. In tal caso, la nostra contabilità interna non sarà corretta, quindi attribuzioni, conversioni e ogni altro tipo di cose non andranno bene andando avanti.
Come lo risolviamo? Quando scriviamo le nostre definizioni di lavoro, riflettiamo molto sull'idempotenza e sul comportamento dei tentativi.
Quando si parla di code, idempotenza significa che un singolo lavoro può essere terminato in un punto arbitrario, il lavoro rimesso in coda è stato eseguito nuovamente nella sua interezza e il risultato finale sarà lo stesso come se avessimo eseguito correttamente il lavoro esattamente uno volta. Questo è intimamente legato al nostro comportamento di scelta dei tentativi di ripetizione: consegna almeno una volta. Tenendo presente che tutti i nostri lavori verranno eseguiti almeno una volta, e forse più volte, possiamo scrivere definizioni di lavoro idempotenti che garantiscono coerenza anche di fronte a errori casuali.
Tornando al nostro esempio di invio di messaggi, come potremmo utilizzare questi concetti per garantire la coerenza? In questo caso, potremmo spezzare il lavoro in due parti, con il primo che invia il messaggio e mette in coda il secondo, e il secondo che scrive al database. In questo scenario, possiamo riprovare uno qualsiasi dei lavori tutte le volte che vogliamo: se il provider di invio dei messaggi è inattivo o il database di contabilità interno è inattivo, riproveremo in modo appropriato finché non avremo successo!
Buone recinzioni fanno buoni vicini
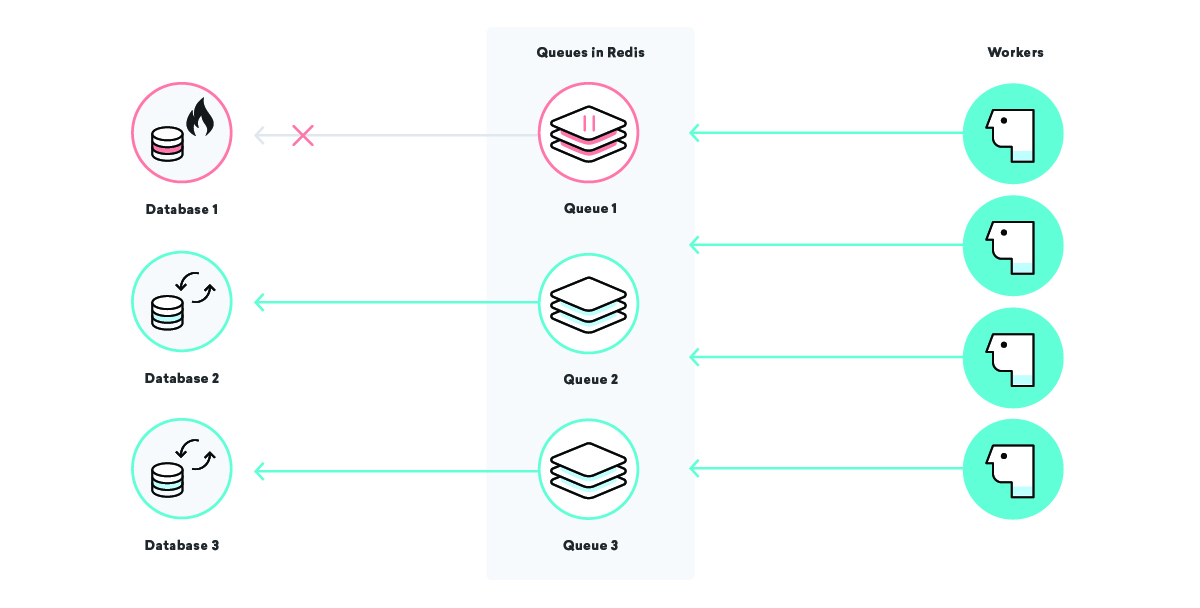
Cosa succede all'elaborazione dei dati della nostra azienda di esempio Consolidated Widgets quando il database per Global Gizmos è inattivo?
In questo scenario, se la nostra strategia di consegna almeno una volta è in gioco, ci aspetteremmo che tutti i lavori di elaborazione dei dati per Global Gizmos vengano ripetuti più e più volte finché non hanno esito positivo. Questo è fantastico: non perderemo alcun dato anche se il loro database è inattivo. Per Consolidated Widgets, tuttavia, potrebbe non essere eccezionale: se i lavoratori riprovano costantemente e falliscono, potrebbero essere troppo occupati per elaborare il lavoro di Consolidated Widgets in modo tempestivo.
Possiamo risolvere questo problema utilizzando nomi di coda ben scelti e mettendo in pausa alcune code secondo necessità. Con questo nella nostra cintura degli attrezzi, possiamo alleviare la tensione su pezzi di infrastruttura in modo chirurgico. Nel nostro scenario sopra, una volta che sappiamo che il database di Global Gizmos è inattivo, possiamo mettere in pausa la coda di elaborazione dei dati fino a quando non sappiamo che è stato eseguito il backup, assicurandoci che un'interruzione specifica non influisca su nessun altro cliente!

L'attesa è dolorosa
Cosa succede se Consolidated Widgets e Global Gizmos inviano campagne e-mail a 50 milioni di utenti ciascuno, a 5 minuti di distanza? Chi va per primo?
I semplici sistemi di accodamento dei lavori hanno una semplice coda di "lavoro" da cui i lavoratori estraggono i lavori. Una volta che hai una buona varietà di lavori e tipi di lavoro diversi, probabilmente passerai ad avere più tipi di code, ognuno con priorità o tipi di lavoratori diversi che estraggono da quelle code. In questo senso, abbiamo una varietà di code semplici per l'elaborazione dei dati, la messaggistica e varie attività di manutenzione.
Passando rapidamente a quando invii miliardi di messaggi personalizzati al giorno, una coda di "messaggistica" non la taglierà: cosa succede quando quella coda diventa estremamente grande, come nel nostro esempio sopra? Diamo la priorità ai lavori che sono arrivati per primi?
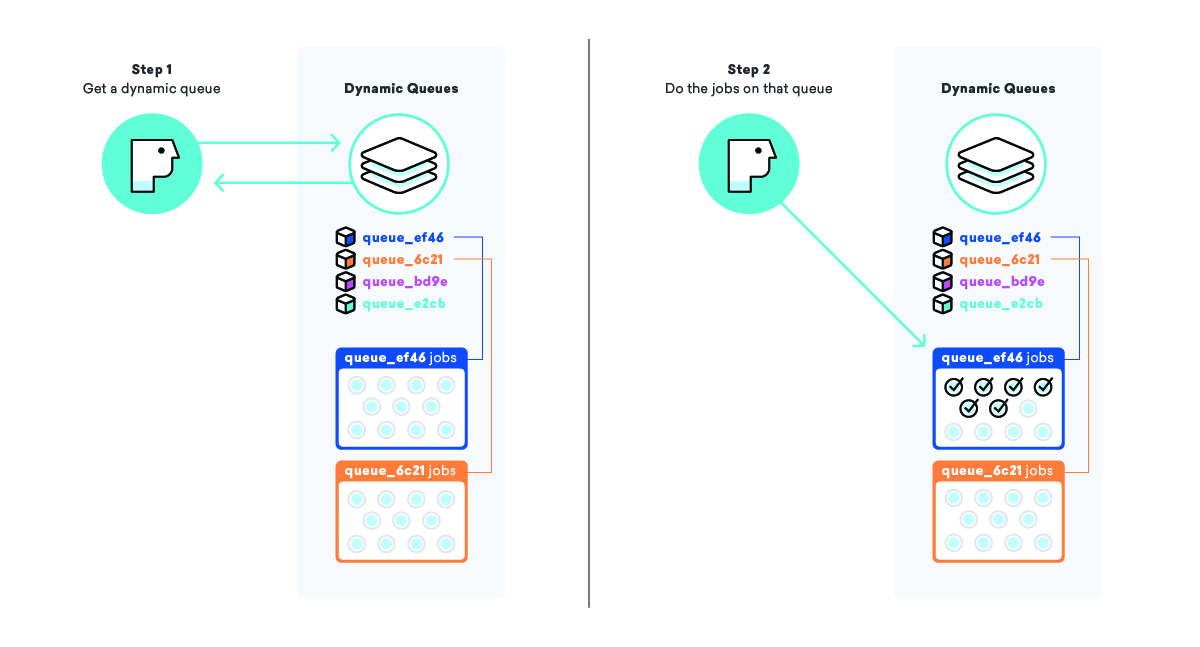
Il nostro sistema di accodamento dinamico cerca di affrontare un fenomeno chiamato mancanza di lavoro, in cui un lavoro pronto per l'esecuzione attende molto tempo prima di essere eseguito, di solito a causa di un qualche tipo di priorità. In una semplice coda di "messaggistica", la priorità è semplicemente il momento in cui il lavoro è entrato nella coda, il che significa che i lavori aggiunti alla fine di una grande coda possono finire per aspettare molto tempo.
Quando andiamo a mettere in coda una campagna e tutti i suoi messaggi, invece di aggiungere i lavori a una grande coda di "messaggi", creiamo una coda completamente nuova solo per questa campagna, completa di un nome speciale in modo da sapere di cosa si tratta e come trovarlo. Dopo aver aggiunto i lavori alla coda, prendiamo il nostro elenco di "code dinamiche" e aggiungiamo questo nuovo nome di coda alla fine.
Utilizzando questa strategia, possiamo istruire i lavoratori a prendere il nome di una coda dinamica dall'elenco "code dinamiche", quindi elaborare tutti i lavori su quella coda particolare. Questo ci consente di garantire che i messaggi vengano inviati il più velocemente possibile E che tutti i nostri clienti siano trattati con la stessa priorità.
Di conseguenza, questo ha altri vantaggi, come tassi di accesso alla cache più elevati e meno connessioni al database, a causa dell'aumento della località di lavoro per determinati lavoratori. Tutti vincono!
Avere sempre un piano di backup
Cosa succede quando un database è inattivo, alcune code vengono messe in pausa e le code dei lavori iniziano a riempirsi?
A volte pezzi importanti dell'infrastruttura muoiono semplicemente addosso a te. Disponiamo di secondari e backup, ma il tempo necessario per promuovere l'infrastruttura di backup non è quasi mai zero. Avere più livelli di code nell'intera infrastruttura dell'applicazione può essere molto utile per mitigare l'impatto di questi tipi di eventi.
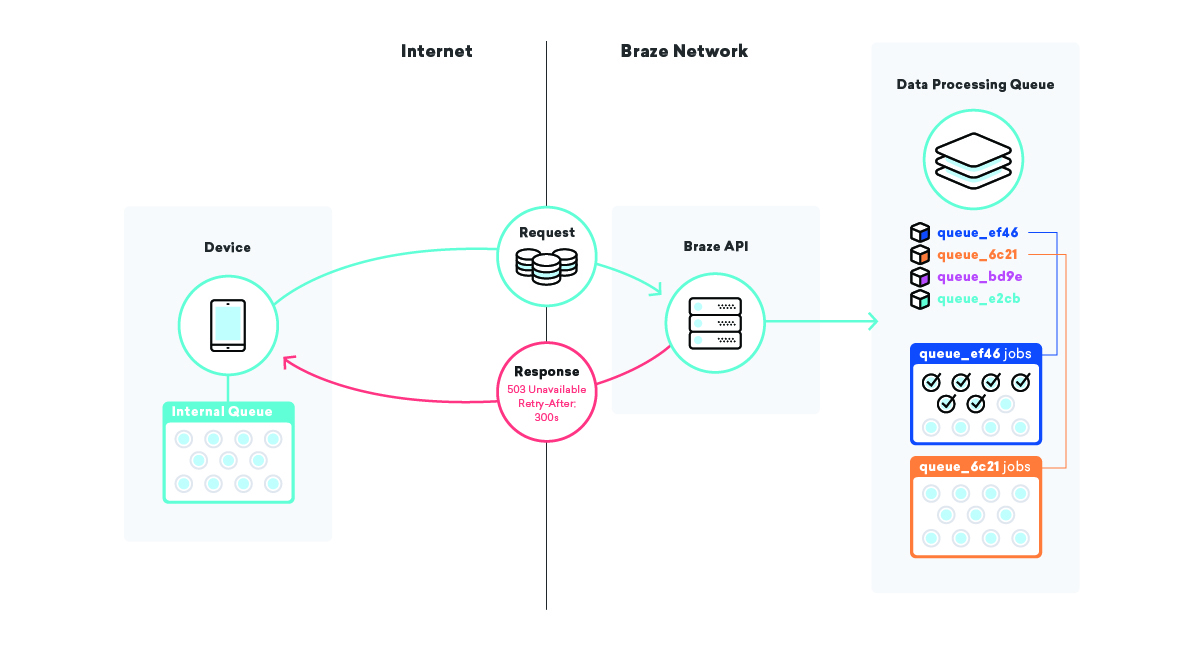
Una di queste strategie che impieghiamo è fare la coda sui dispositivi stessi. Milioni e milioni di dispositivi hanno applicazioni diverse che utilizzano un Braze SDK e, in tali applicazioni, utilizziamo una coda per inviare dati alle nostre API.
Quando il nostro SDK invia i dati e non riesce, per qualsiasi motivo, l'SDK esegue una coda di tentativi utilizzando un algoritmo di backoff esponenziale finché non riesce. Questa strategia riduce al minimo l'impatto dell'infrastruttura o degli errori del codice, poiché i dispositivi semplicemente accodano i propri dati e li invieranno a Braze quando tutto sarà di nuovo online.
Muoversi velocemente e non rompere le cose
In fin dei conti, il nostro obiettivo è inviare messaggi iper-focalizzati e personalizzati meglio di chiunque altro, e ciò implica muoversi rapidamente, essere resilienti e fare tutto bene. Le code di lavoro sono al centro dell'infrastruttura di Braze, quindi controlliamo sempre le nostre prestazioni, utilizziamo le migliori pratiche e sperimentiamo nuove strategie e tecniche avanzate per essere i migliori nel gioco.
Se questo tipo di ingegneria dei sistemi ad alte prestazioni e bassa latenza nello spazio dell'automazione del marketing ti eccita, allora dovresti assolutamente controllare la nostra bacheca di lavoro!