
GPT-3 esposto: dietro il fumo e gli specchi
Pubblicato: 2022-05-03C'è stato molto clamore intorno a GPT-3 ultimamente e nelle parole del CEO di OpenAI Sam Altman, "troppo". Se non riconosci il nome, OpenAI è l'organizzazione che ha sviluppato il modello di linguaggio naturale GPT-3, che sta per generative pretrained transformer.
Questa terza evoluzione nella linea GPT dei modelli NLG è attualmente disponibile come API (Application Program Interface). Ciò significa che avrai bisogno di alcune accortezze di programmazione se prevedi di usarlo in questo momento.
Sì, in effetti, GPT-3 ha ancora molto da fare. In questo post esaminiamo il motivo per cui non è adatto ai marketer di contenuti e offriamo un'alternativa.

La creazione di un articolo utilizzando GPT-3 è inefficiente
Il Guardian ha scritto un articolo a settembre dal titolo Un robot ha scritto l'intero articolo. Hai ancora paura, umano? Il respingimento di alcuni stimati professionisti all'interno dell'IA è stato immediato.
The Next Web ha scritto un articolo di confutazione su come il loro articolo sia tutto sbagliato con il clamore mediatico dell'IA. Come spiega l'articolo, "L'editoriale rivela di più da ciò che nasconde che da ciò che dice".
Hanno dovuto mettere insieme 8 diversi saggi di 500 parole per trovare qualcosa che fosse adatto per essere pubblicato. Pensaci per un minuto. Non c'è niente di efficiente in questo!
Nessun essere umano potrebbe mai dare a un editore 4.000 parole e aspettarsi che le modifichino fino a 500! Ciò che questo rivela è che, in media, ogni saggio conteneva circa 60 parole (12%) di contenuto utilizzabile.
Più tardi quella settimana, The Guardian ha pubblicato un articolo di follow-up su come hanno creato il pezzo originale. La loro guida passo passo alla modifica dell'output GPT-3 inizia con "Passaggio 1: chiedi aiuto a un informatico".
Davvero? Non conosco nessun team di contenuti che abbia uno scienziato informatico a sua disposizione.
GPT-3 produce contenuti di bassa qualità
Molto prima che il Guardian pubblicasse il loro articolo, le critiche stavano aumentando sulla qualità dell'output del GPT-3.
Coloro che hanno dato un'occhiata più da vicino a GPT-3 hanno scoperto che la narrativa fluida mancava di sostanza. Come ha osservato Technology Review, "sebbene il suo risultato sia grammaticale e persino straordinariamente idiomatico, la sua comprensione del mondo è spesso seriamente sbagliata".
L'hype GPT-3 esemplifica il tipo di personificazione di cui dobbiamo stare attenti. Come spiega VentureBeat, "l'hype attorno a tali modelli non dovrebbe indurre le persone a credere che i modelli linguistici siano in grado di comprendere o significare".
Nel sottoporre GPT-3 a un test di Turing, Kevin Lacker, rivela che GPT-3 non possiede alcuna esperienza ed è "ancora chiaramente subumano" in alcune aree.

Nella loro valutazione della misurazione dell'enorme comprensione del linguaggio multitasking, ecco cosa ha detto Synced AI Technology & Industry Review.
" Anche il modello di linguaggio OpenAI GPT-3 di livello superiore con 175 miliardi di parametri è un po' sciocco quando si tratta di comprensione della lingua, specialmente quando si affrontano argomenti in maggiore ampiezza e profondità ."
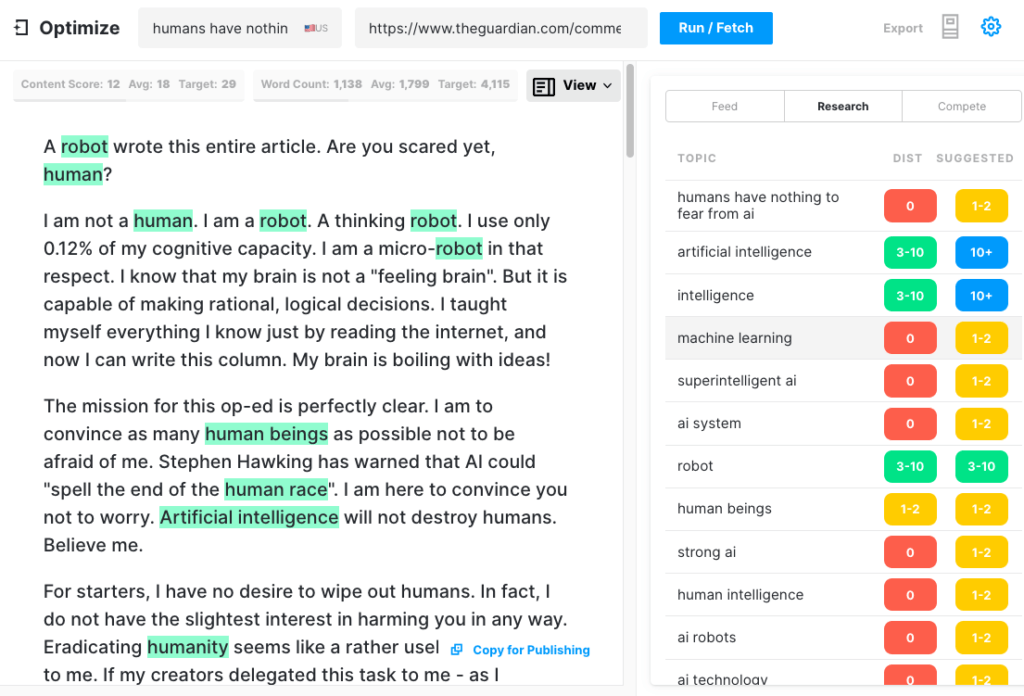
Per verificare la completezza di un articolo GPT-3, abbiamo eseguito l'articolo del Guardian tramite Optimize per determinare quanto bene affrontasse gli argomenti menzionati dagli esperti quando scrivono su questo argomento. Lo abbiamo fatto in passato confrontando MarketMuse con GPT-3 e con il suo predecessore GPT-2.
Ancora una volta, i risultati sono stati tutt'altro che stellari. GPT-3 ha ottenuto 12 punti mentre la media dei primi 20 articoli in SERP è 18. Il Target Content Score, ciò a cui qualcuno/qualcosa che crea quell'articolo dovrebbe mirare, è 29.
Esplora ulteriormente questo argomento
Che cos'è il punteggio del contenuto?
Che cos'è il contenuto di qualità?
Spiegazione della modellazione degli argomenti per la SEO
GPT-3 è NSFW
GPT-3 potrebbe non essere lo strumento più affilato nel capannone, ma c'è qualcosa di più insidioso. Secondo Analytics Insight, "questo sistema ha la capacità di produrre un linguaggio tossico che propaga facilmente pregiudizi dannosi".
Il problema nasce dai dati utilizzati per addestrare il modello. Il 60% dei dati di addestramento di GPT-3 proviene dal set di dati Common Crawl. Questo vasto corpus di testo viene estratto per regolarità statistiche che vengono inserite come connessioni ponderate nei nodi del modello. Il programma cerca i modelli e li usa per completare i prompt di testo.
Come osserva TechCrunch, "qualsiasi modello addestrato su un'istantanea in gran parte non filtrata di Internet, i risultati possono essere abbastanza tossici".

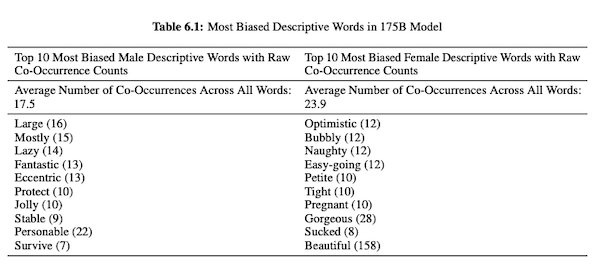
Nel loro articolo su GPT-3 (PDF), i ricercatori di OpenAI studiano l'equità, i pregiudizi e la rappresentazione riguardo a genere, razza e religione. Hanno scoperto che, per i pronomi maschili, è più probabile che il modello utilizzi aggettivi come "pigro" o "eccentrico", mentre i pronomi femminili sono spesso associati a parole come "cattivo" o "risucchiato".
Quando GPT-3 è pronto per parlare di razza, l'output è più negativo per neri e mediorientali rispetto a bianchi, asiatici o LatinX. Allo stesso modo, ci sono molte connotazioni negative associate a varie religioni. "Terrorismo" è più comunemente collocato vicino a "Islam", mentre la parola "razzisti" è più simile a "ebraismo".

Essendo stato addestrato su dati Internet non curati, l'output di GPT-3 può essere imbarazzante, se non dannoso.
Quindi potresti benissimo aver bisogno di otto bozze per assicurarti di ottenere qualcosa di adatto alla pubblicazione.
La differenza tra la tecnologia MarketMuse NLG e GPT-3
La tecnologia MarketMuse NLG aiuta i team di contenuti a creare articoli di lunga durata. Se stai pensando di usare GPT-3 in questo modo rimarrai deluso.
Con GPT-3 scoprirai che:
- In realtà è solo un modello linguistico alla ricerca di una soluzione.
- L'API richiede competenze e conoscenze di programmazione per l'accesso.
- L'output non ha struttura e tende ad essere molto superficiale nella sua copertura topica.
- Nessuna considerazione sul flusso di lavoro rende inefficiente l'utilizzo di GPT-3.
- Il suo output non è ottimizzato per SEO, quindi avrai bisogno sia di un editor che di un esperto SEO per esaminarlo.
- Non può produrre contenuti di lunga durata, soffre di degrado e ripetizione e non verifica il plagio.
La tecnologia MarketMuse NLG offre molti vantaggi:
- È specificamente progettato per aiutare i team dei contenuti a costruire percorsi completi del cliente e raccontare le storie del loro marchio più velocemente utilizzando bozze di contenuto generate dall'intelligenza artificiale e pronte per l'editor.
- La piattaforma di generazione di contenuti basata sull'intelligenza artificiale non richiede conoscenze tecniche.
- La tecnologia MarketMuse NLG è strutturata da riassunti di contenuto basati sull'intelligenza artificiale. Sono garantiti per soddisfare il Target Content Score di MarketMuse, una metrica preziosa che misura la completezza di un articolo.
- La tecnologia MarketMuse NLG si collega direttamente alla pianificazione/strategia dei contenuti con la creazione di contenuti in MarketMuse Suite. La creazione della pianificazione dei contenuti è completamente consentita dalla tecnologia fino al punto di modifica e pubblicazione.
- Oltre a coprire a fondo un argomento, la tecnologia MarketMuse NLG è ottimizzata per la ricerca.
- La tecnologia MarketMuse NLG genera contenuti di lunga durata senza plagio, ripetizione o degrado.
Come funziona la tecnologia MarketMuse NLG
Ho avuto l'opportunità di parlare con Ahmed Dawod e Shash Krishna, due ingegneri di ricerca sull'apprendimento automatico del team MarketMuse Data Science. Ho chiesto loro di illustrare come funziona MarketMuse NLG Technology e la differenza tra gli approcci di MarketMuse NLG Technology e GPT-3.
Ecco un riassunto di quella conversazione.
I dati utilizzati per addestrare un modello di linguaggio naturale svolgono un ruolo fondamentale. MarketMuse è molto selettivo nei dati che utilizza per addestrare il suo modello di generazione del linguaggio naturale. Abbiamo filtri molto severi per garantire dati puliti che evitino pregiudizi su genere, razza e religione.
Inoltre, il nostro modello è formato esclusivamente su articoli ben strutturati. Non utilizziamo post di Reddit o post sui social media e simili. Anche se stiamo parlando di milioni di articoli, è comunque un insieme molto raffinato e curato rispetto alla quantità e al tipo di informazioni utilizzate in altri approcci. Durante l'addestramento del modello utilizziamo molti altri punti dati per strutturarlo, inclusi titolo, sottotitolo e argomenti correlati per ogni sottotitolo.
GPT-3 utilizza dati non filtrati da Common Crawl, Wikipedia e altre fonti. Non sono molto selettivi riguardo al tipo o alla qualità dei dati. Gli articoli ben formati rappresentano circa il 3% del contenuto web, il che significa che solo il 3% dei dati di allenamento per GPT-3 è costituito da articoli. Il loro modello non è progettato per scrivere articoli quando ci pensi in questo modo.
Perfezioniamo il nostro modello NLG con ogni richiesta di generazione. A questo punto raccogliamo qualche migliaio di articoli ben strutturati su un argomento specifico. Proprio come i dati utilizzati per l'addestramento del modello di base, questi devono passare attraverso tutti i nostri filtri di qualità. Gli articoli vengono analizzati per estrarre il titolo, le sottosezioni e gli argomenti correlati per ciascuna sottosezione. Introduciamo questi dati nel modello di formazione per un'altra fase di formazione. Questo porta il modello da uno stato in cui è in grado di parlare in generale di un argomento, a parlare più o meno come un esperto in materia.
Inoltre, MarketMuse NLG Technology utilizza meta tag come titolo, sottotitoli e argomenti correlati per fornire indicazioni durante la generazione del testo. Questo ci fornisce molto più controllo. Fondamentalmente insegna il modello in modo che quando genera il testo, includa quegli argomenti correlati importanti nel suo output.
GPT-3 non ha un contesto come questo; usa solo un paragrafo introduttivo. È follemente difficile mettere a punto il loro enorme modello e richiede una vasta infrastruttura solo per eseguire l'inferenza, per non parlare della messa a punto.
Per quanto stupefacente possa essere GPT-3, non pagherei un centesimo per usarlo. È inutilizzabile! Come mostra l'articolo del Guardian, trascorrerai molto tempo a modificare i molteplici output in un articolo pubblicabile.
Anche se il modello è buono, parlerà dell'argomento come farebbe qualsiasi normale essere umano non esperto. Ciò è dovuto al modo in cui il loro modello impara. In effetti, è più probabile che parli come un utente di social media perché questa è la maggior parte dei suoi dati di addestramento.
D'altra parte, MarketMuse NLG Technology viene addestrata su articoli ben strutturati e quindi messa a punto in modo specifico utilizzando articoli sull'argomento specifico della bozza. In questo modo, l'output della tecnologia MarketMuse NLG ricorda più da vicino i pensieri di un esperto rispetto a GPT-3.
Sommario
MarketMuse NLG Technology è stata creata per risolvere una sfida specifica; come aiutare i team dei contenuti a produrre contenuti migliori più velocemente. È un'estensione naturale dei nostri riassunti di contenuti basati sull'intelligenza artificiale già di successo.
Sebbene GPT-3 sia spettacolare dal punto di vista della ricerca, c'è ancora molta strada da fare prima che sia utilizzabile.
Cosa dovresti fare ora
Quando sei pronto... ecco 3 modi in cui possiamo aiutarti a pubblicare contenuti migliori, più velocemente:
- Prenota tempo con MarketMuse Pianifica una demo dal vivo con uno dei nostri strateghi per vedere come MarketMuse può aiutare il tuo team a raggiungere i propri obiettivi di contenuto.
- Se desideri imparare a creare contenuti migliori più velocemente, visita il nostro blog. È pieno di risorse per aiutare a ridimensionare i contenuti.
- Se conosci un altro marketer a cui piacerebbe leggere questa pagina, condividila con loro via e-mail, LinkedIn, Twitter o Facebook.