
Identificazione degli attributi soggettivi delle entità
Pubblicato: 2022-05-13Identificazione degli attributi soggettivi UGC delle entità
Questo brevetto recentemente concesso riguarda l'identificazione degli attributi soggettivi delle entità.
Non ho visto un brevetto sugli attributi soggettivi delle entità o sulle risposte a quelle entità.
Un aspetto critico è che si tratta di contenuti generati dagli utenti.
Ci viene detto che i contenuti generati dagli utenti (UGC) stanno diventando più comuni sul Web a causa della crescente popolarità di social network, blog, siti Web di recensioni, ecc.
Spesso vediamo contenuti generati dagli utenti sotto forma di commenti, come ad esempio:
- Un commento di un primo utente sul contenuto condiviso da un secondo utente all'interno di un social network
- Commenti degli utenti in risposta a un articolo nel blog di un giornalista
- Un commento da un video clip pubblicato su un sito Web di hosting di contenuti
- Recensioni (come di prodotti, film)
- Azioni (come Mi piace!, Non mi piace!, +1, condivisione, bookmarking, playlist, ecc.)
- Così via
In base a questo brevetto, viene fornito un modo per identificare e prevedere gli attributi soggettivi per le entità (come clip multimediali, immagini, articoli di giornali, post di blog, persone, organizzazioni, attività commerciali, ecc.).
Si inizia con:
- Identificare un primo insieme di attributi soggettivi per una prima entità sulla base di una reazione alla prima entità (come commenti su un sito Web, una dimostrazione di approvazione della prima entità (come "Mi piace!, ecc.)
- Condivisione della prima entità
- Aggiungere la prima entità ai segnalibri
- Aggiunta della prima entità a una playlist
- Addestrare un classificatore (come una macchina vettoriale di supporto, AdaBoost, una rete neurale, un albero decisionale su un insieme di mappature input-output, in cui l'insieme di mappature input-output comprende una mappatura input-output il cui input fornisce un vettore di funzionalità per la prima entità, il cui output si basa sul primo insieme di attributi soggettivi
- Fornire un vettore di caratteristiche per una seconda entità al classificatore addestrato per ottenere un secondo insieme di attributi soggettivi per la seconda entità
Vengono forniti una memoria e un processore per identificare e prevedere gli attributi soggettivi per le entità.
Un supporto di memorizzazione leggibile dal computer contiene istruzioni che fanno sì che un sistema informatico esegua operazioni, tra cui:
- Identificare un primo insieme di attributi soggettivi per una prima entità sulla base di una reazione alla prima entità
- Ottenere un primo vettore di feature per la prima entità
- Addestrare un classificatore su un insieme di mappature input-output, in cui l'insieme di mappature input-output comprende una mappatura input-output il cui input si basa sul primo vettore di caratteristiche e il cui output si basa sul primo insieme di attributi soggettivi
- Ottenere un secondo vettore di feature per una seconda entità
- Fornire al classificatore, dopo l'addestramento, il secondo vettore di caratteristiche per ottenere un secondo insieme di attributi soggettivi per la seconda entità
Questo brevetto sull'identificazione degli attributi soggettivi per le entità = si trova all'indirizzo:
Identificazione degli attributi soggettivi mediante l'analisi dei segnali di cura
Inventori: Hrishikesh Aradhye e Sanketh Shetty
Assegnatario: Google LLC
Brevetto USA: 11.328.218
Concesso: 10 maggio 2022
Archiviato: 6 novembre 2017
Astratto:
Vengono divulgati un sistema e un metodo per identificare e prevedere gli attributi soggettivi per le entità (come clip multimediali, film, programmi televisivi, immagini, articoli di giornali, post di blog, persone, organizzazioni, attività commerciali, ecc.).
In un aspetto, gli attributi soggettivi per un primo elemento multimediale vengono identificati in base a una reazione al primo elemento multimediale e vengono determinati i punteggi di pertinenza per le qualità personali relative al primo elemento multimediale.
Un classificatore viene addestrato utilizzando (i) un input di formazione comprendente un insieme di caratteristiche per il primo elemento multimediale e un output target per l'input di formazione, l'output target comprendendo i rispettivi punteggi di pertinenza per gli attributi soggettivi del primo elemento multimediale.
Identificazione e previsione degli attributi soggettivi per le entità
Modi per identificare e prevedere gli attributi soggettivi per le entità (come clip multimediali, immagini, articoli di giornali, post di blog, persone, organizzazioni, attività commerciali, ecc.).
Gli attributi soggettivi (come "carino", "divertente", "fantastico" ecc.) vengono definiti e gli attributi soggettivi per una particolare entità vengono identificati in base alla reazione dell'utente all'entità, come ad esempio:
- Commenti su un sito web
- Piace!
- Condivisione della prima entità con altri utenti
- Contrassegnare la prima entità
- Aggiunta della prima entità a una playlist
- Eccetera
I punteggi di pertinenza per gli attributi soggettivi vengono determinati sull'entità
Se l'attributo soggettivo "carino" appare in una proporzione significativa dei commenti per un video clip, allora "carino" può ricevere un punteggio di pertinenza elevato.
L'entità viene quindi associata agli attributi soggettivi identificati e ai punteggi di pertinenza (ad esempio tramite tag applicati all'entità, tramite voci in una tabella di un database relazionale, ecc.).
La procedura di cui sopra viene eseguita per ciascuna entità in un determinato insieme di entità (come clip video in un repository di clip video, ecc.) e viene generata una mappatura inversa dagli attributi soggettivi alle entità nel gruppo in base alle qualità personali e ai punteggi di pertinenza .
La mappatura inversa può quindi essere utilizzata per identificare tutte le entità nell'insieme che corrispondono a un determinato attributo soggettivo (come tutte le entità che sono state associate all'attributo soggettivo "divertente", ecc.), consentendo così:
- Recupero rapido di entità rilevanti per l'elaborazione di ricerche di parole chiave
- Popolamento delle playlist
- Consegnare annunci
- Generazione di set di addestramento per il classificatore
- Così via
Un classificatore (come una macchina vettoriale di supporto [SVM], AdaBoost, una rete neurale, un albero decisionale, ecc.) viene addestrato fornendo una serie di esempi di addestramento, in cui l'input per un esempio di addestramento comprende un vettore di caratteristiche ottenuto da un entità particolare (come un vettore di funzionalità per un clip video.
Può contenere valori numerici su:
- Colore
- Struttura
- Intensità
- Tag di metadati associati al clip video
- Eccetera
L'output ha punteggi di pertinenza per ogni attributo soggettivo nel vocabolario per l'entità particolare.
Il classificatore addestrato può quindi prevedere gli attributi soggettivi per le entità non nel set di addestramento (come un video clip appena caricato, un articolo di notizie che non ha ancora ricevuto commenti, ecc.).
Questo brevetto può classificare le entità in base ad attributi soggettivi come "divertente", "carino", ecc. In base alla reazione dell'utente alle entità.
Questo brevetto può migliorare la qualità delle descrizioni delle entità, come i tag di un video clip, migliorando la qualità delle ricerche e il targeting degli annunci pubblicitari.
Un'architettura di sistema per identificare gli attributi soggettivi
L'architettura del sistema comprende:
- Macchina server
- Negozio di entità
- Le macchine client sono connesse a una rete
La rete può essere pubblica (come Internet), una rete privata (come una rete locale (LAN) o una rete vasta (WAN)) o una combinazione di queste.
Le macchine client possono essere terminali wireless (smartphone, ecc.), personal computer (PC), laptop, tablet o qualsiasi altro dispositivo informatico o di comunicazione.
Le macchine client possono eseguire un sistema operativo (OS) che gestisce l'hardware e il software delle macchine client.
Un browser (non mostrato) può essere eseguito sui computer client (come nel sistema operativo dei computer client).
Il browser può essere un browser Web in grado di accedere a pagine Web e contenuti serviti da un server Web.
Le macchine client possono anche caricare:
- pagine web
- Clip multimediali
- Voci di blog
- link ad articoli
- Così via
La macchina server include un server web e un gestore di attributi soggettivi. Il server web e il gestore degli attributi emotivi possono essere eseguiti su dispositivi diversi.
L'Entity Store è una memoria persistente in grado di memorizzare entità come clip multimediali (come clip video, clip audio, clip contenenti sia video che audio, immagini, ecc.) e altri tipi di elementi di contenuto (come pagine Web, documenti basati su documenti, recensioni di ristoranti, recensioni di film, ecc.), nonché strutture di dati per contrassegnare, organizzare e indicizzare le entità.
L'Entity Store può essere ospitato da dispositivi di archiviazione, come memoria principale, dischi magnetici o basati su archiviazione ottica, nastri o dischi rigidi, NAS, SAN, ecc.
L'Entity Store potrebbe essere ospitato da un file server collegato alla rete. Al contrario, in altre implementazioni, l'Entity Store può essere ospitato da qualche altro tipo di archiviazione persistente come quella della macchina server o macchine diverse accoppiate alla macchina server tramite la rete.
Le entità archiviate nell'Entity Store possono includere contenuti generati dagli utenti che vengono caricati dalle macchine client e possono includere contenuti forniti da fornitori di servizi come:
- Testate giornalistiche
- Editori
- Biblioteche
- Presto
Il server può servire pagine Web e contenuti dagli archivi dell'entità ai client.
Il gestore degli attributi soggettivi:
- Identifica gli attributi soggettivi per le entità in base alla reazione dell'utente (come commenti, Mi piace!, condivisione, bookmarking, playlist, ecc.)
- Determina i punteggi di pertinenza per gli attributi soggettivi delle entità
- Associa attributi soggettivi e punteggi di pertinenza alle entità
- Estrae caratteristiche come caratteristiche dell'immagine come colore, trama e intensità; caratteristiche audio come ampiezza, rapporti di coefficienti spettrali; caratteristiche testuali come frequenze delle parole, lunghezza media delle frasi, parametri di formattazione; metadati associati all'entità; ecc.) dalle entità per generare vettori di caratteristiche
- Addestra un classificatore in base ai vettori delle caratteristiche e ai punteggi di pertinenza degli attributi soggettivi
- Utilizza il classificatore addestrato per prevedere gli attributi soggettivi per le nuove entità in base ai vettori delle caratteristiche delle nuove entità
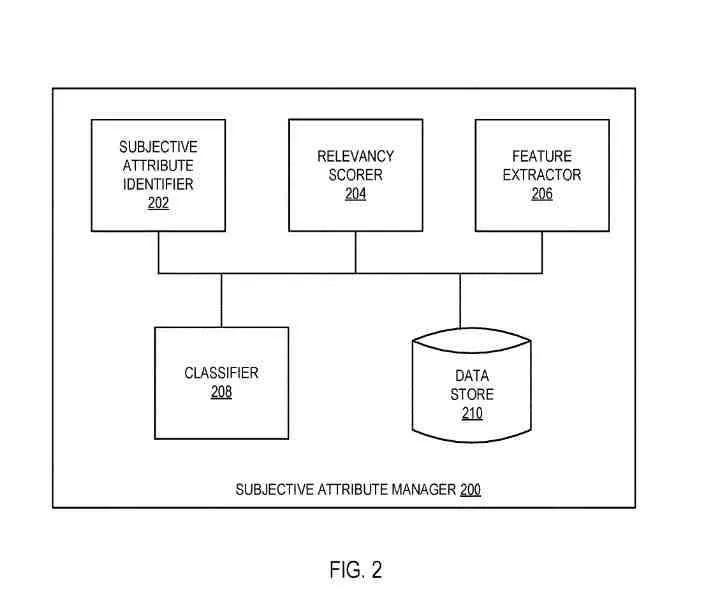
Un gestore di attributi soggettivi
Il gestore dell'attributo soggettivo può essere lo stesso del gestore dell'attributo soggettivo e può includere:
- Identificatore di attributo soggettivo
- Marcatore di pertinenza
- Estrattore di funzionalità
- Classificatore
- Archivio dati
.
I componenti possono essere combinati o separati in ulteriori dettagli.
L'archivio dati può essere lo stesso dell'archivio entità o un archivio dati diverso (come un buffer temporaneo o un archivio dati permanente) per contenere un vocabolario di attributi personali, entità che devono essere elaborate, vettori di funzionalità associati a entità, attributi personali e punteggi di pertinenza relativi alle entità o a una combinazione di questi dati.
Il datastore può essere ospitato da dispositivi di archiviazione, come memoria principale, dischi magnetici o ottici, nastri o dischi rigidi, ecc.
Il gestore dell'attributo soggettivo notifica agli utenti i tipi di informazioni archiviate nell'archivio dati e nell'archivio entità e consente agli utenti di scegliere di non raccogliere e condividere tali informazioni con il gestore dell'attributo soggettivo.
L'identificatore di attributo soggettivo
L'identificatore dell'attributo personale identifica gli attributi soggettivi per le entità in base alla reazione dell'utente alle entità.
L'identificatore di attributo personale può identificare attributi soggettivi tramite l'elaborazione del testo dei commenti degli utenti a un'entità pubblicata da un utente su un sito di social network.
L'identificatore di attributo soggettivo può identificare gli attributi soggettivi per le entità sulla base di altri tipi di reazioni dell'utente alle entità, come ad esempio:
- 'Piace!' o "Non mi piace!"
- Condivisione dell'entità
- Aggiungere l'entità ai preferiti
- Aggiunta dell'entità a una playlist
- Così via
L'identificatore di attributo personale può applicare soglie per determinare quali attributi sono associati a un'entità (come un attributo soggettivo dovrebbe apparire in almeno N commenti, ecc.).
Il punteggio di pertinenza determina i punteggi di pertinenza per gli attributi soggettivi delle entità.
Ad esempio, quando l'identificatore di attributo soggettivo ha identificato gli attributi soggettivi "carino", "divertente" e "fantastico" in base ai commenti a un clip multimediale pubblicato su un sito Web di social network, il punteggio di pertinenza può determinare i punteggi di pertinenza per ciascuno di questi tre punteggi soggettivi attributi basati su:
- La frequenza con cui questi attributi soggettivi compaiono nei commenti
- Gli utenti particolari che hanno fornito gli attributi soggettivi
- Così via
Ad esempio, se ci sono 40 commenti e "carino" appare in 20 parole e "fantastico" compare in 8 commenti, allora "carino" potrebbe ricevere un punteggio di pertinenza superiore a "fantastico".
I punteggi di pertinenza possono essere assegnati in base alla proporzione di commenti in cui appare un attributo soggettivo (come un punteggio di 0,5 per "carino" e un punteggio di 0,2 per "fantastico", ecc.).
Il marcatore di pertinenza può mantenere solo i k attributi soggettivi più rilevanti e scartare altri attributi personali.
Ad esempio, supponiamo che l'identificatore di attributo personale identifichi sette attributi emotivi che compaiono nei commenti degli utenti almeno tre volte. In tal caso, il valutatore di pertinenza può, ad esempio, conservare solo i cinque attributi soggettivi con i punteggi di pertinenza più alti e scartare gli altri due attributi emotivi (ad esempio impostando i punteggi di pertinenza su zero, ecc.).
Un punteggio di pertinenza è un numero naturale compreso tra 0,0 e 1,0 inclusi.
L'estrattore di funzionalità ottiene un vettore di funzionalità per un'entità utilizzando tecniche quali:
- Analisi delle componenti principali
- Incastri semidefiniti
- isomap
- Minimi quadrati parziali
- Così via
I calcoli associati all'estrazione di funzionalità di un'entità vengono eseguiti dall'estrattore di funzionalità stesso.

In alcuni altri aspetti questi calcoli vengono eseguiti da un'altra entità, come una libreria eseguibile di:
- Routine di elaborazione delle immagini ospitate dalla macchina server [non rappresentate nelle figure]
- Routine di elaborazione audio
- Routine di elaborazione del testo
- Eccetera
I risultati vengono forniti all'estrattore di funzionalità.
Il classificatore è una macchina di apprendimento (come macchine vettoriali di supporto [SVM], AdaBoost, reti neurali, alberi decisionali, ecc.) che accetta come input un vettore di funzionalità associato a un'entità e restituisce punteggi di pertinenza (come un numero effettivo compreso tra 0 e 1 compreso, ecc.) per ogni attributo soggettivo del vocabolario degli attributi personali.
Il classificatore è costituito da un unico classificatore.
Il classificatore può includere più classificatori (come un classificatore per ogni attributo soggettivo nel vocabolario degli attributi personali, ecc.).
Una serie di esempi positivi e criteri negativi sono assemblati per ogni attributo soggettivo nel vocabolario degli attributi personali.
L'insieme di esempi positivi per un attributo soggettivo può includere vettori di caratteristiche per entità associate a quel particolare attributo personale.
L'insieme di esempi negativi per un attributo soggettivo può includere vettori di caratteristiche per entità che non sono state associate a quel particolare attributo personale.
Quando l'insieme degli esempi positivi e l'insieme dei criteri negativi sono di dimensioni diverse, l'insieme più ampio può essere campionato per corrispondere alle dimensioni del gruppo più piccolo.
Dopo l'addestramento, il classificatore può prevedere attributi soggettivi per altre entità non nel set di addestramento fornendo vettori di caratteristiche per queste entità come input per il classificatore.
Un insieme di attributi soggettivi può essere ottenuto dall'output del classificatore includendo tutti gli attributi emotivi con punteggi di pertinenza diversi da zero. Un gruppo di punti soggettivi può essere ottenuto applicando la soglia più piccola ai punteggi numerici (considerando tutti gli attributi personali che hanno un punteggio di almeno, diciamo, 0,2 come membri dell'insieme).
Identificazione degli attributi soggettivi delle entità
Il metodo viene eseguito mediante l'elaborazione della logica che può comprendere hardware (circuito, logica dedicata, ecc.), Software (come viene eseguito su un sistema informatico generico o una macchina dedicata) o entrambi.
Il metodo viene eseguito dalla macchina server, mentre alcune altre implementazioni possono essere eseguite da un altro dispositivo.
Vari componenti dei gestori di attributi soggettivi possono essere eseguiti su macchine separate (come l'identificatore di attributo personale e il punteggio di pertinenza possono essere eseguiti su un dispositivo mentre l'estrattore di funzionalità e il classificatore vengono eseguiti su un altro dispositivo, ecc.).
Per semplicità di spiegazione, il metodo viene rappresentato e descritto come una serie di atti.
Ma gli atti possono verificarsi in vari ordini e con altri atti qui non presentati e descritti.
Inoltre, non tutti gli atti illustrati possono essere obbligati ad installare le modalità dall'oggetto della comunicazione.
Inoltre, gli esperti del ramo comprenderanno e apprezzeranno che il metodo potrebbe essere rappresentato come una serie di stati interconnessi tramite un diagramma di stato o eventi.
Inoltre, si dovrebbe apprezzare che i metodi descritti in questa descrizione sono in grado di essere memorizzati su un articolo di fabbricazione per facilitare il trasporto e il trasferimento di tali metodologie ai dispositivi informatici.
Il termine articolo di fabbricazione, come qui utilizzato, viene inteso a comprendere un programma per computer accessibile da qualsiasi dispositivo leggibile da computer o supporto di memorizzazione.
Viene generato un vocabolario di attributi soggettivi.
In alcuni aspetti, il vocabolario degli attributi soggettivi può essere definito. Al contrario, in alcuni altri fattori, il vocabolario degli attributi personali può essere generato in modo automatizzato raccogliendo termini e frasi che vengono utilizzati nelle reazioni degli utenti alle entità. Al contrario, in altri aspetti ancora, il vocabolario può essere generato da una combinazione di tecniche manuali e automatizzate.
Il vocabolario viene seminato con un piccolo numero di attributi soggettivi che dovrebbero essere applicati alle entità. Il vocabolario viene ampliato nel tempo man mano che più termini o frasi che compaiono nelle reazioni degli utenti vengono identificati tramite l'elaborazione automatizzata delle risposte.
Il vocabolario degli attributi soggettivi può essere organizzato gerarchicamente, possibilmente sulla base di "meta attributi" associati agli attributi personali (come l'attributo personale "divertente" può avere un metaattributo "positivo", mentre il punto soggettivo "disgustoso" può avere un meta-attributo "negativo", ecc.).
Viene preelaborato un insieme S di entità (come tutte le entità nell'archivio entità, un sottoinsieme di entità nell'archivio entità e così via).
Sotto un aspetto, la pre-elaborazione delle entità comprende l'identificazione delle reazioni degli utenti alle entità e quindi la formazione di un classificatore basato sulle risposte.
Quando un'entità è un'entità fisica reale
Va notato che quando un'entità è un'entità fisica reale (come una persona, un ristorante, ecc.), la pre-elaborazione dell'entità viene eseguita tramite un "cyber proxy" associato all'entità fisica (come un fan page di un attore su un sito di social network, una recensione di un ristorante su un sito web, ecc.); ma gli attributi soggettivi vengono considerati per essere associati all'entità stessa (come l'attore o il ristorante, non la fan page dell'attore o la recensione del ristorante).
Un esempio di metodo per eseguire viene descritto in dettaglio.
Viene ricevuta l'entità Atn E che non è nel set S (come un video clip appena caricato, un articolo di notizie che non ha ancora ricevuto alcun commento, un'entità nell'entity store che non è stata inclusa nel set di addestramento, ecc.).
Vengono ottenuti gli attributi del soggetto e i punteggi di pertinenza per l'entità E.
Di seguito viene descritta in dettaglio un'implementazione di un primo metodo di esempio e vengono descritte le prestazioni di un secondo metodo di esempio.
Gli attributi soggettivi e i punteggi di pertinenza ottenuti sono associati all'entità E (ad esempio applicando tag corrispondenti all'entità, aggiungendo un record in una tabella di database relazionale, ecc.).
L'esecuzione continua indietro.
Va notato che il classificatore può essere riqualificato (ad esempio dopo ogni 100 iterazioni del ciclo, ogni N giorni, ecc.) da un processo di riqualificazione che può essere eseguito contemporaneamente.
Pre-elaborazione di un insieme di entità
Il metodo viene eseguito mediante l'elaborazione della logica che può comprendere hardware (circuito, logica dedicata, ecc.), Software (come viene eseguito su un sistema informatico generico o una macchina dedicata) o entrambi.
Il metodo viene eseguito, mentre in alcune altre implementazioni può essere eseguito da un'altra macchina.
Il training set viene inizializzato sul set vuoto. Un'entità E viene selezionata e rimossa dall'insieme S di entità.
Gli attributi soggettivi per l'entità E sono identificati in base alle reazioni dell'utente all'entità E (come commenti utente, Mi piace!, bookmarking, condivisione, aggiunta a una playlist, ecc.).
L'identificazione degli attributi soggettivi include l'elaborazione dei commenti degli utenti, ad esempio da parte di:
- Abbinare le parole nei commenti degli utenti con gli attributi soggettivi nel vocabolario
- Combinando la corrispondenza delle parole e altre tecniche di elaborazione del linguaggio naturale come l'analisi sintattica e semantica
- Eccetera
Entità che si verificano vicino a posizioni
Le reazioni degli utenti possono essere aggregate per entità che si verificano in molte posizioni, come ad esempio:
- Entità che appaiono nelle playlist di molti utenti
- Entità che sono state condivise e appaiono in una pluralità di “newsfeed” degli utenti su un sito di social network
- Eccetera
Le diverse posizioni possono essere ponderate nel loro contributo ai punteggi di pertinenza in base a una varietà di fattori, come ad esempio:
L'utente specifico associato alla posizione (ad esempio un utente specifico può essere un'autorità sulla musica classica e quindi i commenti su un'entità nel proprio feed di notizie possono avere un peso maggiore rispetto ai commenti in un altro feed di notizie, ecc.), reazioni dell'utente non testuali (come come "Mi piace!", "Non mi piace!", "+1", ecc.).
Inoltre, il numero di posizioni in cui appare l'entità può essere utilizzato anche per determinare gli attributi soggettivi e i punteggi di pertinenza (come i punteggi di pertinenza di un video clip possono essere aumentati quando il video clip si trova in centinaia di playlist utente, ecc.).
Il blocco viene eseguito dall'identificatore di attributo soggettivo.
I punteggi di pertinenza per gli attributi soggettivi vengono determinati dall'entità E.
Un punteggio di pertinenza è determinato per un particolare attributo soggettivo in base alla frequenza con cui l'attributo personale appare nei commenti degli utenti, gli utenti specifici che hanno fornito i dettagli soggettivi nelle loro parole (come alcuni utenti potrebbero essere conosciuti dall'esperienza per essere più accurati nel loro commenti rispetto ad altri utenti, ecc.).
Ad esempio, se ci sono 40 commenti e "carino" appare in 20 parole e "fantastico" compare in 8 commenti, allora "carino" potrebbe ricevere un punteggio di pertinenza superiore a "fantastico".
I punteggi di pertinenza possono essere assegnati in base alla proporzione di commenti in cui compare un attributo soggettivo (come un punteggio di 0,5 per "carino" e un punteggio di 0,2 per "fantastico", ecc.).
Sotto un aspetto, i punteggi di pertinenza vengono normalizzati per cadere in intervalli [0, 1].
Per alcuni aspetti, gli attributi soggettivi identificati possono essere scartati in base ai loro punteggi di pertinenza (come mantenere i k attributi emotivi con i punteggi di pertinenza più alti, scartare qualsiasi attributo personale il cui punteggio di pertinenza è inferiore a una soglia, ecc.).
Va notato che un attributo soggettivo può essere scartato impostando il suo punteggio di pertinenza a zero in alcuni aspetti.
Gli attributi soggettivi e i punteggi di pertinenza sono associati alle entità
Gli attributi soggettivi e i punteggi di pertinenza sono associati alle entità (ad esempio tramite tagging, voci in una tabella in un database relazionale, ecc.).
Viene ottenuto un vettore di caratteristiche per l'entità E.
In un aspetto, il vettore di funzionalità per un clip video o un'immagine fissa può contenere valori numerici su colore, trama, intensità, ecc., mentre il vettore di funzionalità per un clip audio (o un clip video con suono) può includere valori numerici sull'ampiezza , coefficienti spettrali, ecc., mentre il vettore di caratteristiche per un documento di testo può includere:
- Valori numerici sulle frequenze delle parole
- Lunghezza media della frase
- Parametri di formattazione
- Così via
Questo potrebbe essere eseguito dall'estrattore di funzionalità.
Il vettore di funzionalità e i punteggi di pertinenza ottenuti vengono aggiunti al set di formazione.
Il bock controlla se l'insieme S di entità è vuoto; se S non è vuoto, l'esecuzione continua, altrimenti l'esecuzione procede.
Il classificatore viene addestrato su tutti gli esempi del set di addestramento, in modo tale che il vettore di funzionalità di un esempio di addestramento venga fornito come input al classificatore e i punteggi di pertinenza degli attributi soggettivi vengano forniti come output.
Ottenere attributi soggettivi e punteggi di pertinenza per un'entità
Viene generato un vettore di feature per l'entità E.
Come descritto sopra, il vettore di funzionalità per un clip video o un'immagine fissa può contenere valori numerici su colore, trama, intensità, ecc. Al contrario, il vettore di funzionalità per un clip audio (o un clip video con suono) può includere valori numerici sull'ampiezza, sui coefficienti spettrali, ecc. Al contrario, il vettore di caratteristiche per un documento di testo può includere valori numerici sulle frequenze delle parole, sulla lunghezza media delle frasi, sui parametri di formattazione e così via.
Il classificatore addestrato fornisce il vettore delle caratteristiche per ottenere attributi soggettivi previsti e punteggi di pertinenza per l'entità E.
Gli attributi soggettivi previsti e i punteggi di pertinenza vengono associati all'entità E (ad esempio tramite tag applicati all'entità E, tramite voci in una tabella di un database relazionale, ecc.).
Un secondo metodo per ottenere attributi soggettivi e punteggi di pertinenza per un'entità
Il metodo viene eseguito elaborando la logica che può comprendere hardware (circuito, logica dedicata, ecc.), Software o una combinazione di entrambi.
Il metodo viene eseguito dalla macchina server, mentre altri possono essere eseguiti da un altro dispositivo.
Viene generato un vettore di feature per l'entità E. Il classificatore addestrato fornisce il vettore delle caratteristiche per ottenere attributi soggettivi previsti e punteggi di pertinenza per l'entità E.
Gli attributi soggettivi previsti ottenuti vengono suggeriti a un utente (come l'utente che ha caricato l'entità. Un insieme raffinato di attributi personali viene ottenuto dall'utente, ad esempio tramite una pagina Web in cui l'utente seleziona tra gli attributi suggeriti ed eventualmente aggiunge nuovi attributi, ecc.).
Un punteggio di pertinenza predefinito per le entità
Un punteggio di pertinenza predefinito viene assegnato a tutti i nuovi attributi soggettivi aggiunti dall'utente.
Il punteggio di pertinenza predefinito può essere 1,0 su una scala da 0,0 a 1,0, il punteggio di pertinenza predefinito può essere basato sull'utente in particolare (ad esempio un punteggio di 1,0 quando l'utente è noto dalla storia passata per essere molto bravo a suggerire attributi, un punteggio di 0,8 quando l'utente è noto per essere in qualche modo bravo a suggerire attributi, ecc.).
I rami di blocco si basano sul fatto che l'utente abbia rimosso uno qualsiasi degli attributi soggettivi suggeriti (ad esempio non selezionando l'attributo).
L'entità E viene archiviata come esempio negativo degli attributi rimossi per il riaddestramento futuro del classificatore. Il raffinato insieme di attributi soggettivi e i corrispondenti punteggi di pertinenza sono associati all'entità E (ad esempio tramite tag applicati all'entità E, tramite voci in una tabella di un database relazionale, ecc.).