
Noindex Nofollow e Disallow: direttive del crawler di ricerca
Pubblicato: 2022-12-01Ci sono tre direttive (comandi) che puoi utilizzare per dettare come i motori di ricerca scoprono, memorizzano e forniscono informazioni dal tuo sito come risultati di ricerca:
- NoIndex: non aggiungere la mia pagina ai risultati di ricerca.
- NoFollow: non guardare i link in questa pagina.
- Disallow: non guardare affatto questa pagina.
Queste direttive ti consentono di controllare quali pagine del tuo sito possono essere scansionate dai motori di ricerca e apparire nella ricerca.
Cosa significa Nessun indice?
La direttiva noindex dice ai crawler di ricerca, come googlebot, di non includere una pagina web nei risultati di ricerca.

Come si contrassegna una pagina NoIndex?
Esistono due modi per emettere una direttiva noindex :
- Aggiungi un meta tag noindex al codice HTML della pagina
- Restituisce un'intestazione noindex nella richiesta HTTP
Utilizzando il meta tag "no index" per una pagina o come intestazione di risposta HTTP, stai essenzialmente nascondendo la pagina dalla ricerca.
La direttiva noindex può anche essere utilizzata per bloccare solo specifici motori di ricerca. Ad esempio, puoi impedire a Google di indicizzare una pagina ma consentire comunque a Bing:
Esempio: blocco della maggior parte dei motori di ricerca*
<meta name=”robots” content=”noindex”>
Esempio: blocco solo di Google
<meta name=”googlebot” content=”noindex”>
Nota: a partire da settembre 2019, Google non rispetta più le direttive noindex nel file robots.txt . Noindex ora DEVE essere emesso tramite meta tag HTML o intestazione di risposta HTTP. Per gli utenti più avanzati, disallow funziona ancora per ora, anche se non per tutti i casi d'uso.
Qual è la differenza tra noindex e nofollow?
C'è una differenza tra l'archiviazione di contenuti e la scoperta di contenuti:
noindex viene applicato a livello di pagina e indica a un crawler del motore di ricerca di non indicizzare e pubblicare una pagina nei risultati di ricerca.
nofollow viene applicato a livello di pagina o di collegamento e indica al crawler di un motore di ricerca di non seguire (scoprire) i collegamenti.
Essenzialmente il tag noindex rimuove una pagina dall'indice di ricerca e un attributo nofollow rimuove un collegamento dal grafico dei collegamenti del motore di ricerca.
NoFollow come attributo della pagina
L'utilizzo di nofollow a livello di pagina significa che i crawler non seguiranno nessuno dei collegamenti su quella pagina per scoprire contenuti aggiuntivi e i crawler non utilizzeranno i collegamenti come segnali di classificazione per i siti di destinazione.
<meta name=”robots” content=”nofollow”>
NoFollow come attributo di collegamento
L'utilizzo di nofollow a livello di collegamento impedisce ai crawler di esplorare il collegamento specifico dell'annuncio e impedisce che tale collegamento venga utilizzato come segnale di ranking.
La direttiva nofollow viene applicata a livello di collegamento utilizzando un attributo rel all'interno del tag a href:
<a href=”https://domain.com” rel=”nofollow”>
Per Google in particolare, l'utilizzo dell'attributo link nofollow impedirà al tuo sito di trasferire il PageRank agli URL di destinazione.
Perché dovresti contrassegnare una pagina come NoFollow?
Per la maggior parte dei casi d'uso, non dovresti contrassegnare un'intera pagina come nofollow: sarà sufficiente contrassegnare i singoli collegamenti come nofollow.
Contrassegneresti un'intera pagina come nofollow se non desideri che Google visualizzi i collegamenti sulla pagina o se ritieni che i collegamenti sulla pagina possano danneggiare il tuo sito.
Nella maggior parte dei casi, le direttive generali nofollow a livello di pagina vengono utilizzate quando non si ha il controllo sul contenuto pubblicato su una pagina Alcuni editori di fascia alta hanno anche applicato la direttiva nofollow alle loro pagine per dissuadere i loro autori dall'inserire link sponsorizzati all'interno dei loro contenuti.
Come utilizzo le pagine NoIndex?
Contrassegna le pagine come noindex che difficilmente forniranno valore agli utenti e non dovrebbero essere visualizzate come risultati di ricerca. Ad esempio, è improbabile che le pagine esistenti per l'impaginazione abbiano lo stesso contenuto visualizzato nel tempo.
È improbabile che Domain.com/category/resultspage=2 mostri a un utente risultati migliori rispetto a domain.com/category/resultspage=1 e le due pagine competono solo tra loro nella ricerca. È meglio non indicizzare le pagine il cui unico scopo è l'impaginazione.
Ecco i tipi di pagine che dovresti considerare noindexing:
- Pagine utilizzate per l'impaginazione
- Pagine di ricerca interne
- Pagine di destinazione ottimizzate per gli annunci
- Es: mostra solo una presentazione e un modulo di iscrizione, nessuna navigazione principale
- Es: varianti duplicate dello stesso contenuto, utilizzate solo per gli annunci
- Pagine dell'autore archiviate
- Pagine nei flussi di pagamento
- Pagine di conferma
- Es: pagine di ringraziamento
- Es: ordina pagine complete
- Es: successo! Pagine
- Alcune pagine generate da plug-in che non sono rilevanti per il tuo sito (es: se utilizzi un plug-in commerciale ma non utilizzi le normali pagine dei prodotti)
- Pagine di amministrazione e pagine di accesso dell'amministratore
Contrassegnare una pagina Noindex e Nofollow
Una pagina contrassegnata sia noindex che nofollow bloccherà un crawler dall'indicizzare quella pagina e impedirà a un crawler di esplorare i collegamenti sulla pagina.
In sostanza, l'immagine qui sotto mostra cosa vedrà un motore di ricerca su una pagina web a seconda di come hai usato le direttive noindex e nofollow:

Contrassegnare una pagina già indicizzata come NoIndex
Se un motore di ricerca ha già indicizzato una pagina e la contrassegni come noindex , la prossima volta che la pagina viene scansionata verrà rimossa dai risultati di ricerca Affinché questo metodo di rimozione di una pagina dall'indice funzioni, non devi bloccare (non consentire) il crawler con il tuo file robots.txt.
Se stai dicendo a un crawler di non leggere la pagina, non vedrà mai l'indicatore noindex e la pagina rimarrà indicizzata anche se il suo contenuto non verrà aggiornato.
Come posso impedire ai motori di ricerca di indicizzare il mio sito?
Se desideri rimuovere una pagina dall'indice di ricerca, dopo che è già stata indicizzata, puoi completare i seguenti passaggi:
- Applicare la direttiva noindex Aggiungere l'attributo noindex al meta tag o all'intestazione della risposta HTTP
- Richiedi al motore di ricerca di eseguire la scansione della pagina Per Google puoi farlo nella console di ricerca, richiedi a Google di reindicizzare la pagina. Ciò attiverà Googlebot che esegue la scansione della pagina, dove Googlebot scoprirà la direttiva noindex. Dovrai eseguire questa operazione per ogni motore di ricerca che desideri rimuovere dalla pagina.
- Conferma che la pagina è stata rimossa dalla ricerca Una volta che hai chiesto al crawler di rivisitare la tua pagina web, attendi un po' di tempo, quindi conferma che la tua pagina è stata rimossa dai risultati di ricerca. Puoi farlo andando su qualsiasi motore di ricerca e inserendo l'URL di destinazione dei due punti del sito, come nell'immagine qui sotto.
Se la tua ricerca non restituisce risultati, la tua pagina è stata rimossa dall'indice di ricerca. - Se la pagina non è stata rimossa Verifica di non avere una direttiva "disallow" nel tuo file robots.txt. Google e altri motori di ricerca non possono leggere la direttiva noindex se non sono autorizzati a eseguire la scansione della pagina. Se lo fai, rimuovi la direttiva disallow per la pagina di destinazione, quindi richiedi nuovamente la scansione.
- Imposta una direttiva disallow per la pagina di destinazione nel tuo file robots.txt Disallow: /page$
Dovrai inserire il simbolo del dollaro alla fine dell'URL nel tuo file robots.txt o potresti accidentalmente non consentire alcuna pagina sotto quella pagina, così come qualsiasi pagina che inizia con la stessa stringa. Es: Disallow: /sweater non consentirà anche /sweater-weather e /sweater/green, ma Disallow: /sweater$ non consentirà solo la pagina esatta /sweater.
Come per rimuovere una pagina dalla ricerca di Google
Se la pagina che vuoi rimuovere dalla ricerca si trova su un sito che possiedi o gestisci, la maggior parte dei siti può utilizzare lo Strumento per la rimozione degli URL dei webmaster.
Lo strumento per la rimozione degli URL dei webmaster rimuove i contenuti dalla ricerca solo per circa 90 giorni, se desideri una soluzione più permanente dovrai utilizzare una direttiva noindex, non consentire la scansione dal tuo file robots.txt o rimuovere la pagina dal tuo sito. Google fornisce ulteriori istruzioni per la rimozione permanente dell'URL qui.

Se stai tentando di rimuovere una pagina dalla ricerca di un sito di cui non sei il proprietario, puoi richiedere a Google di rimuovere la pagina dalla ricerca se soddisfa i seguenti criteri:
- Visualizza informazioni personali come la carta di credito o il numero di previdenza sociale
- La pagina fa parte di uno schema di malware o phishing
- La pagina viola la legge
- La pagina viola un copyright
Se la pagina non soddisfa uno dei criteri di cui sopra, puoi contattare un'azienda SEO o una società di pubbliche relazioni per assistenza nella gestione della reputazione online.
Dovresti noindex pagine di categoria?
Di solito non è consigliabile non indicizzare le pagine di categoria, a meno che tu non sia un'organizzazione a livello aziendale che crea pagine di categoria in modo programmatico in base a ricerche o tag generati dall'utente e il contenuto duplicato sta diventando ingombrante.
Per la maggior parte, se tagghi i tuoi contenuti in modo intelligente, in un modo che aiuti gli utenti a navigare meglio nel tuo sito e a trovare ciò di cui hanno bisogno, allora starai bene.
In effetti, le pagine delle categorie possono essere una miniera d'oro per la SEO poiché in genere mostrano una profondità di contenuto sotto gli argomenti della categoria.
Dai un'occhiata a questa analisi che abbiamo fatto a dicembre 2018 per quantificare il valore delle pagine di categoria per una manciata di pubblicazioni online.
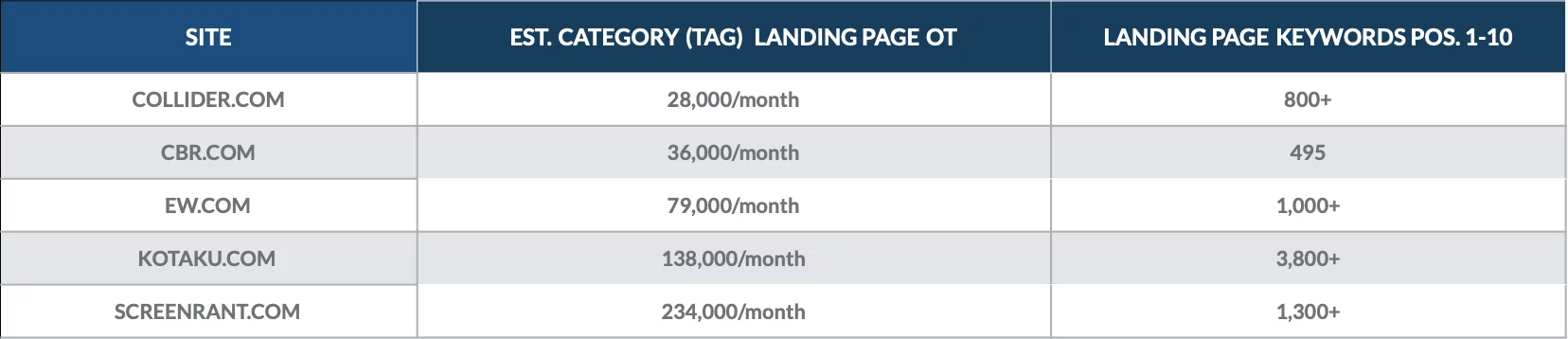
Abbiamo scoperto che le pagine di destinazione di categoria si classificavano per centinaia di parole chiave della pagina 1 e portavano migliaia di visitatori organici ogni mese.
Le pagine di categoria più preziose per ciascun sito spesso hanno portato migliaia di visitatori organici ciascuna.
Dai un'occhiata a EW.com qui sotto, abbiamo misurato il traffico verso ogni pagina (rappresentato dalla dimensione del cerchio) e il valore del traffico verso ogni pagina (rappresentato dal colore del cerchio).
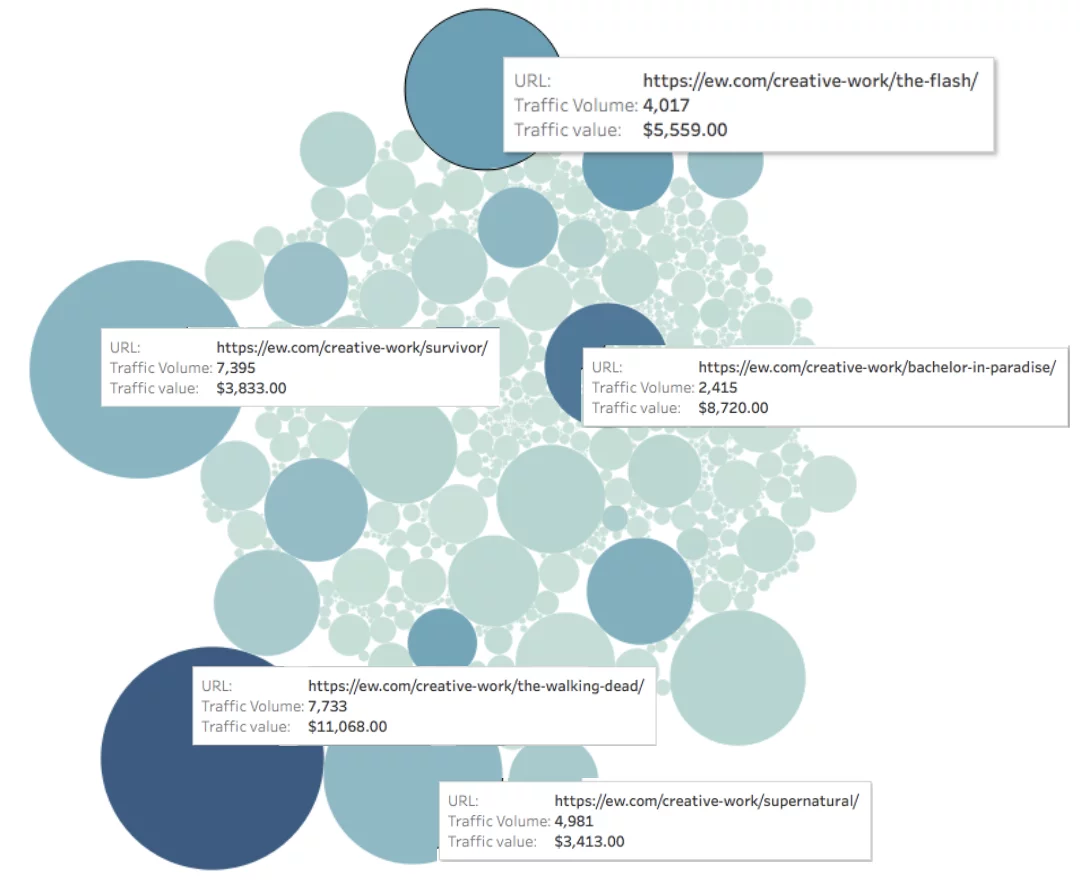
Valore organico mensile della pagina = Profondità del colore
Ora immagina gli stessi grafici, ma per i siti basati sui prodotti in cui è probabile che i visitatori effettuino acquisti attivi.
Detto questo, se le tue categorie sono abbastanza simili da causare confusione negli utenti o competere tra loro nella ricerca, potrebbe essere necessario apportare una modifica:
- Se imposti tu stesso le categorie, ti consigliamo di migrare i contenuti da una categoria all'altra e di ridurre il numero totale di categorie che hai complessivamente.
- Se si consente agli utenti di creare categorie, allora si consiglia di non indicizzare le pagine delle categorie generate dagli utenti, almeno fino a quando le nuove categorie non sono state sottoposte a un processo di revisione.
Come posso impedire a Google di indicizzare i sottodomini?
Esistono alcune opzioni per impedire a Google di indicizzare i sottodomini:
- Puoi aggiungere una password utilizzando un file .htpasswd
- Puoi disattivare i crawler con un file robots.txt
- Puoi aggiungere una direttiva noindex a ogni pagina del sottodominio
- Puoi eseguire il 404 su tutte le pagine del sottodominio
Aggiunta di una password per bloccare l'indicizzazione
Se i tuoi sottodomini sono a scopo di sviluppo, l'aggiunta di un file .htpasswd alla directory principale del tuo sottodominio è l'opzione perfetta. Il muro di accesso impedirà ai crawler di indicizzare i contenuti nel sottodominio e impedirà l'accesso di utenti non autorizzati.
Esempi di casi d'uso:
- Dev.dominio.com
- Staging.dominio.com
- Testing.dominio.com
- QA.dominio.com
- UAT.dominio.com
Utilizzo di robots.txt per bloccare l'indicizzazione
Se i tuoi sottodomini hanno altri scopi, puoi aggiungere un file robots.txt alla directory principale del tuo sottodominio. Dovrebbe quindi essere accessibile come segue:
https://sottodominio.dominio.com/robots.txt
Dovrai aggiungere un file robots.txt a ciascun sottodominio che stai tentando di bloccare dalla ricerca. Esempio:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
In ogni caso il file robots.txt non dovrebbe consentire i crawler, per bloccare la maggior parte dei crawler con un singolo comando, utilizzare il seguente codice:
Agente utente: *
Non consentire: /
La stella * dopo user-agent: è chiamata carattere jolly, corrisponderà a qualsiasi sequenza di caratteri. L'utilizzo di un carattere jolly invierà la seguente direttiva disallow a tutti gli agenti utente indipendentemente dal loro nome, da googlebot a yandex.
La barra rovesciata indica al crawler che tutte le pagine al di fuori del sottodominio sono incluse nella direttiva disallow.
Come bloccare in modo selettivo l'indicizzazione delle pagine del sottodominio
Se desideri che alcune pagine di un sottodominio vengano visualizzate nella ricerca, ma non altre, hai due opzioni:
- Usa le direttive noindex a livello di pagina
- Utilizzare le direttive disallow a livello di cartella o directory
Le direttive noindex a livello di pagina saranno più complicate da implementare, poiché la direttiva deve essere aggiunta all'HTML o all'intestazione di ogni pagina. Tuttavia, le direttive noindex impediranno a Google di indicizzare un sottodominio indipendentemente dal fatto che il sottodominio sia già stato indicizzato o meno.
Le direttive disallow a livello di directory sono più facili da implementare, ma funzioneranno solo se le pagine del sottodominio non sono già nell'indice di ricerca. Aggiorna semplicemente il file robots.txt del sottodominio per impedire la scansione delle directory o delle sottocartelle applicabili.
Come faccio a sapere se le mie pagine sono NoIndexed?
L'aggiunta accidentale di pagine senza direttiva indice sul tuo sito può avere conseguenze drastiche per le classifiche di ricerca e la visibilità della ricerca.
Se trovi che una pagina non riceve traffico organico nonostante buoni contenuti e backlink, controlla prima di tutto di non aver accidentalmente disabilitato i crawler dal tuo file robots.txt. Se ciò non risolve il tuo problema, dovrai controllare le singole pagine per le direttive noindex.
Verifica della presenza di NoIndex nelle pagine di WordPress
WordPress semplifica l'aggiunta o la rimozione di questo tag sulle tue pagine. Il primo passo per verificare la presenza di nofollow sulle tue pagine è semplicemente attivare o disattivare l'impostazione Visibilità sui motori di ricerca all'interno della scheda "Lettura" del menu "Impostazioni".
Questo probabilmente risolverà il problema, tuttavia questa impostazione funziona come un "suggerimento" piuttosto che come una regola e alcuni dei tuoi contenuti potrebbero comunque essere indicizzati.
Per garantire la privacy assoluta dei tuoi file e contenuti, dovrai compiere un ultimo passaggio proteggendo con password il tuo sito utilizzando gli strumenti di gestione cPanel, se disponibili, o tramite un semplice plug-in.
Allo stesso modo, la rimozione di questo tag dai tuoi contenuti può essere eseguita rimuovendo la protezione con password e deselezionando l'impostazione di visibilità.
Controllo di NoIndex su Squarespace
Le pagine di Squarespace sono anche facilmente NoIndexed utilizzando la funzionalità di Code Injection della piattaforma. Come WordPress, Squarespace può essere facilmente bloccato dalle ricerche di routine utilizzando la protezione tramite password, tuttavia la piattaforma sconsiglia anche di intraprendere questo passaggio per proteggere l'integrità dei tuoi contenuti.
Aggiungendo la riga di codice NoIndex all'interno di ciascuna pagina che desideri nascondere ai motori di ricerca Internet e a ciascuna sottopagina sottostante, puoi garantire la sicurezza dei contenuti protetti che dovrebbero essere esclusi dall'accesso pubblico. Come altre piattaforme, anche la rimozione di questo tag è abbastanza semplice: è sufficiente utilizzare la funzione Code Injection per estrarre il codice.
Squarespace è unico in quanto i suoi concorrenti offrono questa opzione principalmente come parte della suite di impostazioni negli strumenti di gestione delle pagine. Squarespace parte da qui, consentendo la manipolazione personale del codice. Questo è interessante perché puoi vedere il cambiamento che stai apportando al contenuto della tua pagina, a differenza degli altri in questo spazio.
Controllo di NoIndex su Wix
Wix consente anche una soluzione semplice e veloce per i problemi di NoIndexing. Nelle impostazioni "Menu e pagine", puoi semplicemente disattivare l'opzione "mostra questa pagina nei risultati di ricerca" se desideri NoIndex di una singola pagina all'interno del tuo sito.
Come con i suoi concorrenti, Wix suggerisce anche di proteggere con password le tue pagine o l'intero sito per una maggiore privacy. Tuttavia, Wix si discosta dagli altri in quanto il team di supporto non prescrive azioni parallele su entrambi i fronti per proteggere i contenuti dal crawler. Wix fa una nota particolare sulla differenza tra nascondere una pagina dal tuo menu e nasconderla dai criteri di ricerca.
Questo è un consiglio particolarmente utile per i costruttori di siti Web meno esperti che inizialmente potrebbero non comprendere la differenza considerando che la rimozione dal menu del tuo sito rende la pagina irraggiungibile dal sito, ma non da un termine di ricerca Google prudente.