
Modellazione di argomenti con Word2Vec
Pubblicato: 2022-05-02Una parola è definita dall'azienda che mantiene. Questa è la premessa dietro Word2Vec, un metodo per convertire le parole in numeri e rappresentarli in uno spazio multidimensionale. Le parole che si trovano spesso vicine tra loro in una raccolta di documenti (corpus) appariranno anche vicine in questo spazio. Si dice che siano correlati contestualmente.
Word2Vec è un metodo di machine learning che richiede un corpus e una formazione adeguata. La qualità di entrambi influisce sulla sua capacità di modellare accuratamente un argomento. Eventuali carenze diventano immediatamente evidenti quando si esamina l'output per argomenti molto specifici e complicati poiché questi sono i più difficili da modellare con precisione. Word2Vec può essere utilizzato da solo, sebbene sia spesso combinato con altre tecniche di modellazione per affrontarne i limiti.
Il resto di questo articolo fornisce ulteriori informazioni su Word2Vec, come funziona, come viene utilizzato nella modellazione degli argomenti e alcune delle sfide che presenta.
Cos'è Word2Vec?
Nel settembre 2013, i ricercatori di Google, Tomas Mikolov, Kai Chen, Greg Corrado e Jeffrey Dean, hanno pubblicato il documento "Efficient Estimation of Word Representations in Vector Space" (pdf). Questo è ciò che ora chiamiamo Word2Vec. L'obiettivo del documento era "introdurre tecniche che possono essere utilizzate per apprendere vettori di parole di alta qualità da enormi set di dati con miliardi di parole e con milioni di parole nel vocabolario".
Prima di questo punto, qualsiasi tecnica di elaborazione del linguaggio naturale trattava le parole come unità singolari. Non hanno tenuto conto di alcuna somiglianza tra le parole. Sebbene ci fossero valide ragioni per questo approccio, aveva i suoi limiti. Ci sono state situazioni in cui il ridimensionamento di queste tecniche di base non poteva offrire miglioramenti significativi. Da qui la necessità di sviluppare tecnologie avanzate.
Il documento ha mostrato che modelli semplici, con i loro requisiti di calcolo inferiori, potrebbero addestrare vettori di parole di alta qualità. Come conclude il documento, è "possibile calcolare vettori di parole ad alta dimensione molto accurati da un set di dati molto più ampio". Stanno parlando di raccolte di documenti (corpora) con un trilione di parole che forniscono una dimensione virtualmente illimitata del vocabolario.
Word2Vec è un modo per convertire le parole in numeri, in questo caso vettori, in modo che le somiglianze possano essere scoperte matematicamente. L'idea è che i vettori di parole simili vengano raggruppati all'interno dello spazio vettoriale.
Pensa alle coordinate latitudinali e longitudinali su una mappa. Usando questo vettore bidimensionale, puoi determinare rapidamente se due posizioni sono relativamente vicine tra loro. Affinché le parole siano rappresentate in modo appropriato in uno spazio vettoriale, due dimensioni non sono sufficienti. Quindi, i vettori devono incorporare molte dimensioni.
Come funziona Word2Vec?
Word2Vec prende come input un grande corpus di testo e lo vettorizza utilizzando una rete neurale poco profonda. L'output è un elenco di parole (vocabolario), ciascuna con un vettore corrispondente. Parole con significato simile si trovano spazialmente nelle immediate vicinanze. Matematicamente questo è misurato dalla somiglianza del coseno, dove la somiglianza totale è espressa come un angolo di 0 gradi mentre nessuna somiglianza è espressa come un angolo di 90 gradi.
Le parole possono essere codificate come vettori utilizzando diversi tipi di modelli. Nel loro articolo, Mikolov et al. ha esaminato due modelli esistenti, il modello di linguaggio della rete neurale feedforward (NNLM) e il modello di linguaggio della rete neurale ricorrente (RNNLM). Inoltre, propongono due nuovi modelli log-lineari, sacchetto continuo di parole (CBOW) e Skip-gram continuo.
Nei loro confronti, CBOW e Skip-gram hanno ottenuto risultati migliori, quindi esaminiamo questi due modelli.
CBOW è simile a NNLM e si basa sul contesto per determinare una parola target. Determina la parola target in base alle parole che vengono prima e dopo di essa. Mikolov ha riscontrato che la migliore prestazione si è verificata con quattro parole future e quattro storiche. Si chiama 'borsa di parole' perché l'ordine delle parole nella storia non influenza l'output. "Continuo" nel termine CBOW si riferisce al suo uso di "rappresentazione distribuita continua del contesto".
Skip-gram è il contrario di CBOW. Data una parola, prevede le parole circostanti all'interno di un intervallo specifico. Un intervallo più ampio fornisce vettori di parole di migliore qualità ma aumenta la complessità computazionale. Viene dato meno peso ai termini distanti perché di solito sono meno legati alla parola corrente.
Confrontando CBOW con Skip-gram, è stato riscontrato che quest'ultimo offre risultati di qualità migliore su grandi set di dati. Sebbene CBOW sia più veloce, Skip-gram gestisce meglio le parole usate di rado.
Durante l'allenamento, a ogni parola viene assegnato un vettore. I componenti di quel vettore sono regolati in modo che parole simili (in base al loro contesto) siano più vicine tra loro. Pensa a questo come a un tiro alla fune, in cui le parole vengono spinte e trascinate in questo vettore multidimensionale ogni volta che un altro termine viene aggiunto allo spazio.
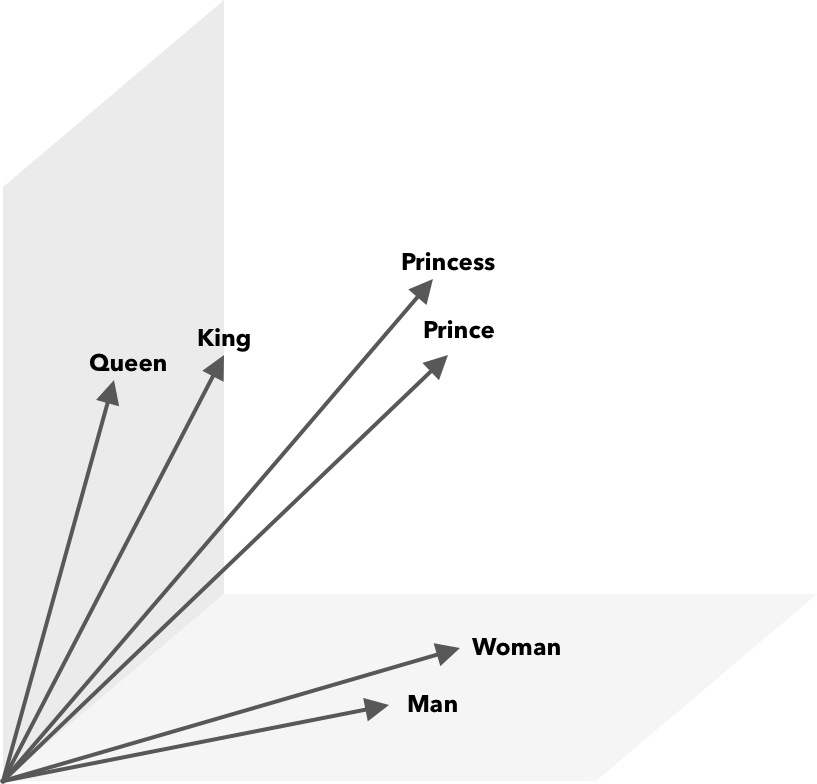
Le operazioni matematiche, oltre alla somiglianza del coseno, possono essere eseguite su vettori di parole. Ad esempio, vector("King") – vector("Man") + vector("Woman") risulta in un vettore più vicino a quello che rappresenta la parola Queen.

Word2Vec per la modellazione di argomenti
Il vocabolario creato da Word2Vec può essere interrogato direttamente per rilevare le relazioni tra le parole o inserito in una rete neurale di deep learning. Un problema con gli algoritmi di Word2Vec come CBOW e Skip-gram è che pesano allo stesso modo ogni parola. Il problema che sorge quando si lavora con i documenti è che le parole non rappresentano allo stesso modo il significato di una frase.
Alcune parole sono più importanti di altre. Pertanto, per affrontare la situazione vengono spesso utilizzate diverse strategie di ponderazione, come TF-IDF. Questo aiuta anche ad affrontare il problema dell'hubness menzionato nella sezione successiva. Searchmetrics ContentExperience utilizza una combinazione di TF-IDF e Word2Vec, di cui puoi leggere qui nel nostro confronto con MarketMuse.
Mentre le incorporazioni di parole come Word2Vec acquisiscono informazioni morfologiche, semantiche e sintattiche, la modellazione degli argomenti mira a scoprire la struttura semantica latente o gli argomenti in un corpus.
Secondo Budhkar e Rudzicz (PDF), la combinazione dell'allocazione Dirichlet latente (LDA) con Word2Vec può produrre caratteristiche discriminatorie per "affrontare il problema causato dall'assenza di informazioni contestuali incorporate in questi modelli". Una lettura più facile su LDA2vec può essere trovata in questo tutorial di DataCamp.
Sfide di Word2Vec
Ci sono diversi problemi con l'incorporamento di parole in generale, incluso Word2Vec. Toccheremo alcuni di questi, per un'analisi più dettagliata, fare riferimento a "A Survey of Word Embedding Evaluation Methods" (pdf) di Amir Bakarov. Il corpus e le sue dimensioni, così come la formazione stessa, avranno un impatto significativo sulla qualità dell'output.
Come valuti l'output?
Come spiega Bakarov nel suo articolo, un ingegnere della PNL valuterà in genere le prestazioni degli incorporamenti in modo diverso rispetto a un linguista computazionale o un marketer di contenuti per quella materia. Ecco alcuni problemi aggiuntivi citati nel documento.
- La semantica è un'idea vaga. Un "buono" incorporamento di parole riflette la nostra nozione di semantica. Tuttavia, potremmo non essere consapevoli se la nostra comprensione è corretta. Inoltre, le parole hanno diversi tipi di relazioni come la relazione semantica e la somiglianza semantica. Che tipo di relazione dovrebbe riflettere la parola incorporamento?
- Mancanza di dati di allenamento adeguati. Quando si addestrano gli incorporamenti di parole, i ricercatori spesso ne migliorano la qualità adattandoli ai dati. Questo è ciò che chiamiamo adattamento della curva. Invece di adattare il risultato ai dati, i ricercatori dovrebbero cercare di catturare le relazioni tra le parole.
- L'assenza di correlazione tra metodi intrinseci ed estrinseci significa che non è chiaro quale classe di metodo sia preferita. La valutazione estrinseca determina la qualità dell'output da utilizzare più a valle in altre attività di elaborazione del linguaggio naturale. La valutazione intrinseca si basa sul giudizio umano delle relazioni verbali.
- Il problema del mozzo. Gli hub, vettori di parole che rappresentano parole comuni, sono vicini a un numero eccessivo di altri vettori di parole. Questo rumore può influenzare la valutazione.
Inoltre, ci sono due sfide significative in particolare con Word2Vec.
- Non può affrontare le ambiguità molto bene. Di conseguenza, il vettore di una parola con più significati riflette la media, che è tutt'altro che ideale.
- Word2Vec non è in grado di gestire parole fuori vocabolario (OOV) e parole morfologicamente simili. Quando il modello incontra un nuovo concetto, ricorre all'utilizzo di un vettore casuale, che non è una rappresentazione accurata.
Sommario
L'uso di Word2Vec o di qualsiasi altra incorporazione di parole non è garanzia di successo. L'output di qualità si basa su una formazione adeguata utilizzando un corpus appropriato e sufficientemente ampio.
Sebbene la valutazione della qualità dell'output possa essere ingombrante, ecco una soluzione semplice per i marketer dei contenuti. La prossima volta che stai valutando un ottimizzatore di contenuti, prova a utilizzare un argomento molto specifico. I modelli tematici di scarsa qualità falliscono quando si tratta di testare in questo modo. Vanno bene per i termini generali, ma si rompono quando la richiesta diventa troppo specifica.
Quindi, se usi l'argomento "come coltivare gli avocado", assicurati che i suggerimenti abbiano qualcosa a che fare con la coltivazione della pianta e non con gli avocado in generale.
La generazione del linguaggio naturale di MarketMuse NLG Technology ha aiutato a creare questo articolo.
Cosa dovresti fare ora
Quando sei pronto... ecco 3 modi in cui possiamo aiutarti a pubblicare contenuti migliori, più velocemente:
- Prenota tempo con MarketMuse Pianifica una demo dal vivo con uno dei nostri strateghi per vedere come MarketMuse può aiutare il tuo team a raggiungere i propri obiettivi di contenuto.
- Se desideri imparare a creare contenuti migliori più velocemente, visita il nostro blog. È pieno di risorse per aiutare a ridimensionare i contenuti.
- Se conosci un altro marketer a cui piacerebbe leggere questa pagina, condividila con loro via e-mail, LinkedIn, Twitter o Facebook.