
Che cos'è il crawl budget e come ottimizzarlo in modo intelligente?
Pubblicato: 2021-08-19Sommario
L'analisi del crawl budget è tra le mansioni lavorative di qualsiasi esperto SEO (in particolare se ha a che fare con siti Web di grandi dimensioni). Un compito importante, decentemente trattato nei materiali forniti da Google. Tuttavia, come puoi vedere su Twitter, anche i dipendenti di Google minimizzano il ruolo del crawl budget nell'ottenere traffico e ranking migliori:

Hanno ragione su questo?
Come funziona Google e come raccoglie i dati?
Mentre affrontiamo l'argomento, ricordiamo come il motore di ricerca raccoglie, indicizza e organizza le informazioni. Tenere questi tre passaggi in un angolo della tua mente è essenziale durante il tuo lavoro successivo sul sito web:
Passaggio 1: scansione . Perlustrare le risorse online allo scopo di scoprire - e navigare attraverso - tutti i collegamenti, i file e i dati esistenti. In genere, Google inizia con i luoghi più popolari sul Web, quindi procede alla scansione di altre risorse meno di tendenza.
Passaggio 2: indicizzazione . Google cerca di determinare di cosa tratta la pagina e se il contenuto/documento in analisi costituisce materiale unico o duplicato. In questa fase, Google raggruppa i contenuti e stabilisce un ordine di importanza (leggendo i suggerimenti nei tag rel="canonical" o rel="alternate" o altro).
Passaggio 3: servire . Una volta segmentati e indicizzati, i dati vengono visualizzati in risposta alle query degli utenti. Questo è anche il momento in cui Google ordina i dati in modo appropriato, considerando fattori come la posizione dell'utente.
Importante: molti dei materiali disponibili trascurano il passaggio 4: rendering dei contenuti . Per impostazione predefinita, Googlebot indicizza i contenuti di testo. Tuttavia, poiché le tecnologie web continuano ad evolversi, Google ha dovuto escogitare nuove soluzioni per smettere di "leggere" e iniziare anche a "vedere". Questo è tutto ciò che riguarda il rendering. Serve a Google per migliorare sostanzialmente la sua portata tra i siti Web appena lanciati ed espandere l'indice.
Nota : i problemi con il rendering dei contenuti possono essere la causa di un crawl budget non riuscito.
Qual è il budget di scansione?
Il budget di scansione non è altro che la frequenza con cui i crawler e i bot dei motori di ricerca possono indicizzare il tuo sito Web, nonché il numero totale di URL a cui possono accedere in una singola scansione. Immagina il tuo crawl budget come crediti che puoi spendere in un servizio o in un'app. Se non ti ricordi di "addebitare" il tuo budget di scansione, il robot rallenterà e ti farà meno visite.
In SEO, "addebito" si riferisce al lavoro dedicato all'acquisizione di backlink o al miglioramento della popolarità complessiva di un sito web. Di conseguenza, il crawl budget è parte integrante dell'intero ecosistema del Web. Quando stai facendo un buon lavoro sul contenuto e sui backlink, stai aumentando il limite del tuo budget di scansione disponibile.
Nelle sue risorse, Google non si azzarda a definire esplicitamente il crawl budget. Indica invece due componenti fondamentali della scansione che influiscono sulla completezza di Googlebot e sulla frequenza delle sue visite:
- limite di velocità di scansione;
- domanda di scansione.
Qual è il limite della velocità di scansione e come verificarlo?
In parole povere, il limite della velocità di scansione è il numero di connessioni simultanee che Googlebot può stabilire durante la scansione del tuo sito. Poiché Google non vuole danneggiare l'esperienza dell'utente, limita il numero di connessioni per mantenere prestazioni fluide del tuo sito Web/server. In breve, più lento è il tuo sito web, minore è il tuo limite di velocità di scansione.
Importante: il limite di scansione dipende anche dalla salute generale della SEO del tuo sito web: se il tuo sito attiva molti reindirizzamenti, errori 404/410 o se il server restituisce spesso un codice di stato 500, anche il numero di connessioni diminuirà.
Puoi analizzare i dati sui limiti della velocità di scansione con le informazioni disponibili in Google Search Console, nel rapporto Statistiche di scansione .
Scansione della domanda o popolarità del sito web
Mentre il limite della velocità di scansione richiede di rifinire i dettagli tecnici del tuo sito web, la domanda di scansione ti premia per la popolarità del tuo sito web. In parole povere, maggiore è il brusio attorno al tuo sito Web (e su di esso), maggiore è la sua richiesta di scansione.
In questo caso, Google fa il punto su due questioni:
- Popolarità generale: Google è più desideroso di eseguire scansioni frequenti degli URL generalmente popolari su Internet (non necessariamente quelli con backlink dal maggior numero di URL).
- Freschezza dei dati dell'indice: Google si impegna a presentare solo le informazioni più recenti. Importante: la creazione di un numero sempre maggiore di nuovi contenuti non significa che il limite complessivo del budget di scansione stia aumentando.
Fattori che influenzano il crawl budget
Nella sezione precedente, abbiamo definito il budget di scansione come una combinazione del limite della velocità di scansione e della domanda di scansione. Tieni presente che devi prenderti cura di entrambi, contemporaneamente, per garantire la corretta scansione (e quindi l'indicizzazione) del tuo sito web.
Di seguito troverai un semplice elenco di punti da considerare durante l'ottimizzazione del crawl budget
- Server : il problema principale sono le prestazioni. Minore è la tua velocità, maggiore è il rischio che Google assegni meno risorse all'indicizzazione dei tuoi nuovi contenuti.
- Codici di risposta del server : maggiore è il numero di reindirizzamenti 301 e errori 404/410 sul tuo sito Web, peggiori risultati di indicizzazione otterrai. Importante: fai attenzione ai loop di reindirizzamento: ogni "hop" riduce il limite di velocità di scansione del tuo sito Web per la visita successiva del bot.
- Blocchi in robots.txt : se stai basando le tue direttive robots.txt sulla sensazione istintiva, potresti finire per creare colli di bottiglia nell'indicizzazione. Il risultato: ripulirai l'indice, ma a scapito dell'efficacia dell'indicizzazione per le nuove pagine (quando gli URL bloccati erano saldamente incorporati nella struttura dell'intero sito Web).
- Navigazione sfaccettata/identificatori di sessione/qualsiasi parametro negli URL : soprattutto, fai attenzione alle situazioni in cui un indirizzo con un parametro può essere ulteriormente parametrizzato, senza restrizioni in atto. Se ciò dovesse accadere, Google raggiungerà un numero infinito di indirizzi, spendendo tutte le risorse disponibili nelle parti meno significative del nostro sito web.
- Contenuti duplicati: i contenuti copiati (a parte la cannibalizzazione) danneggiano in modo significativo l'efficacia dell'indicizzazione di nuovi contenuti.
- Contenuto sottile – che si verifica quando una pagina ha un rapporto testo/HTML molto basso. Di conseguenza, Google potrebbe identificare la pagina come un cosiddetto Soft 404 e limitare l'indicizzazione del suo contenuto (anche quando il contenuto è significativo, come potrebbe essere il caso, ad esempio, della pagina di un produttore che presenta un unico prodotto e non contenuto del testo).
- Scarso collegamento interno o mancanza di esso .
Strumenti utili per l'analisi del crawl budget
Poiché non esiste un benchmark per il crawl budget (il che significa che è difficile confrontare i limiti tra i siti Web), attrezzatevi con una serie di strumenti progettati per facilitare la raccolta e l'analisi dei dati.
Console di ricerca di Google
GSC è cresciuta bene nel corso degli anni. Durante un'analisi del crawl budget, ci sono due rapporti principali che dovremmo esaminare: Index Coverage e Crawl stats.
Copertura dell'indice in GSC
Il rapporto è un'enorme fonte di dati. Verifichiamo le informazioni sugli URL esclusi dall'indicizzazione. È un ottimo modo per capire la portata del problema che stai affrontando.
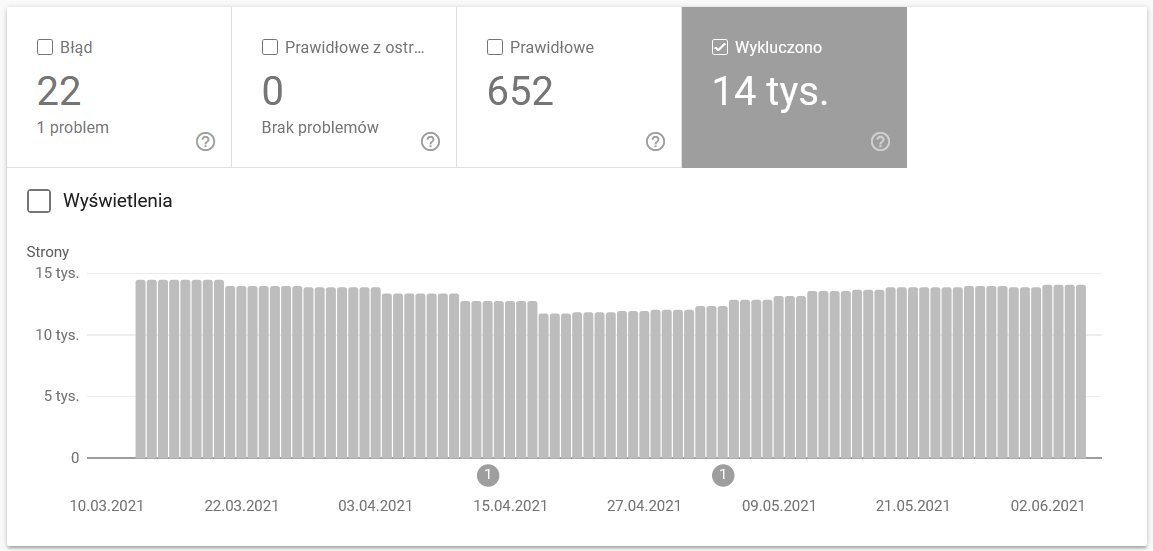
L'intero rapporto merita un articolo separato, quindi per ora concentriamoci sulle seguenti informazioni:
- Escluso dal tag 'noindex' – In generale, più pagine noindex significano meno traffico. Il che fa sorgere la domanda: che senso ha tenerli sul sito web? Come limitare l'accesso a queste pagine?
- Scansionato – attualmente non indicizzato – se lo vedi, controlla se il contenuto viene visualizzato correttamente agli occhi di Googlebot. Ricorda che ogni URL con quello stato spreca il tuo budget di scansione perché non genera traffico organico.
- Scoperto – al momento non indicizzato – uno dei problemi più allarmanti che vale la pena mettere in cima alla lista delle priorità.
- Duplica senza canonico selezionato dall'utente : tutte le pagine duplicate sono estremamente pericolose in quanto non solo danneggiano il budget di scansione, ma aumentano anche il rischio di cannibalizzazione.
- Duplicato, Google ha scelto canonico diverso dall'utente : in teoria, non è necessario preoccuparsi. Dopotutto, Google dovrebbe essere abbastanza intelligente da prendere una decisione sana al nostro posto. Bene, in realtà, Google seleziona i suoi canonici in modo abbastanza casuale, spesso tagliando pagine preziose con un canonico che punta alla home page.
- Soft 404 : tutti gli errori "soft" sono altamente pericolosi in quanto possono portare alla rimozione di pagine critiche dall'indice.
- URL inviato duplicato non selezionato come canonico , simile alla segnalazione di stato sulla mancanza di canoni selezionati dall'utente.
Statistiche di scansione
Il report non è perfetto e per quanto riguarda i consigli, consiglio vivamente di giocare anche con i buoni vecchi log del server, che danno una visione più approfondita dei dati (e più opzioni di modellazione).
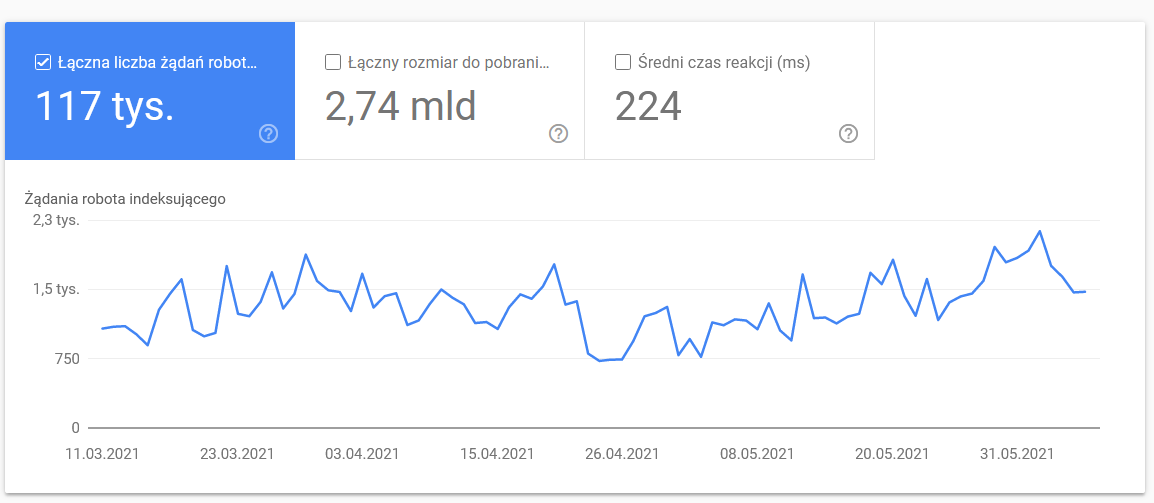
Come ho già detto, sarà difficile cercare benchmark per le cifre sopra. Tuttavia, è un buon invito a dare un'occhiata più da vicino:
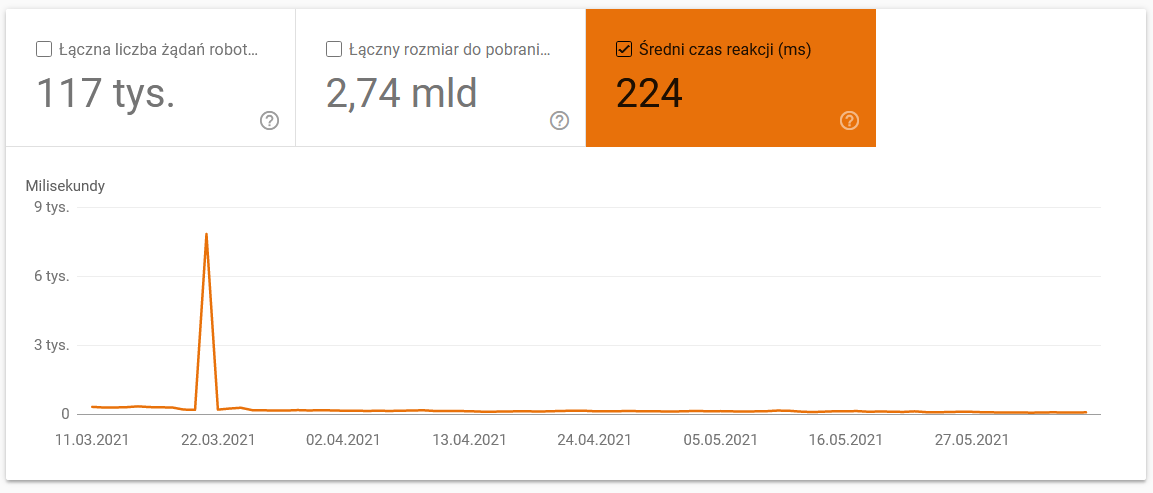
- Tempo medio di download. Lo screenshot qui sotto mostra che il tempo medio di risposta ha avuto un notevole successo, a causa di problemi relativi al server:
- Risposte di scansione. Guarda il rapporto per vedere, in generale, se hai un problema con il tuo sito web o meno. Presta molta attenzione ai codici di stato del server atipici, come i 304 di seguito. Questi URL non hanno uno scopo funzionale, tuttavia Google spreca le sue risorse per eseguire la scansione dei loro contenuti.

- Scopo della scansione. In generale, questi dati dipendono in gran parte dal volume di nuovi contenuti sul sito web. Le differenze tra le informazioni raccolte da Google e l'utente possono essere piuttosto affascinanti:
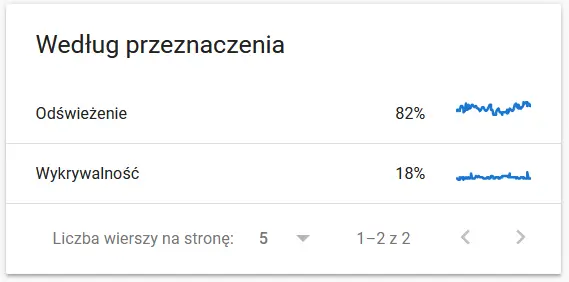
Contenuti di un URL scansionato agli occhi di Google:
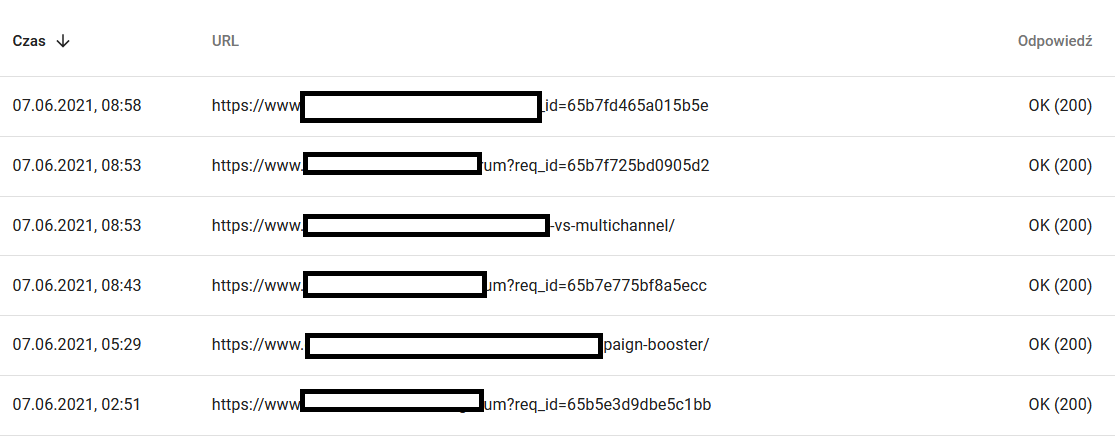
Nel frattempo, ecco cosa vede l'utente nel browser:
Sicuramente motivo di riflessione e analisi :)
- Tipo di Googlebot . Qui hai i bot che visitano il tuo sito web su un piatto d'argento, insieme alle loro motivazioni per analizzare i tuoi contenuti. Lo screenshot seguente mostra che il 22% delle richieste si riferisce al caricamento delle risorse della pagina.
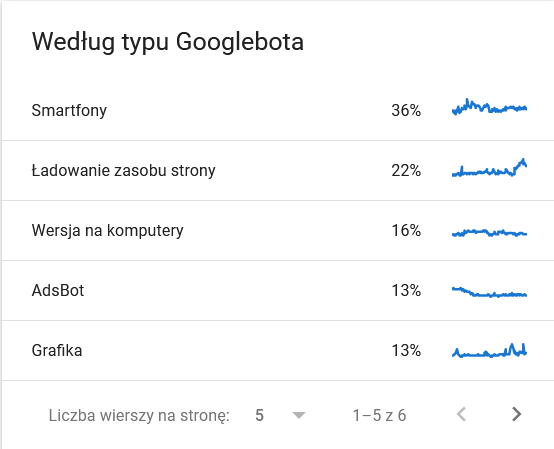
Il totale è aumentato negli ultimi giorni dell'intervallo di tempo:
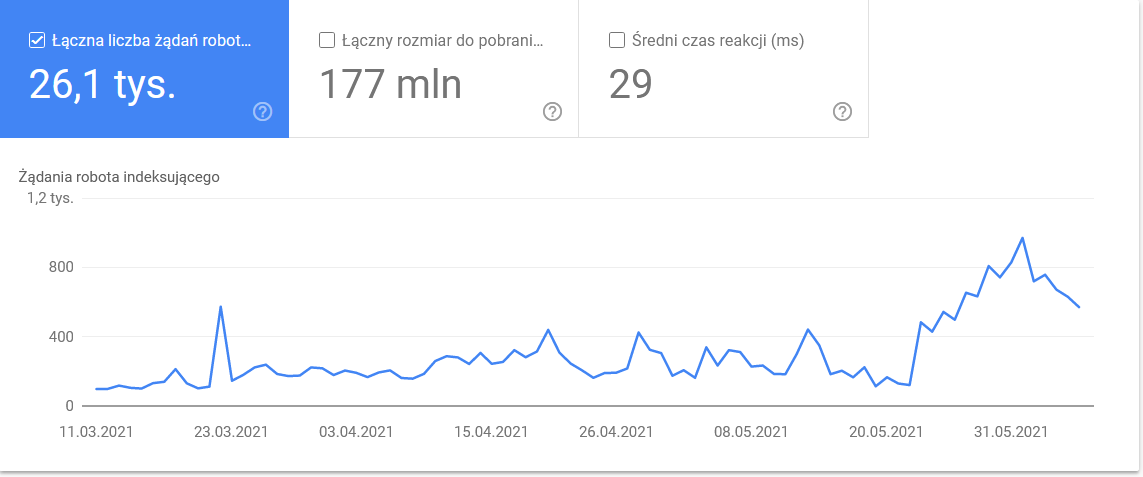
Uno sguardo ai dettagli rivela gli URL che richiedono maggiore attenzione:
Crawler esterni (con esempi da Screaming Frog SEO Spider)
I crawler sono tra gli strumenti più importanti per analizzare il budget di scansione del tuo sito web. Il loro scopo principale è imitare i movimenti dei bot di scansione sul sito web. La simulazione ti mostra a colpo d'occhio se tutto sta andando a gonfie vele.
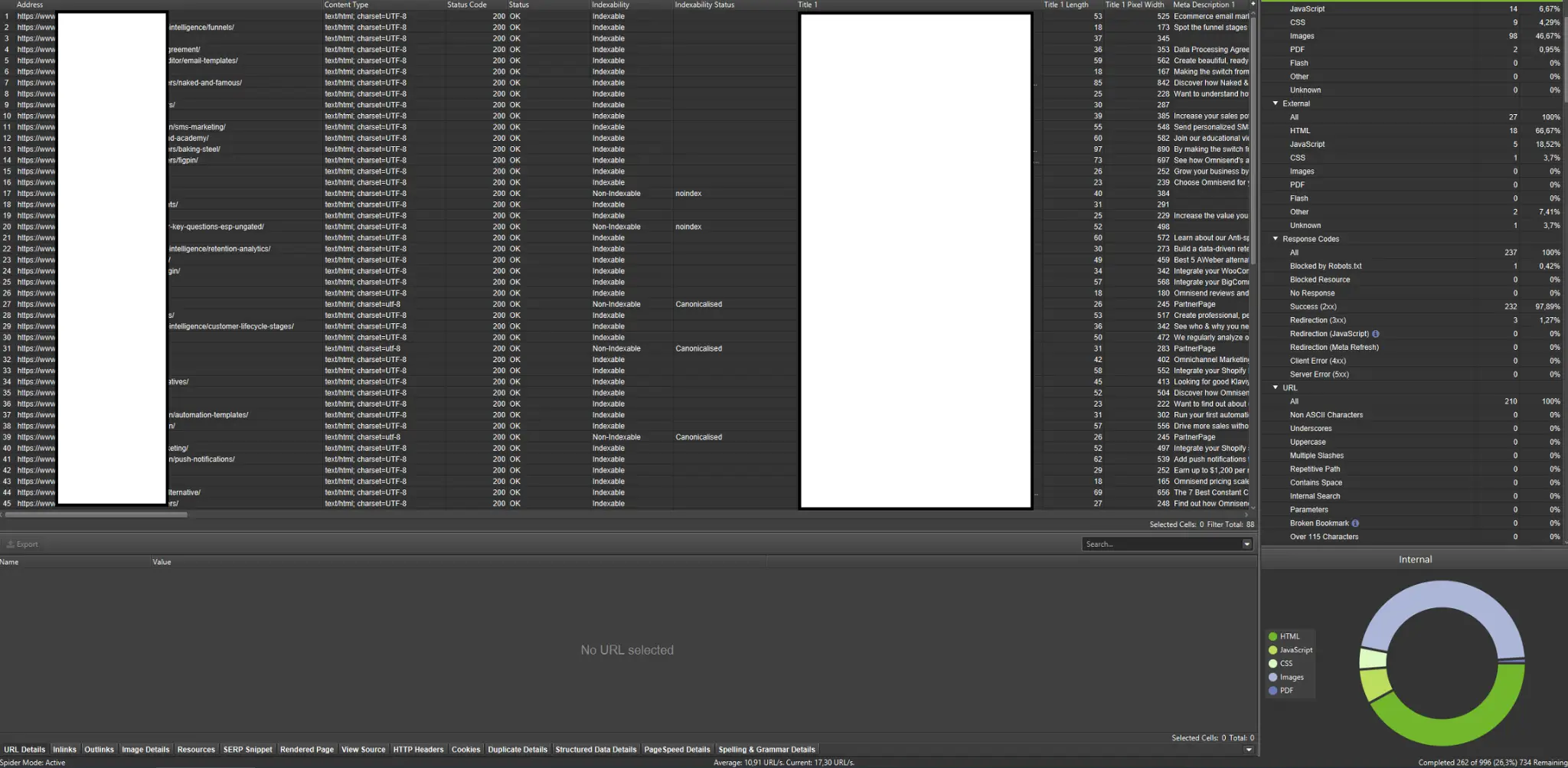
Se sei uno studente visivo, dovresti sapere che la maggior parte delle soluzioni disponibili sul mercato offre visualizzazioni di dati.
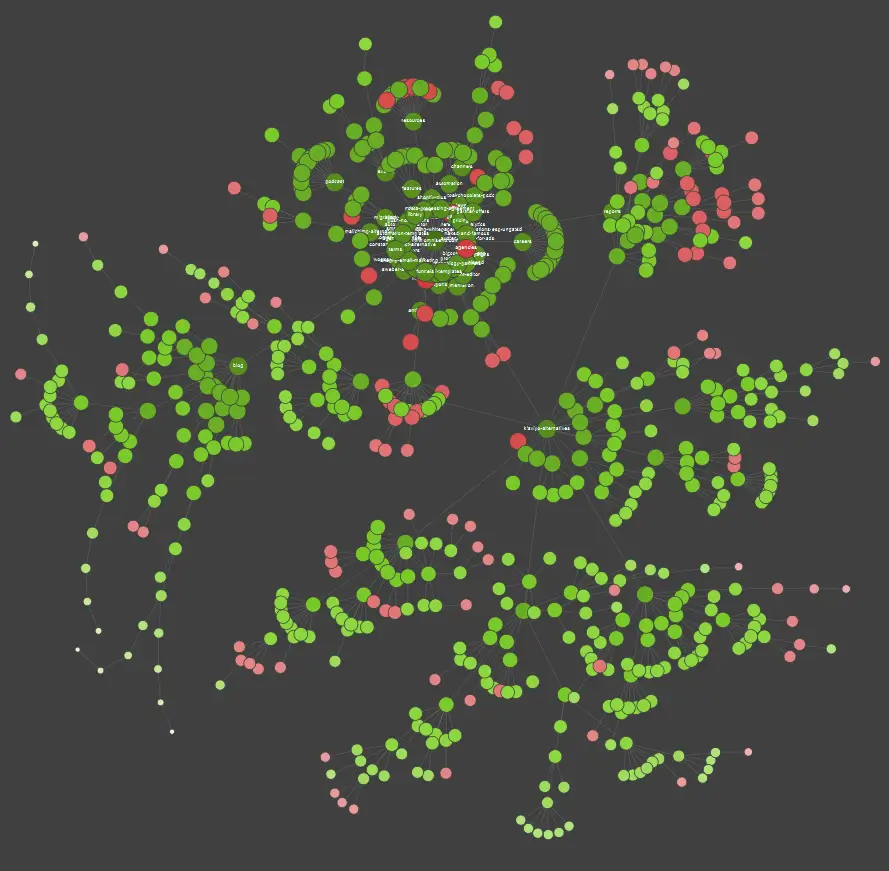
Nell'esempio sopra, i punti rossi rappresentano le pagine non indicizzate. Prenditi un po' di tempo per considerare la loro utilità e impatto sul funzionamento del sito. Se i log del server rivelano che queste pagine fanno perdere molto tempo a Google senza aggiungere alcun valore, è tempo di rivisitare seriamente il punto di mantenerle sul sito web.
Importante : se vogliamo ricreare il comportamento di un Googlebot nel modo più accurato possibile, le impostazioni corrette sono d'obbligo. Qui puoi vedere le impostazioni di esempio dal mio computer:
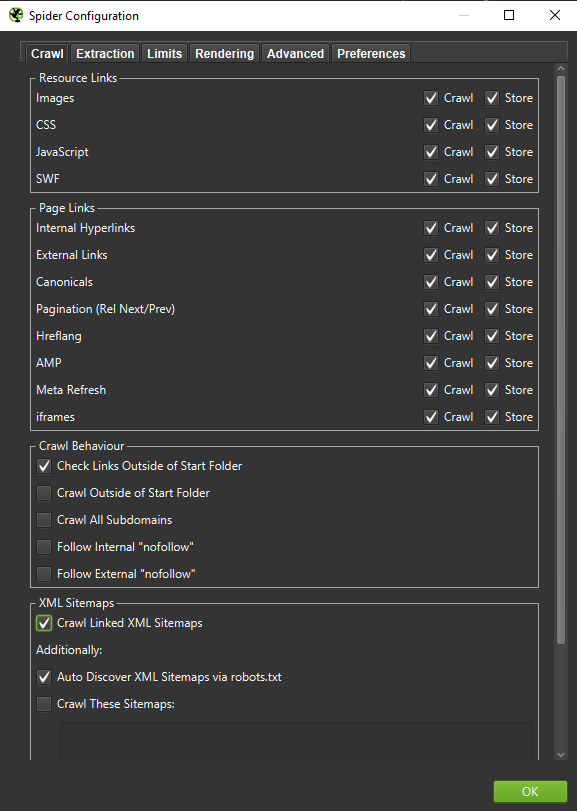
Quando si esegue un'analisi approfondita, è consigliabile testare due modalità – Solo testo, ma anche JavaScript – per confrontare le differenze (se presenti).

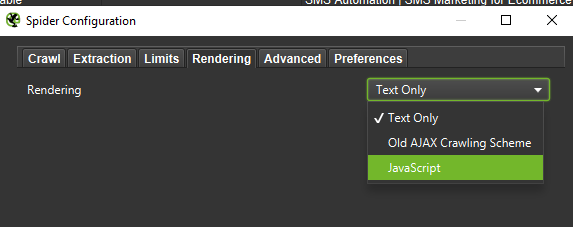
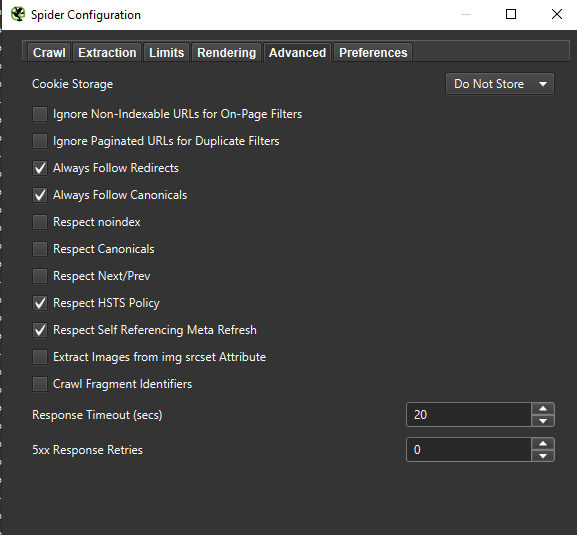
Infine, non fa mai male testare la configurazione presentata sopra su due diversi programmi utente:
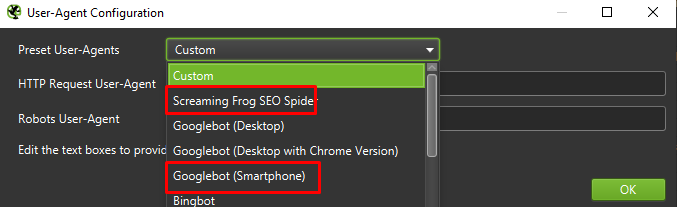
Nella maggior parte dei casi, dovrai concentrarti solo sui risultati sottoposti a scansione/rendering dall'agente mobile.
Importante: suggerisco anche di sfruttare l'opportunità fornita da Screaming Frog e di alimentare il tuo crawler con i dati di GA e Google Search Console. L'integrazione è un modo rapido per identificare gli sprechi di crawl budget, come un corpo consistente di URL potenzialmente ridondanti che non ricevono traffico.
Strumenti per l'analisi dei log (Screaming Frog Logfile e altri)
La scelta di un analizzatore di log del server è una questione di preferenze personali. Il mio strumento di riferimento è l'analizzatore di file di registro Screaming Frog. Potrebbe non essere la soluzione più efficiente (caricare un enorme pacchetto di registri = appendere l'applicazione), ma mi piace l'interfaccia. La parte importante è ordinare al sistema di visualizzare solo Googlebot verificati.
Strumenti per il monitoraggio della visibilità
Un aiuto utile, perché ti permettono di identificare le tue prime pagine. Se una pagina si posiziona in alto per molte parole chiave in Google (= riceve molto traffico), potrebbe potenzialmente avere una maggiore richiesta di scansione (controllalo nei log: Google genera davvero più hit per questa particolare pagina?).
Per i nostri scopi, avremo bisogno di rapporti generali in Senuto – Percorsi e URL – per una revisione continua in futuro. Entrambi i report sono disponibili in Analisi visibilità, la scheda Sezioni. Dare un'occhiata:
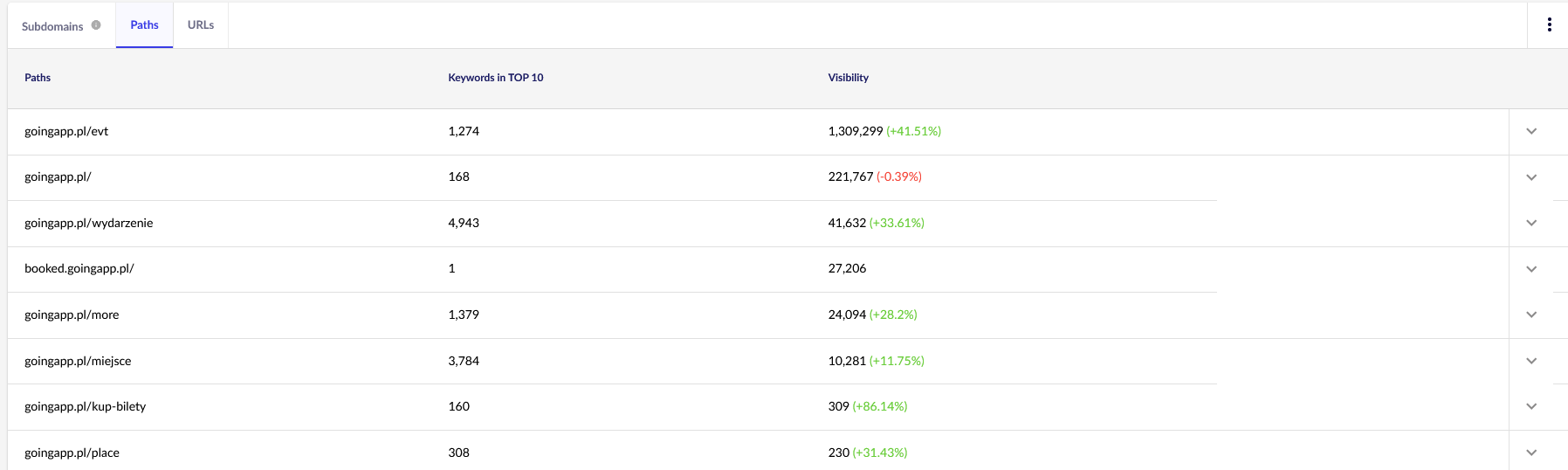
Il nostro principale punto di interesse è il secondo rapporto. Ordiniamolo per esaminare la visibilità delle nostre parole chiave (l'elenco e il numero totale di parole chiave per le quali il nostro sito Web si posiziona nella TOP 10). I risultati ci serviranno per identificare l'asse principale per la stimolazione (e l'allocazione efficiente) del nostro crawl budget.
Strumenti per l'analisi dei backlink (Ahrefs, Majestic)
Se una delle tue pagine ha una quantità elevata di link in entrata, usala come pilastro della tua strategia di ottimizzazione del crawl budget. Le pagine popolari possono assumere il ruolo di hub che trasferiscono ulteriormente il succo. Inoltre, una pagina popolare con un discreto pool di link preziosi ha maggiori possibilità di attirare frequenti crawl.
In Ahrefs, abbiamo bisogno del rapporto Pages e, per essere esatti, della sua parte intitolata: "Best by links":
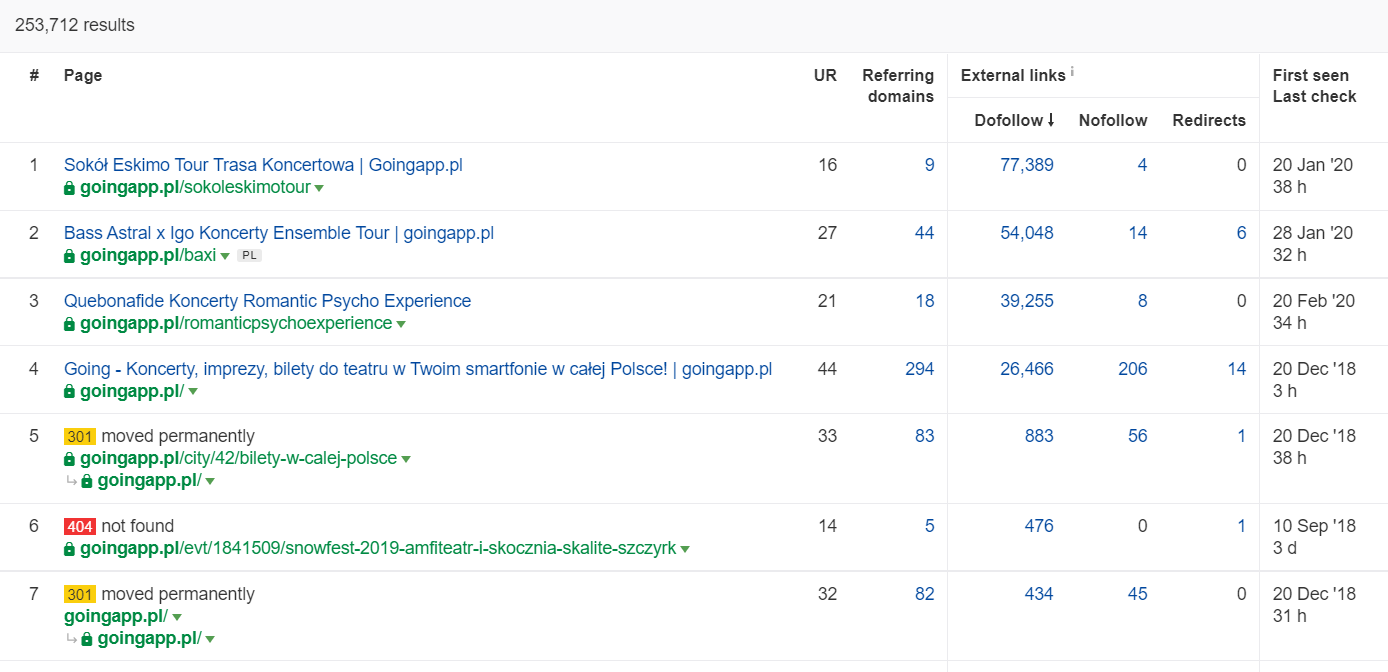
L'esempio sopra mostra che alcuni LP relativi ai concerti hanno continuato a generare statistiche solide per i backlink. Anche con tutti i concerti cancellati a causa della pandemia, vale comunque la pena utilizzare pagine storicamente potenti per stuzzicare la curiosità dei robot scansionati e diffondere il succo negli angoli più profondi del tuo sito web.
Quali sono i segni evidenti di un problema di crawl budget?
La consapevolezza di avere a che fare con un crawl budget problematico (eccessivamente basso) non è facile. Come mai? Principalmente perché la SEO è un'impresa estremamente complessa. Rango bassi o problemi di indicizzazione possono anche essere la conseguenza di un profilo di collegamento mediocre o della mancanza del contenuto giusto sul sito web.
In genere, una diagnostica del crawl budget comporta il controllo di:
- Quanto tempo passa dalla pubblicazione all'indicizzazione di nuove pagine (post blog/prodotti), supponendo che tu non richieda l'indicizzazione tramite Google Search Console?
- Per quanto tempo Google conserva gli URL non validi nel suo indice? Importante: gli indirizzi reindirizzati sono un'eccezione: Google li memorizza di proposito.
- Hai pagine che entrano nell'indice solo per essere eliminate in seguito?
- Quanto tempo dedica Google alle pagine che non generano valore (traffico)? Vai all'analisi del registro per scoprirlo.
Come analizzare e ottimizzare il crawl budget?
La decisione di immergersi nell'ottimizzazione del crawl budget è dettata principalmente dalle dimensioni del tuo sito web. Google suggerisce che, in generale, i siti Web con meno di 1000 pagine non dovrebbero tormentarsi per sfruttare al meglio i limiti di scansione disponibili. Nel mio libro, dovresti iniziare a lottare per una scansione più efficiente ed efficace se il tuo sito Web include più di 300 pagine e i tuoi contenuti cambiano dinamicamente (ad esempio, continui ad aggiungere nuove pagine / post di blog).
Come mai? È una questione di igiene SEO. Implementa buone abitudini di ottimizzazione e una sana gestione del crawl budget nei primi giorni e avrai meno da rettificare e riprogettare in futuro.
Ottimizzazione del budget di scansione. Una procedura standard
In generale, il lavoro di analisi e ottimizzazione del craw budget si compone di tre fasi:
- Raccolta dei dati, che è il processo di compilazione di tutto ciò che sappiamo sul sito Web, sia da webmaster che da strumenti esterni.
- Analisi della visibilità e identificazione dei frutti a bassa pendenza. Cosa funziona come un orologio? Cosa potrebbe esserci di meglio? Quali aree hanno il più alto potenziale di crescita?
- Raccomandazioni per il crawl budget.
Raccolta dati per un controllo del crawl budget
1. Scansione completa del sito Web eseguita con uno degli strumenti disponibili in commercio. L'obiettivo è completare un minimo di due scansioni: la prima simula Googlebot, mentre l'altra recupera il sito Web come agente utente predefinito (lo farà l'agente utente di un browser). In questa fase, sei interessato solo a scaricare il 100% del contenuto . Se noti che il crawler è entrato in un ciclo (quando, dopo un giorno di scansione, abbiamo ancora solo il 10% del sito Web sul nostro disco rigido), fai sapere che c'è un problema e puoi interrompere la scansione. Un numero ragionevole di URL per l'analisi, nel caso di siti Web di grandi dimensioni, è di circa 250-300 mila pagine.
a) Quello che stiamo cercando sono principalmente reindirizzamenti 301 interni, errori 404, ma anche situazioni in cui i tuoi testi potrebbero essere classificati come contenuti sottili. Screaming Frog ha la possibilità di rilevare contenuti quasi duplicati:
2. Registri del server . L'intervallo di tempo ideale dovrebbe abbracciare l'ultimo mese, tuttavia, nel caso di siti Web di grandi dimensioni, due ultime settimane potrebbero essere sufficienti. Nel migliore dei casi, dovremmo avere accesso ai log storici del server per confrontare i movimenti di Googlebot nel momento in cui tutto stava andando a gonfie vele.
3. Esportazione dei dati da Google Search Console . In combinazione con i punti 1 e 2 sopra, i dati di Index Coverage e Crawl Stats dovrebbero darti un resoconto abbastanza completo di tutti gli eventi sul tuo sito web.
4. Dati sul traffico organico . Pagine principali determinate da Google Search Console, Google Analytics, nonché da Senuto e Ahrefs. Vogliamo identificare tutte le pagine che si distinguono tra la folla con le loro statistiche di alta visibilità, il volume di traffico o il conteggio dei backlink. Queste pagine dovrebbero diventare la spina dorsale del tuo lavoro sul crawl budget. Li utilizzeremo per migliorare la scansione delle pagine più importanti.
5. Revisione manuale dell'indice . In alcuni casi, il miglior amico di un esperto SEO è una soluzione semplice. In questo caso: una rassegna dei dati presi direttamente dall'indice! È una buona scelta per controllare il tuo sito web con la combinazione di inurl: + site: operator.Infine, dobbiamo unire tutti i dati raccolti. In genere, utilizzeremo un crawler esterno con funzionalità che consentono l'importazione di dati esterni (dati GSC, registri del server e dati sul traffico organico).
Analisi della visibilità e frutti bassi
Il processo merita un articolo separato, ma il nostro obiettivo oggi è avere una visione a volo d'uccello dei nostri obiettivi per il sito Web e dei progressi compiuti. Ci interessa tutto ciò che è fuori dall'ordinario: i cali di traffico improvvisi (non spiegabili con le tendenze stagionali) e gli spostamenti simultanei della visibilità organica. Stiamo verificando quali gruppi di pagine sono i più forti perché diventeranno i nostri HUB per spingere Googlebot più in profondità nel nostro sito web.
Nel mondo perfetto, un tale controllo dovrebbe coprire l'intera storia del nostro sito Web dal suo lancio. Tuttavia, poiché il volume di dati continua a crescere ogni mese, concentriamoci sull'analisi della visibilità e del traffico organico dell'ultimo periodo di 12 mesi.
Crawl budget: i nostri consigli
Le attività sopra elencate differiranno a seconda delle dimensioni del sito web ottimizzato. Tuttavia, sono gli elementi più importanti che considero sempre quando eseguo un'analisi del crawl budget. L'obiettivo principale è eliminare i colli di bottiglia sul tuo sito web. In altre parole, per garantire la massima scansionabilità per i Googlebot (o altri agenti di indicizzazione).
1. Cominciamo dalle basi: l'eliminazione di tutti i tipi di errori 404/410, l'analisi dei reindirizzamenti interni e la loro rimozione dai collegamenti interni . Dovremmo concludere il nostro lavoro con un ultimo crawl. Questa volta, tutti i collegamenti dovrebbero restituire un codice di risposta 200, senza reindirizzamenti interni o errori 404.
- A questo punto, è una buona idea correggere tutte le catene di reindirizzamento rilevate nel rapporto di backlink.
2. Dopo la scansione, assicurati che la struttura del nostro sito Web sia priva di evidenti duplicati .
- Verifica anche la potenziale cannibalizzazione: a parte i problemi derivanti dal targeting della stessa parola chiave con più pagine (in breve, smetti di controllare quale pagina verrà visualizzata da Google), la cannibalizzazione influisce negativamente sull'intero crawl budget.
- Consolida i duplicati identificati in un unico URL (di solito quello con il ranking più alto).
3. Controlla quanti URL hanno il tag noindex . Come sappiamo, Google può ancora navigare tra quelle pagine. Semplicemente non vengono visualizzati nei risultati di ricerca. Stiamo cercando di ridurre al minimo la quota di tag noindex nella struttura del nostro sito web.
- Caso in questione: un blog organizza la sua struttura con i tag; gli autori affermano che la soluzione è dettata dalla comodità dell'utente. Ogni post è etichettato con 3-5 tag, assegnati in modo incoerente e non indicizzati. L'analisi del registro rivela che è la terza struttura più scansionata sul sito web.
4. Esamina robots.txt . Ricorda che l'implementazione di robots.txt non significa che Google non visualizzerà l'indirizzo nell'indice.
- Verifica quali delle strutture di indirizzi bloccate vengono ancora sottoposte a scansione. Forse tagliarli sta causando un collo di bottiglia?
- Rimuovere le direttive obsolete/non necessarie.
5. Analizza il volume di URL non canonici sul tuo sito web. Google ha smesso di considerare rel="canonical" come una direttiva rigida. In molti casi, l'attributo viene addirittura ignorato dal motore di ricerca (ordinamento dei parametri nell'indice – ancora un incubo).
6. Analizzare i filtri e il loro meccanismo sottostante . Il filtraggio delle inserzioni è il principale problema dell'ottimizzazione del crawl budget. I titolari di attività di e-commerce insistono nell'implementare filtri applicabili in qualsiasi combinazione (ad esempio, filtrando per colore + materiale + taglia + disponibilità... all'ennesima volta). La soluzione non è ottimale e dovrebbe essere limitata al minimo.
7. Architettura delle informazioni sul sito Web : un'architettura che tiene conto degli obiettivi aziendali, del potenziale di traffico e del profilo di collegamento corrente. Partiamo dal presupposto che un link al contenuto critico per i nostri obiettivi di business debba essere visibile in tutto il sito (su tutte le pagine) o sulla home page. Stiamo semplificando qui, ovviamente, ma la home page e il menu principale / i collegamenti a livello di sito sono gli indicatori più potenti per creare valore dai collegamenti interni. Allo stesso tempo, stiamo cercando di ottenere la diffusione ottimale del dominio: il nostro obiettivo è la situazione in cui possiamo iniziare la scansione da qualsiasi pagina e raggiungere comunque lo stesso numero di pagine (ogni URL dovrebbe avere un link in entrata AL MINIMO) .
- Lavorare verso una solida architettura dell'informazione è uno degli elementi chiave dell'ottimizzazione del crawl budget. Ci consente di liberare alcune delle risorse del bot da una posizione e reindirizzarle a un'altra. È anche una delle sfide più grandi, poiché richiede la cooperazione delle parti interessate del business, il che spesso porta a enormi battaglie e critiche che minano le raccomandazioni SEO.
8. Rendering dei contenuti. Critico nel caso di siti web che mirano a basare i loro collegamenti interni su sistemi di raccomandazione che catturano il comportamento degli utenti. Soprattutto, la maggior parte di questi strumenti si basa su file cookie. Google non memorizza i cookie, quindi non ottiene risultati personalizzati. Il risultato: Google vede sempre lo stesso contenuto o nessun contenuto.
- È un errore comune impedire a Googlebot di accedere a contenuti JS/CSS critici. Questa mossa potrebbe causare problemi con l'indicizzazione delle pagine (e far perdere tempo a Google nel rendere i contenuti non disponibili).
9. Prestazioni del sito Web: elementi vitali Web principali . Sebbene sia scettico sull'impatto del CWV sulle classifiche dei siti (per molte ragioni, inclusa la diversità dei dispositivi disponibili in commercio e le velocità variabili della connessione Internet), è uno dei parametri che vale la pena discutere con un programmatore.
10. Sitemap.xml – controlla se funziona e contiene tutti gli elementi chiave (nient'altro che URL canonici che restituiscono un codice di stato 200).
- Il mio primo consiglio per ottimizzare sitemap.xml è di dividere le pagine per tipo o, quando possibile, per categoria. La divisione ti darà il pieno controllo sui movimenti di Google e sull'indicizzazione dei contenuti.