
キューによる復元力の実現:10億のビートをスキップしないシステムの構築
公開: 2018-12-21Brazeは、顧客に代わって1日あたり数十億のイベントを処理し、その結果、エンドユーザーに送信される数十億の非常に焦点を絞ったパーソナライズされたメッセージを生成します。 これらのメッセージの1つを送信しなかった場合、それが領収書の紛失であろうと、さらに悪いことに、食品の準備ができたことをユーザーに知らせる通知の紛失であろうと、結果が生じます。 これらの重要なメッセージが常に正しく、常に時間どおりであることを確認するために、Brazeはジョブキューを活用する方法に戦略的なアプローチを採用しています。
ジョブキューとは何ですか?
典型的なジョブキューは、プロセスが計算ジョブをキューに送信し、他のプロセスが実際にジョブを実行するアーキテクチャパターンです。 これは通常、良いことです。適切に使用すると、従来の要求と応答のパラダイムでは得られない程度の同時実行性、スケーラビリティ、および冗長性が得られます。 多くのワーカーは、複数のプロセス、複数のマシン、または複数のデータセンターで同時に異なるジョブを実行して、同時実行性をピークにすることができます。 特定のワーカーノードを特定のキューで動作するように割り当て、特定のジョブを特定のキューに送信して、必要に応じてリソースをスケーリングできます。 ワーカープロセスがクラッシュしたり、データセンターがオフラインになったりした場合、他のワーカーが残りのジョブを実行できます。
これらの原則を確実に適用して、小規模でジョブキューイングシステムを簡単に実行できますが、何十億ものジョブを処理しているときに、継ぎ目が表示され始めます(さらにはバーストします)。 1日あたり数千から数百万、そして今では数十億のジョブの処理に成長するにつれて、Brazeが直面したいくつかの問題を見てみましょう。
一貫性の欠如は弱点です
メッセージを送信したが、そのメッセージを送信したという事実を記録する前にクラッシュした場合はどうなりますか?
ここでは、いくつかの異なる悪い結果が生じる可能性があります。 まず、失敗したジョブのスケジュールを変更して、メッセージを再送信することができます。 それは…理想的ではありません。同じものを2回受け取りたいと思う人は誰もいません。 代わりに、スケジュールをまったく変更しないことを検討してください。 その場合、当社の内部会計は不正確になるため、帰属、コンバージョン、およびその他のあらゆる種類のものが正しく前進することはありません。
どうすれば修正できますか? 私たちの仕事の定義を書くとき、私たちはべき等性と再試行の振る舞いについて本当に真剣に考えます。
キューについて話している場合、べき等とは、単一のジョブを任意の時点で終了し、再キューに入れられたジョブ全体を再実行できることを意味します。最終結果は、ジョブを1つだけ正常に実行した場合と同じになります。時間。 これは、選択した再試行動作(少なくとも1回の配信)と密接に関連しています。 すべてのジョブが少なくとも1回、場合によっては複数回実行されることを念頭に置くことで、ランダムな障害が発生した場合でも一貫性を確保するべき等のジョブ定義を記述できます。
メッセージ送信の例に戻ると、一貫性を確保するためにこれらの概念をどのように使用できるでしょうか。 この場合、ジョブを2つの部分に分割し、最初の部分がメッセージを送信して2番目の部分をキューに入れ、2番目の部分がデータベースに書き込みます。 そのシナリオでは、どちらのジョブも何度でも再試行できます。メッセージ送信プロバイダーがダウンしている場合、または内部アカウンティングデータベースがダウンしている場合は、成功するまで適切に再試行します。
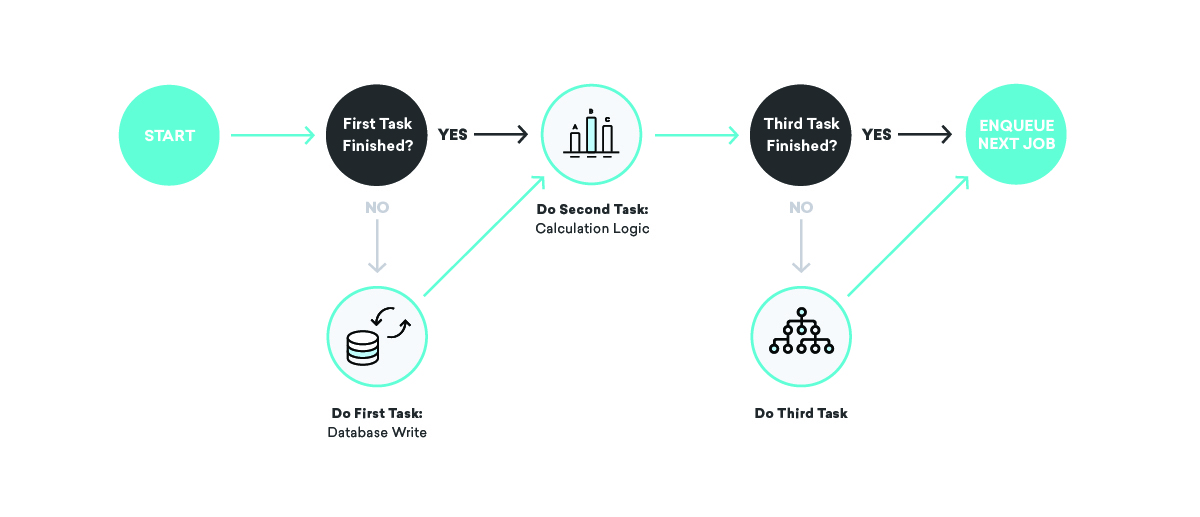
良いフェンスは良い隣人を作る
Global Gizmosのデータベースがダウンすると、サンプル会社のConsolidated Widgetsのデータ処理はどうなりますか?
このシナリオでは、少なくとも1回の配信戦略が機能している場合、Global Gizmosのすべてのデータ処理ジョブは、成功するまで何度も再試行することが期待されます。 これは素晴らしいことです。データベースがダウンしている間でもデータが失われることはありません。 ただし、統合ウィジェットの場合はそれほど優れていない可能性があります。ワーカーが常に再試行して失敗している場合は、忙しすぎて統合ウィジェットの作業をタイムリーに処理できない可能性があります。
これは、適切に選択されたキュー名を使用し、必要に応じて特定のキューを一時停止することで修正できます。 これをツールベルトに組み込むことで、外科的な方法でインフラストラクチャの一部への負担を軽減できます。 上記のシナリオでは、Global Gizmosのデータベースがダウンしていることがわかったら、バックアップが完了するまでデータ処理キューを一時停止して、特定の停止が他の顧客に影響を与えないようにすることができます。

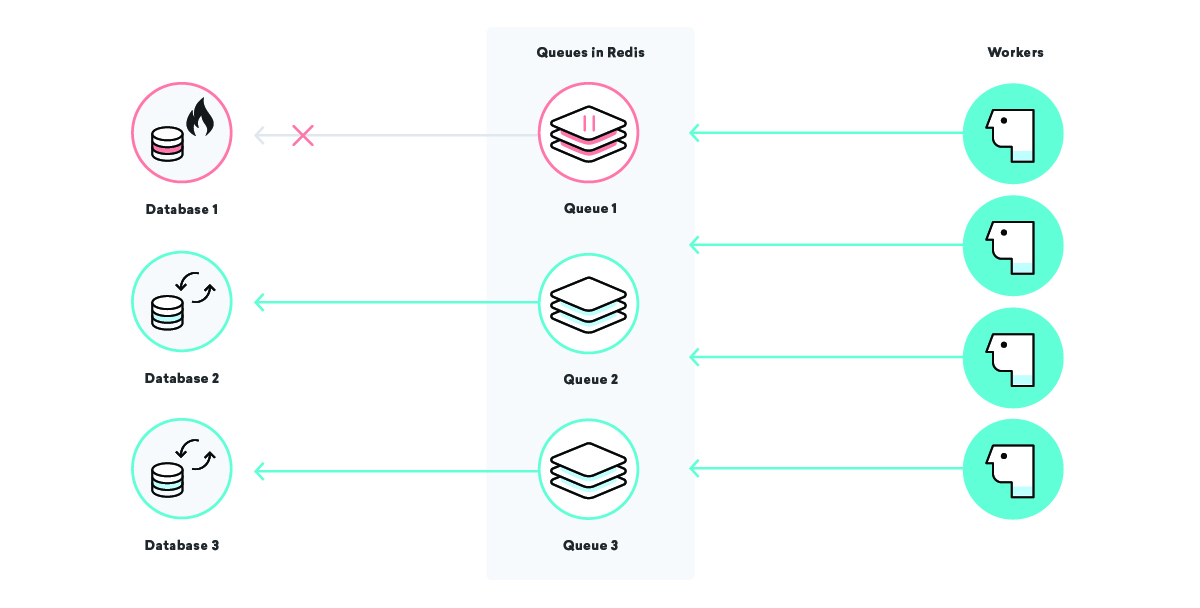
待つのは辛い
統合ウィジェットとグローバルギズモがそれぞれ5000万人のユーザーに5分間隔でメールキャンペーンを送信するとどうなりますか? 誰が最初に行きますか?
単純なジョブキューイングシステムには、ワーカーがジョブをプルする単純な「作業」キューがあります。 さまざまなジョブとジョブタイプができたら、おそらく複数のタイプのキューに移ります。それぞれのキューには、異なる優先順位またはそれらのキューからプルするワーカーのタイプがあります。 その流れの中で、データ処理、メッセージング、およびさまざまなメンテナンスタスクのためのさまざまな単純なキューがあります。
1日に何十億ものパーソナライズされたメッセージを送信する場合に早送りすると、1つの「メッセージング」キューがそれを削減することはありません。上記の例のように、そのキューが非常に大きくなるとどうなりますか? 最初に到着したジョブを優先しますか?
私たちの動的キューイングシステムは、ジョブの枯渇と呼ばれる現象に対処しようとしています。この現象では、通常、何らかの優先順位が原因で、実行の準備ができているジョブが実行されるまで長時間待機します。 単純な「メッセージング」キューでは、優先順位は単にジョブがキューに入った時間です。つまり、大きなキューの最後に追加されたジョブは、非常に長い時間待機することになります。
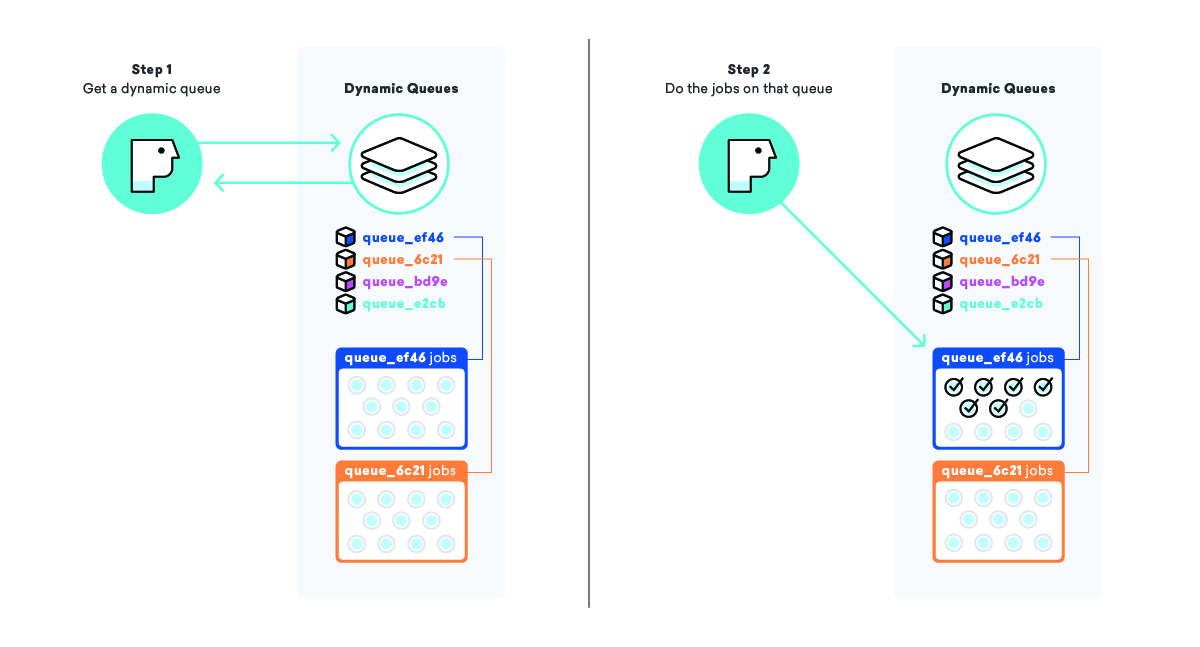
キャンペーンとそのすべてのメッセージをキューに入れるとき、大きな「メッセージング」キューにジョブを追加する代わりに、このキャンペーンだけのまったく新しいキューを作成します。特別な名前が付いているので、それが何であるかがわかります。それを見つける方法。 ジョブをキューに追加した後、「動的キュー」リストを取得し、この新しいキュー名を最後に追加します。
この戦略を採用することで、「動的キュー」リストから動的キューの名前を取得し、その特定のキュー上のすべてのジョブを処理するようにワーカーに指示できます。 これにより、メッセージが可能な限り高速に送信され、すべてのお客様が同等の優先順位で扱われるようになります。
その結果、特定のワーカーの作業の局所性が高まるため、キャッシュヒット率が高くなり、データベース接続が少なくなるなど、他の利点もあります。 誰もが勝ちます!
常にバックアップ計画を立てる
データベースがダウンし、一部のキューが一時停止され、ジョブキューがいっぱいになり始めるとどうなりますか?
インフラストラクチャの重要な部分が単にあなたに死ぬこともあります。 セカンダリとバックアップが用意されていますが、バックアップインフラストラクチャの促進にかかる時間はほとんどゼロではありません。 アプリケーションインフラストラクチャ全体に複数のキュー層を設けることは、これらのタイプのイベントの影響を軽減するのに非常に役立ちます。
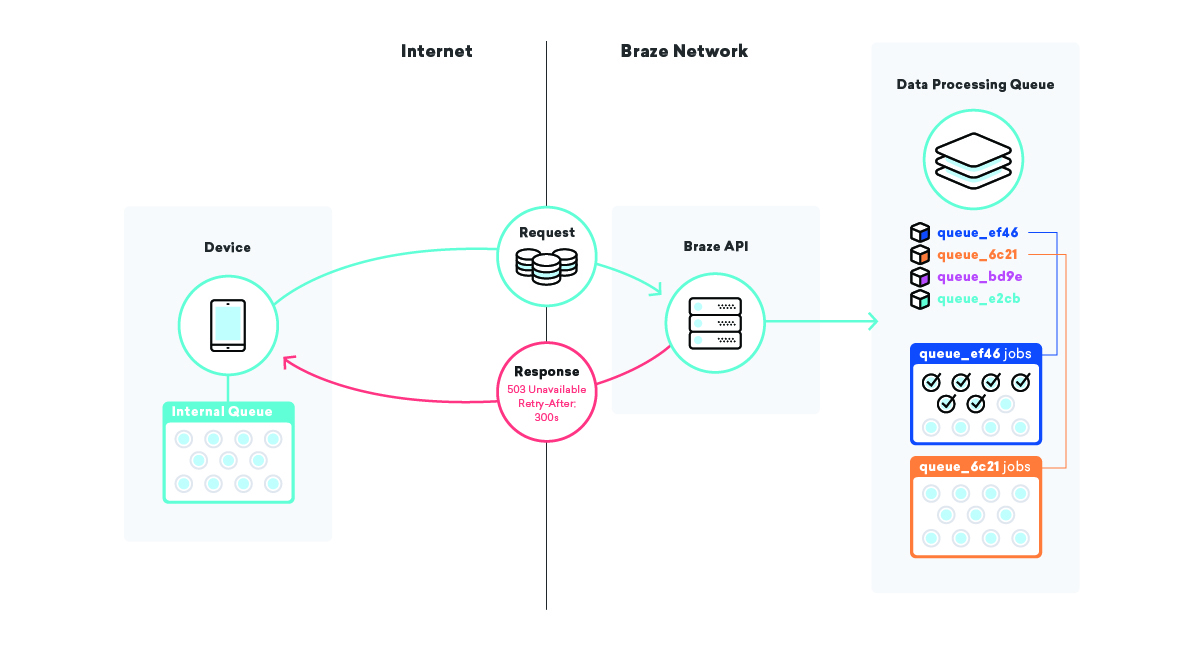
私たちが採用しているそのような戦略の1つは、デバイス自体のキューイングです。 何百万ものデバイスがBrazeSDKを使用するさまざまなアプリケーションを持っており、それらのアプリケーションでは、APIにデータを送信するためにキューを利用しています。
SDKがそのデータを送信しようとして失敗すると、何らかの理由で、SDKは成功するまで指数バックオフアルゴリズムを使用して再試行をキューに入れます。 この戦略は、インフラストラクチャやコードの障害の影響を最小限に抑えます。これは、デバイスが自分のデータをキューに入れ、すべてがオンラインに戻ったときにそれをBrazeに送信するためです。
速く動き、物事を壊さない
結局のところ、私たちの目標は、他の誰よりも優れた、焦点を絞ったパーソナライズされたメッセージを送信することです。これには、迅速に行動し、回復力を持ち、すべてを正しく行うことが含まれます。 ジョブキューはBrazeのインフラストラクチャの中心であるため、常にパフォーマンスを監視し、ベストプラクティスを採用し、ゲームで最高になるように新しい戦略と高度なテクニックを試しています。
マーケティングオートメーション分野でのこの種の高性能で低レイテンシのシステムエンジニアリングがあなたを興奮させるなら、あなたは間違いなく私たちの求人掲示板をチェックするべきです!